

Cutting-edge NLP 1 : ULMFiT

Cet article est le premier d’une série de discussions dédiées à l’exploration de ce qui se fait de mieux dans la recherche académique liée au Natural Language Processing (NLP). Les objectifs sont multiples : appréhender cet état de l’art qui a accéléré ces derniers mois et révolutionne peu à peu la discipline ; et comprendre comment actionner concrètement ces fantastiques découvertes pour des cas d’usages réels.
Ce premier billet se concentre sur ULMFiT [1].
Constat : des méthodes de transfer learning inadaptées au NLP
ImageNet – un dataset fort aujourd’hui de plus de 14 millions d’images – est souvent considéré comme le catalyseur de la recherche en Intelligence Artificielle moderne. Utilisé comme modèle pré-entraîné dans un nombre important de tâches, il a démocratisé le transfer learning : la réutilisation d’un modèle pré-entraîné sur les données d’une tâche générale comme base pour l’entraînement d’un nouveau modèle sur les données d’une tâche cible. Il a ainsi contribué à faire progresser considérablement la recherche en Computer Vision (CV). La situation est différente en ce qui concerne le NLP : si de nombreux modèles – essentiellement basés sur du deep learning – ont atteint l’état-de-l’art sur de nombreuses tâches, ils sont entraînés from scratch – à partir de zéro, nécessitent des jeux de données labellisés très volumineux et des temps d’entraînements importants, parfois plusieurs jours…
L’introduction des embeddings [2] – représentations vectorielles denses et porteuses de sens de caractères, mots, phrases, etc. – a permis d’entrevoir une première forme de transfer learning. Ces derniers sont entraînés sur des corpus de textes volumineux comme Wikipedia et servent de première couche (ou base) pour d’autres modèles. Cependant, la spécialisation d’un modèle final – via l’étape de fine-tuning ou ajustement des paramètres – se révèle souvent infructueuse à cause de méthodes peu adaptées qui annihilent ce qui a été appris par le modèle pré-entraîné.
C’est en partant de ce constat que Jeremy Howard de l’université de San Francisco et Sebastian Ruder du NUI Galway [1] ont décidé d’introduire pour le NLP une méthode équivalente au fine-tuning des modèles de CV pré-entraînés sur ImageNet : Universal Lanquage Model Fine-Tuning (ULMFiT).
1. Des modèles de langue généralistes comme équivalents d’ImageNet pour le NLP
En cherchant à prédire le mot suivant au sein d’une phrase, les modèles de langue (LM) capturent de nombreuses facettes du langage telles que les dépendances long terme entre les mots, les relations hiérarchiques et les sentiments. C’est cette capacité à capturer les propriétés générales du langage qui rend un LM particulièrement pertinent comme modèle pré-entraîné en vue de futures tâches de NLP. En outre, les résultats empiriques montrent que leur structure est particulièrement adaptée au processus de fine-tuning, permettant de s’adapter aux particularités d’une tâche cible. Enfin, parce que l’entraînement d’un LM est non supervisé – la cible étant toujours « le mot d’après », il libère l’utilisateur de toute contrainte sur la quantité de données textuelles labellisées disponibles, ces dernières étant particulièrement difficiles à réunir en quantité et qualité suffisantes.
Un LM pré-entraîné sur un corpus généraliste semble donc être un bon équivalent à un modèle pré-entraîné sur ImageNet pour le NLP. Dans le cas de l’anglais, un corpus généraliste peut s’apparenter à la base de données Wikitext-103, qui comprend 28 595 articles prétraités sur Wikipedia et 103 millions de mots.
Les modèles sous-jacents aux LMs sont généralement des réseaux de neurones récurrents de type LSTM. Les meilleures performances sont notamment obtenues avec une architecture de type AWD-LSTM [1].
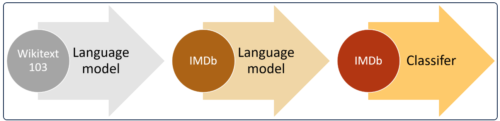
Figure 1 : illustration des 3 étapes dans le cas de l’entraînement d’un classifieur sur les données IMDb.
2. Deux méthodes de fine-tuning novatrices pour adapter le LM aux données de la tâche cible
Un LM pré-entraîné sur un corpus généraliste est par définition peu spécifique et cherche à capter des généralités du langage. Les données d’une tâche cible – qui sont elles spécifiques – proviendraient donc probablement d’une distribution différente. Une première idée consiste alors en la spécialisation – ou fine-tuning – du LM généraliste aux données cibles. Le LM obtenu sera robuste, et ce même avec de faibles volumes de données. Deux méthodes adaptées au fine-tuning des LMs sont introduites :
- Le discriminative fine-tuning : les différentes couches du LM capturent différents types d’informations. C’est la raison pour laquelle elles doivent être fine-tunées différemment : au lieu d’utiliser un pas d’apprentissage (learning rate) unique pour l’ensemble des couches du modèle, chaque couche est fine-tunée avec un pas d’apprentissage qui lui est propre. Le papier de recherche propose de commencer par choisir le pas d’apprentissage de la dernière couche L par fine-tuning, avant de diviser ce pas par un facteur 2.6 à chque des couches précédentes jusqu’à atteindre la première couche.
- Le slanted triangular learning rates (STLR) : pour adapter les paramètres du LM aux caractéristiques d’une tâche spécifique. On cherchera dans un premier temps à les faire converger rapidement vers une région appropriée de l’espace des paramètres avant de les affiner. STLR va donc d’abord accroître rapidement et linéairement le pas d’apprentissage (LR) avant de le réduire lentement et linéairement.
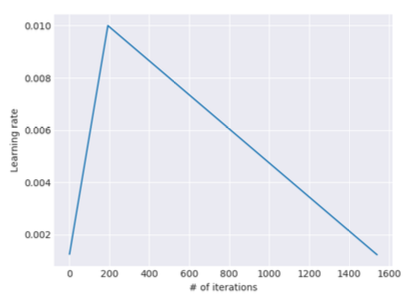
Figure 2 : valeur du taux d’apprentissage selon le nombre d’itération avec la méthode STLR.
3. Un classifieur à fine-tuner sur la tâche cible
Une fois fine-tuné, le LM est complété par deux blocs linéaires supplémentaires qui constituent la partie classifieur du modèle pour résoudre une tâche cible non généraliste. C’est bien le fine-tuning de ce classifieur qui est la partie la plus difficile du transfer learning. En effet, contrairement au LM déjà pré-entraîné, les couches de classifieur doivent être entraînées from scratch.
Pour associer les couches de LM aux deux blocs linéaires de classifieur, on applique le concat pooling pour capter les informations les plus importantes et écarter celles qui le sont moins et qui seront les inputs des deux blocs linéaires.
Concat pooling : le signal dans les tâches de classification de texte est souvent contenu dans quelques mots qui peuvent apparaître à n’importe quel endroit au sein du document. Comme les documents d’entrée peuvent contenir des centaines de mots, des informations peuvent être perdues si on ne considère que le dernier état caché du modèle. Pour cette raison, la première couche linéaire prend en entrée les états poolés de la dernière couche cachée : on concatène l’état caché au dernier step avec les représentations max-pooled et mean-pooled des états cachés sur autant de time step que les GPU le permettent.
D’autre part, un réglage trop agressif du classifieur entraînerait un « oubli catastrophique », éliminant ainsi l’information capturée ; un réglage trop prudent conduirait à une convergence lente et à un sur-ajustement. L’entraînement des couches de classifieur se fait donc par une approche que l’on appelle gradual unfreezing qui permet d’éviter l’oubli des connaissances qui ont été déjà acquises grâce au LM.
Gradual unfreezing : fine-tuner toutes les couches à la fois risquerait de provoquer un « oubli catastrophique » – une perte de toutes les connaissances acquises dans les couches pré-entraînées. A la place, on freeze l’ensemble des couches du modèle – on fixe les paramètres de chacune des couches pour les rendre insensibles à un nouvel entraînement – avant de les unfreeze progressivement à partir de la dernière couche, cette dernière contenant les connaissances les plus spécifiques. A chaque étape on dégèle une nouvelle couche et on fine-tune l’ensemble des couches dégelées.
Finalement, pour pouvoir réaliser le fine-tuning de classifieur de manière optimale, avec des documents de texte de taille très grande, on utilise BPT3C.
BPTT for Text Classification (BPT3C) : dans le cadre de RNN, l’algorithme classique de backpropagation est adapté en backpropagation through time (BPTT). Il s’agit de l’application de la backpropagation sur le RNN déplié dans le temps ce qui permet notamment l’entraînement sur des séquences d’entrée de taille différente. Les LMs sont donc généralement entraînés avec la BPTT pour permettre la propagation par gradient pour de grandes séquences d’entrée. Afin de pouvoir permettre le fine-tuning de classifieurs sur des documents volumineux, le document est divisé en lots de tailles fixes. A chaque lot le modèle est initialisé avec l’état final du lot précédent et une trace des états cachés avec max-pooling et mean-pooling. Les gradients sont rétropropagés aux lots dont les états cachés ont contribué à la prédiction finale.
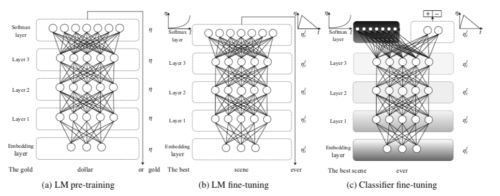
Figure 3 : architecture du modèle et méthodes de fine-tuning appliquées lors des 3 étapes.
4. Perspectives avec ULMFiT
ULMFiT est une méthode de transfer learning robuste applicable à n’importe quelle tâche de NLP. Plusieurs techniques de fine-tuning y sont introduites afin d’éviter tout oubli catastrophique et de permettre un apprentissage robuste sur une grande diversité de tâches. ULMFiT sera particulièrement utile dans les cas suivants :
NLP pour les langues autres que l’anglais, où les données d’entraînement pour les tâches de pré-entraînement supervisées sont rares,
Les nouveaux problèmes de NLP pour lesquels il n’existe pas encore d’architecture à l’état de l’art,
Les problèmes de NLP présentant des quantités limitées de données labellisées (et une quantité raisonnable de données non-labellisées).
ULMFiT commence déjà à avoir des impacts concrets en permettant par exemple des avancées sur les corrélations radiologiques-pathologiques dans le domaine de la santé [3].
Dans son souci d’appréhension de l’état-de-l’art de la discipline, Quantmetry a développé au sein de son pôle d’expertise NLP la connaissance nécessaire pour appliquer ULMFiT sur des cas d’usages réels et répondre aux problématiques les plus complexes rencontrées par ses clients.
✍Rédigé par Tom Stringer & Sang-hoon Yoon
[1] J. Howard and S. Ruder, “Universal Language Model Fine-tuning for Text Classification”, 2018.
[2] T. Mikolov, I. Sutskever, K. Chen, G. Corrado and J Dean, “Distributed Representations of Words and Phrasesand their Compositionality”
[3] R. Filice, “Deep-Learning Language-Modeling Approach for Automated, Personalized, and Iterative Radiology-Pathology Correlation,“ in Journal of the American College of Radiology, 2019.
