Uncategorized
07/09/2018
Faîtes connaissance avec NiFi (1/2)
Temps de lecture : 5 minutes
Cet article est une présentation de la technologie NiFi. Un second article sera consacré à un tutoriel pour commencer à utiliser cet outil.
Avec l’augmentation du nombre et de la complexité des systèmes producteurs et consommateurs de données dans les organisations, il devient nécessaire de disposer d’un outil centralisé pour assurer des échanges de qualité entre ces différents systèmes. NiFi est une technologie qui répond à ce besoin en permettant de gérer et d’automatiser ces flux de données, et participe à l’amélioration de la gouvernance des données.
NiFi est à l’origine un projet débuté en 2006 et porté par la National Security Agency (NSA) américaine sous le nom de NiagaraFiles (jeu de mot dont NiFi est la contraction), qui confie son développement à l’entreprise Onyara. En 2014, la NSA décide de faire passer ce projet en open source en le remettant à la fondation Apache. L’année suivante, en 2015, la société HortonWorks fait l’acquisition d’Onyara, et intègre NiFi à sa solution de traitement de données en transit HDF.
L’avantage le plus probant de NiFi par rapport à d’autres outils de gestion de données est sans aucun doute son interface utilisateur, qui permet de créer des flux de données de manière intuitive par glisser-déposer sans avoir besoin d’écrire de code. Cela permet en outre d’amener les experts métiers au plus proche du traitement de la donnée. En ce sens, il possède des similitudes avec certains ETL.
NiFi se caractérise aussi par sa polyvalence : il possède de d’innombrables connecteurs et est indépendant des sources et des systèmes de traitement auxquels il est relié. Il est aussi très extensible et il est facile d’y incorporer de nouveaux connecteurs après les avoir développés.
Eléments constitutifs
Le paradigme de NiFi repose sur celui du flow-based programming. Ce paradigme envisage une application comme étant une « usine de données », dans laquelle les données transitent à travers des connexions entre divers postes de traitement, à l’image d’un tapis roulant. Il est alors possible de modifier ces connexions sans modifier le fonctionnement interne de ces modules de traitement [1].
De la même manière, un flux de données NiFi est constitué de trois éléments de base :
-
les FlowFiles : ils représentent les données qui transitent dans NiFi. Ils sont composés d’une part de l’information utile à proprement parler (le contenu), et d’autre part d’un ensemble d’attributs clé/valeur qui font office de métadonnées ;
-
les Processors : ce sont les modules qui opèrent sur les données en exploitant les métadonnées. Ils ont en général une entrée et une sortie, et orientent les Flowfiles vers d’autres Processors en fonction du résultat de leur traitement ;
les connexions : elles relient deux Processors adjacents. Elles sont empruntées par les Flowfiles en fonction des traitements opérés par les Processors en amont. Chaque Flowfile constitue une queue dans laquelle résident les Flowfiles dans l’attente d’être traitées par les Processors en aval
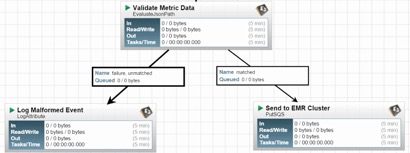
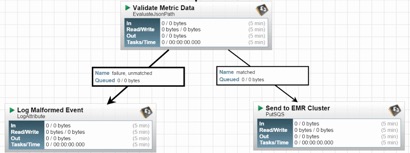
Figure 1 : Exemple d’un flux minimal qui teste la validité d’une expression JSON : auquel cas il la transmet à Amazon SQS, sinon il consignera l’événement dans un journal d’erreur
NiFi possède en plus un langage d’expression qui peut servir à configurer les Processors pour que ceux-ci puisse tirer parti des attributs des Flowfiles.
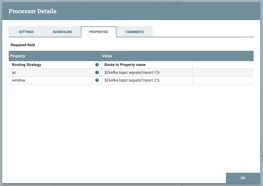
Figure 2 : Dans cette fenêtre de configuration d’un Processor Kafka, les paramètres ac et window sont renseignés grâce au langage d’expression de NiFi entre ‘${’ et ‘}’
Fonctionnalités
Les deux fonctionnalités les plus prisées de NiFi sont la provenance des données et la contre-pression.
La provenance des données est une fonctionnalité essentielle pour pouvoir étudier le cycle de vie des données et mieux investiguer en cas de problème (data lineage). Les Flowfiles étant immuables, ils sont enregistrés à chaque étape de leur parcours. Ils peuvent donc être inspectés à tout instant pour savoir pourquoi ils sont passés par telle ou telle connexion. Cela permet aussi de faire des modifications très fines du flux de données et d’en rejouer certaines séquences pour s’assurer que tout fonctionne correctement.
La contre-pression (backpressure) est un mécanisme qui met en pause un Processor directement en aval d’une connexion lorsque la queue est engorgée. L’intérêt de ce mécanisme est qu’il empêche NiFi de planter. Pour configurer la contre-pression, il est possible de caractériser cet égorgement en choisissant un seuil selon trois axes :
-
le nombre de Flowfiles présent dans la queue de la connexion ;
-
la taille maximale de stockage des Flowfiles ;
-
le délai maximal de présence d’un Flowfile dans la queue.
D’autres fonctionnalités non moins intéressantes existent, comme par exemple la possibilité d’enregistrer et de partager les flux conçus avec d’autres utilisateurs (templates).
Enfin, NiFi peut être distribué pour assurer la scalabilité de ses traitements de données. Dans cette configuration, il n’est pas nécessaire de désigner un nœud maître (master) : l’interface utilisateur est accessible depuis n’importe quel nœud du cluster (architecture Zero Master Clustering). Il est cependant de bon ton d’incorporer à cette architecture un load balancer en cas de panne du nœud choisi, sans oublier Zookeeper pour la coordination entre les nœuds.
Applications
Les applications de NiFi sont variées, en particulier lorsqu’il s’agit de consommer de la donnée en temps réel, et/ou lorsque les systèmes impliqués sont nombreux et complexes. Les cas d’usage peuvent être aussi différents que l’amélioration de l’expérience client en magasin [2] ou le monitoring de processus industriel [3].
Chez Quantmetry, NiFi a été utilisé dans un contexte IoT, pour lequel il est très bien adapté. En effet, l’IoT est le plus souvent caractérisé par des données fortement véloces et un nombre très élevé de dispositifs producteurs de donnée (le plus souvent des capteurs).
En 2016, le projet NiFi a vu l’introduction d’une solution complémentaire du nom de MiNiFi. Comme son nom le laisse entendre, MiNiFi est beaucoup plus léger et est destiné à être embarqué dans des dispositifs de faible capacité de stockage. L’objectif de MiNiFi est d’étendre la gestion des flux de données aux marges du système (capteurs, etc) et d’uniformiser la gestion des flux de données sous un même paradigme.