

TALAGRAND - Traitement Automatique du LAngage au service du GRANd Débat National

« Initier la mise à disposition, pour tout citoyen, de techniques d’Intelligence Artificielle destinées à appréhender le nombre important de contributions au Grand Débat »
Introduction
Depuis plusieurs semaines, Le Grand Débat National occupe le devant de la scène politique française. A l’initiative du gouvernement, son ambition est de permettre « à toutes et tous de débattre de questions essentielles pour les Français ». Il s’articule autour de 4 thèmes : Démocratie et la citoyenneté, Fiscalité et dépenses publiques, Organisation de l’État et des services publics, et Transition écologique.
Les citoyens ont la possibilité d’y contribuer selon plusieurs modalités : soit en participant à des initiatives locales (réunions publiques et cahiers de doléances en mairie), soit en soumettant leurs idées directement sur une plateforme en ligne. Cet article se concentre essentiellement sur cette deuxième source de participation. A travers une contribution en ligne, le citoyen a l’opportunité de donner son avis sur un ou plusieurs des 4 thèmes, en répondant à des questions fermées ou ouvertes, comme l’illustre la Figure 1 ci-dessous.
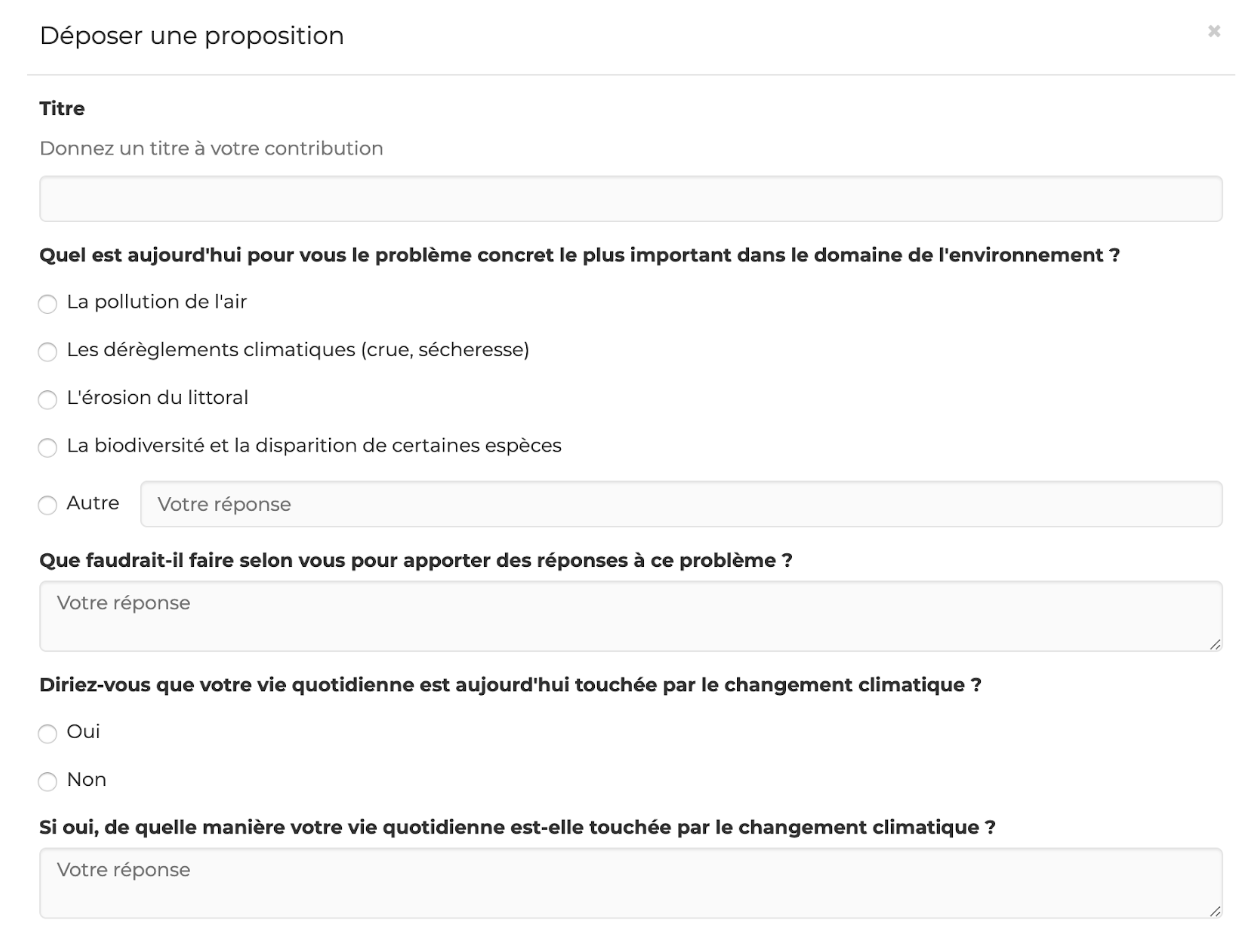
Figure 1 – Exemple de formulaire de participation au Grand Débat
Quelques ordres de grandeur : au 2 Mars, le nombre de contributeurs est de 72 000 en moyenne par thème. Le thème La fiscalité et les dépenses publiques compte le plus de contributions avec 94 000 participants uniques. Concernant la rédaction, chaque réponse compte en moyenne 35 mots avec encore une préférence pour le thème La fiscalité et des dépenses publiques pour lequel les participants écrivent en moyenne 5 mots de plus.
Quantmetry s’est prêté à l’exercice de l’analyse de ces contributions en ligne. Elles sont librement accessibles en open data sur data.gouv.fr. Sous la forme d’une courte expérimentation, nous avons souhaité initier la mise à disposition, pour tout citoyen, de techniques d’Intelligence Artificielle destinées à appréhender le nombre important de contributions au Grand Débat ; et ce dans l’objectif de :
- Explorer les idées exprimées de manière récurrente
- Résumer les milliers de réponses à une question donnée en quelques extraits caractéristiques
NB : nous ne rendons publique aucune interprétation des réponses. Le mandat que nous nous sommes fixés est davantage de réunir les outils nécessaires pour quiconque – avec des connaissances basiques en programmation – souhaite se constituer une opinion sur l’ensemble des contributions.
Les procédures sur lesquelles nous nous reposons sont librement accessibles à cette adresse : github.com/quantmetry/grand-debat. Au total, pas moins de 86 millions de mots peuvent être analysés. D’une part, nous encourageons les lecteurs curieux à utiliser ces outils pour se faire leur propre opinion sur les idées principales qui émergent. Mais également à itérer sur cette base et à proposer d’autres angles d’analyse.
Méthodologie
Détection de thématiques et des idées principales
Un premier angle d’analyse vise à détecter arbitrairement n thématiques et idées principales ou récurrentes exprimées dans l’ensemble des réponses à une question. Cela repose sur une procédure d’exploration non supervisée : la LDA. Cette approche fait l’hypothèse – raisonnable – suivante : chaque phrase exprime une idée unique. Ainsi, chaque phrase de chaque réponse est associée à l’une des thématiques identifiées, comme le suggère la Figure 2.
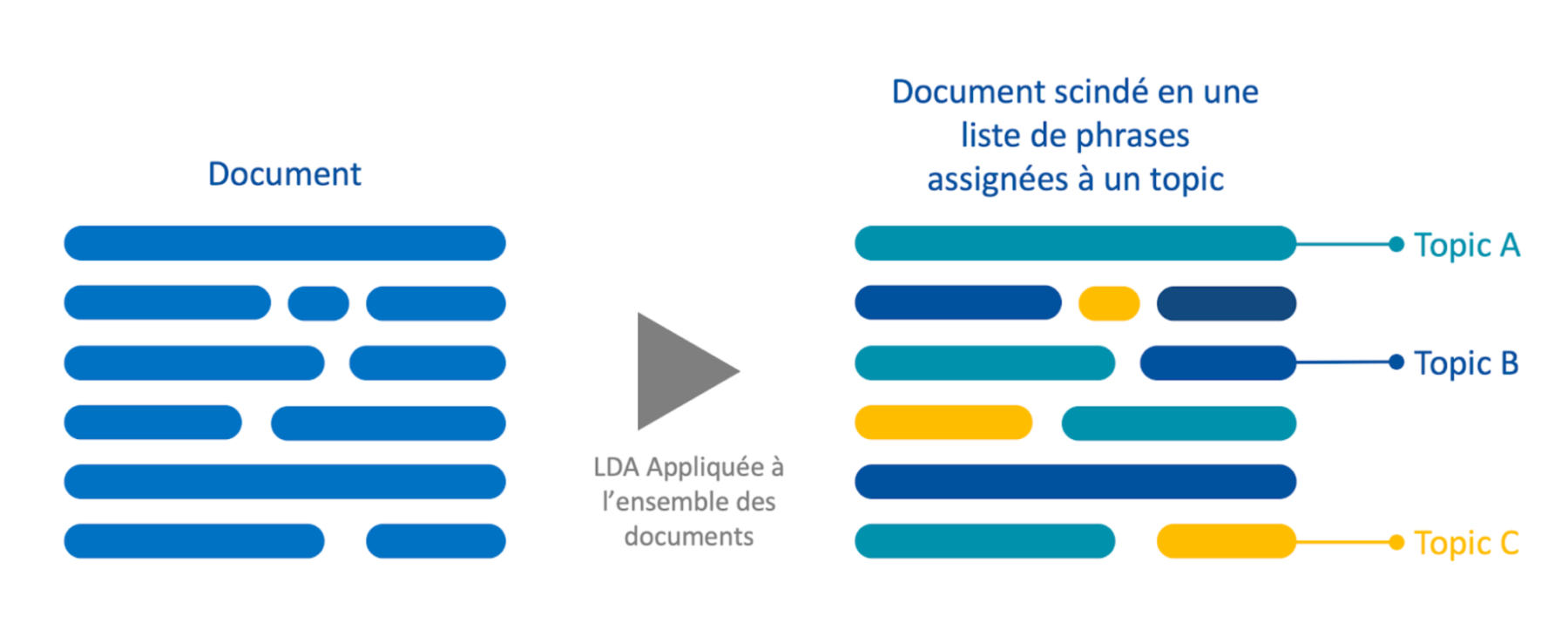
Figure 2 – Modélisation de chaque contribution comme un ensemble de phrases, chacune assignée à un topic identifié par une technique de LDA
En quelques mots, l’algorithme de LDA permet de décrire une thématique par un ensemble de mots clés. Par exemple, pour la question « Quelles sont toutes les choses qui pourraient améliorer l’information des citoyens sur l’utilisation des impôts ? », l’un des thèmes identifiés, parmi les n thèmes, est caractérisé par les mots clés suivants : [coût, santé, scolarité, défense, factures hospitalisation, éducation, hôpital, …]. L’un des avantages de la LDA est qu’elle s’interprète visuellement et simplement, comme l’illustre la Figure 3.
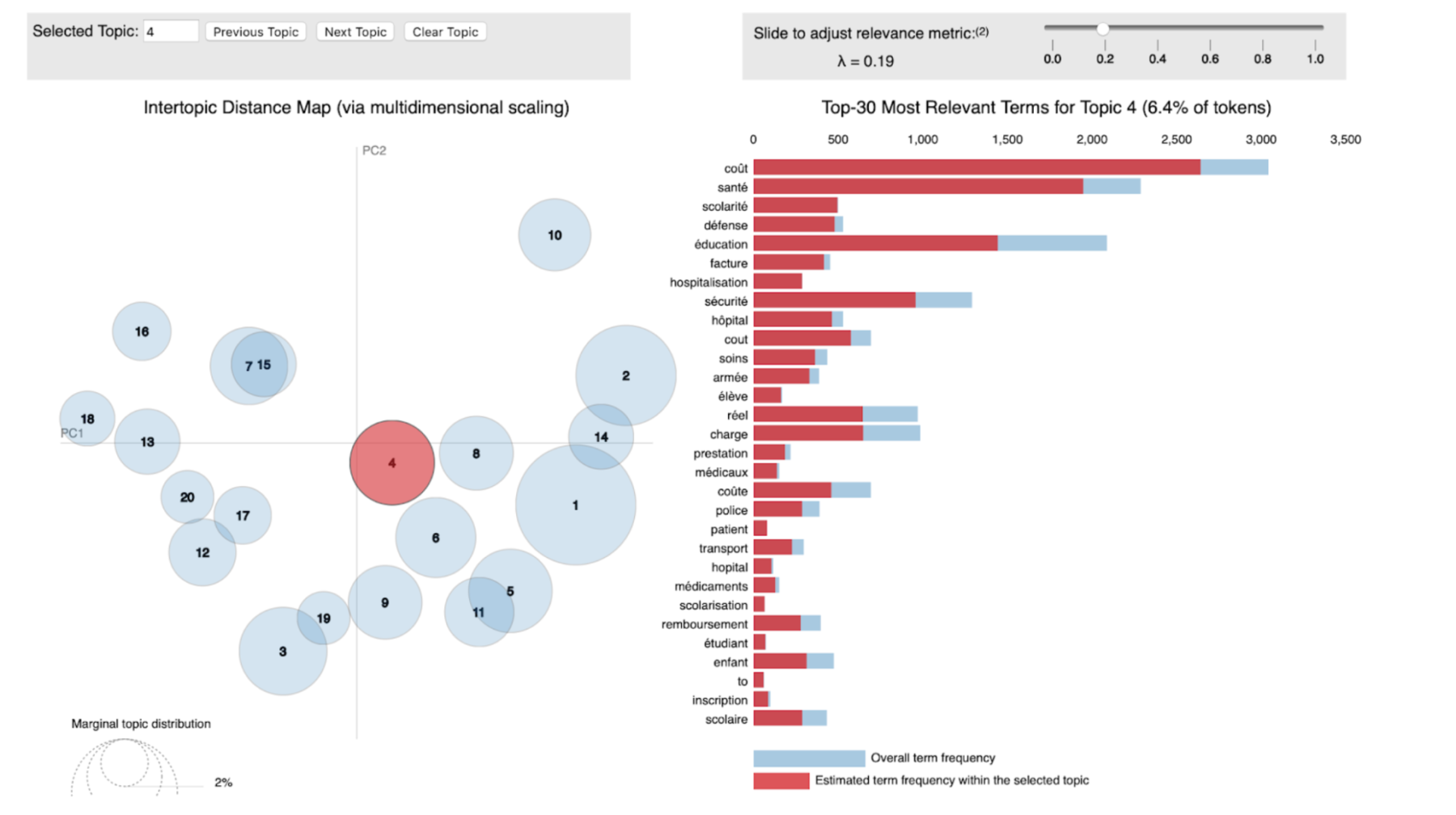
Figure 3 – Dashboard d’exploration des résultat de l’application de l’algorithme LDA sur les contributions du Grand Débat. La figure de gauche décrit la proximité entre les thématiques identifiées. Celle de droite décrit pour une thématique, les mots clés associés.
Synthèse des contributions pour chaque thématique identifiée
Un second angle d’analyse vise à faire la synthèse des milliers de réponses à une question. Cela repose sur une technique de résumé automatique dite extractive, c’est-à-dire qui cherche à constituer un résumé à partir de phrases du document source. La procédure proposée repose sur l’algorithme TextRank.
Pour l’exploiter, nous nous proposons de rassembler l’ensemble des phrases associées à une thématique (thématique générée par la première étape). Cet ensemble peut être vu comme un graphe. Les nœuds du graphe accueillent les phrases de cet ensemble ; et les liens du graphe correspondent à une mesure de similarité entre ces phrases (définie plus bas). Par suite, l’algorithme TextRank permet d’extraire les nœuds, dans notre cas les phrases, les plus caractéristiques du texte. Enfin, la phrase la plus caractéristique du graphe est retenue comme le titre de la thématique.
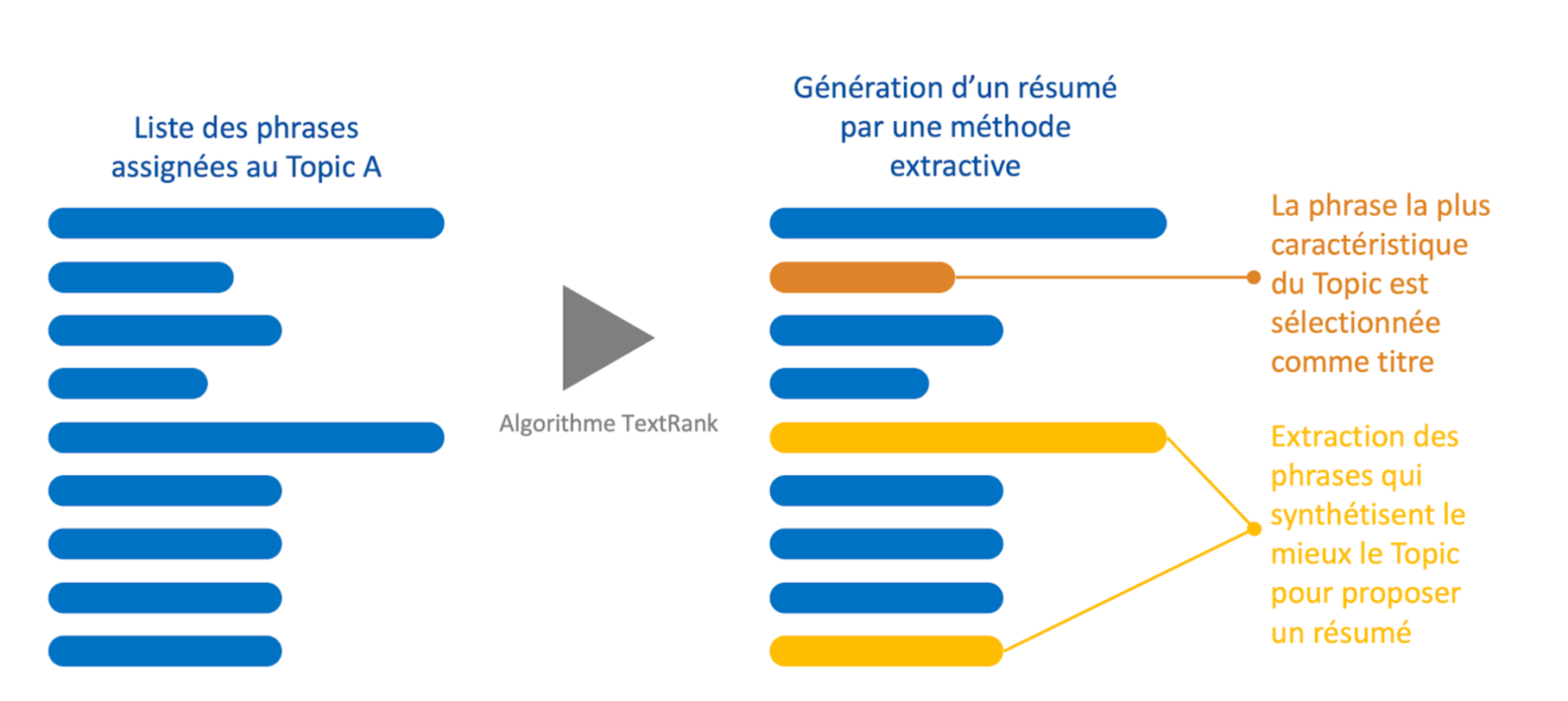
Figure 4 – Illustration de l’application de l’algorithme TextRank à un ensemble de phrases rattachées à une thématique identifiée.
Comme introduit plus haut, TextRank suppose de pouvoir mesurer la similarité entre deux phrases. Pour ce faire, nous utilisons une méthode de représentation des phrases sous la forme de vecteurs denses : le sentence embedding.
Chaque mot est représenté par un vecteur dense qui capture son sens. Nous avons ici entraîné nos propres embeddings, sur la base de l’ensemble des contributions au Grand Débat, via word2vec. Nous mettons à disposition une version allégée de ces représentations à cette adresse : github.com/quantmetry/grand-debat/data. Une phrase est ensuite représentée comme la somme des embeddings de chacun des mots qui la constituent, comme l’illustre la Figure 5. Une fois les phrases vectorisées, il devient commode de les comparer par calcul de distance standard. Nous avons ici utilisé la distance cosine, qui compare ainsi la proximité sémantique de chacune des phrases.
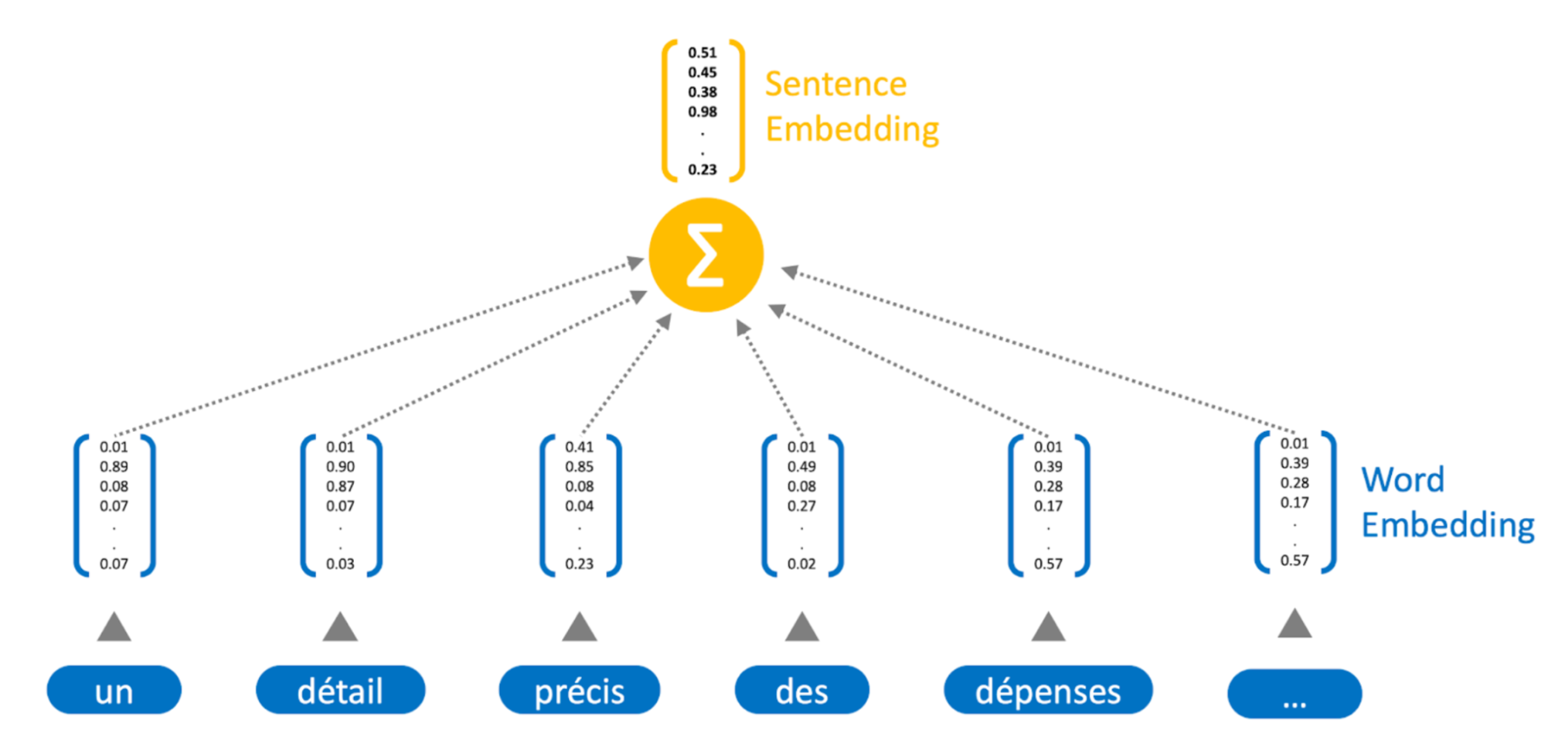
Figure 5 – Méthode de sentence embedding
La synthèse des analyses précédentes est restituée sous la forme d’un document texte structuré comme illustré en Figure 6. Le document est segmenté en paragraphes. Chaque paragraphe est constitué des phrases les plus caractéristiques de la thématique correspondante.

Figure 6 – Exemple de résultat obtenu avec le thème fiscalité et dépenses publiques
Conclusion
Cet article propose une premier outil d’analyse des contributions au Grand Débat National. Les méthodes exposées ci-dessus ne sont le résultat que d’une (trop) courte expérimentation et n’exploitent qu’une mince partie des outils de traitement automatique du langage : détection d’entités nommées, analyse de sentiments, ou encore génération de résumés, sont autant de pistes qui viendraient enrichir la compréhension et la synthèse des réponses apportées par les citoyens.
