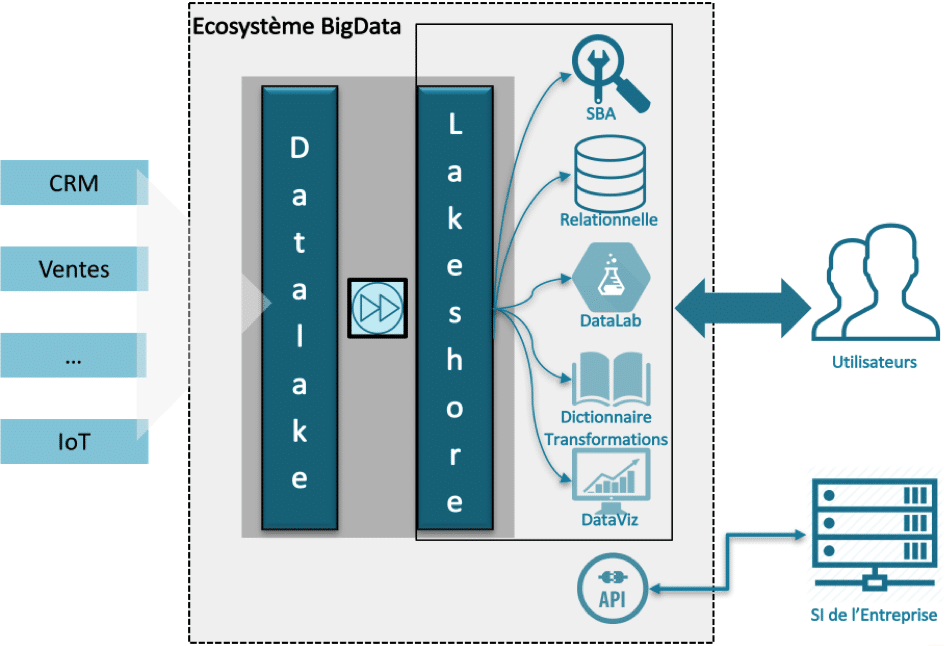
Comment exposer les données du DataLake ?

Cet article fait partie d’une série d’articles co-rédigés par Emmanuel Manceau (Quantmetry), Olivier Denti (Quantmetry) et Magali Barreau-Combeau (OVH) sur le sujet « Architecture – De la BI au Big Data ».
Au sein de l’écosystème « BigData », une fois les données brutes recopiées dans le datalake, se posent différentes questions :
– Comment améliorer la connaissance de mes données ?
– Comment mes données sont-elles structurées ?
– Comment les visualiser, les manipuler ?
– Comment les mettre à disposition ?
Aujourd’hui, plusieurs solutions existent pour que les utilisateurs puissent accéder aux données.
Les outils dédiés à une population d’utilisateurs :
Search Based Application (moteur de recherche)
Utilisé essentiellement par les Utilisateurs avancés, Utilisateurs Finaux ou DataAnalyst, il permet de rechercher de l’information dans de grandes quantités de données (indexées depuis un modèle dénormalisé) sans forcément devoir pré-agréger la donnée. Une analyse, via IHM, sur toutes les dimensions est donc possible, avec d’excellents temps de réponse.
Base SQL Relationnelle
Principalement destinée aux Utilisateurs avancés ou DataAnalyst, elle permet de réaliser des requêtes ad-hoc et joindre des data set comme ils le faisaient précédemment avec un Datawarehouse. Les données proviennent d’un sous-ensemble du Lakeshore.
DataLab
Utilisé par les DataScientist ou DataAnalyst, c’est le lieu d’expérimentation par excellence et de POC. La liberté est laissée aux utilisateurs de réaliser différents types de traitements (dont Machine Learning).
Outils de DataViz / Data Analytics
Ils servent surtout aux Utilisateurs avancés, Utilisateurs Finaux ou DataAnalyst pour visualiser et manipuler les données. Plusieurs outils peuvent être mis à disposition en fonction des exigences de l’use case (visualisation des données en temps réel, temps de réponse à la sélection, profondeur de l’historique etc.).
Les outils dédiés au Système d’Information (SI)
Le SI de l’Entreprise est un « client » comme un autre des données du DataLake. On distingue deux systèmes.
Export de données
Cette technique, plutôt utilisée en mode « batch », permet d’alimenter des systèmes en une seule fois (une fois par jour par exemple, après les traitements de nuit).
API
Les systèmes récupèrent des données unitaires via une interface (type WebService). Cette méthode est par exemple utilisée dans un centre d’appels, où les frontaux des téléconseillers affichent un « score » client récupéré en temps réel lors de la consultation du dossier client.
Les outils communs pour tous les acteurs
Quels que soient les types d’acteurs (utilisateurs, SI), il est impératif de connaître quelles sont les données présentes et comprendre comment elles ont été constituées. Deux outils sont alors nécessaires.
Dictionnaire de données
Le dictionnaire de données permet à un utilisateur de :
– retrouver une information nécessaire, comme un objet métier ;
– avoir une définition claire et précise de l’objet ;
– identifier la localisation (table, colonne, fichier…) de cette information.
Cette recherche se fait généralement par une recherche en texte libre et/ou une navigation à travers des facettes de navigation afin de converger rapidement vers le résultat escompté.
Pour être pertinent, le dictionnaire prend également en compte les définitions des objets des métiers de l’Entreprise ainsi que leur rattachement à des domaines fonctionnels. Par « objet métier », j’entends par exemple le « payeur », « titulaire », « contrat », « compte de facturation »…
Référentiel des transformations
Le référentiel des transformations, que l’on appelle également Data Lineage, permet de comprendre comment est constituée la donnée (à partir de quoi et comment).
Par exemple, le calcul du chiffre d’affaires peut être le résultat d’un agrégat de tous les tickets de caisses en excluant les achats réalisés lors des ventes privées. Idéalement, l’outil doit tracer les cheminements et transformations des données, depuis la réception des données brutes (tickets de caisses) jusqu’à leur enrichissement (dans quel contexte la vente a été réalisée), le filtrage (exclure les ventes privées) et l’exposition (faire la somme des montants).
Ce type d’outil (très demandé !) n’existe pas vraiment. Des suites logicielles (à condition qu’elles soient utilisées de bout en bout de la chaîne) sont à même de proposer un « lineage » mais les informations restituées sont très techniques et ne peuvent actuellement pas être mises à disposition à des utilisateurs « finaux ». L’alternative serait de documenter manuellement chaque étape de la transformation mais c’est une charge importante et qui doit nécessairement être maintenue dans le temps.