

PMML : un format pour l’interopérabilité des modèles de Machine Learning entre Entraînement et Production
Introduction
Un des grands challenges associés à l’entraînement de modèles de Machine Learning est de garantir leur interopérabilité, c’est-à-dire leur capacité à être exportés puis réutilisés par des librairies ou des environnements différents. Commençons par définir quelques notions: un modèle entraîné est la sortie d’un algorithme de Machine Learning servant à faire des prédictions sur un jeu de données. Une libraire est un package software comme scikit-learn ou keras. Un environnement est la combinaison d’un système d’exploitation et de hardware.
Il existe plusieurs situations ou l’interopérabilité des modèles est importante:
- L’environnement d’entraînement est différent de l’environnement de production, et la librairie utilisée pour le premier n’est pas disponible dans le second. Un environnement d’entraînement est par exemple le système d’exploitation MacOS du Macbook d’un Data Scientist, la production étant ensuite réalisée par un serveur de production sur le Cloud.
- La taille des environnements d’entraînement et de production diffère énormément, par exemple dans le cas d’un algorithme de Deep Learning entraîné via TensorFlow sur un cluster avec 100 GPUs puis exécuté sur un iPhone.
- Des exigences très strictes sur la latence en production, et le langage ou la librairie utilisés pour l’entraînement ne délivrent pas une performance suffisante.
- Les équipes de développement et de déploiement du modèle ont des préférences de langage et/ou de librairie différentes. C’est une pierre d’achoppement classique entre équipes de Data Scientists en charge de d’entraîner le modèle et de le fournir aux équipes IT qui le mettent en production.
Il existe plusieurs options pour permettre l’interopérabilité des modèles. Dans cet article, nous nous concentrons sur le format PMML (Predictive Model Markup Language), un modèle d’échange de format basé sur XML développé et maintenu par le Data Mining Group. Développé en continu entre 1997 et 2016, PMML est un format standard supporté par plus de 30 organisations de premier plan telles que IBM, Microsoft, Java, Teradata, SAS ou Apache Spark.
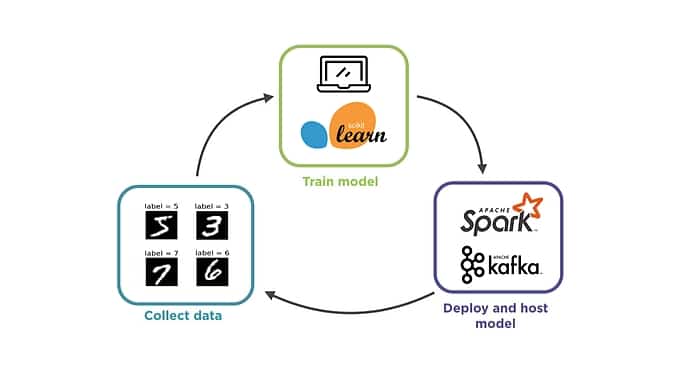
Dans la suite de l’article, nous nous concentrons sur l’utilisation pratique de PMML pour exporter un modèle de forêt aléatoire généré via scikit-learn dans un framework de production en streaming via Kafka et Spark.
Cas d’usage : EMNIST dataset
Le dataset MNIST est une référence dans le domaine de la classification et de la computer vision de part le caractère intuitif de la tâche à accomplir (reconnaître et classifier des images de chiffres de 0 à 9 écrits à la main), la taille raisonnable des sets d’entraînement (60 000) et de test (10 000) et la facilité d’accès aux données (gratuites et accessibles ici). MNIST a cependant souffert de sa grande simplicité de classification, avec des précisions supérieures à 99,7% par la plupart des algorithmes classiques, le transformant plus en moyen de validation du systèmes de classification qu’en véritable challenge pour les algorithmes de Deep Learning les plus performants.
Le Extended MNIST, ou EMNIST, est un ensemble de datasets (disponibles ici) représentant un plus grand challenge pour les classifications de machine learning. Notre sélection, le EMINST By_Merge, contient 47 classes parmi les chiffres et lettres manuscrits de 0 à 9 et A à Z (minuscules et majuscules). Avec 700 000 et 116 000 images dans les sets d’entraînement et de test respectivement, le dataset représente un volume suffisant pour justifier son industrialisation dans un environnement approprié.
Méthodologie
Nous souhaitons tester la facilité d’utilisation en pratique du format PMML pour passer de l’entraînement à l’industrialisation.
1. Entraînement
Nous réalisons l’entraînement localement sur un Macbook muni de Python 3.6 et du package scikit-learn pour entraîner le modèle de forêt aléatoire. La librairie skearn2pmml (installable via pip install sklearn2pmml), exporte ensuite le pipeline scikit-learn en PMML. La méthodologie est la suivante:
- Importer le module sklearn2pmml
- Créer un pipeline PMML en définissant le modèle de Machine Learning à utiliser. Le pipeline PMML supporte les fonctionnalités d’un pipeline normal telles que feature selection, feature engineering, Grid Search Cross Validation.
- Réaliser l’entraînement du modèle sur les données d’entraînement.
- Exporter le pipeline localement en fichier .pmml.

La portabilité est très facile à obtenir et ne représente que quelques lignes de code. Le PMML lui-même est basé sur XML et enregistre la description des features numériques et de catégorie ainsi que tous les paramètres du modèle.
2. Industrialisation
Nous allons importer le modèle PMML créé dans un module de streaming, afin de faire des prédictions en temps réel. Le framework utilisé pour appliquer le modèle est Apache Spark dans sa version 2.3.1, et nous utiliserons kafka pour la partie streaming.
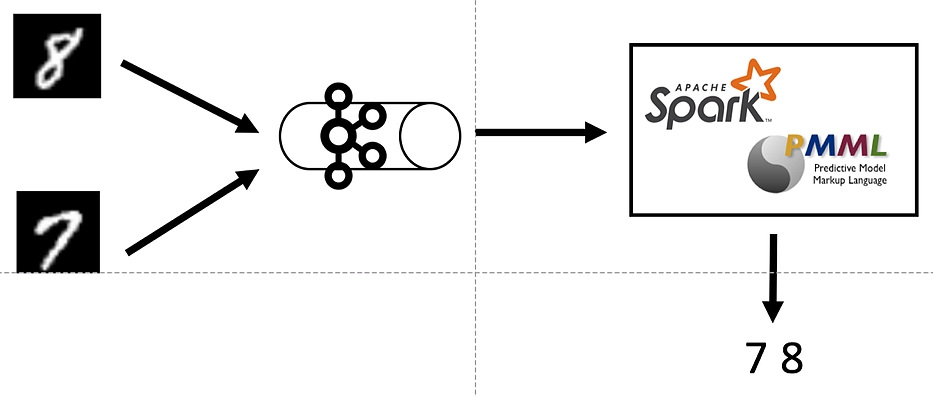
Les images sont de taille normalisées 28×28, soit 784 pixels, et sont envoyés au format chaîne de caractère, composés de 784 nombres séparé par des virgules. Chaque nombre correspond à la valeur de gris entre 0 (noir) et 255 (blanc)
Exemple de chaîne envoyé à kafka:
0,0,0,0,0,0,0,0,0,0,4,66,111,…,0,0,0,0,0,,0,0,0,0,0,0,0,0
Note : Il ne s’agit évidemment pas d’un format optimisé, car non compressé, mais le but du tutoriel qui suit est de faire un proof-of-concept, et non une solution destinée à la production.
Tutoriel d’implémentation
Pour faire fonctionner ce tutoriel il est nécessaire d’avoir installé :
- Kafka en version 0.10 ou plus
- Apache spark en version 2.3.0
- scala avec sbt
Nous utiliserons le module spark-streaming-kafka-0-10 pour faire la liaison entre spark et kafka
Partie 1 : Code scala
1. Création des spark session et du streaming context

2. Importation du fichier PMML et assemblage du modèle

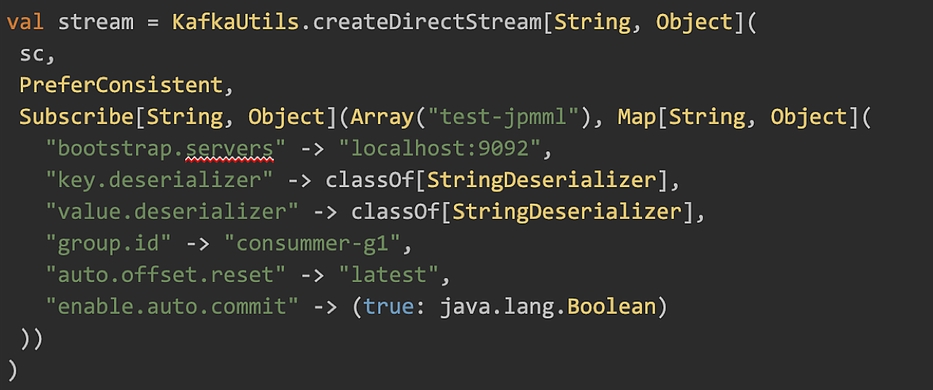
3. Création du stream
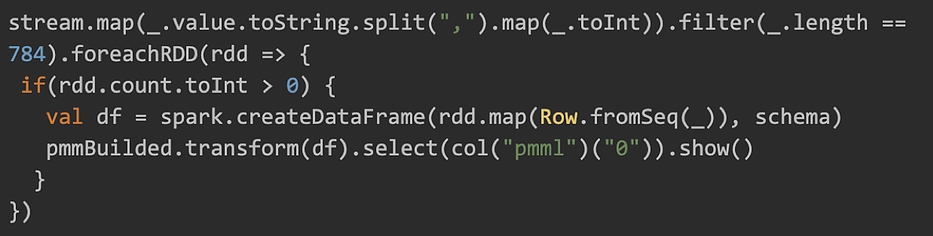
4. Transformation en Dataframe spark
L’idée va être de transformer le flux de chaîne de caractère en un dataframe qui peut être interprété par le modèle construit en 2.
Tout d’abord il est nécessaire de créer le schéma du dataframe, soit 784 colonnes

Chaque RDD qui compose le flux va être transformé en dataframe, en 2 étapes :
- Le RDD[String] est transformé en RDD[Array[Int]]
- Le RDD[Array[Int]] est transformé en dataframe en appliquant le schéma
Le modèle est ensuite appliqué au dataframe.

Le code complet, qui inclus les librairies, les plugins sbt et les import se trouve dans le zip ici
Création d’un fat-jar destiné à spark-submit
Le jar destiné au spark-submit doit contenir toutes les librairies, le plugin sbt-assembly (https://github.com/sbt/sbt-assembly) permet de créer ce type de jar, aussi appelé fat-jar
Dans la racine du projet
![]()
Cela créera le fat jar dans le dossier target/scala_2.11
Lancement des services spark et KAFKA
Installez et lancez un broker kafka en suivant la documentation officielle (https://kafka.apache.org/quickstart) et crééz un topic « test-jpmml » avec 2 partitions

Alimentez le topic avec des messages

Lancez un spark-submit avec le jar généré

où le nombre de worker spark correspond aux nombre de partitions kafka créées dans la partie précédente. Le spark-submit est lancé en mode local pour les besoins du tutoriel.
Résultats
Et voilà ! Après quelques secondes de traitement les premiers résultats arrivent… la prédiction en temps réelle est fonctionnelle.
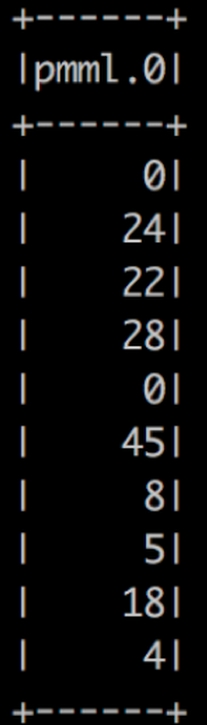
La colonne représente la classe prédite. Ces classes sont déterminées dans la partie entraînement.
Conclusion :
L’utilisation du format .pmml via la librairie sklearn2pmml de scikit learn permet de séparer les environnements d’entraînement et de production. L’export du modèle ne représente que quelques lignes de code et permet une perméabilité beaucoup plus grande entre le travail du Data Scientist et celui du Data Engineer. Il permet également une industrialisation, et le gain de performance qui l’accompagne, de manière rapide et simple.
Toutefois, quelques points d’attention à retenir de notre benchmark :
- Les fichiers .ppml peuvent être assez gros en fonction de la taille du jeu d’entraînement et du modèle de Machine Learning choisi. Dans notre étude, nous avons constaté une taille du fichier .pmml de 3 à 10 fois la taille du jeu d’entraînement. Bien que l’espace disque occupé par le modèle dans l’environnement de déploiement ne soit pas un paramètre aussi contraignant que l’espace occupé en RAM, la taille du modèle peut devenir problématique, d’autant plus qu’environ 30% de la taille est causée par des tabs dans le fichier XML.
- Le modèle ML souhaité doit être supporté par PMML. Une liste des modèles supportés, très compréhensive, se trouve ici. Même si la plupart des modèles se retrouvent, tous ne s’y trouvent pas et en implémenter un nouveau demande un développement relativement complexe en java.
- Seuls les modèle pré-entraînés peuvent être exportés en pmml. Il n’est donc pas possible d’exporter un squelette vide de modèle pour faire entraînement et prédiction à la fois dans un environnement différent de celui où a été simplement initialisé le modèle.
PMML est considéré par de nombreux utilisateurs comme le standard “de facto” pour l’interopérabilité des modèles de machine learning classique malgré des limitations qui perdurent. Mais le monde du Machine Learning change vite, avec notamment l’apparition de nouveaux formats d’échange, tels que :
- PFA, le successeur de PMML développé par le même groupe : Data Mining Group
- ONNX, spécialisé dans les réseaux de neurones et développés par FaceBook, Microsoft et Amazon (un article que Quantmetry a rédigé est disponible ici)
- Core ML développé par Apple
Ce sont des solutions à suivre de près pour le futur de l’export des modèles.
✍Écrit par Sophie Monnier, Julien Roussel et Fouad Talaouit
