

Quand l'intelligence artificielle s'attaque à la fraude : le problème des biais de sélection

La mise en place de systèmes de détection de la fraude ou de credit scoring représente un enjeu majeur pour les entreprises de bien des secteurs d’activité. Qu’il s’agisse de souscription d’abonnements, de crédits ou de contrats d’assurance, les comportements frauduleux sont à l’origine de pertes financières conséquentes.
Le credit scoring est une méthode d’évaluation du niveau de risque associé à un dossier de crédit potentiel, et qui permet d’estimer la probabilité de défaut qui permettra d’affecter chaque client à une des catégories suivantes : bon payeur ou mauvais payeur.
La fraude correspond quant à elle à la survenance d’un évènement particulier, rare, et souvent associé à une période de survenance (ces éléments varient en fonction des métiers considérés).
Lorsqu’il s’agit de prédire une probabilité de défaut ou une probabilité de fraude, nous sommes confrontés à ce qu’on appelle le biais de sélection. De quoi s’agit-il ?
Le biais de sélection fait référence au biais qui implique que l’échantillon de données utilisé ne constitue pas un groupe représentatif de la population étudiée. Comment adresser cette problématique ? En utilisant des techniques dites d’inférence des refusés.
Cet article a pour but de présenter les problématiques principales rencontrées chez nos clients et les approches de Data Science que nous avons adoptées pour les adresser. Notons que la pertinence de ces approches dépend évidemment des cas d’usage. En effet, selon les cas, les types de données disponibles et la définition de la cible peuvent varier fortement.
Nous nous plaçons ici dans le cadre d’une approche supervisée, pour laquelle nous avons donc récupéré un historique de données labellisées, le but étant de prédire l’apparition d’un évènement, de type fraude ou défaut de paiement (problème de classification).
Note:
Dans la suite de l’article, il est à noter que le modèle dont nous parlons traite de la prédiction d’évènements de fraude. Il peut cependant être transposé à des problématiques de défauts de paiement dans le cadre de credit scoring.
Ce modèle a été positionné à l’intérieur d’un processus bien défini, qui comporte notamment en sortie des contrôles manuels. C’est important car le modèle ne peut alors prendre qu’une décision de validation des dossiers, il ne peut pas les rejeter. Tous les dossiers prédits douteux par le modèle sont envoyés dans la suite du processus et sont alors analysés manuellement par des analystes compétents.
COMMENT SE CARACTÉRISE CONCRÈTEMENT LE BIAIS DE SÉLECTION ?
La cible correspond dans ce cas d’usage à une donnée binaire, soit 2 classes : fraudeur / non-fraudeur. Mais qu’est-ce qu’on entend exactement par “fraudeur” ? Cette question est particulièrement importante et définit toute la suite du processus de modélisation.
La définition de cette cible suppose deux aspects importants :
-
L’identification du caractère qui définit la fraude : il s’agit là d’une définition métier dont l’occurrence est généralement suivie par une décision de résiliation de la part de l’organisme (tel comportement dans tel lapse de temps correspond à de la fraude)
-
La prise en compte des dossiers précédemment rejetés pour suspicion de fraude
C’est sur ce dernier point que nous allons nous arrêter afin de caractériser le biais de sélection.
L’historique de données dont nous disposons comprend un dossier par ligne, chaque dossier étant caractérisé (labellisé) fraudeur ou non fraudeur. Qu’est-ce que cela signifie ?
-
Un dossier qui est indiqué comme fraudeur est ainsi caractérisé car il a été initialement accepté dans le processus de contrôle de la fraude. Une fois ce dossier accepté, dans son « parcours de vie », l’organisme a identifié un comportement qu’elle a qualifié de frauduleux, et l’a ainsi résilié. C’est uniquement de cette façon, et donc via l’acceptation initiale, qu’un dossier peut être qualifié de frauduleux.
-
Un dossier indiqué non fraudeur est un dossier qui a été accepté initialement, et pour lequel l’organisme n’a pas relevé de comportement pouvant être qualifié comme frauduleux durant son « parcours de vie ».
Qu’en est-il alors des dossiers qui ont été refusés ?
Ces dossiers correspondent alors à des suspicions de fraude. Etant donné qu’ils ont été rejetés, il n’y a pas eu souscription, et donc l’organisme ne connaît pas leur « parcours de vie ». Il est alors impossible de savoir si ces dossiers correspondent effectivement à des potentiels fraudeurs, ou bien s’ils ont été rejetés à tort.
Ce point est très important et peut être résumé par la matrice suivante :
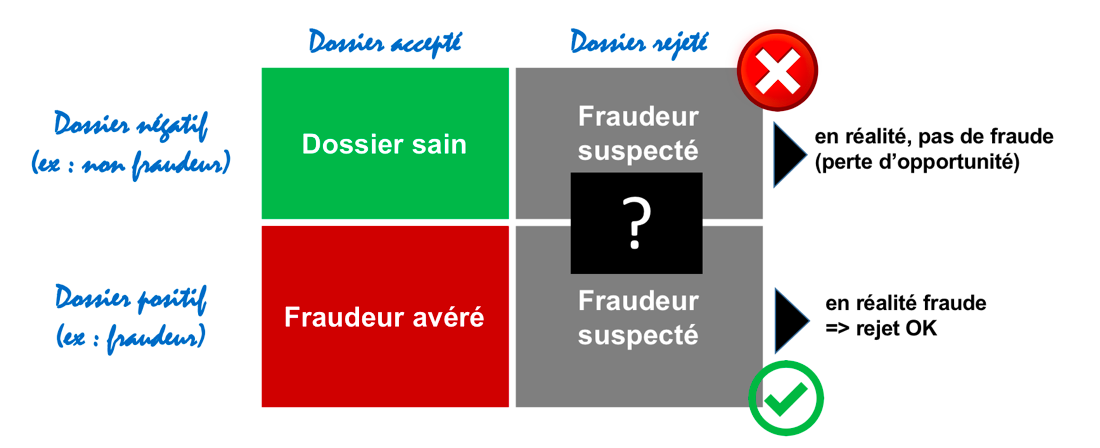
Ainsi, nous comprenons qu’il ne peut y avoir de certitude sur l’échéance d’un dossier que s’il a été accepté, chaque dossier rejeté laissant place à un biais. Il s’agit donc du fameux biais de sélection.
Dans notre cas, les positifs de la cible avaient été définis comme étant l’union des fraudeurs avérés et des dossiers rejetés. Ceci impliquait donc l’introduction d’un biais non-négligeable dans la cible. Toute la question alors est de savoir comment il est possible de traiter ce biais afin de réduire son impact. C’est là qu’interviennent les techniques de débiaisage, ou d’inférence des refusés.
Nous mentionnons ici les quelques techniques que nous avons pu tester dans le cadre de notre cas d’usage :
-
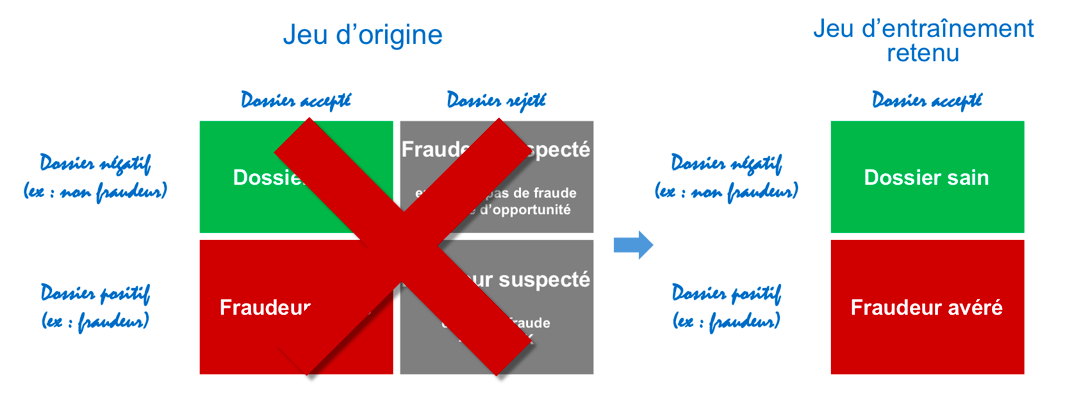
KGB (Known Good Bad) : il s’agit de ne considérer que les dossiers qui ont été acceptés, sains ou fraudeurs avérés.
L’avantage est de pouvoir s’affranchir du biais introduit par les dossiers rejetés.
L’inconvénient est qu’un autre biais est introduit. En effet, certains profils de fraudeurs ne seront alors pas pris en compte (les profils qui ont été rejetés précédemment) dans l’apprentissage, et le déséquilibre du jeu de données va se creuser. En effet, dans l’hypothèse que le processus de contrôle de la fraude mis en place présentait une relative efficacité, il y a logiquement une proportion plus faible de fraudeurs.
-
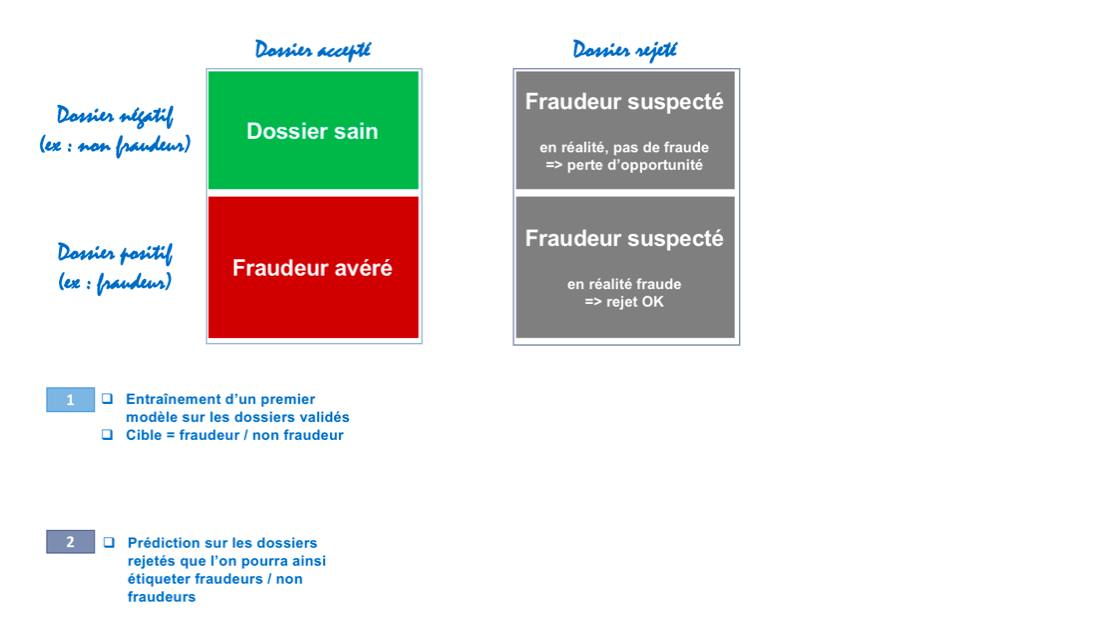
Reclassification itérative : cette technique permet de réaliser une affectation des fraudeurs / non fraudeurs parmi les dossiers rejetés.
Elle consiste à :
-
Entraîner un premier modèle uniquement sur les dossiers validés dont la cible est « fraudeur/non fraudeur », puis à prédire sur les rejetés afin de les classer dans une de ces catégories. Les rejetés sont alors étiquetés « fraudeurs / non fraudeurs ».
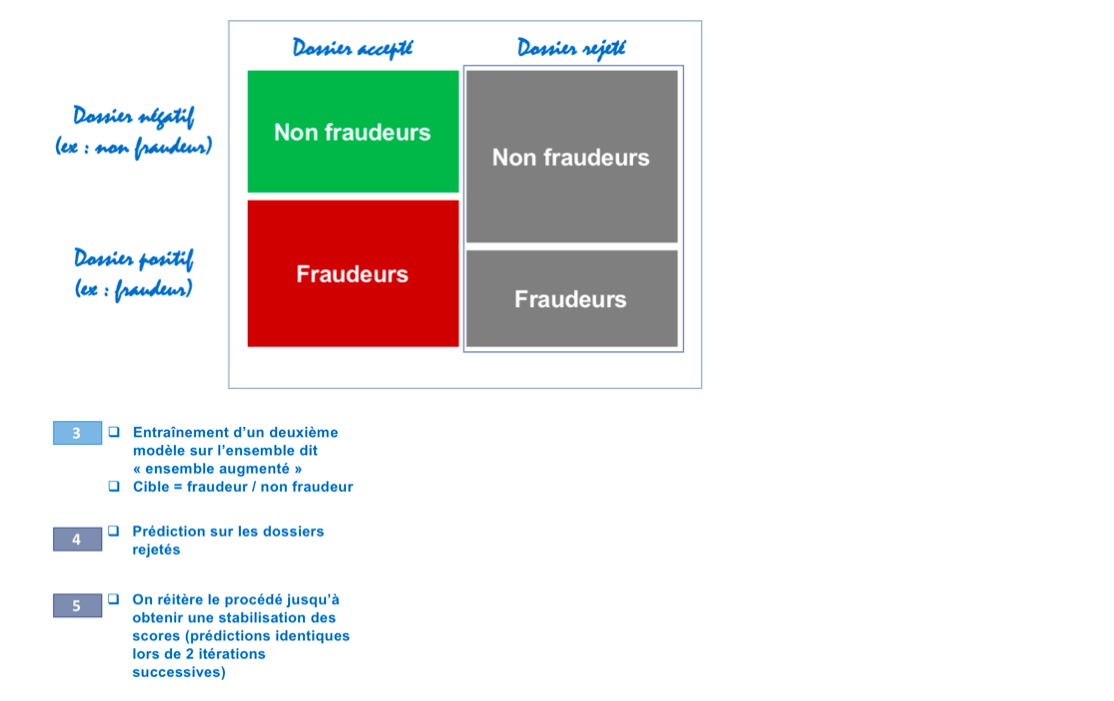
-
On construit ensuite « l’ensemble augmenté », qui correspond à la population totale étiquetée désormais « fraudeurs / non fraudeurs ». On entraîne un modèle sur cette population totale et on prédit sur la population des rejetés.
-
On réitère alors ce processus jusqu’à obtenir une stabilisation des scores (prédictions identiques lors de deux itérations successives)
Cette technique présente des résultats très intéressants, notamment en comparaison avec l’utilisation d’un groupe de contrôle. Cependant, nous conservons ici le biais relatif au fait que certains profils (ceux qui ont été rejetés précédemment) ne sont pas pris en compte.
-
Re-weighting : cette technique permet d’affecter un poids selon que le dossier ait été accepté ou refusé.
-
On entraîne un premier modèle à prédire si un dossier sera accepté (1) ou rejeté (0), puis on l’applique à la population totale. On obtient ainsi une probabilité d’acceptation pour chacun des dossiers.
-
On pondère alors chaque dossier par l’inverse de la probabilité d’acceptation qui vient d’être calculée. Un dossier qui aura été identifié par le premier modèle comme probablement non accepté aura alors un poids bien plus important qu’un dossier probablement accepté.
-
On construit alors un modèle sur les dossiers ainsi pondérés afin de prédire la caractéristique « fraudeur / non fraudeur ».
-
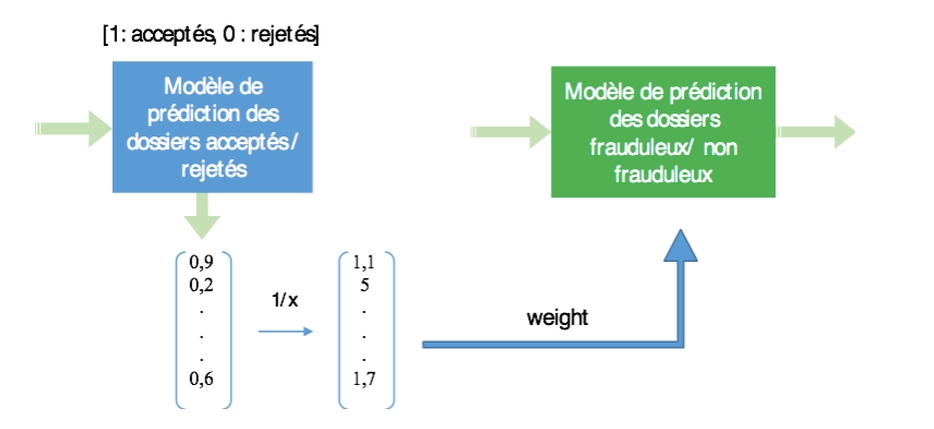
De la même façon qu’avec la reclassification itérative, cette technique présente des résultats très intéressants, mais conserve le biais relatif au fait que certains profils (ceux qui ont été rejetés précédemment) ne sont pas pris en compte.
-
Utilisation d’un groupe de contrôle pour débiaisage : nous parlerons de cette dernière technique dans le prochain paragraphe.
PROBLÉMATIQUE D’UTILISATION D’UN GROUPE DE CONTRÔLE
Un groupe de contrôle, c’est en quelques sortes un jeu de données témoin. Il est d’abord constitué dans le but de pouvoir comparer les résultats du modèle avec une situation sans modèle. Ce groupe de contrôle est un jeu de données dans lequel aucun contrôle n’est réalisé (situation sans modèle, sans règles), ce qui induit que tous les fraudeurs dans ce jeu de données sont validés. Ce que cela implique, c’est:
-
Comme tous les dossiers y sont validés, il n’y a ni acceptation ni rejet, ce qui permet d’avoir une certitude sur l’échéance de chacun des dossiers (fraudeurs ou non fraudeurs). La limitation à cette certitude provient du temps nécessaire pour pouvoir catégoriser un dossier comme fraudeur, ou plutôt pour catégoriser les dossiers non fraudeurs. En effet, pour effectuer cette classification, il faut avoir attendu suffisamment de temps pour être certain qu’un dossier jusque-là non fraudeur ne le deviendra pas par la suite. Cette durée provident des définitions métier de la cible évoquées plus haut.
-
Le groupe de contrôle coûte cher. Tous les dossiers fraudeurs qui passent par le groupe de contrôle sont validés, ce qui constitue une perte financière immédiate pour l’organisme. Entrent alors en consideration plusieurs éléments :
-
Les pertes générées par ce groupe de contrôle seront-elles compensées par les apports (gains) que le modèle fournira?
-
Quelle taille donner à ce groupe de contrôle pour trouver un équilibre entre les pertes financières provoquées et sa capacité à apporter l’information nécessaire à l’amélioration du modèle ? En effet, il faut pouvoir être certain que les mesures effectuées sur le groupe de contrôle représentent significativement les performances mesurées et ne sont pas dus à la variabilité introduite par la taille du jeu de données.
-
Ce groupe de contrôle peut ainsi être utilisé de deux façons: pour l’évaluation du modèle et pour son entraînement.
Evaluation: sans ce groupe de contrôle, on évalue les résultats sur un jeu biaisé (avec des rejetés dont on ne sait rien), et on se retrouve alors à tester nos prédictions contre des fraudeurs supposés qui sont peut-être des dossiers sains en réalité. Le groupe de contrôle nous permet de nous affranchir de ce biais et d’évaluer réellement les performances du modèle.
Entraînement: le groupe de contrôle peut être utilisé comme un jeu d’entraînement complet (et donc débiaisé) ou bien être combiné au modèle initial pour débiaisage. En effet, le groupe de contrôle représentant une faible proportion des commandes de par sa nature même, l’intervalle de temps pour récupérer un jeu conséquent est relativement important.
L’idée est alors par exemple, et c’est ce que nous avons fait dans notre cas, de construire un modèle complémentaire au modèle initial, entraîné sur ce groupe de contrôle, et destiné à prédire uniquement sur les dossiers prédits comme douteux par le modèle initial.

Le modèle initial ayant été paramétré pour être relativement conservateur (et donc privilégié les faux-positifs aux faux-négatifs), cette technique permet un débiaisage très efficace et diminue fortement le nombre de faux-positifs au prix de quelques faux-négatifs supplémentaires. De plus, elle permet d’utiliser un groupe de contrôle de taille modeste car seule une faible proportion de dossiers est prédite douteuse par le modèle initial.
Un bémol qu’il est nécessaire de rajouter est que, comme dit précédemment, la mise en place d’un groupe de contrôle coûte cher. Et notamment, la justification de sa mise en place est tributaire du ratio entre le coût des faux-négatifs et la perte d’opportunité représentée par les faux-positifs. En effet, si on se place dans le cas où un faux-négatif (validé à tort) coûte 5 fois moins que ne pourrait rapporter un faux-positifs (dossier sain rejeté à tort) non rejeté, alors le groupe de contrôle se justifie, puisqu’il fera perdre 5 fois moins (par dossier) en validant des dossiers à tort qu’il ne rapportera en validant des dossiers sains (qui seraient rejetés à tort sinon). Si on se place dans le cas inverse, à savoir le cas où un fraudeur coûte 5 fois plus que ne rapporte un dossier sain, il faut alors bien étudier l’opportunité d’une telle mise en place (par exemple, dans le cas d’organismes de crédits, un dossier sain rapporte les intérêts d’un crédit alors qu’un fraudeur coûte la totalité du crédit, soit un ratio très important de l’ordre de 1 sur 50 dans le cas d’un taux de 2% d’intérêt).
CONCLUSION
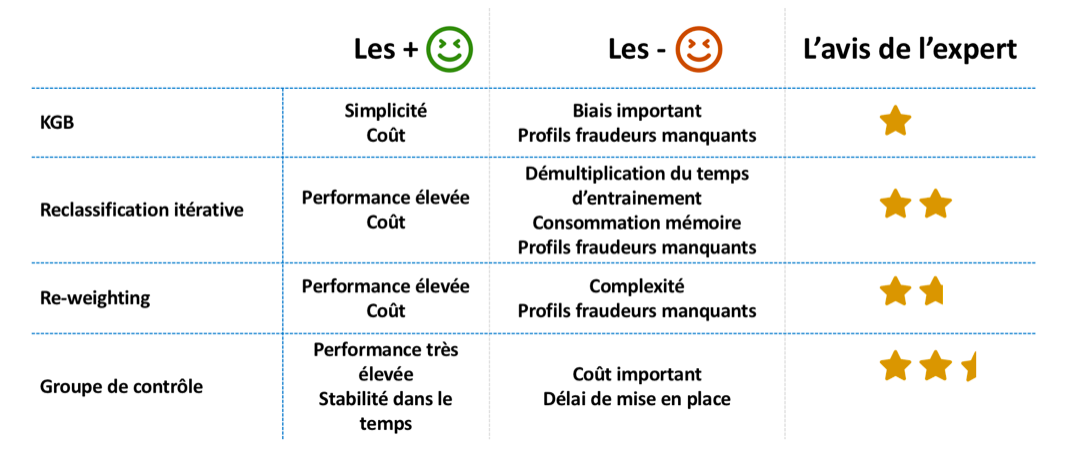
Nous avons pu parcourir tout au long de cet article certaines des principales problématiques que nous avons pu rencontrer, ainsi que les approches que nous avons mises en place pour les adresser. Afin de conclure sur ces techniques, voici un benchmark synthétique des éléments que nous avons pu discuter plus haut.
Enfin, il est, selon moi, essentiel de rappeler deux points que nous avons évoqués plus haut, et qui constitue une conclusion et une ouverture vers la suite.
Le premier point concerne le fait que ces approches sont fortement dépendantes du secteur d’activité dans lequel est supposé évoluer le modèle, comme nous avons pu le voir dans le cadre de la mise en place d’un groupe de contrôle et des coûts générés.
Le deuxième et dernier point, qui me semble très important, est de rappeler que le modèle est ici inscrit dans le cadre d’un processus, et est directement suivi par des contrôles manuels réalisés par des analystes compétents. Le modèle n’est alors pas destiné à remplacer des contrôles manuels, et n’est pas suffisamment performant pour cela d’ailleurs, mais fonctionne de façon performante en association avec ces contrôles manuels. La Data Science vient alors en renfort d’un processus pour accompagner les métiers.
BIBLIOGRAPHIE :
-
Asma Guizani, Traitement des dossiers refusés dans le processus d’octroi de crédit aux particuliers.. Business administration. Conservatoire national des arts et metiers – CNAM, 2014. French.
-
Asma Guizani & Besma Souissi & Salwa Ben Ammou & Gilbert Saporta, UNE COMPARAISON DE QUATRE TECHNIQUES D’INFÉRENCE DES REFUSÉS DANS LE PROCESSUS D’OCTROI DE CRÉDIT
