

Data : les utilisateurs et leurs besoins

Cet article fait partie d’une série d’articles co-rédigés par Emmanuel Manceau (Quantmetry), Olivier Denti(Quantmetry) et Magali Barreau-Combeau (OVH) sur le sujet « Architecture – De la BI au Big Data ».
Il existe 4 grandes populations d’utilisateurs ayant des besoins en données (hormis les acteurs de l’IT qui sont amenés à traiter les données pour les rendre disponibles aux utilisateurs).
Qui utilise les données du data lake ?
Data Analyst
Le Data Analyst est amené à évaluer les données via un raisonnement analytique et logique ; il va fouiller dans les données (data mining), les préparer (data crunching), les visualiser (DataViz) pour extraire un set de données (ex : clients à cibler dans une campagne commerciale à partir de certains critères) ou pour expliquer un fait (ex : pourquoi les ventes de juin sont-elles faibles ?).
Ces populations sont formées à utiliser les bases de données relationnelles et décisionnelles, ainsi que créer des requêtes d’extraction et d’exploration de données. Elles peuvent rebasculer sur des outils de manipulation de données, créer des dimensions d’analyse pour faciliter l’exploration des données.
Data Scientist
Le data scientist est un nouveau métier apparu cette décennie avec l’émergence du BigData. En plus des activités propres au Data Analyst, le Data Scientist est amené à produire de nouvelles données à partir de modèles type « Machine Learning ». Par exemple : produire un score de risque client, prédire les ventes des 3 prochains mois, évaluer la satisfaction des clients à partir de leurs mails etc.
Le Data Scientist connait l’ensemble des techniques de persistance de l’information (bases relationnelles, HDFS, NoSQL) et connait parfaitement les techniques de requêtage et d’extraction de l’information. Le SQL fait un retour en force depuis que l’écosystème Hadoop a adopté des techniques proches du SQL comme Hive ou SparkSQL. Enfin, il connait aussi les langages de programmation (Python pour Pandas, Java ou Scala pour manipuler des dataframes Spark) pour transformer les données (généralement sous forme de matrices).
Business Analyst
Le Business Analyst est un opérationnel d’un métier considéré qui reprend le travail d’un Data Analyst pour l’exploitation courante de la donnée et satisfaire les demandes régulières de son métier.
Il s’agit d’utilisateurs ayant un usage avancé (à la fois technique et fonctionnel) de la donnée. Ils peuvent ajuster des requêtes déjà préparées, voire construire des requêtes SQL (requêtage ad-hoc), sont capables d’établir un rapport/dashboard à partir des données déjà préparées, manipuler les données dans un tableau et créer du code de traitement de l’information (macro ou encore via des outils de DataViz) et de mettre tout cela à disposition de leur propre métier.
Utilisateurs finaux
Les utilisateurs finaux sont des « consommateurs » de données mises à leur disposition ; les interactions avec les données sont limitées par l’application de DataViz ou bien par le set de données déjà préparé qui leur a été fourni.
Compétences exigibles
Compte tenu des caractéristiques et des compétences attendues pour chacune de ces populations, nous pouvons évaluer leur utilisation des fonctions d’accès à la donnée pour chacun des rôles.

Compétences attendues par profil utilisateur Big Data
Accès à la donnée
Tous les utilisateurs n’ont donc pas à vocation à requêter directement dans la base du BigData, qui peut avoir des contraintes opérationnelles (traitements sur de très gros volumes de données à finaliser pour telle heure), des contraintes techniques (temps de réponse d’une requête relativement long) ou qui contient des données dont la valeur informationnelle unitaire est très faible.
L’information est donc organisée par étages successifs qui consolident et simplifient l’accès à l’information, de la plus brute à la plus consolidée comme décrit dans le schéma suivant.
Construction des étages d’accès à la donnée
L’étage le plus bas peut accueillir n’importe quel type de donnée (structurée, image, texte, sons) puis cette information est synthétisée, simplifiée, enrichie à mesure qu’on monte dans les étages : sa valeur métier va croissante.
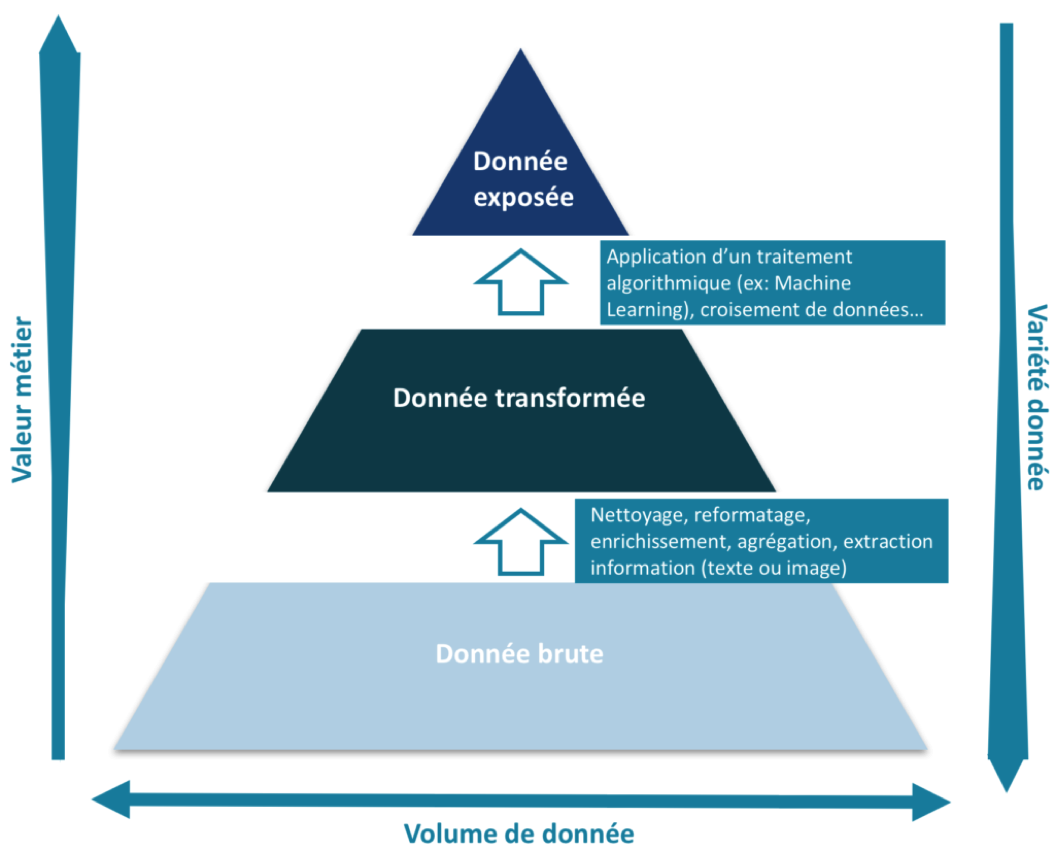
Au niveau le plus bas, on peut imaginer trouver l’ensemble des tickets de caisse d’une chaine de grande surface, au niveau le plus haut le chiffre d’affaires annuel avec différents axes d’analyse (comme la catégorie socio-professionnelle, obtenue notamment en croisant le ticket de caisse avec les cartes de fidélité).
Accès aux données brutes
L’accès aux données brutes du datalake est essentiellement réservé au datascientist qui met en place la chaîne d’acquisition des données (événements en temps réel, fichiers etc.) et de contrôle qualité (format du fichier, nombre de colonnes / lignes etc.).
A noter qu’on utilise des techniques de traitement d’image ou du langage pour extraire de l’information structurée à partir de sources d’information semi ou non structurées (image, texte, son) du datalake. Il peut s’agir d’identifier des mots, identifier des formes dans des images ou encore détecter des sons particuliers. L’objectif ici est d’extraire de l’information utile du support brut. Par exemple, pour interpréter un niveau de satisfaction client, on interprète des commentaires que l’on classe en catégories (content / pas content) qui sont ensuite intégrées dans une information structurée.
Accès aux données transformées
Les données transformées sont issues des données brutes auxquelles une série de traitements spécifiques (pipeline) est appliquée pour nettoyer, enrichir voire agréger les données. Pour cela, le Data Engineer travaille avec un référent métier / Data Manager (qui connaît les données produites sur son périmètre d’activité) et les autres acteurs pour recueillir leurs besoins.
Dans l’industrie minière, il faut traiter quatre tonnes de terre pour extraire quatre grammes d’or pour les mines les plus productives : Le Data Engineer est ici un mineur qui doit lui aussi extraire d’un grand volume de données, une information à forte valeur ajoutée. Il nous est arrivé de passer d’un dataset comptant des milliards de lignes à un dataset de quelques milliers.
A titre d’exemple, une donnée brute est une mesure de capteur physique produite toutes les millisecondes par un parc de mille capteurs. La donnée transformée peut être :
-
une donnée enrichie via des référentiels (localisation du capteur, type de capteur etc.) ; le niveau de détail est alors maximal
-
une donnée enrichie et agrégée sur un ou plusieurs axes (ex : moyenne de la valeur agrégée par « ville ») ; le niveau de détail est plus « macro » mais reste compatible avec ce qui est demandé par les utilisateurs.
Le Data Engineer connait les techniques de traitement de données volumineuses et les caractéristiques des architectures parallèles et distribuées ; les autres acteurs n’ont pas forcément les connaissances informatiques propres à ces environnements.
Le Data Analyst est à même de mieux comprendre les données et leurs relations. Il va donc utiliser des outils de visualisation pour naviguer dans cette couche et rechercher notamment des signaux faibles, des liens cachés et des corrélations.
Accès aux données exposées
Comparativement à la donnée transformée, la donnée exposée répond à une problématique particulière (cas d’usage) ou est suffisamment préparée pour être directement mise à disposition à un large éventail d’acteurs.
Le plus souvent, les données exposées sont consolidées dans des bases plus classiques (SGBDR) et interrogeables par des analystes n’ayant pas de compétences trop poussées en informatique. L’accès se fait donc avec les instruments habituels des analystes (SAS, PowerBI, Qlik, Tableau…)
Pour reprendre l’exemple précédent, la donnée exposée serait mise en regard avec la maintenance des équipements (pose, réparation, surveillance). De la sorte, nous serions en mesure d’identifier des causes potentielles d’anomalies dans le parc et d’expliquer pourquoi certaines mesures sont en écart. Ces données résultent de croisements et se voit appliquer des calculs métiers (KPI) et sont exposées le plus souvent dans des outils de pilotage opérationnel.
Vers une vision unifiée et partagées des données
Tout l’enjeu de l’architecture data est de faire en sorte que les accès à ces familles de données s’appuient sur les mêmes données et sur une plateforme technique commune. Or, trop souvent, les datalakes sont construits à côté des entrepôts BI et la même information est dupliquée en de multiple endroits créant ainsi des incohérences et la perte de traçabilité de l’information.
Le pari réussi d’OVH est précisément d’avoir obtenu la centralisation de l’ensemble des informations et de faire en sorte que les vues décrites ci-dessus s’appuient sur les mêmes données et la même architecture logicielle. Business Analyst et DataScientist travaillent sur les mêmes données, et le datalake a supplanté les entrepôts BI pour servir l’ensemble des besoins.
