

AlphaZero : 1 algorithme, 3 jeux de plateau maîtrisés

Dans un article de recherche paru le 5 décembre 2017 (0), Google Deepmind généralise ses travaux en IA et leur application aux jeux de plateau avec AlphaZero. Après les améliorations successives d’AlphaGo pour le jeu de go (1), AlphaZero démontre ses performances aux échecs, shogi et go en battant à chaque fois les meilleures* IA existantes : Stockfish (moteur d’échec open source), Elmo et même AlphaGo Zero.
Portée de ces travaux : AlphaZero utilise la même stratégie d’apprentissage pour les 3 jeux et se base uniquement sur les règles du jeu
Plus précisément :
● AlphaZero se base uniquement sur les règles du jeu et non sur des connaissances humaines expertes pour les jeux en question. En particulier, aucune base historique de parties jouées, ou de bibliothèque d’ouvertures (de début de partie) n’est utilisée. De plus, AlphaZero ne nécessite pas de variables construites par des experts (cf notion de “handcrafted features” dans l’article), sur laquelle repose les programmes informatiques classiques du jeu d’échec (dont Stockfish).
● AlphaZero utilise le même algorithme de deep reinforcement learning et quasiment les mêmes paramètres d’apprentissage pour les trois jeux. Ainsi, AlphaZero a simulé quelques dizaines de millions de parties en jouant contre lui-même afin de pouvoir faire émerger des stratégies efficaces. Ce n’est que dans un second temps que l’algorithme est en mesure d’affronter son adversaire en évaluation quelques dizaines de milliers de positions à chaque tour.
Conséquences pour les joueurs d’échecs : une nouvelle page de l’histoire des échecs s’écrit
Depuis environ 20 ans, les meilleurs humains ne battent plus les programmes d’échecs. Cependant, l’approche d’AlphaZero est différente car elle est généraliste et ne requiert pas de connaissances expertes. L’effervescence de la communauté échiquéenne est bien illustrée dans cet article (4) et ses commentaires. On y trouve par exemple une citation du grand-maître Peter Heine Nielsen, qui est depuis plusieurs années le secondant du champion du monde Magnus Carlsen, où il déclare : “[…] I always wondered how it would be if a superior species landed on earth and showed us how they play chess. I feel now I know.” Dans ce billet de blog, seul un aspect du caractère révolutionnaire d’AlphaZero est détaillé.
AlphaZero offre une perspective nouvelle sur la théorie des ouvertures (les premiers coups d’une partie). Cette théorie des ouvertures est très importante dans la pratique des échecs et elle peut être lue au regard des différentes écoles de pensées qui se sont succédées dans l’histoire. Lors de la phase d’apprentissage, le caractère exploratoire d’AlphaZero a bien sûr fait apparaître des ouvertures bien connues, notamment celle connue sous le nom d’ouverture espagnole. On constate que cette partie espagnole a en effet nécessité un volume important d’exploration (quelques pourcents du total de toutes les parties simulées). On peut lire sur la courbe ci-dessous que parmi les 8 heures d’apprentissage où AlphaZero a joué contre lui-même, la partie espagnole (aussi appelée ouverture Ruy Lopez, du nom du moine espagnol qui a promu cette ouverture au XVIème siècle) a représenté jusqu’à 10% des parties simulées, pendant plus d’une heure.
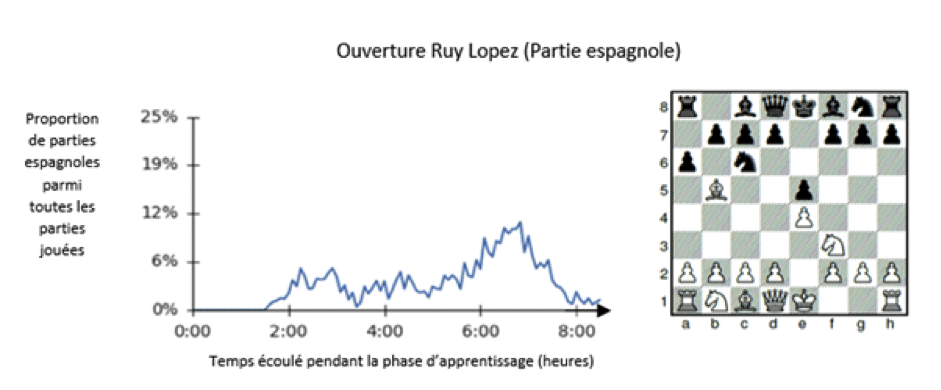
Figure extraite de l’article (0) : Evolution temporelle de la proportion que représente l’ouverture espagnole parmi toutes les parties jouées par AlphaZero contre lui-même en phase d’apprentissage.
Ce constat peut s’interpréter comme une confirmation, indépendante de l’histoire des échecs, que les positions qui succèdent à cette ouverture constituent un des “chemins” privilégiés qui se démarquent et qui constituent un terrain de jeu intéressant et plutôt équilibré des deux côtés de l’échiquier. Un telle prise de recul est unique dans l’histoire des échecs. Toutefois, les résultats disponibles dans l’article ne permettent pas encore d’aller plus loin en identifiant par exemple des ouvertures connues mais qu’AlphaZero aurait négligées ou pas retrouvées.
Perspectives plus générales
Ces travaux se situent dans la lignée des avancées en IA de l’équipe Deepmind, pour qui la prochaine étape devrait être dans le monde du jeu vidéo avec Star Craft 2. Cela impose de dépasser une vision tour-par-tour et de pouvoir élaborer à la fois des stratégies court et long terme (plus d’information, consulter (2)).
Plus largement, un certain nombre de challenges techniques restent à surmonter pour que ces travaux soient généralisables à des domaines intégrant des comportements humains. Une des nouvelles dimensions à explorer est par exemple la capacité à élaborer une stratégie dans des conditions plus proches de la réalité : quand une partie de l’information n’est pas disponible pour prendre la décision ou alors que les actions prises ne sont pas issues de comportements rationnels (cf cet article (3) qui donne plus d’éléments sur ces problématiques).
* Il y a néanmoins quelques débats concernant les conditions dans lesquelles les parties d’échecs ont été réalisées entre le programme d’échecs Stockfish et AlphaZero (4). En effet, il semble que Stockfish n’ait pas eu accès à la bibliothèque d’ouvertures dont il dispose habituellement.
(0) : https://arxiv.org/pdf/1712.01815.pdf
(1) : https://deepmind.com/blog/alphago-zero-learning-scratch/
(4) : https://www.chess.com/news/view/google-s-alphazero-destroys-stockfish-in-100-game-match
