

Model As Code : automatisation du déploiement de modèles R en production (1/2)
L’industrialisation de modèles est une étape charnière du cycle de vie d’un projet Data Science mené au sein d’une entreprise. On observe que cette partie est encore rarement traitée alors qu’elle est indispensable pour l’exploitation continue des résultats des modèles.
Lorsque qu’un modèle finalisé présente un pouvoir prédictif satisfaisant en phase de développement, la mise en production permet de le déployer et de l’exploiter de manière continue et automatique et ce, en minimisant la charge de travail (i.e. : sans avoir à solliciter à nouveau l’intervention de Data Scientists, Data Engineers, etc.) Les différences entre les technologies utilisées en production et celles utilisées pour prototyper les modèles rendent généralement cette étape délicate.
Cette série de deux articles présente plusieurs retours d’expériences sur la mise en place de notre approche « model as code » pour raccourcir voire annuler le temps de mise en production comparativement aux techniques classiques. Ce premier article, présente les briques générales de notre Proof of Concept et un exemple d’implémentation sur un environnement type Web-API. Le deuxième article fera l’objet d’un retour d’expérience d’une implémentation « scalable » sur environnement Big Data – Hadoop.
De manière générale les modèles développés en R ne sont pas exploitables en dehors de R et de l’appel à la fonction predict. La mise en production de ces modèles consiste trop souvent à devoir retranscrire le code R dans un langage adapté à l’environnement de production cible (Java, C++, etc.). Ce type d’approche est coûteux en temps et mobilise des compétences pointues dans différents domaines. La méthode que nous proposons consiste à déployer le modèle encapsulé dans un format sérialisé directement accessible à la suite de la phase d’entraînement du modèle sous R.
La sérialisation
Sous R, l’encapsulation d’un modèle est possible sous trois formats principaux : pmml, rda et rds. Le format ou norme pmml est un fichier xml qui décrit les caractéristiques principales d’un modèle suivant la norme élaborée par le Data Mining Group. Par exemple, le fichier pmml d’une régression linéaire spécifiera les coefficients d’interception et la pente. Ce format XML n’est cependant pas idéal pour tous les modèles, à l’instar des modèles GBM ou GAM.
Les formats rda et rds sont des formats sérialisés binaires qui contiennent toute l’information détenue dans un objet R sous forme compressée. Ils permettent de stocker n’importe quel objet R et donc des modèles entrainés. La différence entre le format rda (équivalent du RData) et rds réside dans la généricité de l’objet sérialisé. En effet, le format rda encapsule un objet entier (valeur et nom), qui sera déployé sous le même nom à la lecture alors que le format rds permet de stocker uniquement la valeur de l’objet (de manière anonyme). C’est donc le format rds que nous avons choisi d’exploiter dans ce projet.
Les modèles R peuvent parfois être volumineux car ils peuvent contenir de nombreuses données utilisées lors de la phase d’entraînement mais inutiles pour la phase de prédiction. Pour faciliter la mise en production, on peut avoir recourt à une « déshydratation » du modèle, qui consiste à enlever ces données supplémentaires afin d’alléger les phases de déploiement et d’exploitation du modèle.
Les objets rds sont exploités directement au sein d’une session R. L’objectif de notre approche est de permettre de lancer une session R dans un environnement de production afin d’exploiter les résultats du modèle exporté.
Web-API
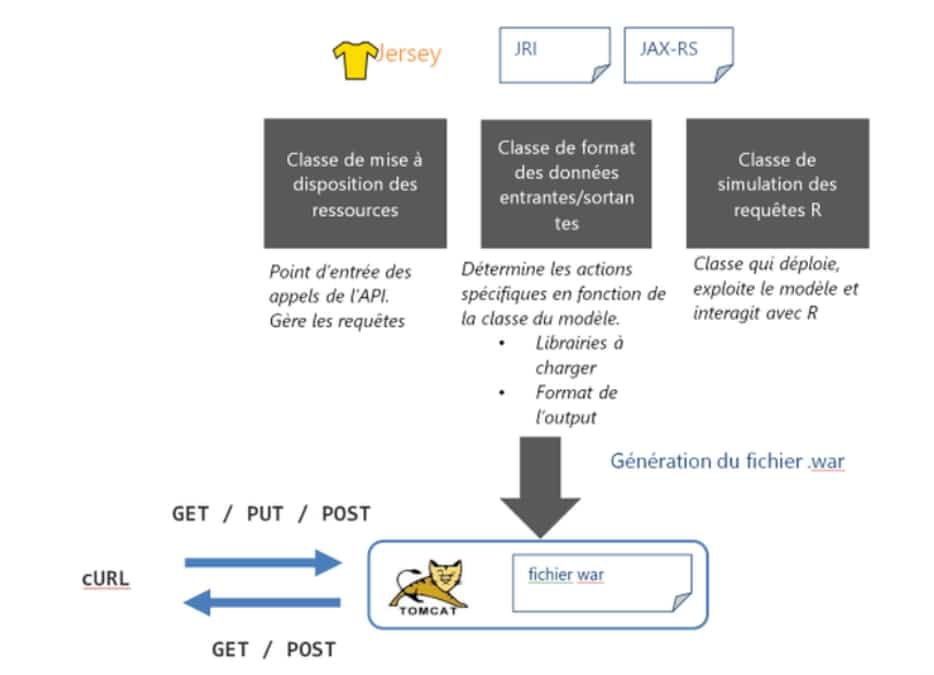
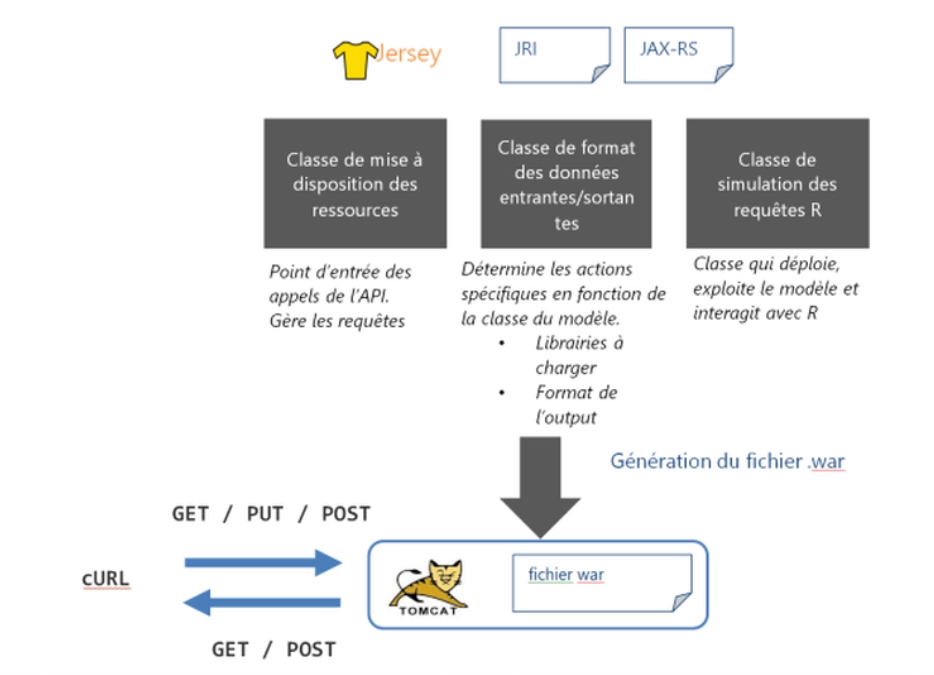
La première technique d’automatisation du déploiement de tels modèles s’est portée sur le webservice. La technologie Java Platform Enterprise Edition (Java EE) (1) a été retenue pour la réalisation de ce webservice. Cette technologie robuste et mature présente l’avantage d’être solidement implantée dans le paysage des systèmes d’informations des entreprises et d’être simplement activable sous forme d’API REST par requêtes http (via curl par exemple).
Pour déployer les modèles R sous une forme encapsulée, nous avons dû nous intéresser aux liens entre R et les autres logiciels, notamment Java, qui est un langage fortement présent dans les systèmes d’informations classiques ainsi que ceux orientés « Big Data ». La librairie rJava, fusionnant les projets rJava (Java dans R) et JRI (R dans Java), permet d’établir ce lien entre R et Java : c’est-à-dire d’ouvrir une instance de R à partir de Java ou inversement.
L’architecture de l’API REST que nous avons développée avec Jersey (2) est inspirée de l’outil de déploiement de modèles pmml, l’API open scoring. Elle gère trois types de requêtes :
GET : retourne au client la liste des modèles disponibles pouvant être exploités.
PUT : déploie le modèle et le rend accessible pour le webservice, sous un type (gam, gbm, régression linéaire, etc.) spécifié. Cette notion de type permet de charger les librairies nécessaires.
POST: lance une prédiction du modèle sur les données au format JSON. Le modèle et les données à utiliser sont spécifiés en paramètres
(1) Java EE est l’extension du framework Java standard, conçu en particulier pour les applications d’entreprise
(2) Jersey est un framework qui étend JAX-RS, l’API de référence Java pour la conception de webservice REST
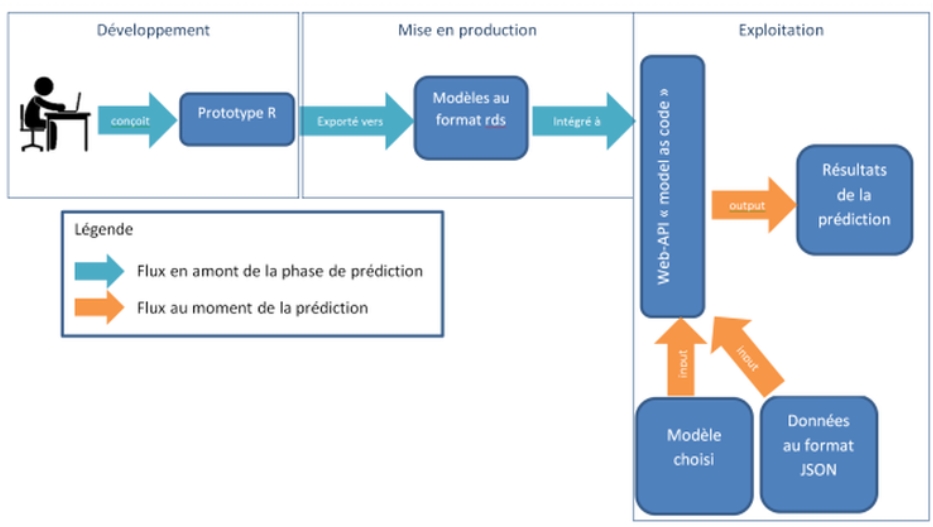
Le processus complet de la mise en production est alors le suivant :
-
Le pouvoir prédictif du modèle est validé en phase de développement
-
Mise en production
-
Le Data Scientist exporte le modèle R développé au format rds dans un dossier spécifique
-
Un client envoie régulièrement une requêtes PUT via curl pour déployer le fichier rds présent dans ce dossier.
-
-
Exploitation du modèle
-
Les données « fraîches » à scorer arrivent au format JSON
-
Un script client lance régulièrement des batchs de prédictions sur ces données par requêtes POST
-
L’API retourne les résultats ou score du modèle au format JSON
-
Ce simple prototype d’API permet de :En phase de déploiement : réduire voire annuler le temps de mise en production d’un modèle R :
-
export du modèle format rds en 1 ligne de code avec la fonction saveRDS
-
requête PUT pour déployer le modèle (mettre un exemple)
En phase d’exploitation : proposer des temps de réponses et des performances correctes très proches de ceux obtenus directement dans le cadre d’une session R.
Les performances de scoring avec l’API dépendent directement de la JVM qui fait tourner le webservice et de la mémoire allouée à R. Des paramètres laissés par défaut sur une machine grand public nous ont permis d’avoir des temps de réponses inférieur à 3s pour scorer un fichier de 10 000 lignes (avec 5 variables) par un gbm. Par défaut cette même JVM « décrochait » avec un Heap Space error à partir de fichiers de l’ordre du million de lignes. Bien que perfectible et optimisable cette approche par webservice n’est pas entièrement scalable et peut, pour de très larges quantités de données ne pas supporter la charge. Nous avons donc, en complément développé la même approche « model as code » mais cette fois-ci en environnement Hadoop et Big Data entièrement scalable que nous vous présenteront dans le 2ème article de cette série.
