

Les données personnelles c’est comme les légumes, il vaut mieux les hacher avant de les cuisiner

L’occasion de refaire un point sur l’anonymisation et la pseudonymisation et en particulier sur la méthode de « hashing ».
Anonymisation, pseudonymisation…
Lorsqu’une entreprise collecte et utilise des données personnelles, elle a l’obligation de préserver la confidentialité des individus. Pour cela plusieurs méthodes existent avec des niveaux de protection plus ou moins forts et contraignants.
Les méthodes d’anonymisation sont les plus fiables. L’objectif : que personne ne puisse remonter à l’identité de l’individu avec les données traitées. L’exemple le plus simple d’anonymisation consiste à supprimer directement toutes les données personnelles sans possibilité de les récupérer (ou remplacer les données par des chaînes de caractère aléatoires) mais cette méthode radicale génère forcément une perte d’information importante !
3 critères sont utilisés pour évaluer une méthode d’anonymisation :
- L’individualisation : peut-on isoler un individu grâce aux données traitées ?
- Par exemple, une base présentant le nom, prénom et date de naissance des personnes permet de manière évidente de remonter à l’identité des personnes
- La corrélation : peut-on rattacher plusieurs informations de bases indépendantes à un individu ?
- Par exemple deux bases présentant des numéros de client avec d’autres données peuvent être rapprochées grâce au numéro de client
- L’inférence : peut-on déduire des informations personnelles avec une probabilité élevée ?
- Par exemple, une base présentant activités professionnelles et ville permet de remonter à l’individu s’il n’y a qu’un seul boucher ou courtier en assurance dans la ville
Ces 3 règles paraissent intuitives mais sont en réalité très difficiles à mettre en œuvre. Il existe en effet aujourd’hui (et il existera de plus en plus) tellement de données massives publiques qu’il sera de plus en plus difficile (impossible ?) de garantir les critères d’inférence ou de corrélation. En effet, comment prouver que sur toutes les bases existantes dans le monde aucune ne permette de faire d’inférence sur un individu ? Google propose depuis peu un moteur de recherche de dataset (Google DataSet Search), et il serait illusoire de les passer tous en revue pour garantir ces critères. En particulier, Arvind Narayanan avait réussi dès 2006 à identifier des individus au sein d’une base de données « anonymisées » de Netflix, en recoupant les appétences pour des films à des commentaires postés sur des sites publics. C’est un exemple inoffensif mais qui peut tout de même inquiéter. Les traitements d’anonymisation sont donc limités et les 3 critères difficiles à démontrer, mais permettent tout de même de rendre la tâche plus difficile aux personnes mal intentionnées.
Dans le cas où il est important de pouvoir identifier les individus concernés par le traitement des données, les méthodes de pseudonymisation peuvent être recommandées. Elles sont cependant (encore) moins sécurisées. En effet, l’idée est ici que seules les personnes ayant accès à une clé ou table de pseudonymes (la plus complexe possible) puissent remonter de la donnée à l’individu. Mais l’existence même de la table de correspondance ou de la clé crée une faille supplémentaire. Si l’on veut une sécurité optimale, il « suffit » donc de se débarrasser de la clé ou de la table et d’être sûr que personne ne s’en souvienne ce qui revient donc à anonymiser les données…
Le hashing
Le hashing est une technique au carrefour de la pseudonymisation et de l’anonymisation. Ici pas besoin de table de correspondance pseudonyme/identité ou de clé de passage de l’un à l’autre. Le hashing repose sur des fonctions mathématiques particulières appelées fonctions à sens unique (il s’agit donc d’une clé qui n’ouvre la porte que dans un sens).
Par exemple, si pour une donnée ‘A’, la fonction de hashing renvoie le pseudonyme ‘B’, une personne tierce qui voit ensuite ‘B’ dans le jeu de donnée, même si elle connaît la fonction utilisée, ne sera pas capable de savoir que l’information d’origine était ‘A’.
Lorsqu’il s’agit d’une correspondance entre 2 lettres, il suffit d’essayer la fonction sur tout l’alphabet pour identifier quand celle-ci renvoie ‘B’. Il faut donc considérer en « entrée » de la fonction une chaîne plus complexe, par exemple « NomPrénomDatedenaissanceCodepostal ». On applique ensuite la fonction de hashing qui renverra par exemple « 5fgghb678TcfhvnB6 ». J’ai ainsi un identifiant unique généré pour une personne qui contient implicitement son identité.
Pourquoi ne pas simplement générer un numéro d’identifiant aléatoire ?
Grâce au principe de hashing, si l’on doit anonymiser deux fois la même personne, on retombera sur le même identifiant (sous réserve d’utiliser la même fonction de hashing bien sûr). Par exemple pour une étude portant sur les utilisateurs d’un site X et d’un autre Y, il devient possible de travailler sur des données non personnelles tout en recoupant les utilisateurs. Je saurai, sans connaître son identité, qu’un même internaute a navigué sur les deux sites et je pourrai comparer ses comportements.
Nous avons déjà expliqué que, même en connaissant la fonction utilisée, il était impossible de remonter à l’individu (c’est le principe de l’irréversibilité de la fonction). Cependant, en connaissant la fonction de hashing utilisée, il serait envisageable pour un ‘data pirate’ d’essayer des attaques par force brute (tenter toutes les combinaisons, comme nous le suggérions lorsqu’il n’y avait qu’une lettre codée) ou par dictionnaire (tenter des combinaisons probables, par exemple appliquer la fonction connue sur « BernardDupond » si l’on sait que l’un des individus dont les données ont été cryptées s’appelle Bernard Dupond. Il suffit ensuite de comparer le résultat avec les identifiants hashés. D’où l’intérêt de choisir une combinaison complexe de données personnelles avant de faire fonctionner la fonction de hashing.
Pourquoi utiliser un tel processus de pseudonymisation ? Un cas concret
Trois entités d’un même groupe fonctionnent séparément avec 3 bases de données clients différentes. Elles souhaitent bâtir une segmentation client pertinente commune, sans divulguer l’identité ou les autres données personnelles de l’ensemble de leurs clients aux autres entités.
Il est possible, en restant conforme à la législation, de proposer le dispositif suivant :
Pseudonymisation par hashage des données personnelles pour recouper les clients communs sans expliciter leur identité
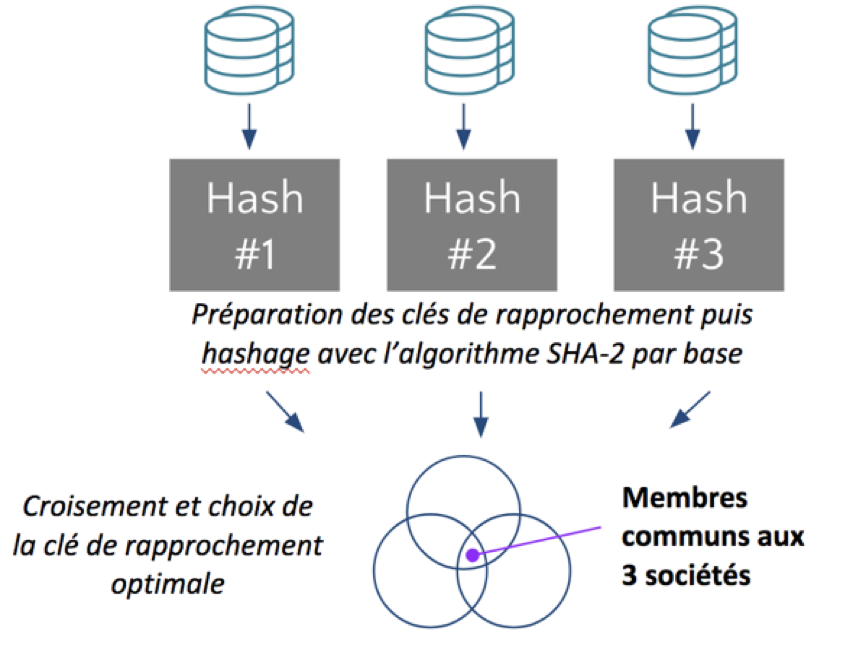
Ce process permet d’effectuer les recoupements et analyses à la maille individu, sans identifier ces individus. La clé de rapprochement mentionnée ici est une combinaison de données personnelles du type ‘NomPrénomCodePostalDateDeNaissance’ qui permet, une fois hashée, d’effectuer le rapprochement des bases sans expliciter la donnée personnelle.
A retenir :
- L’anonymisation repose sur 3 critères individualisation, corrélation et inférence
- Il est difficile (et il le sera toujours plus !) d’anonymiser rigoureusement des données selon ces 3 critères
- Le Hashing est une technique permettant de travailler sur des données pseudonymisées avec un premier niveau de sécurité garantissant le critère d’individualisation
✍Écrit par Olivier Wautier
Source :
https://www.cnil.fr/fr/le-g29-publie-un-avis-sur-les-techniques-danonymisation
