

IoT Data Platform Factory appliquée au “Smart Mobility”
Quantmetry accompagne un acteur mondial des transports dans la mise en oeuvre d’une plateforme IoT sur Azure, afin de proposer à ses clients des services innovants autour de l’exploitation et la valorisation des données, au bénéfice des voyageurs.
Notre Client, acteur mondial de 1er plan dans le secteur des transports, s’est lancé depuis quelques années dans le “Smart Mobility”, pour répondre aux besoins des voyageurs (meilleure ponctualité, amélioration de l’information voyageur, intégration dans un contexte multimodal) et répondre aux exigences des opérateurs locaux (fluidité du trafic, disponibilité, efficacité etc.)
L’objectif de la prestation menée par Quantmetry est d’offrir à son Client, ses partenaires et Clients une plateforme permettant d’acquérir, traiter et exposer les données produites dans le cadre d’un projet (un “projet” correspondant à une ligne ferroviaire par exemple).
Diversité des données manipulées
Données produites par le matériel du Client :
- capteurs des matériels roulants (vitesse, température, état de fermetures des portes etc.)
- capteurs des matériels au sol (aiguillage notamment) ou en gare
Données fournies par les partenaires :
- les trajets et horaires (“missions”)
- billetterie
Données de type “3rd party” ou “open data” comme :
- météo, pollution
- trafic automobile sur les zones opérées
- événements locaux (concert, exposition etc.)
L’ensemble de ces données entrent en jeu dans le cadre du “Smart Mobility” :
- un événement exceptionnel (comme un concert) peut nécessiter un afflux de passagers ponctuellement avant et après l’événement et nécessiter des moyens de transport supplémentaires
- un pic de pollution, entraînant une limitation du trafic routier, entraîne un surcroît de voyageurs durant la journée
- un incident sur une ligne peut nécessiter un redéploiement de transport d’un “autre mode”, comme des cars
- minimiser les incidents en cours de mission en effectuant les opérations de maintenance de manière prévisionnelle
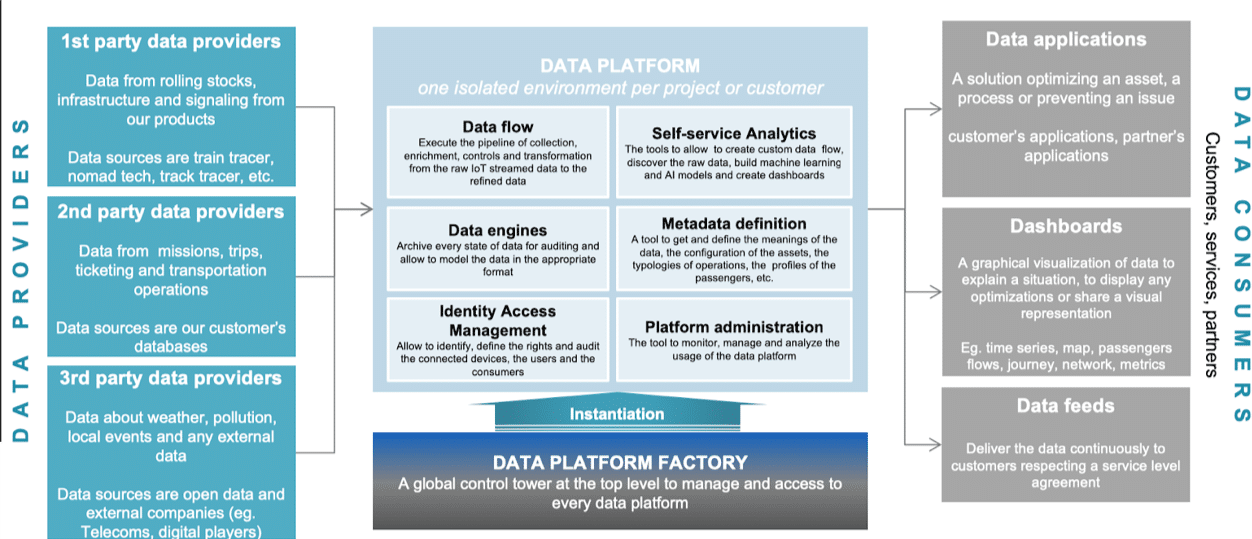
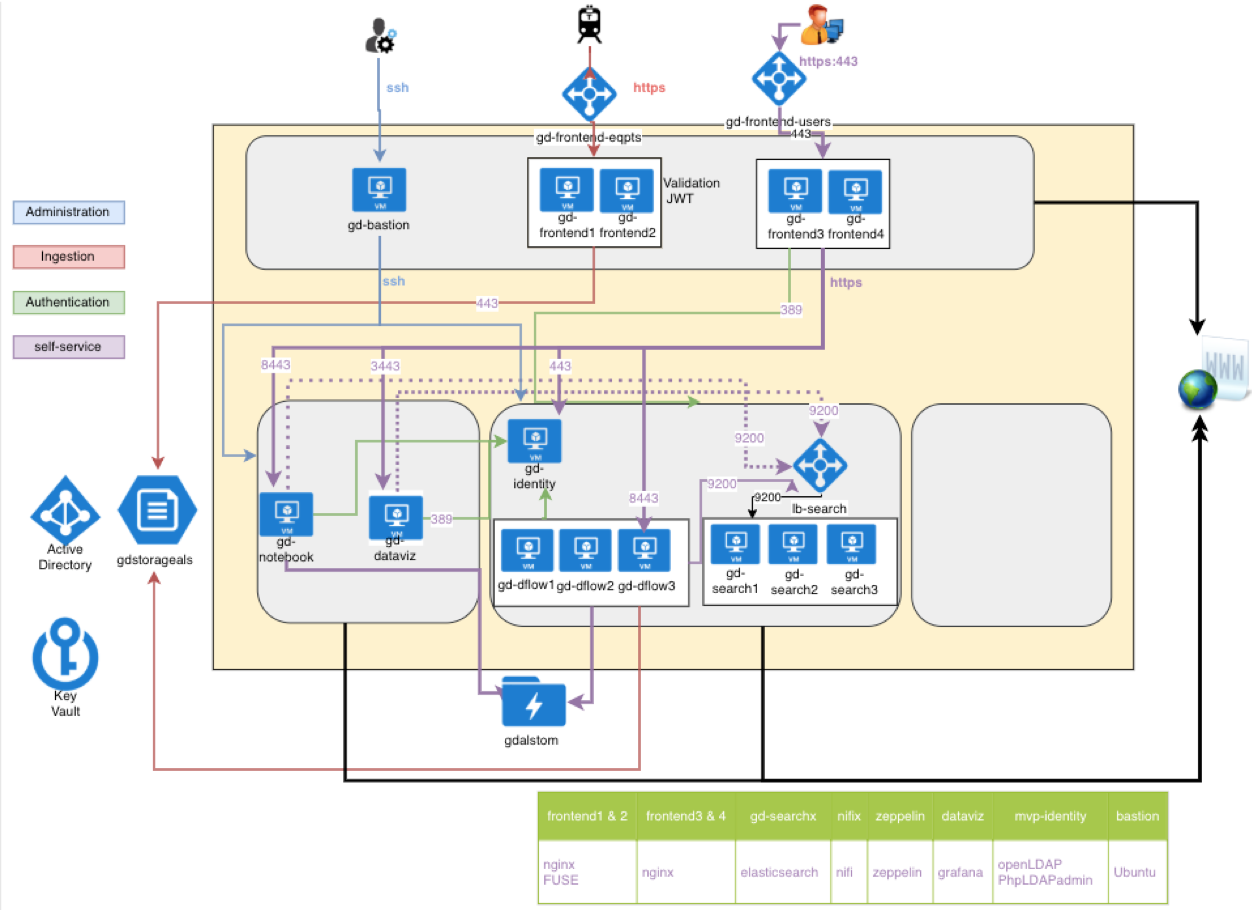
L’architecture fonctionnelle globale de la solution est la suivante :
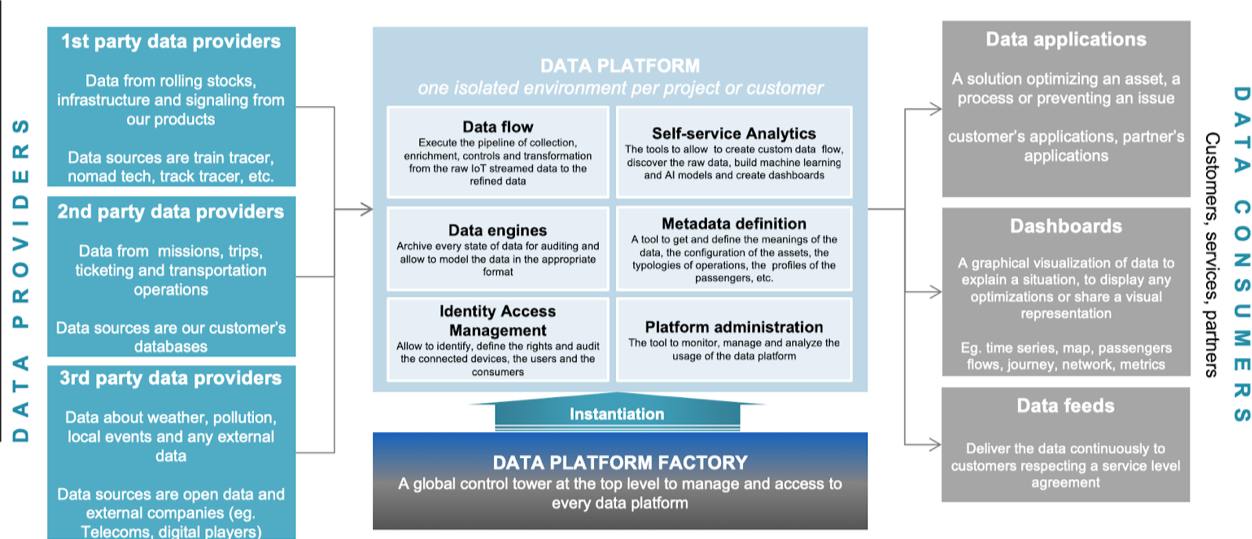
Pour des besoins liés à la réglementation, les données sont hébergées au plus près de leur lieu de “production”. Cela pose différentes exigences car notre Client est un acteur mondial présent dans plus de 50 pays et aucun fournisseur de “Cloud” n’est présent dans chaque pays où le Client opère.
Les choix technologiques retenus ont donc d’emblée exclu les solutions de type PaaS proposées par les Cloud provider, afin d’être en capacité d’héberger la solution sur tout type de Datacenter (on-premise ou Cloud public).
Afin d’accélérer la mise en place des plateformes pour chaque projet, la “reproductabilité” est le maître mot : “architecture as a code” permet cela en scriptant la mise en place (en quelques minutes) de l’infrastructure informatique et les briques logicielles nécessaires, via les briques “Terraform” et “Ansible”.
Afin de limiter les coûts, l’usage de solutions open-source est privilégiée.
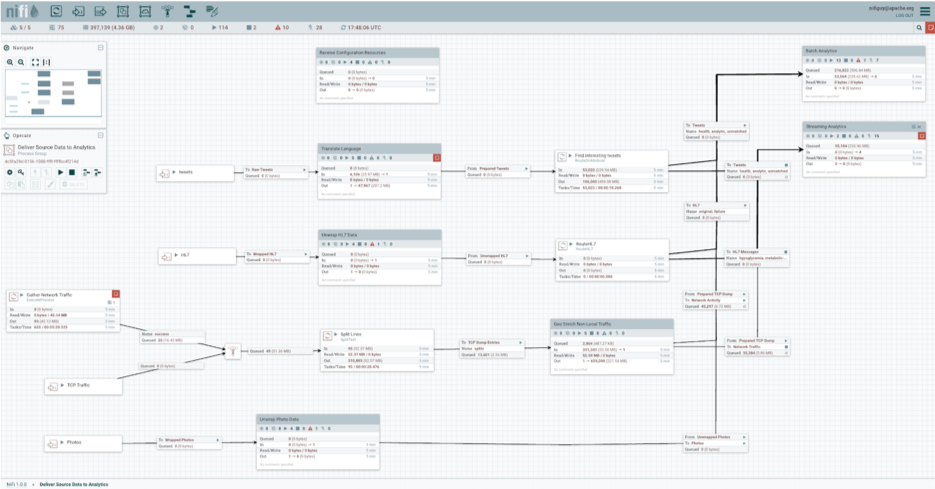
Les composants mis en oeuvre dans le cadre de ce démonstrateur sont les suivants :
- Data Flow : NiFi (https://nifi.apache.org/) est en développement actif au sein de la Fondation Apache, gage de pérennité. La richesse de ses connecteurs, les différents cas d’usage possibles (notamment temps réel et batch), la scalabilité proposée (mise en clusters) et la relative accessibilité de l’outil (la grande majorité de la configuration se fait via une interface Web) en font un choix idéal pour ce projet. Pour plus de détail, voir l’article d’Abdellah sur notre Blog.
- Stockage : HDFS. Les quantités de données ingérées par jour peuvent être importantes (centaines de Go), en fonction du nombre de matériels roulants opérant sur la ligne et afin de pouvoir réaliser des cas d’usage de type “maintenance prévisionnelle”, une profondeur d’historique de plusieurs années est nécessaire. La technologie HDFS permet de bénéficier d’une capacité de stockage quasi illimitée tout en offrant une tolérance aux pannes importantes, du fait de la réplication des données.
- Self-Service Analytics : Apache Zeppelin apporte au Data Scientist ou au Data Analyst une interface Web (notebook) permettant à chacun d’utiliser son langage favori pour traiter la donnée (R, Python, Scala, PySpark, SQL, requêtes JSON pour Elasticsearch…). Un cluster Spark est mis en oeuvre afin d’être en mesure de traiter de gros volumes de données.
- Acquisition des données IoT : Nginx est utilisé en tant que proxy permettant :
- être le point de terminaison pour la connexion chiffrée
- vérifier le JSON Web Token (JWT) (https://jwt.io/) afin de valider l’origine du message transmis
- Moteur de recherche / Analytics : Elasticsearch permet d’indexer de gros volumes de données et de pouvoir réaliser des requêtes complexes (de type agrégat) permettant notamment d’apprécier rapidement de la qualité des données (min, max, moyenne, écart type des valeurs prises par un capteur notamment).
- Data Vizualization : Grafana a été privilégié (plutôt que Kibana) du fait de la présence de nombreux connecteurs, permettant de s’interfacer avec de nombreuses sources de données (http://docs.grafana.org/features/datasources/), dont Elasticsearch.
Ce type de solution permet d’offrir de nouveaux services et d’ouvrir les possibilités de revenus en proposant par exemple un coût à l’usage (type abonnement), au volume de données manipulées (pour un usage ponctuel) etc.
Le challenge est d’être le 1er à proposer ce genre de services afin d’être en position de force et d’être un acteur incontournable afin de fédérer un maximum de partenaires.
