

Logistique et data : vers un outil d'aide à la décision

Il existe aujourd’hui 2 axes de croissance d’activité connus pour les entreprises : diminuer les coûts et augmenter les revenus. Ils ne sont pas incompatibles et peuvent être engagés en parallèle. En ce qui concerne les services de logistique, la seule possibilité réside dans la diminution des coûts, puisqu’il s’agit d’un centre de coûts avant tout pour beaucoup de dirigeants. En moyenne, en France et dans tous les secteurs d’activité, les coûts logistiques représentent entre 8 et 10% du chiffre d’affaires. La Data science et les outils associés permettent de faire diminuer ces coûts, et ce tout en améliorant la satisfaction client. Celui-ci sera donc livré plus vite, à moindres coûts et avec moins d’erreurs.
Dans un autre article, nous avions expliqué comment la data science permettait de prédire la charge journalière des entrepôts à une semaine. Aujourd’hui, nous nous intéressons à un cas d’optimisation des stocks pour des pièces de rechange : où et en quelle quantité doit-on positionner les stocks pour pouvoir répondre au mieux à la demande finale ?
Il y a en général plusieurs niveaux de stockage en entrepôts qui correspondent classiquement à des périmètres géographiques (local, régional, national…). L’entrepôt est bel et bien un maillon clé de la supply chain intégrée, et les bénéfices potentiels de son optimisation ne sont plus à prouver. Nous vous proposons de revenir sur les problématiques rencontrées, et d’y apporter des réponses, adaptées au contexte.
PROBLÉMATIQUES RENCONTRÉES
-
Connaissance des modèles – quel est le modèle adapté pour prédire les consommations de pièces de maintenance ?
-
Importance des règles métiers dans le paramétrage de l’IA – comment les règles métiers vont déterminer les résultats du modèle ? Quels sont les paramètres et quelle est leur signification d’un point de vue métier ?
-
Appropriation et utilisation de l’IA par les équipes métiers – comment le métier analyse-t-il les modèles calculés et comment choisit-il le modèle optimal ? Comment l’intelligence du modèle s’insère dans le processus actuel ?
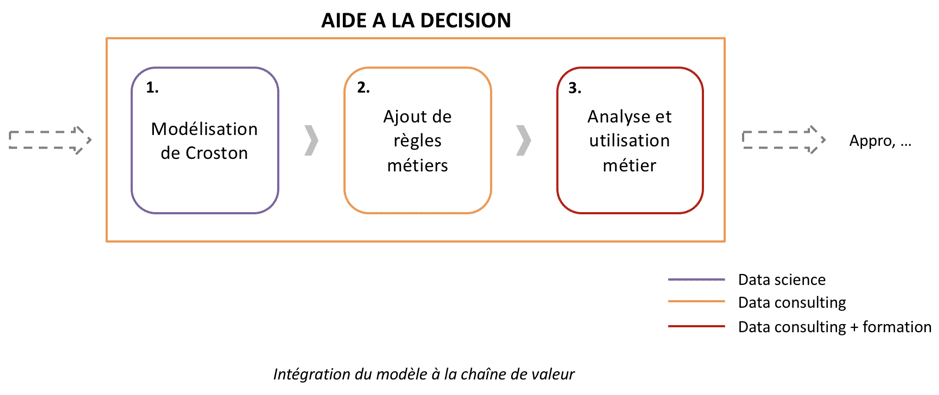
CONTEXTE
Prenons pour exemple une situation de surstockage de pièces de maintenance dans l’ensemble des entrepôts : cela implique des coûts d’immobilisations élevés (espace, obsolescence…) et il est normal que les entreprises cherchent à optimiser leurs niveaux de stocks tout en garantissant un taux de service suffisamment élevé. Il y a a priori un équilibre à trouver entre valeur stockée et taux de service sur les différents niveaux de stockage puisque moins de pièces en stock implique inévitablement une diminution du taux de service.
CONNAISSANCE DES MODÈLES
Comme souvent, les pièces de maintenance ont un type de consommation sporadique, c’est-à-dire que les pièces sont consommées à des intervalles très longs et irréguliers. Etant donné la typologie particulière de consommation des pièces, c’est le modèle de Croston qui est le plus approprié et qui permet de réaliser deux prédictions indépendantes : une pour la valeur de chaque consommation, une autre pour l’intervalle entre chaque consommation. Dans les deux cas, la prédiction est un arbitrage entre la dernière prédiction et l’observation la plus récente ; grâce à ce principe de lissage exponentiel, les consommations historiques reçoivent des poids variables en fonction de leur ancienneté dans le temps.
Le rôle du Data Scientist est de sélectionner le modèle le plus adapté à l’historique de consommations très particulier de ce type de pièces. Les prédictions réalisées se font à la référence qui est le niveau le plus bas (ici il s’agit d’une combinaison pièce/entrepôt). L’utilisateur métier final n’aura donc pas besoin de désagréger la prédiction du modèle.
IMPORTANCE DES RÈGLES MÉTIERS DANS LE PARAMÉTRAGE DE L’IA
En revanche, il est nécessaire d’affiner le modèle tel qu’il existe dans la littérature avec les règles métiers des logisticiens, sans quoi le modèle n’aurait aucun sens.
La connaissance métier de la typologie des pièces stockées et de leurs caractéristiques de consommation permet d’ajouter au modèle des règles de gestion pour l’ajuster davantage aux contraintes business. Les règles métiers définissent des coefficients qui vont être multipliés par la valeur de demande prédite par le modèle de Croston. Il y a donc plusieurs coefficients qui ont été définis suivant la typologie des pièces : sensible ou non, prix de la pièce (économique, moyen, cher), délai moyen d’approvisionnement, taux de rotation et conditionnement. Ces coefficients permettent d’avoir de meilleures performances en termes de taux de service pour les catégories de pièces qui nous intéressent le plus. Par exemple, il est possible de prendre les règles suivantes sur les deux cas extrêmes de typologie de pièces :
Nous aimerions être presque toujours capables de répondre à une commande de pièces sensibles, économiques et à rotation élevée. Ne pas les avoir en stock ne diminuera pas beaucoup le capital immobilisé mais dégradera en revanche de manière significative la qualité du service assuré ;
Pour une pièce très chère, non sensible, et qui est consommée rarement, par contre, il sera plus raisonnable de ne pas garder de stock. Être en mesure de satisfaire toutes les commandes dans cette catégorie ferait exploser le capital immobilisé.
A consommations égales, nous proposerons par exemple des coefficients multiplicateurs plus élevés pour des pièces économiques et plus faibles pour des pièces chères.
Ainsi la traduction en coefficients multiplicateurs des différentes règles métiers de stockage permet de réaliser un algorithme sur-mesure. La politique de gestion de stock choisie sera réellement reflétée dans les prédictions du modèle final. C’est le rôle du Data Consultant d’accompagner la définition des règles métiers et leur implémentation au sein du modèle.
APPROPRIATION ET UTILISATION DE L’IA PAR LES ÉQUIPES MÉTIERS
L’algorithme sur-mesure génère un certain nombre de modèles qui testent différentes combinaisons de paramètres. Il s’agit des paramètres de lissage du modèle qui donnent des poids variables aux consommations historiques en fonction de leur ancienneté dans le temps. Ces deux paramètres de lissage permettent de régler ce poids pour, respectivement, la quantité commandée en moyenne et l’intervalle entre deux commandes consécutives.
La performance des modèles calculés est évaluée vis-à-vis des deux KPIs définis initialement : taux de service et valeur stockée. Comme nous nous y attendions, nous constatons qu’il y a une relation de dépendance entre les 2 KPIs : baisser la valeur totale de stock se fait au détriment du taux de service, et vice-versa. Il y a donc un compromis adapté d’un point de vue métier à trouver entre ces deux contraintes.
La modélisation propose des solutions raisonnables mais ne peut pas trancher définitivement pour un modèle optimal. Une intervention humaine est strictement nécessaire pour choisir ce modèle optimal en se basant sur les contraintes business de l’activité à l’instant t, et prendre la décision opérationnelle de le mettre en œuvre. Par exemple dans un premier temps, il peut être pertinent de construire de la confiance autour des prédictions du modèle avec les gestionnaires d’entrepôt, et donc éviter de choisir les modèles qui favorisent uniquement une faible valeur stockée.
L’analyse métier des modèles générés est donc fondamentale pour utiliser la puissance de l’algorithme à bon escient. Le métier doit en amont être sensibilisé aux notions de machine learning et formé à l’outil qui n’est finalement rien d’autre qu’une aide à la décision au quotidien. Ces activités d’appropriation et de formation à l’IA sont menées par le Data Consultant.
CONCLUSION
L’IA n’est pas autoporteuse dans sa construction et dans son analyse. Son utilisation et son exploitation nécessitent d’une part l’adaptation à un contexte métier, et d’autre part l’intervention du métier pour analyser les résultats et les mettre en œuvre. Cette valeur ajoutée humaine ne sera pas remplaçable par des robots.
Il faut également automatiser le flux de données entrant de manière qualitative et quantitative afin d’éviter au métier les opérations de nettoyage et de mise en qualité des données. C’est le rôle du Data Engineer de construire les solutions qui vont permettre l’exploitation fluide de gros volumes de données. Cela garantira l’appropriation et la confiance des différents opérationnels en la qualité des prédictions fournies, et donc le succès de l’intégration du modèle à la chaîne de valeur.
Nota Bene : le modèle de Croston fera l’objet d’un autre article qui détaillera son fonctionnement technique. Ici l’objectif était d’expliciter les contraintes et impacts métiers de la mise en place d’un modèle de Data science en logistique.
