

Système Expert et IA pour améliorer la qualité des données dans un contexte web complexe et dynamique
Grâce à la digitalisation, les clients ont désormais à leur disposition un vaste éventail de canaux d’interaction avec leurs marques préférées (web, mobile, tablette, assistants virtuels et en boutique). La multiplication des interactions permet de collecter de plus en plus de données clients. La consolidation et l’interprétation de ce déluge de données clients sont souvent exposées à des problèmes de qualité avec un impact très important sur la relation client. Les raisons de non-qualité de données clients peuvent être très variées et liées à des problèmes techniques ou organisationnels : évolutions d’un site web sans standardisation des métadonnées, coquilles dans le paramétrage du référentiel de données. Aujourd’hui il existe des techniques innovantes et agiles pour surveiller et identifier les données erronées bien avant que les utilisateurs de données (ex. entités marketing ou relation client) ne s’en aperçoivent. Cet article présente un projet réalisé pour un opérateur de télécom avec des techniques de Data Engineering et de Data Science pour pallier à ce problème universel de non-qualité des données clients.
Les canaux d’interaction clients évoluent constamment, le risque d’anomalies de données clients aussi
Les canaux d’interaction clients se renouvellent en permanence pour ajouter des nouvelles fonctionnalités, pour élargir leur périmètre ou tout simplement, pour changer leur Look&Feel. Ils évoluent pour suivre l’évolution des nouveaux écrans (web, mobile, wearables, …) mais aussi les nouveaux besoins des clients (ajout de produits et d’offres, modification des options, refonte du design, personnalisation …). Le moindre problème dans la gestion de ces canaux d’interaction peut potentiellement générer des anomalies de données clients et avoir un impact important sur le business (client non reconnu, chatbot ne fonctionnant plus, manque de visibilité sur des campagnes marketing enclenchées, …). Dans ces conditions, il est important d’avoir un système proactif pour détecter des anomalies avant que le métier soit impacté. Dans notre exemple nous avons eu l’occasion de travailler avec un ensemble de sites web (un portail web) développés depuis plus de 20 ans et visités par plus de 10 millions d’internautes par mois. Ce portail couvre aujourd’hui toutes les offres de notre client et est développé constamment et en parallèle par une multitude de développeurs. Finalement, ce portail est basé sur une plateforme dotée de nombreux outils de gestion (BigQuery, SI de vente, Web analytics, Audience & campagne manager, …).
Système expert + IA en mode agile pour détecter et alerter en cas d’anomalies
Dans un contexte organisationnel très complexe (nombreuses équipes responsables de différentes briques sur l’ensemble du site web et qui interviennent à différent endroits de l’architecture) et un site web qui évolue constamment (nouveaux parcours web proposés régulièrement), le client a décidé de mettre en place un système expert doté d’une intelligence artificielle pour détecter et alerter en cas d’anomalies. Nous sommes donc intervenus afin de construire un outil intelligent capable de détecter au plus vite les anomalies en bout de chaîne. Cela permet d’accélérer et d’automatiser la détection de valeurs non cohérentes, et ainsi d’aboutir à une correction plus rapide, sans pour autant perturber le fonctionnement de la structure.
L’objectif final est triple :
- éviter aux équipes métiers une investigation manuelle et chronophage,
- détecter plus d’anomalies,
- pouvoir communiquer sur la qualité des données, afin de sensibiliser les acteurs intervenant dans le processus.
La migration des fonctionnalités data sur le cloud GCP, Google Cloud Platform, nous a permis de bénéficier d’une prise en main rapide en tirant parti des services managés comme Google Cloud Composer. Il fallait d’une part parvenir à un outil fonctionnel autonome, et d’autre part que les équipes du client puissent en assurer la maintenance et le devenir.
Adaptation à l’architecture déjà existante et utilisation de bonnes briques nous ont permis d’obtenir rapidement de premiers résultats en quelques mois
Ce MVP a pu aboutir à des résultats probants en l’espace de deux mois grâce à l’utilisation d’un environnement cloud opérationnel très rapidement.
Il a été très facile de s’intégrer à l’architecture cloud existante en créant un projet à part entière. Ce dispositif a permis au client de monitorer et sécuriser notre utilisation des ressources ainsi que nos accès aux différentes sources de données tout en laissant aux data scientists une grande liberté, notamment dans la création des différentes entités nécessaires. De plus, notre intégration dans l’architecture déjà existante a favorisé la reprise de l’outil développé par les équipes clientes pour de futures améliorations.
Première version du système basé sur la connaissance métier
L’un des objectifs de ce projet était de déterminer les erreurs de valorisation des variables enregistrées lors d’un parcours client. Nous avons alors été confrontés à la nécessité de définir ce qu’est une erreur. En effet, certaines erreurs peuvent être évidentes, comme une valeur manquante dans une variable constamment valorisée; tandis que d’autres erreurs sont plus subtiles et nécessitent l’appui expert du métier. Or, l’environnement du web marketing est fugace : des valorisations de variables apparaissent puis disparaissent du fait de leur temporalité.
Rapidement, nous avons pris conscience du besoin de parvenir à une rationalisation de cette connaissance métier, ou du moins à un transfert de connaissance.
Système d’expert enrichi par l’apprentissage automatique (Open source Skope Rules by Quantmetry)
L’exigence d’avoir un référentiel à partir duquel les données pourraient être comparées a constitué une des difficultés majeures du projet. Il s’est avéré compliqué d’établir ce référentiel du fait des nombreuses variables présentes, leurs possibles valorisations dépendantes du contexte et des autres variables notamment, ainsi que de l’évolution permanente de ces variables (ajout, suppression, modification etc.).
Afin d’accompagner les équipes clients dans la réalisation de ce référentiel, une approche par l’apprentissage automatique (Machine Learning) a été choisie. L’utilisation d’un algorithme non supervisé de détection d’anomalies appelé Isolation Forest a permis de s’affranchir des règles métier et d’établir un premier référentiel. Ensuite, les data scientists ont utilisé une librairie open source (d’intelligibilité) permettant d’élaborer des règles de décision aboutissant aux résultats obtenus par une méthode non supervisée comme l’algorithme d’Isolation Forest. Pour résumer, cette librairie, appelée Skope Rules, a permis de dégager les features prépondérantes dans la décision de classer telle variable comme anormale ou non. Cette librairie open source a été développée par Quantmetry. Les règles émises par Skope Rules étaient intelligibles par les équipes métiers, ce qui leur permettait de valider ou invalider les erreurs remontées.
Nous avons donc pallié à la difficulté d’établir un référentiel à la main en utilisant une approche non supervisée, couplée à une librairie d’intelligibilité afin d’obtenir une validation du métier.
Nécessité d’équiper le système expert + IA d’un système de monitoring et d’alerting pour le métier
Ce projet a abouti à 2 livrables précieux dans le monitoring de la qualité de données :
- Un outil d’alerting pour informer par email les équipes en cas d’anomalie et d’une manière hebdomadaire résumant les principaux KPIs établis avec le métier sur la qualité des données. Ce mail permet de faire un résumé de l’état des données à un instant T et notamment de mesurer l’impact de certaines actions (mise à jour du plan de tagging, évolution côté développement etc.) à l’échelle d’une semaine. Il permet aussi à l’ensemble de l’équipe de suivre à une échelle haut niveau la qualité de la donnée.
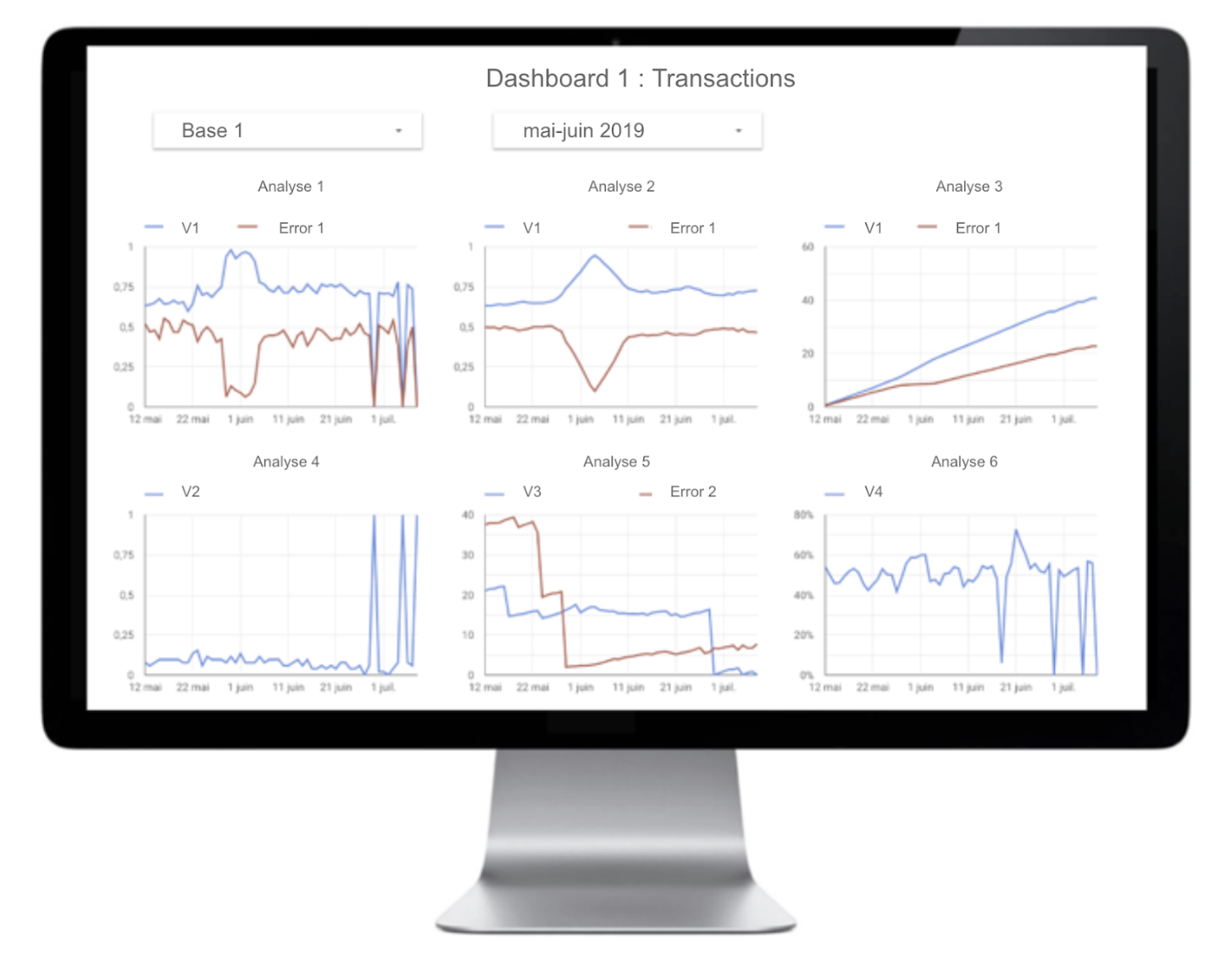
- Un dashboard à triple vocation :
- Permettre à l’équipe Pôle Data de comprendre en détails les KPIs de l’outil d’alerting en analysant l’évolution de la qualité variable par variable à la granularité temporelle voulue.
- La grande maniabilité de l’interface permet de créer des indicateurs très précis et d’identifier les points critiques rapidement.
- Présenter certains graphiques aux collaborateurs influents sur la qualité de la donnée comme les développeurs pour les sensibiliser sur cette question cruciale !
Next steps potentiels
Ce projet a permis à notre client d’enrichir et d’automatiser son suivi de qualité de données d’une manière agile, rapide et naturelle mais c’est aussi une première étape pour aller plus loin et développer de fonctionnalités additionnelles comme :
- un système de recommandation de corrections,
- une approche de machine learning supervisé pour détecter les anomalies,
- un modèle hybride entre un système d’expert, non-supervisé et supervisé.
