

Le Deep Learning : plongée en eaux profondes

INTRODUCTION
Difficile de ne pas en avoir entendu parler lorsque l’on s’intéresse à la data science et au Machine Learning. Le « Deep Learning », c’est le domaine à la mode en intelligence artificielle.
Et pour cause ! Les modèles basés sur le Deep Learning atteignent des résultats incomparables dans de nombreux domaines :
-
Reconnaissance et classification automatique d’images et de vidéos. Si comme Saint Thomas vous ne croyez que ce que vous voyez, allez jeter un coup d’œil à cette petite api bien sympathique : http://www.clarifai.com. Vous chargez n’importe quelle image et le modèle vous renvoie un ensemble de tags décrivant son contenu. Essayez-le c’est bluffant !
-
Reconnaissance et classification automatique de son
-
Traitement du langage naturel. Skype a mis au point récemment un système de traduction automatique qui repose sur des réseaux profonds. Un bon article sur le sujet : ici.
-
Classification et résumé automatique de documents
-
Systèmes apprenant automatiquement à jouer aux jeux vidéo (de loin l’application la plus importante !) : Google Deep Mind a récemment mis en place une technologie combinant Deep Learning et apprentissage par renforcement (1) afin de permettre à des machines d’apprendre par elles-mêmes à jouer à des jeux Atari. Sur une bonne partie des jeux existant, les machines se sont révélées être meilleures que les humains !
Mais quelle est cette technologie qui fait des miracles ? Comment ça fonctionne ? Qu’est ce qui est nouveau par rapport à ce qui existait avant ? Qu’est ce qui fait que ça marche si bien ? Qu’est ce qui a permis à cette discipline d’émerger ces dernières années ?
Après avoir fait un rapide historique de la discipline, cet article présente les grands principes de fonctionnement et les grandes problématiques liés au Deep Learning et apporte des éléments de réponse à ces questions. Cet article prendra appui sur la description d’un cas particulier d’architecture profonde : les Deep Belief Network.
DEEP LEARNING : THE BIG PICTURE !
Des modèles d’inspiration biologique : les réseaux de neurones
Les modèles de Deep Learning sont des réseaux de neurones. Les réseaux de neurones sont des modèles qui s’inspirent (très schématiquement) du fonctionnement du cerveau humain, et en particulier de sa capacité à extraire des structures (des patterns) à partir de données brutes. Prenez le cortex visuel par exemple, dont l’étude a largement inspiré le développement des algorithmes de Deep Learning. Imaginez que vous regardez une photo d’un chat. Lors de ce processus, votre cerveau traite l’information par étapes successives : il va d’abord repérer des formes géométriques très simples : des angles et des lignes, puis il va les combiner pour former des formes un peu plus compliquées (des arcs de cercles, des combinaisons de ligne), puis combiner ces dernières pour créer des formes encore plus compliquées, etc. A la fin du processus, les différentes transformations de formes opérées par votre cerveau vont venir activer la case « chat » de celui-ci, et vous savez qu’il y a un chat sur la photo (tout ça pour ça).
Les modèles de Deep Learning s’inspirent de ce principe : à partir d’une donnée brute en entrée, ils opèrent un grand nombre de transformations successives, permettant de découvrir des représentations de plus en plus abstraites de ces données. Les transformations opérées sont des combinaisons d’opérations linéaires et non linéaires. Ces transformations permettent de représenter la donnée à différents niveaux d’abstraction.
Concrètement, les modèles de Deep Learning sont des réseaux de neurones, avec un grand nombre de couches. Chaque couche du modèle correspond à un degré d’abstraction différent. Dans le cas de la reconnaissance d’image, la première couche correspond à la donnée brute (niveau d’abstraction nul) : un ensemble de pixels par exemple. La dernière couche correspond aux sorties (niveau d’abstraction maximal). Cela peut être par exemple les catégories d’objets qu’on cherche à reconnaître sur les images : chien, chat, personnes, etc. On appelle la couche d’entrée et la couche de sortie les couches visibles, et l’ensemble des couches intermédiaires les couches cachées.
Les deux éléments qui résument le mieux le Deep Learning sont ainsi :
-
La capacité à fitter des fonctions complexes: En appliquant un grand nombre de transformations complexes et en triturant les données d’entrées dans tous les sens, les modèles de Deep Learning sont capables d’apprendre des fonctions complexes (en fait, ils sont même capables d’interpoler n’importe quel ensemble de points !)
-
La capacité d’abstraction : Cette notion d’abstraction est fondamentale car elle constitue l’une des forces du Deep Learning : il permet d’apprendre automatiquement différentes représentations des données. Il permet ainsi d’extraire, automatiquement, à partir de données brutes, différents patterns dans les données, des moins abstraites (des lignes et des angles si on prend l’exemple des images), au plus abstraites (des concepts humains hautement philosophiques : un chat par exemple). Cette capacité à découvrir des structures est en pratique particulièrement utile car elle permet de s’affranchir (dans une certaine mesure) de l’étape souvent pénible de feature engineering (travailler sur les variables d’entrées pour trouver une bonne façon de représenter les données).
La suite de cet article explique en quoi le Deep Learning est une avancée par rapport aux autres modèles de Machine Learning et notamment par rapport aux réseaux de neurones « classiques » (i.e. non profonds).
Remarque : Une annexe qui explique plus en détail le principe des réseaux de neurones est disponible à la fin de l’article.
APPRENDRE ET GÉNÉRALISER
Les limites des réseaux de neurones sont intimement liées aux notions d’apprentissage et de capacité de généralisation.
Il y a toujours deux grandes étapes lors de la construction d’un modèle prédictif de Machine Learning : la phase d’entrainement et la phase de prédiction.
Lors de la phase d’entrainement, on présente des données labellisées (qui constituent la base d’entrainement, ou la base d’apprentissage) au modèle et on modifie les paramètres du modèle pour que celui « colle » le mieux aux données (c’est-à-dire pour que celui-ci soit capable de bien prédire les labels des données).
Pendant la phase de prédiction, on utilise le modèle entraîné sur de nouvelles données non labellisées pour faire de la prédiction.
Un modèle bien entraîné doit respecter deux règles :
-
Etre suffisamment complexe pour capturer la structure des données
-
Avoir des bonnes capacités de généralisation : c’est-à-dire faire des prédictions précises sur de nouvelles données sur lequel le modèle n’a pas été entraîné.
Un modèle peut avoir de très bonnes performances sur les données sur lesquelles il a été entraîné, mais avoir de mauvaises capacités de prédiction sur de nouvelles données. C’est ce qu’on appelle le sur-apprentissage. En général, plus le nombre de paramètres du modèle est grand (plus le modèle est complexe), plus le risque de sur-apprentissage est important.
LES LIMITES DES MODÈLES ÉTROITS
Et c’est là que ça coinçait. Les réseaux de neurones étroits sont en théorie de bons modèles capables d’apprendre des structures complexes. En fait, il a même été prouvé qu’un perceptron (un réseau de neurones avec une couche cachée est un approximateur universel(2) , c’est-à-dire qu’il permet d’approcher aussi bien qu’on veut n’importe quelle fonction mathématique. Le gros problème est pour être capable de modéliser des fonctions complexes, ces réseaux étroits ont besoin de beaucoup, beaucoup de neurones dans la couche cachée, et donc que le modèle a beaucoup, beaucoup de paramètres. Et c’est là que le bât blesse : en pratique, sur des fonctions hautement variables, les modèles étroits vont avoir de bonnes performances sur les données d’entrainement, mais de très mauvaises capacités de généralisation sur des données nouvelles.
Pour résumer, on peut dire qu’on pourrait presque tout faire avec des réseaux étroits, si on disposait d’une infinité de données pour les entraîner.
LES MODÈLES PROFONDS À LA RESCOUSSE
Les avantages des réseaux de neurones profonds (avec un grand nombre de couches cachées) par rapport à leurs cousins étroits sont connus depuis longtemps. Peu après le développement des premiers modèles de réseaux de neurones, à la fin des années 50, les chercheurs ont réalisé qu’augmenter le nombre de couches permettait théoriquement d’améliorer les capacités d’apprentissage de ceux-ci. En fait, la théorie montrait que ce qui pouvait être fait avec une architecture étroite pouvait être fait avec une architecture profonde, en utilisant un nombre total de neurones, (et donc de paramètres) beaucoup moins important, ce qui prémunit ces modèles (dans une certaine mesure) du sur-apprentissage !(2)
Alleluia ! Des modèles capables d’apprendre des fonctions complexes et en plus qui possèdent de bonnes capacités de généralisation !
Bon, si ça avait été aussi simple, cela ferait plus d’un demi-siècle qu’on ferait du Deep Learning et le sujet ne serait plus du tout aussi hype. Alors, qu’est ce qui a coupé court aux si belles promesses (théoriques) des réseaux profonds ? Qu’est ce qui explique que le Deep Learning n’est devenu une discipline mature que récemment ?
DE LA DIFFICULTÉ D’ENTRAINER DES RÉSEAUX PROFONDS
Au début des années 60, de nombreux chercheurs motivés par les promesses théoriques des réseaux de neurones profonds se sont attelés à les entraîner, mais l’entrainement se révéla souvent être de piètre qualité. En effet, les méthodes traditionnelles d’entrainement sont des méthodes supervisées comme la rétro propagation de l’erreur sur des réseaux aux paramètres initialisés aléatoirement, et s’avéraient inefficaces. Du coup, un bon nombre de chercheurs ont jeté l’éponge et les espoirs suscités par les réseaux profonds se sont petit à petit évanouis au cours de la seconde moitié du siècle.
Le problème vient donc de la méthode d’entrainement. Lorsque l’on entraîne un modèle de manière supervisée, on cherche à minimiser une fonction de coût qui quantifie l’erreur entre ce que le modèle prévoit (sur le set d’entrainement) et ce qu’il devrait prévoir. Pour minimiser cette fonction dans le cas des réseaux de neurones, on utilise l’algorithme de la rétro propagation de l’erreur. C’est une méthode à descente de gradients : on part de paramètres initiaux, et, itérativement, on fait des petites modifications des paramètres du réseau pour diminuer l’erreur (quantifiée par la fonction de coût). Ce qu’il faut comprendre, c’est qu’on ne trouve pas analytiquement la meilleure solution, une descente de gradient part d’une solution initiale et cherche une meilleure solution autour de cette solution initiale. Avec cette méthode, on est certain de trouver un minimum local, mais pas le minimum global (c’est-à-dire la meilleure solution).
La descente de gradients est une méthode qui fonctionne bien dans des cas « simples » : si on a une belle fonction bien convexe, alors on est certain de converger vers le minimum global. Or dans le cas des réseaux de neurones profonds, cette fonction de coût n’est pas belle à voir : souvent peuplées d’affreux minima locaux et de plateaux en tout genre, les méthodes à base de descente de gradients fonctionnent mal : le problème est qu’en partant d’une solution aléatoire, on a peu de chance d’être proche d’une bonne solution globale, et la descente de gradients aboutit à un minima local qui constitue une mauvaise solution.
CE QUI A DÉBLOQUÉ LA SITUATION
Les progrès théoriques
En 2006, le chercheur Geoffrey Hinton propose une nouvelle méthode d’entrainement des réseaux de neurones profonds qui va faire son petit effet dans le domaine. Sa solution consiste à introduire une étape de pré-entrainement non supervisée (c’est-à-dire une méthode dans laquelle on ne donne pas au modèle la sortie attendue) pour aider les systèmes à apprendre les représentations intermédiaires (3)
L’idée est de modéliser chacune des paires de couches du réseau par une Restricted Boltzman Machine (une machine composée de deux paires de couches). La première couche et la deuxième couche forment ainsi ensemble une première RBM, la seconde et la troisième forment une deuxième RBM, et ainsi de suite.
On entraine ensuite chacune des RBM de manière non supervisée, chacune prenant ses entrées sur le signal d’entrée propagé en amont du réseau. Par exemple, les entrées de la première RBM sont les exemples d’entrainement en entrée du système. Les entrées de la deuxième RBM sont les sorties de la première RBM (entrainée) après propagation du signal d’entrée au travers de celle-ci. En simplifiant un peu, le but de cet entrainement est d’apprendre la distribution des données d’entrées. Plus précisément, l’idée est de modifier les paramètres du réseau pour augmenter la vraisemblance (comprendre la probabilité) de l’ensemble d’entrainement.
En agissant de la sorte, le modèle pré-apprend en quelque sorte la distribution des données. Une fois pré-entraîné, les paramètres des modèles sont plus proches d’une bonne solution globale.
L’empilement des différentes RBM ainsi pré-entraînées constituent un perceptron multicouche appelé Deep Belief Network (DBN). On applique ensuite aux DBN une étape d’entrainement supervisée (par exemple une rétro-propagation de l’erreur). Cette dernière étape supervisée est appelée « fine-tunning », et se révèle en général beaucoup plus efficace après l’étape de pré-entrainement, car on ne part plus d’une solution initiale aléatoire.
Les progrès techniques
La méthode développée par Hinton repose sur une « astuce » qui permet de limiter le nombre de calculs pendant la phase d’apprentissage non supervisée (qui en fait est en théorie infinie, ce qui est assez embêtant en pratique). Toutefois, le nombre de calculs en combinant les phases non supervisées et supervisées restent très important. Ainsi, il y a encore une dizaine d’années, il aurait été inenvisageable d’entrainer des réseaux tels que ceux qui sont utilisés aujourd’hui (plusieurs dizaine de couches, plusieurs milliers voire dizaine de milliers de neurones). La spectaculaire augmentation des capacités de calculs (liée à l’augmentation des capacités en RAM, des capacités de traitement des CPU et à l’avènement des GPU) a changé la donne et rendu ce genre de calculs possible.
Un domaine toujours vivant
Les méthodes développées fonctionnent bien en pratique, mais au fond, il existe très peu de résultats théoriques expliquant comment et pourquoi ça fonctionne si bien. Contrairement à d’autres modèles qui rentrent dans un cadre mathématique rigoureux, on avance ici un peu à tâtons, en ayant plus des intuitions sur le pourquoi ça marche que de réelles démonstrations.
Notons que de nombreux chercheurs travaillent actuellement sur ces questions. Par exemple Yann Le Cun, qui dirige le laboratoire d’intelligence artificielle de Facebook et qui est le spécialiste des réseaux convolutionnels (un autre type de réseaux profonds), a récemment écrit un article sur le lien entre les modèles atomiques et le Deep Learning. Dans cet article, il obtient quelques résultats théoriques permettant de garantir la qualité des prédictions.
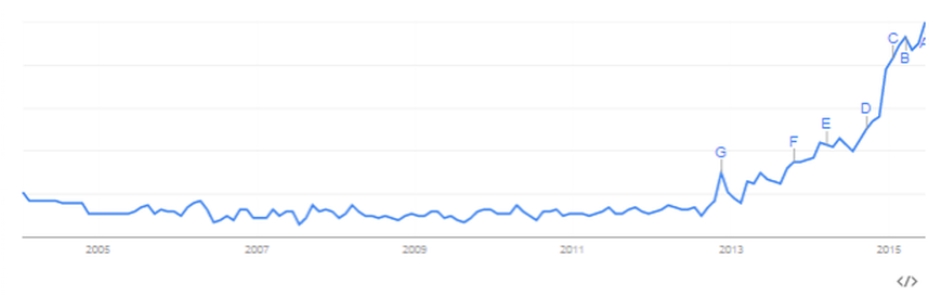
Le Deep Learning qui s’est d’ores et déjà imposé par son efficacité foudroyante dans un grand nombre d’applications, reste donc un sujet d’actualité brûlant : la preuve en graphes avec l’évolution du nombre de recherches « Deep Learning » au cours des 10 dernières années :
RAPPEL SUR LES RESEAUX DE NEURONES
Biblio :
(1) Playing Atari with Deep Reinforcment Learning :https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf
(2) Learning Deep Architecture for AI : http://www.iro.umontreal.ca/~lisa/pointeurs/TR1312.pdf
(3) A fast Learning algorithm for deep belief nets :https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf
