

Evolution des outils et méthodes de Forecast : quelles perspectives pour le S&OP de demain ?

Le forecast, c’est quoi?
Combien de sodas de ma marque A vont être vendus cet été à Paris ? Combien de smartphones bleus nouvelle génération vais-je vendre sur mon site e-commerce ?
Le forecasting est un processus utilisant des données historiques en entrée afin d’établir la prévision (un forecast) d’une quantité dans un horizon temporel donné. Beaucoup de forecasts peuvent être produits à l’échelle d’une entreprise, mais tous sont vus sous plusieurs angles d’analyse :
- la maille temporelle (veut-on prévoir à la semaine, au jour, à l’année),
- la maille produit (veut-on prévoir le modèle, l’article, la gamme, les quantités par magasin…)
- parfois la maille géographique (total des ventes EMEA, nombre de produits vendus à Paris…).
Dans un contexte Retail, un forecast correspond par exemple à une quantité d’articles que nous prévoyons de vendre à un certain client, à un instant t, sur un marché précis et à un prix défini. C’est une donnée d’entrée du processus S&OP (Sales & Operation Planning), processus stratégique et collaboratif de l’entreprise visant à adapter les capacités de production à la demande. L’idée est d’opposer une prévision non contrainte à un capacity planning afin d’obtenir dans un premier temps un « consensus forecast » entre les différentes fonctions impliquées. C’est donc un moyen par la suite de prévoir les approvisionnements et stocks nécessaires, les flux logistiques et le budget associé. Le processus S&OP tend à se généraliser dans les entreprises, même s’il existe des grands groupes qui ne le pratiquent pas encore. La fiabilité de la prévision produite représente un enjeu économique fort pour l’entreprise : en cas de surestimation, il y aura un risque de sur-stockage et donc des coûts supplémentaires et des risques d’obsolescence; et en cas de sous-estimation il y aura un risque de rupture de stock et donc de perte de chiffre d’affaires et d’insatisfaction client.
Le forecast, la clé de voûte du processus S&OP
Il peut y avoir un forecast réalisé en central par un prévisionniste et qui est le résultat d’un processus collaboratif entre plusieurs acteurs (Marketing, Ventes, Production, Finance, Achats, Planification…), ou bien plusieurs forecasts, par exemple un par département, qui dépendent alors des hypothèses prises par chaque métier. Lorsque la prévision est collaborative, le but est d’obtenir un compromis entre les objectifs de chacun des acteurs, qui sont parfois divergents. Par exemple l’équipe Production souhaitera minimiser les niveaux de stock et optimiser les coûts, alors que l’équipe Ventes souhaitera garantir un chiffre d’affaires par compte et obtenir la satisfaction du client.
Lorsque chaque département établit sa propre prévision, celle-ci risque d’être biaisée puisqu’elle prendra seulement en compte les objectifs dudit département. Également si la prévision n’est pas partagée, il y aura une désynchronisation entre capacité et demande, le plan de production correspondra uniquement aux contraintes de ressources humaines et machines et non à la demande.
Une équipe de Prévision indépendante permet globalement d’éviter les biais dans la prévision. D’après le benchmark réalisé par l’Institute of Business Forecasting, 36% des entreprises positionnent la fonction Forecast au sein de la Supply chain, là où finalement se trouvent les principaux acteurs de la prévision, alors que 14% la positionnent dans une équipe indépendante.
Enfin, le Service Après-vente ne fait aujourd’hui pas partie du processus de prévision. Celui-ci est pourtant au contact direct des fluctuations de la demande : problème de frêt, affectation des livraisons dues à des emballages spéciaux, changements dans les habitudes de commandes des clients, mise en place d’un nouveau système d’information client… Une piste serait donc que le Service Après-vente fasse partie du processus S&OP apportant ainsi une perception terrain de la demande.
Les prérequis d’une bonne pratique du forecast
Le cycle de vie du produit doit être pris en compte dans la prévision, chaque phase nécessite une méthode adaptée :
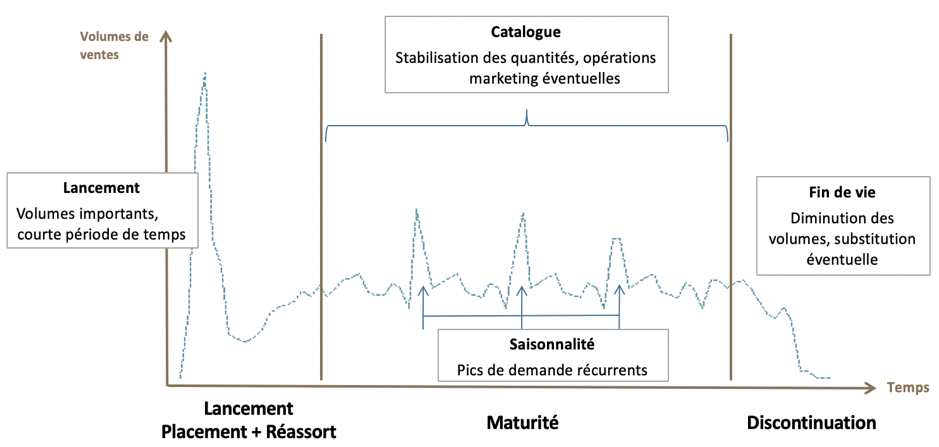
L’une des grandes difficultés du métier de prévisionniste réside dans la prévision du volume de ventes d’un nouveau produit. Il n’y a alors pas de baseline existante, et il est fréquent que les équipes Marketing voient grand pour ce nouveau produit. Il est donc nécessaire de comprendre le positionnement, la stratégie et le potentiel de ce produit en collaboration avec l’équipe Marketing. Un benchmark avec des lancements similaires sera d’une grande aide pour définir les quantités de placement et les quantités de réassort ; cela peut même aller jusqu’à trouver le cluster de produits similaires en termes de typologie, gamme, prix, etc…à l’aide de méthodes Machine learning.
Définir la bonne maille d’agrégation auquel la prévision doit être faite, est une étape clé qui influencera fortement la fiabilité de la prévision. La maille d’agrégation idéale est en général une combinaison entre niveau de hiérarchie produit, segmentation client et zone géographique. Travailler à un niveau agrégé permettra en effet de bénéficier d’un effet de lissage : selon les contextes, il est plus facile de prévoir la quantité par type de produit, par sous-marque ou par gamme par exemple que par référence. Cela nécessitera ensuite d’éclater la prévision pour retomber sur les niveaux les plus fins.
L’horizon de prévision dépend de la nature de l’entreprise : l’industrie aéronautique n’a pas besoin de faire des prévisions à la semaine par exemple mais une prévision à long terme est nécessaire car le coût d’investissement total est élevé. Généralement l’horizon du plan S&OP est de 12 à 18 mois. La maille temporelle de prévision peut être au mois ou à la semaine si la demande fluctue d’une semaine à l’autre (particulièrement vrai dans l’agroalimentaire). La prévision court terme est en tout cas nécessaire pour gérer au mieux les stocks et les ressources de production.
Il est fréquent de voir des classifications ABC permettant au prévisionniste de se focaliser sur les produits stratégiques de classe A : ce sont les produits qui représentent 80% de la valeur de stock et 20% du nombre total d’articles. Parmi ces produits il peut être pertinent de se restreindre à ceux présentant une forte volatilité, afin de rentabiliser au mieux le temps de travail du prévisionniste. Il est également fréquent de voir certains produits phares comme devant être absolument présents en magasin : dans ce cas, une prévision à la baisse pourrait avoir un impact néfaste sur l’image de marque, il faut alors augmenter artificiellement la prévision obtenue pour éviter les ruptures de stock.
Enfin depuis quelques années, la notion de DDMRP (Demand Driven Material Requirement Planning) émerge. C’est une nouvelle vision de la planification multi-niveaux basée uniquement sur la demande : il s’agit d’une méthode qui vise à positionner les stocks de manière stratégique et à les ajuster dynamiquement en fonction de la demande. Cette méthode couplée à une prévision de la demande fiable a tous les atouts pour faire face aux fluctuations des marchés actuels.
Quelles données pour une prévision fiable?
Les modèles de forecast doivent être alimentés par des données cohérentes et exactes. Les données issues des ERP sont très riches mais sont limitées aux données opérationnelles de l’entreprise. Les données produites en dehors des systèmes d’information de l’entreprise sont également nécessaires et de grande valeur : données des fournisseurs, données liées à des événements extérieurs, données de la concurrence, données générées dans les points de vente, données des réseaux sociaux… L’écoute de ces signaux de demande supplémentaires et leur intégration au forecast correspond au demand sensing. Finalement les modèles construits sur des données de mauvaise qualité fourniront des mauvaises prévisions et des mauvaises décisions, la méfiance dans l’algorithme naîtra et les équipes reviendront naturellement aux anciennes méthodes de prévision. La nécessité d’utiliser de larges quantités de données de bonne qualité montre à quel point la gestion des Master data de la Supply chain devient un sujet critique.

Méthodes & outils couramment utilisés aujourd’hui
Malheureusement aujourd’hui la plupart des entreprises n’ont pas fait évoluer leur méthode de Forecast sur les 30 dernières années. Ce sont bien souvent des fichiers Excel qui sont utilisés par les prévisionnistes, et il est peu fréquent de voir des modèles de Forecast qui combinent historiques de ventes et données prévisionnelles sur les lancements et promotions produits par exemple.
De nombreux APS (Advanced Planning and Scheduling) ont inondé le marché : SAP APO, FuturMaster, Dynasys, Azap, Oracle SCP, Vekia, TXT, … et certaines entreprises se sont tournées vers ces solutions. Elles présentent en général un ensemble de modules allant de la prévision des ventes jusqu’à l’approvisionnement et à la distribution. Des modèles traditionnels comme le lissage exponentiel, ARIMA ou Holt Winters sont généralement utilisés dans ces logiciels. Cependant, les hypothèses de distribution normale et d’indépendance entre variables qui sont utilisées par ces modèles sont globalement erronées, et des méthodes plus avancées s’avèrent donc nécessaires.
En ce qui concerne l’évaluation du forecast, celle-ci s’effectue selon la justesse de la prévision (accuracy). Une analyse fine de l’erreur de prévision en fonction de l’horizon temporel prédit est souvent nécessaire pour s’assurer de la qualité du forecast sur tous les horizons ou, au contraire, ajuster son niveau de confiance et les décisions stratégiques prises en fonction de l’erreur observée. En complément de la justesse de prévision, une bonne pratique trop souvent négligée est de coupler cette mesure à un intervalle de confiance. En effet, l’incertitude autour de la valeur prédite est tout autant, voire plus importante, que la valeur prédite elle-même, selon les contextes métiers. Comme le souligne George Box ce qui compte c’est l’utilité du modèle au regard de la réalité : “All models are wrong. Some are useful.”
Quelle que soit la solution utilisée, la majorité des entreprises utilisent seulement un ou deux modèles et en changent très rarement pendant le cycle de vie du produit. La révision du forecast doit être faite lorsqu’un changement notable a été identifié par une source de données ou lors d’un changement de phase du cycle de vie du produit, et doit avoir un réel impact : inutile de revoir un forecast alors que le plan S&OP a été verrouillé pour le prochain mois.
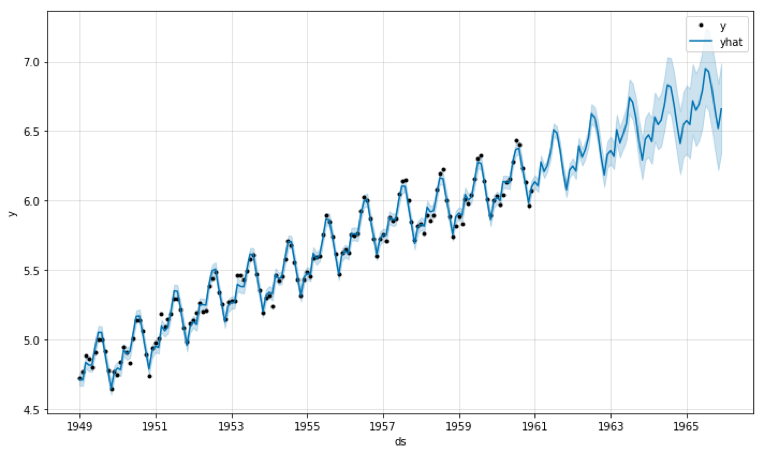
Série temporelle et forecast avec son intervalle de confiance associé sur un dataset classique : AirPassengers
Nos convictions sur l’avenir du forecast
A l’ère de la hype du machine learning, il est de plus en plus courant de voir s’ajouter aux modèles black box des solutions sur étagères, des modèles de forecast mis en production basés sur des modèles de machine learning pur. Choisir une telle approche, bien que tentante, serait oublier plus de quarante ans de recherche dans le domaine des statistiques sur la modélisation des séries temporelles pour le forecasting. Bien que donnant parfois des résultats intéressants, les modèles de machine learning sont soumis à des problématiques d’overfitting qui offrent en phase d’inférence des résultats moins probants.
Notre conviction chez Quantmetry – d’allier machine learning et méthodes statistiques pour le forecasting– a récemment été confirmée par la communauté scientifique spécialisée sur le sujet lors de la compétition M4, qui a eu lieu en 2018. La compétition M4 est la 4ème édition d’une compétition internationale de forecasting, sur des milliers de séries temporelles aux propriétés très hétérogènes. Un résultat intéressant de cette compétition est que sur les 17 méthodes les plus performantes parmi les soixante en lice, 12 étaient issues de combinaisons de méthodes statistiques. Autre résultat : les six méthodes uniquement basées sur du machine learning finissent en bas de tableau, et pire, aucune d’entre elles n’a réussi à battre le benchmark composé d’une combinaison de modèles statistiques simples. En terme de performance pure, la méthode gagnante de cette compétition permet d’obtenir une SMAPE (symmetric mean absolute percentage error) de près de 10 % plus précise que le benchmark utilisé pour comparer les méthodes soumises, ce qui a particulièrement retenu l’attention de la communauté scientifique.
Une autre conviction forte que nous portons est que le forecasting doit être considéré comme une compétence spéciale à part entière : en effet, peu de data scientists formés sur le marché sont initiés au concept de forecasting et aux méthodologies spécifiques qui lui sont associées, et notamment aux enjeux d’interprétabilité du forecast. On pourrait faire un parallèle avec les moteurs de recommandation ou le domaine de l’analyse d’images, qui requièrent – eux aussi – des compétences et techniques spécifiques, accompagnées d’une veille constante afin de pouvoir rester à l’état de l’art.
Aujourd’hui nous sommes donc convaincus que la fonction Forecast est cruciale dans l’entreprise, et qu’elle requiert plus que jamais des compétences alliant Statistiques et Machine Learning, mais aussi la capacité à préparer la donnée et à tester les hypothèses venant des différents acteurs du Forecast.
Nous traiterons dans de prochains articles de manière plus complète les aspects de combinaisons entre méthodes machine learning et méthodes statistiques, et nous reviendrons plus en détails sur les approches gagnantes de la compétition M4.
 Ecrit par : Guillaume Hochard et Charlotte Ledoux
Ecrit par : Guillaume Hochard et Charlotte Ledoux
Bibliographie
- Sales Forecasting by Susan Ward – https://www.thebalancesmb.com/sales-forecasting-2948317
- Benchmarking Forecasting Practices: A Guide to Improving Forecasting Performance By Chaman L. Jain, Jack Malehorn – https://hal-mines-albi.archives-ouvertes.fr/hal-01968744/document
- Journal of Business Forecasting Volume 38 | Issue 1 | Spring 2019 – https://ibf.org/
- Makridakis, Spyros & Spiliotis, Evangelos & Assimakopoulos, Vassilis. (2018). The M4 Competition: Results, findings, conclusion and way forward. International Journal of Forecasting. 1016/j.ijforecast.2018.06.001.
