

La labellisation pour du NLP à forte valeur ajoutée

Les systèmes d’Intelligence Artificielle (IA) actuels sont extrêmement consommateurs en données. Les modèles de Deep Learning doivent souvent consommer des millions d’exemples pour apprendre et généraliser des cas qu’ils n’auraient pas rencontrés. L’amélioration des méthodes d’IA permet d’adresser des cas d’usage de plus en plus complexes. Néanmoins, les données sont le fuel principal de l’IA. Certains cas d’usage, pourtant appétents à un projet d’IA ne peuvent donc être adressés faute de données de qualité.
De nombreux outils d’aide à la labellisation ont vu le jour. L’un des plus connus est Amazon Mechanical Turk ; il vise à complètement externaliser le processus d’annotation en le confiant à des tiers – non nécessairement experts, et intègre de nombreux scénarios de labellisation, pour tous types de données : images, le texte, les séries temporelles.
Pourtant, l’annotation reste une tâche difficile à effectuer : s’il est facile pour chacun d’identifier des chats ou des chiens dans des images, certaines tâches nécessitent des labels plus fins et donc le concours d’un expert. En outre, elles peuvent parfois être sujettes à interprétation : identifier un groupe de mots caractéristiques dans une phrase, rechercher des entités nommées ou segmenter une image. Labelliser nécessite ainsi des outils complets et robustes.
Pour les besoins de ses clients, Quantmetry a renforcé ses convictions sur les questions de labellisation de données textuelles. Cet article est le premier d’une série de deux articles ; il vise à partager la méthodologie que nous appliquons chez nos clients, les outils utilisés, et des retours d’expérience d’ateliers. Le second se concentrera davantage sur les enjeux scientifiques d’une labellisation efficace (article à venir).
Méthodologie itérative
Précision fine requise, multiplicité et hétérogénéité des tâches à résoudre augmentent rapidement le temps alloué à une campagne de labellisation. Se doter d’une stratégie d’annotation claire constitue donc une condition nécessaire au succès de ces campagnes. Forte de son expérience sur les sujets liés au traitement du langage naturel, et en particulier sur les problématiques de labellisation, Quantmetry s’est dotée d’une méthodologie claire et partagée avec les différentes parties prenantes, lui permettant de répondre aux quatre enjeux décrits sur la Fig. 1. ci-dessous. Cette méthodologie itérative garantit l’obtention de données de qualité qui permettent par la suite de répondre au(x) cas d’usage à adresser.
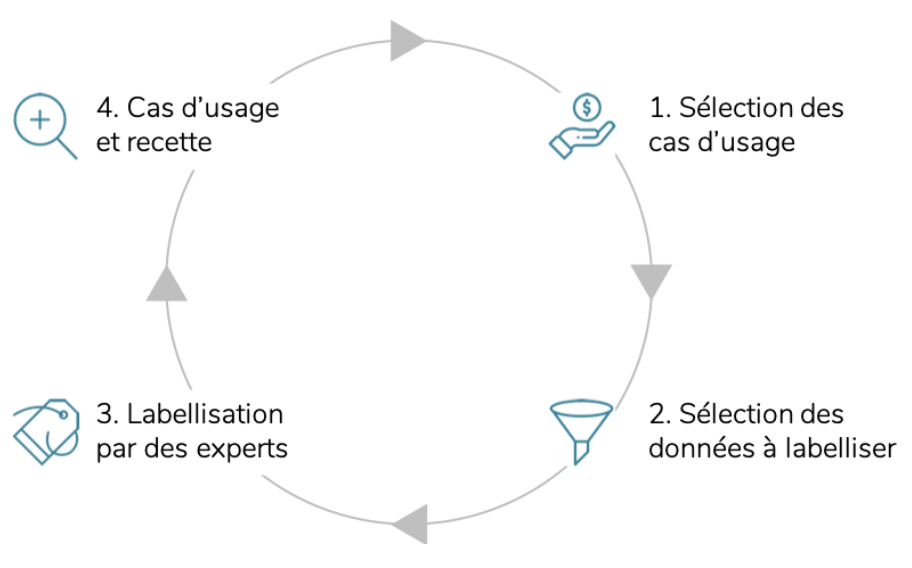
Fig. 1. Cycles itératifs de labellisation
Sélection des cas d’usage
Tous les cas d’usage ne se valent pas ! La première étape du processus itératif est de les évaluer selon des critères objectifs de difficulté et de rentabilité, comme en témoigne la Fig. 2 ci-dessous. Si cette étape est un standard de la gestion de projet, elle est absolument nécessaire pour identifier objectivement l’opportunité induite par chacun des cas d’usage. Les données textuelles contiennent en particulier diverses informations, qui peuvent toutes être labellisées de plusieurs manières pour adresser des cas d’usage distincts. Par exemple saisir la tonalité (bienveillance, malveillance, …), le motif (de quoi parle le verbatim ?), les « objets » référencés (personnes, montant, référence produit, …) ou encore les caractéristiques syntaxiques.
Quelles sont alors les questions à se poser lorsque l’on souhaite soumettre la détection d’un pattern sur des données textuelles à un exercice de labellisation ?
- A propos de la valeur : la détection d’un pattern particulier a d’autant plus de valeur qu’il est lié à une activité critique et/ou récurrente du business. L’estimation de la valeur peut souvent être réalisée via l’analyse de l’historique de l’activité d’une société, et y détecter notamment les goulots d’étranglement. Exemples : pour le service client, automatisation de la détection de verbatims avec un besoin de réponse urgent (entraînant une diminution du temps de réponse, et une augmentation de la satisfaction client en retour) ; ou encore, automatisation de la réponse à des demandes d’envoi de documents spécifiques (entraînant une diminution du temps d’intervention humain), …
- Difficultés de mise en oeuvre : en général, la détection d’un pattern textuel est d’autant plus complexe qu’il est sujet à interprétation. Son caractère polysémique peut également constituer un challenge scientifique, puisque l’approche retenue doit être en mesure de saisir les nuances. Exemple : détection de l’ironie dans un verbatim.
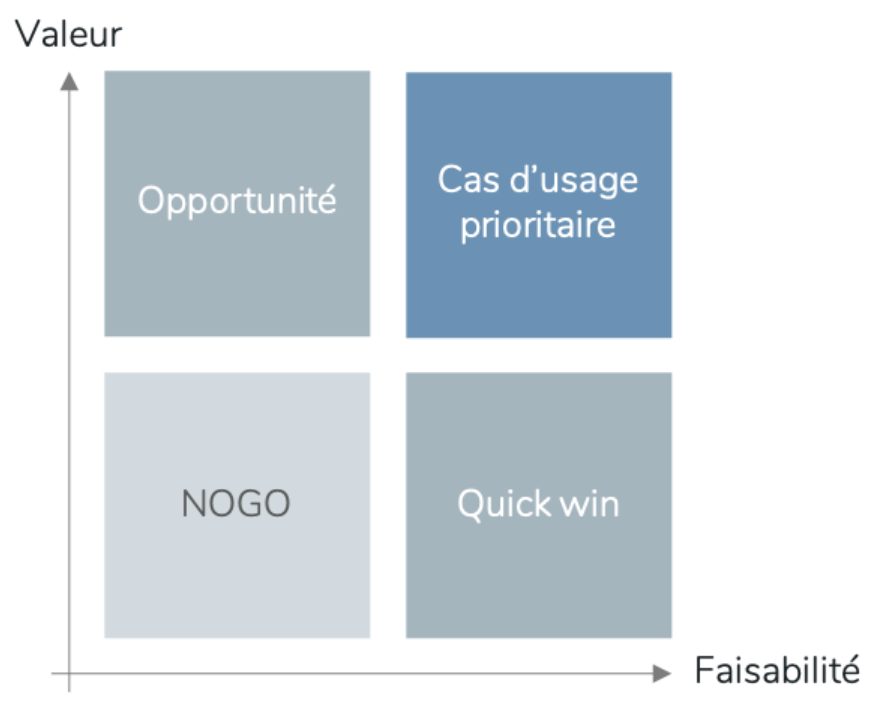
Fig. 2. Valeur VS Faisabilité
Constituer le dataset de labellisation
Tous les verbatims d’un corpus ne sont pas nécessairement utiles à la résolution d’un cas d’usage, et ce en particulier pour les cas d’usage rares et aux patterns peu fréquents. Choisir les exemples à labelliser avec ingéniosité est un véritable challenge. Comme illustré en Fig. 3., dans l’ensemble du corpus, un pattern peut être rare : fréquence d’apparition de 1/10 000 par exemple. S’il s’agit du pattern d’intérêt – qui devra par la suite être détecté par un algorithme de Machine Learning – deux stratégies sont envisageables pour fluidifier l’effort d’annotation et réduire le nombre d’exemples nécessaires.
Une première stratégie manuelle repose sur la mise en place de règles, qui permettent in fine de construire un dataset biaisé contenant une proportion du pattern d’intérêt plus importante (1/60) qu’initialement. Finalement, sur une séance de labellisation au cours de laquelle 6000 exemples sont labellisés, on aura donc probablement 100 manifestations de ce cas particulier (au lieu de 1 tout au plus si les exemples sont tirés au hasard). L’échantillon est donc biaisé, mais l’activité de labellisation devient nettement plus rentable.
Il convient d’être prudent dans la façon de sélectionner les exemples. Si des verbatims sont sélectionnés avec des règles directes (des expressions régulières par exemple), un modèle d’apprentissage automatique risque de simplement reproduire ces règles. Il est donc préférable d’opter pour un critère de sélection détourné. Par exemple, si on travaille avec des articles de presse, il peut être sain de les présélectionner en fonction des métadonnées de référencement ou de consultation. Il est possible d’écrire des règles basées sur leur abstract tant que ce dernier n’est pas extrait directement du texte mais bien une reformulation de l’article. De plus, il est important d’équilibrer les exemples à labelliser et de présenter des contre-exemples. Le but est d’assurer un socle d’exemples faciles à identifier tout en apportant de la diversité.
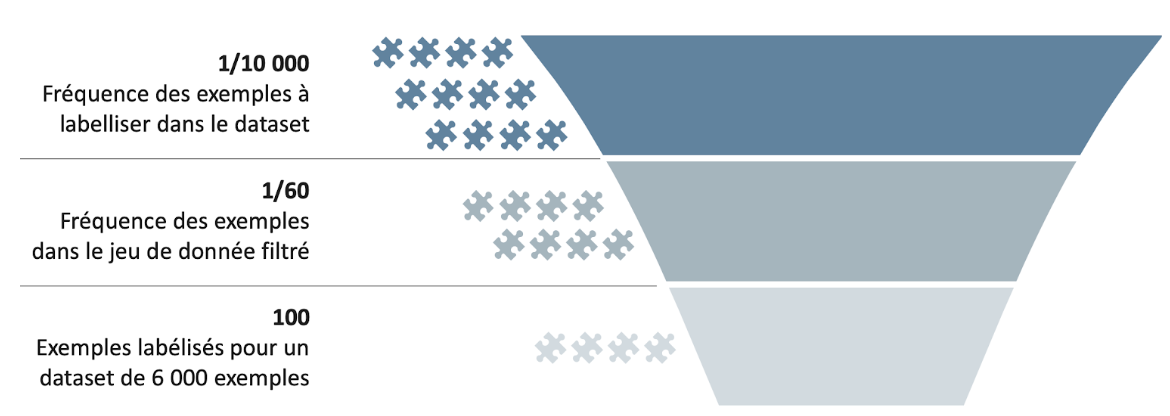
Fig. 3. Sélection biaisée des exemples à labelliser
Un second panel de stratégies repose sur des concepts comme l’Active Learning. Ces concepts seront décrits dans le deuxième article de la série.
Finalement, lors d’une phase de recette, il convient de ne pas évaluer la performance du modèle sur un échantillon sélectionné comme décrit plus haut au risque de surévaluer la précision du modèle. Il est préférable de privilégier un échantillon représentatif des conditions réelles.
Labellisation par des experts
L’atelier
Le succès d’un atelier de labellisation est fortement dépendant des conditions dans lesquelles il est réalisé (le lecteur pourrait presque assimiler cela à une expérimentation scientifique). L’expérience de Quantmetry montre que son succès est souvent dépendant du respect de quelques guidelines :
- Les consignes d’annotation doivent être claires, partagées et surtout comprises par tous les « labellisateurs ». Cela permet de se mettre d’accord sur la façon de labelliser un pattern ; et en retour de se prémunir contre des labellisations trop « étendues » ou impertinentes qui viendraient bruiter les analyses futures. Par exemple si on labellise pour du NER (Named Entity Recognition) il faut éviter de surligner une trop grosse partie du verbatim si l’information pertinente n’est contenue que dans un ou quelques mots.
- L’interface utilisée doit être ergonomique et correspondre au cas d’usage ; c’est-à-dire qu’elle doit permettre simplement et rapidement de labelliser un verbatim, sans friction pour l’utilisateur (voir section suivante).
- Une traçabilité doit être garantie : quels échantillons ont été traités par quel labellisateur ? Cela est d’autant plus vrai pour des patterns soumis à interprétabilité, c’est-à-dire sur lesquels il peut y avoir un désaccord sur la labellisation d’un même verbatim. Il faut donc être en capacité de prendre une décision sur le label retenu, a posteriori, par un vote par exemple.
Les outils
Les critères d’évaluation sur lesquels se concentre Quantmetry lors de son (ses) choix d’outil(s) de labellisation figurent parmi les suivants :
- Les cas d’usage techniques qu’il permet de labelliser (classification, détection d’entités nommées personnalisées, …)
- Sa compatibilité Open Source
- Son ergonomie
Ci-dessous un tableau récapitulatif des différents outils avec lesquels Quantmetry a eu l’opportunité de travailler :
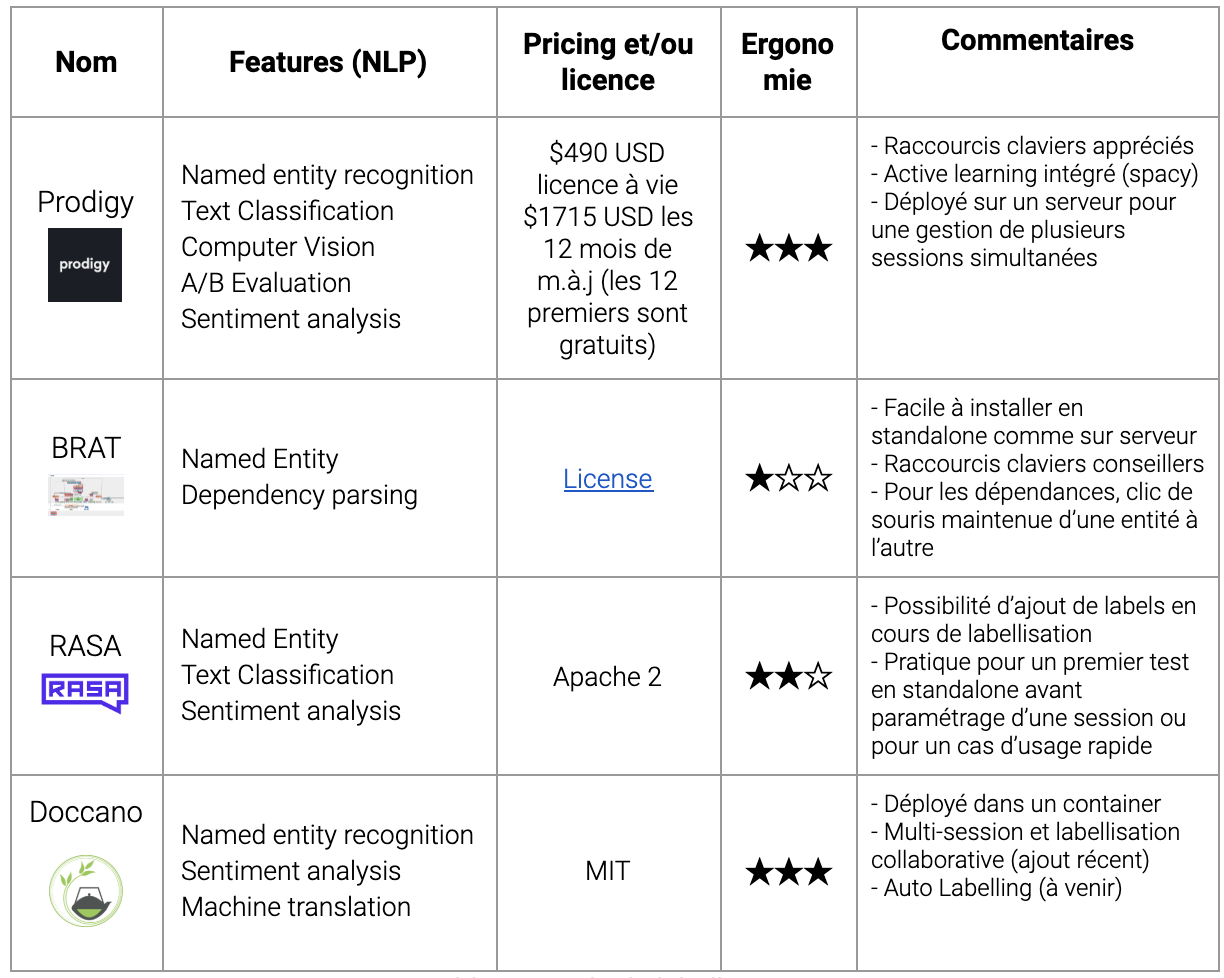
Table. 1. Outils de labellisation
Retour d’expérience
Conditions expérimentales
Nous cherchons à identifier un phénomène assez peu fréquent : environ 1% des phrases dans l’ensemble du dataset. Comme présenté précédemment, nous avons donc été très attentif sur la sélection des exemples : nous avons combiné un focus sur le mois d’août où notre cas d’usage était naturellement plus fréquent et des expressions régulières sur des abstracts de nos textes (pas de règle directe sur les textes donc). Nous avons également tiré des phrases au hasard, une partie d’entre elles a renforcé les exemples présélectionnés pour apporter de la diversité et l’autre a servi de set d’évaluation.
Nous avons déployé prodigy sur un serveur on premise pour que les données n’aient pas à sortir du système. Pour démarrer une séance de labellisation, nous exposons l’interface de prodigy sur un port du serveur hébergeur. Les labellisateurs n’ont qu’à saisir l’url dans leur navigateur web pour commencer leur travail. Nous étions sur place avec les agents pour intervenir sur l’application, répondre aux questions et recueillir en direct des avis sur l’exercice. La Table 2. présente un retour sur 3 ateliers de labellisation.
Résultats
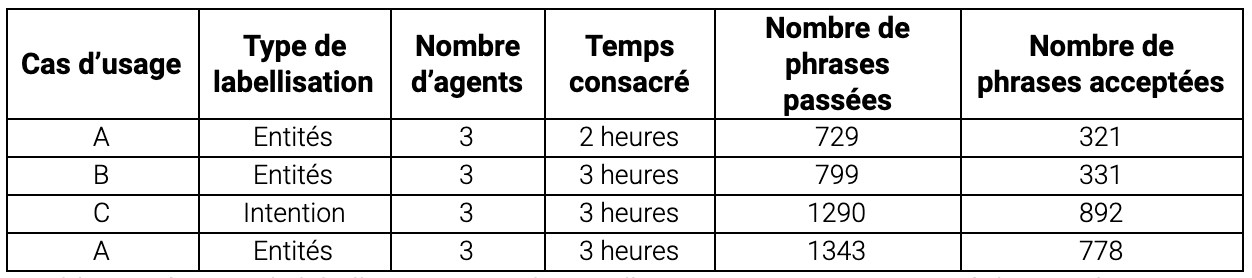
Table. 2. Séances de labellisation. Pour le cas d’usage A, nous avons mené deux ateliers. Pour les cas B et C, un seul atelier était nécessaire.
Plus de 300 entités (9 types d’entités différents) ont été étiquetées au cours du premier atelier. Comme attendu, les tout premiers premiers modèles entraînés sur ces volumes n’ont pas atteint le seuil de précision que nous avions fixé pour une mise en production. Nous nous sommes particulièrement concentré sur notre type d’entité prioritaire (entité 1, voir la Table 3.) au cours de l’atelier de labellisation suivant.
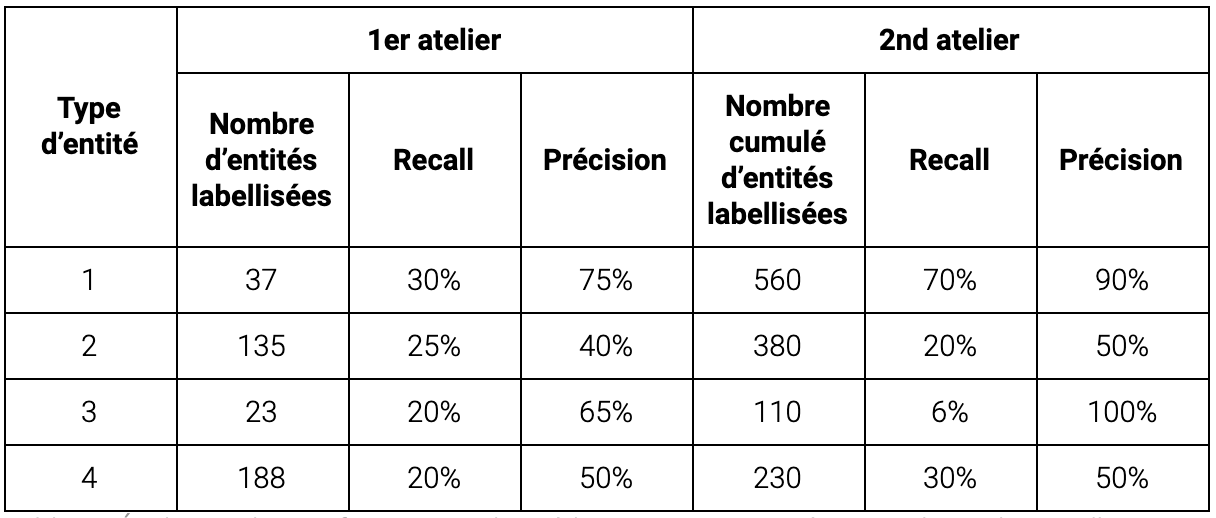
Table. 3. Évolution des performances de prédiction pour 4 entités parmi les 9 du cas d’usage A. Notre modèle a été calibré pour optimiser la détection de l’entité 1.
Nous observons une progression rapide de la performance avec le volume d’exemples mais un seuil (quelques centaines) est nécessaire pour une fiabilité. Ces seuils dépendent bien sûr de la complexité de la tâche (polysémie, exceptions, …). Notre modèle a atteint la performance cible pour notre type d’entité prioritaire au terme de 2 ateliers (560 exemples).
Key learnings
- Labelliser des données est un processus qui n’est pas forcément habituel pour un data scientist. En effet elles sont généralement déjà collectées et le périmètre déjà défini pour le projet. La labellisation est ainsi un (nouveau) processus où il convient d’être particulièrement attentif aux conditions dans lesquelles se passent les ateliers et la manière dont sont acquises les données. Elles auront un impact direct sur les résultats. L’Interprétation des consignes par le métier, le fait de labelliser un même exemple par plusieurs personnes ou la sélection de l’échantillon d’apprentissage sont ainsi des facteurs extrêmement importants pour la réussite du futur cas d’usage.
- Malgré les nombreux outils disponibles, la labellisation reste une étape fastidieuse. Plusieurs ateliers sont souvent nécessaires à un cas d’usage pour atteindre les précisions souhaitées. Les labellisateurs ont besoin d’un temps d’adaptation et sont plus efficaces après quelques ateliers si bien qu’il est très avantageux de retrouver des labellisateurs d’un atelier sur l’autre. Si les cas d’usage sont multiples nous recommandons de mutualiser l’annotation entre les équipes – à moins que leur expertise soit trop spécifique – afin de rendre l’exercice moins monotone et plus rentable. Enfin les labellisateurs aguerris facilitent grandement le travail du data scientist dans la conduite du changement et la transmission de bonnes pratiques.
- Quantmetry a investi du temps de Recherche & Développement pour simplifier le processus de labellisation grâce à des outils open source. En particulier, l’objectif est d’incorporer à des outils existants : des méthodes d’auto-labelling, qui accélèrent la saisie de labels pour l’utilisateur final ; des méthodes statistiques d’active learning, qui proposent de sélectionner dynamiquement les exemples à labelliser afin d’en labelliser moins, et mieux ; des méthodes d’online learning qui permettent de ré-entraîner des modèles à la volée, et rendre disponible « en temps réel » des suggestions à l’utilisateur. Ces aspects sont traités plus en profondeur dans le second article de la série, disponible prochainement.
