

Intelligibilité d'un modèle lié un dispositif clé de la conformité

La Direction De la Conformité (DDC) de Crédit Agricole S.A. a développé des modèles d’apprentissage automatique liés au dispositif de filtrage des messages SWIFT par rapport aux listes de sanctions et d’embargo. L’intégration de l’Intelligence Artificielle dans le processus de conformité a pour objectif de sécuriser le dispositif à travers de l’aide à la décision. Il est bien sûr évident que l’introduction d’une technologie fondée sur des réseaux de neurones se doit d’être intelligible dans un contexte aussi sensible. Dans ce cadre, le Crédit Agricole a choisi de collaborer avec Quantmetry sur le développement de l’intelligibilité des modèles.
Intelligibilité
Pour reprendre la définition de F. Doshi-Velez et B. Kim [1], l’intelligibilité peut se définir comme étant la capacité à expliquer ou à présenter en des termes compréhensibles par un humain. Le projet de Crédit Agricole S.A. ayant un objectif in fine d’aide à la décision, il était important de pouvoir avoir cette intelligibilité pour de multiples raisons :
- Justifier les prédictions du modèle à l’opérateur pour établir une confiance entre les deux acteurs
- Comprendre les erreurs de prédictions du modèle et pouvoir l’améliorer a posteriori
- Auditer les versions futures du modèle sur l’interprétation des prédictions d’une même observation pour comprendre les possibles évolutions entre les versions.
Avec cet objectif en vue, différentes méthodes ont été étudiées pour construire l’intelligibilité du modèle. Pour la suite, l’intelligibilité locale a été retenue, c’est-à-dire la compréhension de chaque décision du modèle de manière indépendante et non pas de son comportement général, qui se définit comme étant l’intelligibilité globale. Le modèle se devait donc d’être explicable sur chacune de ses prédictions.
Il existe plusieurs méthodes d’intelligibilité locales qui ont vu le jour récemment (LIME, DeepLIFT, etc.) mais la méthode SHAP a été choisie car elle a pour ambition de rassembler plusieurs méthodes d’intelligibilité (dont les deux citées précédemment) sous une unique théorie mathématique qui prend ses racines dans la théorie des jeux et dans l’approximation des valeurs de Shapley (d’où le nom de la méthode : SHapley Additive exPlanations).
L’objectif de cet article n’étant pas d’entrer dans les spécificités de SHAP mais d’expliquer le retour d’expérience sur l’utilisation de cet outil. Pour plus d’informations sur SHAP, lire l’article de Scott Lundberg et Su-In Lee [2] sur le sujet. Plus d’informations sur l’intelligibilité en générale sont disponibles dans le livre blanc « IA EXPLIQUE TOI ! » de Quantmetry.
DeepSHAP
Comme expliqué précédemment, SHAP propose un cadre unifié pour plusieurs méthodes d’intelligibilité. Celles-ci peuvent être agnostiques (indépendantes du type de modèle) ou spécifiques (adaptées à un certain type de modèle). Dans cette dernière catégorie il faut citer TreeInterpreter ou DeepLIFT, qui sont respectivement associées aux modèles par arbres et aux réseaux de neurones. Ces deux méthodes appartiennent au cadre unifié de SHAP et se déclinent sous les noms TreeExplainer et DeepSHAP. C’est finalement cette dernière méthode qui sera utilisée pour ce cas d’usage, le modèle étant un réseau de neurones.
La spécificité de DeepSHAP est d’introduire une (ou plusieurs) valeur(s) de référence contre la(es)quelle(s) chaque observation va être comparée. C’est à travers cette comparaison que les différentes valeurs de Shapley associées à chaque variable et observation seront approximées. La théorie introduite dans l’article de recherche préconise l’utilisation de la moyenne comme valeur de référence. Cela pose cependant quelques problèmes pour des variables catégorielles et discrètes puisque les observations seraient comparées à une valeur de référence qui potentiellement n’est pas réaliste.
Dès lors le choix de la valeur de référence est un sujet qui doit être étudié pour chaque cas d’usage comme préconisé par l’article de recherche de DeepLIFT [3]. Celui-ci précise que ce choix est crucial et surtout dépendant de l’objectif in fine du modèle employé. En effet, doit on prendre comme référence une alerte sanction très pertinente ou peu pertinente, ce qui correspond respectivement à une intelligibilité de la non pertinence ou une intelligibilité de la pertinence. Le choix a été fait de prendre une référence très peu pertinente et d’exploiter l’intelligibilité comme une décomposition des contributions à la pertinence de l’alerte. Ce choix est important car il conditionne les usages futurs du modèle.
La première étape naturelle est de valider la prédiction de la référence car c’est une référence synthétique.
Par la suite, les valeurs de Shapley sont calculées comme étant les coefficients d’un modèle additif où la somme de ces coefficients et d’une constante équivaut au score donné par le modèle sur l’observation associée (la constante est égale à la moyenne des prédictions de toutes nos valeurs de référence).
Cette particularité fait que la prédiction peut être décomposée en chacun des effets de chaque variable en partant de la constante jusqu’à la prédiction avec des effets absolus de plus en plus petits.
Exemple de la méthodologie sur des données publiques
La décomposition des effets de chaque variable peut être affichée comme dans le graphique suivant (les données proviennent du dataset “census income” disponible directement à travers SHAP ou via UCI dataset. La variable cible de ce dataset est la prédiction du salaire de divers individus pour savoir s’il excède $50,000 ou pas) :
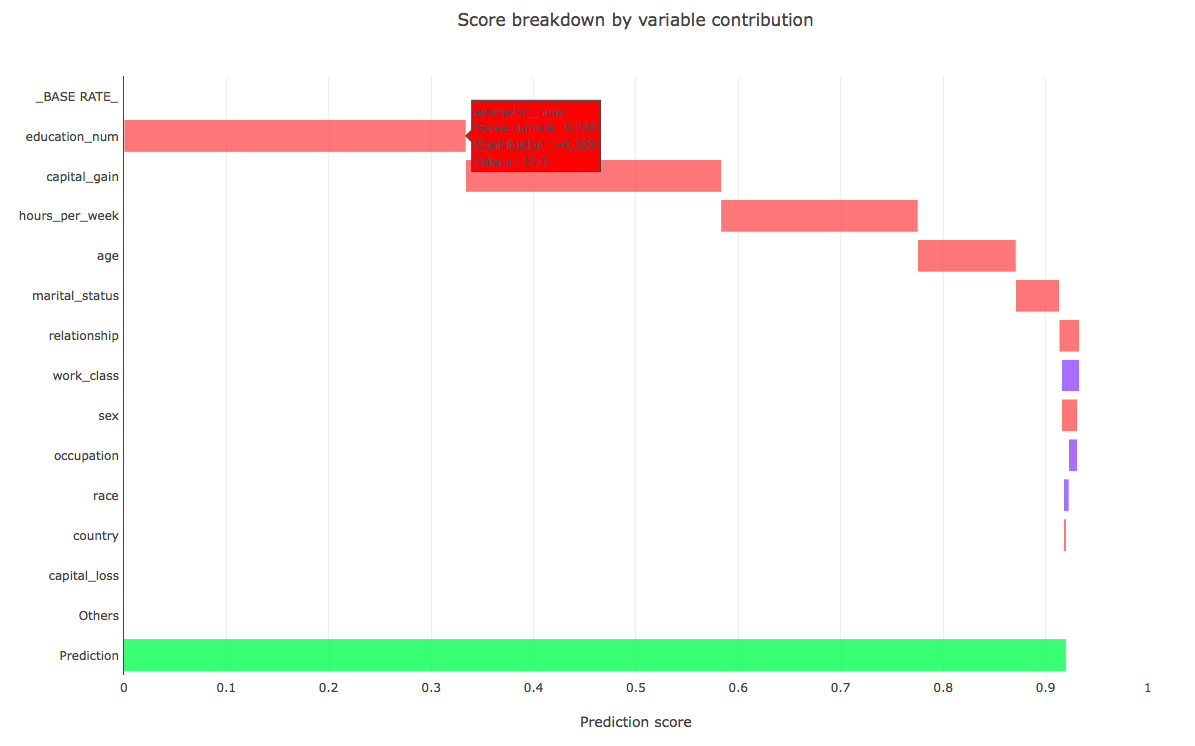
La référence utilisée est ici un individu que l’on pourrait considérer intuitivement comme ayant un salaire très bas pour comparer à la méthode employée dans le cas présenté plus haut concernant une alerte sanction peu pertinente. Ainsi les valeurs de référence sont une éducation très faible, un très faible nombre d’heures de travail par semaine etc.
Par ailleurs, la validation de la référence se fait donc ici puisque la prédiction est quasiment égale à 0 (cf. _BASE_RATE_ dans la figure ci-dessus). Dans un cas pratique il faut bien sûr valider le choix de cette référence avec un opérationnel afin qu’il puisse indiquer si celle-ci est à la fois logique et plausible.
Comme visible sur le graphique, il est intéressant de le rendre interactif afin d’avoir accès à la valeur de la variable, à la contribution (valeur de Shapley) et au score cumulé.
Par ailleurs, plusieurs variables peuvent être agrégées car provenant de la même source :
- Des variables dummies (ou un quelconque encoding) de la même variable catégorielle (agrégation déjà présente dans le graphique ci-dessus)
- Des variables provenant de la même source de données ou indiquant des valeurs similaires
- Des agrégations pertinentes au niveau opérationnel
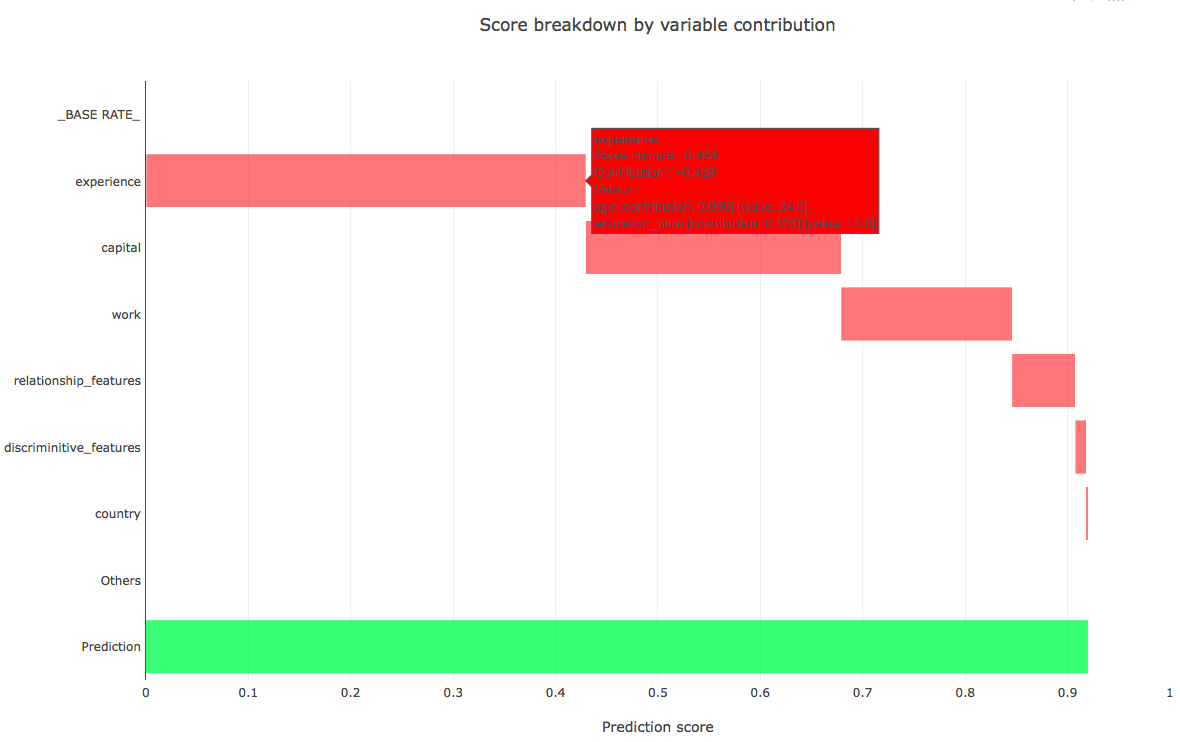
En ré-utilisant la propriété additive du modèle de SHAP, ces différentes valeurs peuvent être sommées pour obtenir un résultat toujours pertinent dans cette analyse.
Dans le même exemple que précédemment, plusieurs variables ont été agrégées comme l’âge et l’éducation pour obtenir un proxy de l’expérience. D’autres variables ont été agrégées mais cela reste dépendant du cas d’usage.
Un dernier message est que l’intelligibilité d’un modèle de machine learning nécessite de nombreux échanges avec les opérationnels puisque ces derniers sont les plus à mêmes d’indiquer si le modèle est bien expliqué ou non.
Prolongements
Une fois cet objectif d’intelligibilité du modèle atteint, une autre étape est nécessaire avant de pouvoir faire confiance à ce dernier : la robustesse de celui-ci. En effet, plusieurs choses sont remarquables dans un modèle classique de machine learning à savoir que :
- Ses performances décroissent avec le temps pour des raisons de dérive des données (leur distribution change avec le temps) ou dérive du modèle lui-même (la loi de probabilité à approcher change avec le temps).
- Il est vulnérable à des attaques adverses ou même à de petites perturbations des données d’entrée.
Une manière de répondre à la première problématique consiste à monitorer les données ainsi que le modèle. Il est ainsi possible de suivre les métriques de performances des prédictions et vérifier si celles-ci sont pertinentes ou respectent la même distribution qu’auparavant.
Pour le second il n’existe pas de méthode, à notre connaissance, pour s’en prémunir. Des tests de sensibilité peuvent bien sûr être effectués pour connaître l’effet de telles actions sur le modèle, mais a priori pas de méthode pour dé-vulnérabiliser un modèle face à ce genre d’attaques.
C’est pour cela que le projet se poursuit sur l’étude des méthodes d’entraînements adverses fondées sur une approche d’entraînement antagoniste avec des réseaux de neurones (plus connu sous le nom de GAN – Generative Adversarial Network).
Conclusion
Dans un contexte sensible, l’Intelligence Artificielle ne peut être introduite sans un minimum de précaution. Une partie des risques est atténuée en l’utilisant à une fin uniquement d’aide à la décision mais pour le reste il faut faire confiance dans le modèle en lui-même. Cette confiance dans le modèle peut se séparer en plusieurs parties :
- Une confiance en ses performances
- Une confiance en le choix de ces décisions, à savoir son intelligibilité
- Une confiance en la robustesse de ces décisions malgré des perturbations dans les données ou des attaques adverses
Dans le cadre de ce projet, les deux premières étapes sont atteintes et la troisième et en bonne voie.
Références
[1] Finale Doshi-Velez and Been Kim. Towards a rigorous science of interpretable machine learning, 2017.
[2] Scott Lundberg and Su-In Lee. A unified approach to interpreting model predictions, 2017.
