

10+ tips to deliver machine learning in production

This short and straightforward blogpost aims at sharing several best practices for delivering machine learning projects into production. It’s based on Quantmetry experience of developing, deploying and monitoring a product recommendation API on AWS following MLOps standards. Processes and technological best practices will be discussed below, the motto being “going live, staying calm”. Of course, this article is not meant to be exhaustive but rather a quick reminder of several aspects based on Quantmetry’s delivery experience.
TL;DR
- All stakeholders should agree on:
- the inputs, features and outputs of each model, how each selected model works, how it will be used on a day to day basis, and the performances of the models that will be served ;
- a live performance evaluation process before the deployment in production ;
- a release management process as it has been the norm with continuous delivery and DevOps ;
- service or interface contracts for communication with other Tiers.
- Log, monitor and alert. Often. Always…
- Test, test and test again.
- When relevant, use a containerized stack and rely on an infrastructure as code with continuous deployment strategies.
- Manage your configurations wisely, storing settings values in as few places as possible.
- Fix all packages versions, including dependencies.
- All this, keeping in mind: the simpler, the better.
Processes
Machine Learning (ML) can be tricky to apprehend and subject to misunderstandings despite high hopes in automation and performance capabilities… This is especially the case when stakeholders manage many projects concurrently with little time granted to the ML project or lack technical background to understand (by themselves) the data science concepts at stake. So, before d-day, all stakeholders should agree on the inputs, features and outputs of each model, how each selected model works, how it will be used on a day to day basis and the performances of the model(s) that will be served to avoid any disappointment (or worse) weeks after the “go live”.
For instance, let’s consider a client scoring model, designed for marketing activities purposes. Months after the first score-based mailing campaign, it’s still possible that stakeholders ask about precision, recall and overall performance of the model. In this case, it would be a waste of time to re-explain the whole performance calculation process, maybe reaching the tipping point of “that’s not achieving what it was supposed to be, we shut down the project.”
 You’d rather avoid this for your machine learning stack.
You’d rather avoid this for your machine learning stack.
If the project reaches the GO/NOGO step to push the model into production (or not), it must have been assessed as valuable in previous evaluations and it’ll be necessary to be able to assess the true return on investment later. Hence, all stakeholders should agree on a live performance evaluation process before the deployment in production. Otherwise, any decision based on whether the project is performing as expected will not be made in due form.
Let’s consider a marketing use case for any company selling high price products (cars, luxury goods, etc.) which consists in scoring clients and pushing emails to top scored customers. The relevant performance KPIs are highly likely to be email opening or click rates rather than n days conversion rate (mainly due to the high price of the products). Then, it’s better for the project that all stakeholders have agreed beforehand that the objective of the campaign was click rate and not the conversation rate otherwise, when campaign results will be shared, there will be discrepancies.
We can also illustrate this need for live performance evaluation with our product recommendation use case. The process of building a recommendation engine is known for not having trivial and sometimes not relevant offline evaluation strategies. Hence, to decide whether model A is better than model B, a solution is to implement in production an A/B testing strategy where a percentage of users will receive recommendations from model A and the rest from model B. For the purpose of choosing which model is the best, it’s obviously necessary to be able to assess the performance of each methodology. In this case, one should make sure that A/B(/C) model performances are compared against control group(s) performances to decide whether those models are even performing better than no marketing action at all or standard business-driven recommendations (ex. pushing the most purchased hoodie for every one).
 Poor Efficiency? But you still have a performance evaluation process.
Poor Efficiency? But you still have a performance evaluation process.
Last but not least regarding the processes, all the people in the development team — data scientists, data engineers, software developers, etc. — should agree on a release management process as it has been the norm with continuous delivery and DevOps standards. As stated in Martin’s Fowler article Continuous Delivery: “Continuous Delivery just means that you are able to do frequent deployments but may choose not to do it, usually due to businesses preferring a slower rate of deployment [than with continuous development resulting in many production deployments every day]”. Hence, it seems essential to set up clear merge request processes, recurrent tests that must pass before a new release and, especially within markets with strong and specific expertise, it’s even possible to have the new pipeline outcomes verified by humans (visually checking the modeling outcomes for example).
As an example, in a product recommendations project with high brand image constraints, business people satisfaction has been the most relevant performance metrics and the final validation step before serving the model API to end users. We had to set scenarios for the business team to apprehend what would be recommended if the client has bought such and such products and be able to give the go for a new release. For this very iterative approach, building relevant scenarios and showcasing product images have been key drivers for success.
Tech
The first of the tech tips is: the simpler, the better… and this is true for every step in the pipeline: from the data ingestion, to the refinement and storage; from model selection to training and serving; for the selection of 10 insightful and maintainable features rather than 100 obscure ones; for the API design and implementation; for the logging and monitoring stack management, etc… Of course, this is especially the case, if it’s your first time going into production.
As an example, for the development of the API discussed above, we stuck to Flask and PostgreSQL database to retrieve, serve and store the predictions. Why? Because they are two reliable technologies, largely used within the community, easy to integrate to a containerized stack and they meet most of the requirements of such projects. This choice has proven to be a very practical approach for the development of the API and we strongly recommend to go simple before using complex services with loads of (unused) features.

This being said, a containerized machine learning stack is a very efficient way to put the whole system into production using continuous deployment strategies. Indeed, if one has two separated environments, replicating the exact same processes in both staging and production environments will be facilitated by dockerization and it’s even more powerful with cloud using multiple accounts and IaC (Infrastructure as Code)… the main difficulty being the simultaneous management of two or three environments. For additional reading on this topic, I would recommend the paragraph “Deployment Pipeline” of the blogpost: How to Build an End to End Production Grade Architecture on AWS Part 2.
For the purpose of the recommendation API, the data engineering team used Infrastructure as Code (IaC) to create and manage the services on both Dev and Prod accounts. Building all the pipelines in the Dev account while making sure that all the services (model and API containers, databases, Jenkins and Prometheus services, etc.) have been automatically created by script without any manual change, has been a true accelerator when we have had to go into production. An example could be the quick adaptation of task definitions for the containers when we had just to update several parameters to replicate the container deployment process from Dev to Prod.
A third tech tip would be: agree on and follow service or interface contracts for communication with other Tiers. Indeed, when reaching agreement on precise communication rules might be a burden, it simplifies processes, prevents failures and makes error management easier because one knows what to expect from others (a clear logging will be key). Doing so, one might prefer to keep the interface contract easily accessible and accessible since it’ll drive further developments and discussions with tech partners. Eventually, one would rather test and validate as soon as possible the communication between Tiers to make sure everyone complies with the interface rules, preventing any waste of time few days before pushing everything into production.
Illustrating this point with a project exposing a ML model through a classic REST API. The “key-value” body of the requests included required information for the recovery of a prediction and during QA tests we were not able to communicate… Digging to understand why, we found out that, when on the interface contract the client identification was supposed to be “client_id”, our counterpart went for “client” in their developments… so we could not catch the upcoming messages in the Kafka queue. Testing the interface contract beforehand would have saved us some precious time during QA tests.

Communication involves at least two persons
Log, monitor and alert. Often. Always… Logs are the only qualitative feedback one has on the automated processes that run in the background, metrics allow fast quantitative insights on the whole stack and alerts push notifications when necessary. For example, one can set up metrics to store and retrieve easily the number of API calls, additional rows in the client database after the data ingestion process — convenient for automated client scoring projects, or the number of errors in the model (re)training process which is useful to set up alerts if the training has failed. Regarding the implementation, using the ELK or EFK stack to manage logs has been really helpful and convenient to store and retrieve logs with Elasticsearch or visualize logs and create search queries in Kibana.
As time goes by, while logging is important but one might get used to seeing “logging.info” and even “logging.warning” for a recurrent wroing import (it’s working though, no problem) in the daily ETL pipeline. Worse, developers might no more read DAG logs every morning (that’s pretty expected) and even not pay attention to lost in the crowd true warning logs… That’s when you need an alerting stack.
Let’s illustrate alerting capabilities. Tech wise, we used a Prometheus server to manage the monitoring and alerting stack. If any metric would exceed a defined threshold, it would trigger an alert and notify the developers in a Slack channel. For example, in order to alert on the API requests errors, we had a counter initiated to 0 at the launch of the API container. When we received wrong HTTP inputs, the value of the error counter would increase and alert manager would detect this and trigger an error to notify the team.
Eventually, a best practice is to include retry and timeout patterns in the code when pushing data to outside services such as Prometheus. One does not want that his/her 12 hours job fails just before the end of the pipeline because the python process could not push its metrics due to an unavailable Prometheus Push Gateway… Hence, adding retry and timeout on such actions (with appropriate warning logs) is a good solution to avoid wasting time.
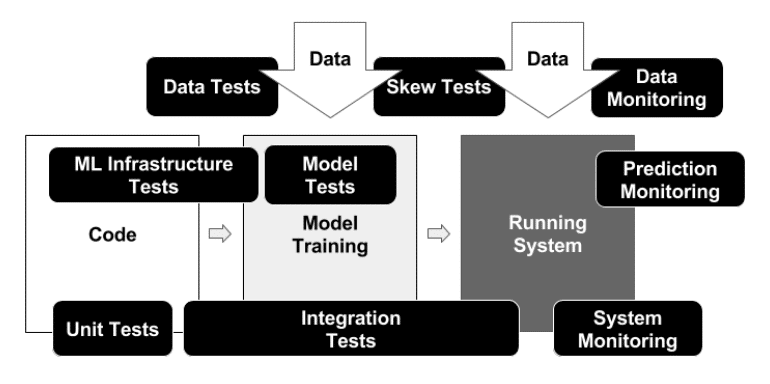 ML Based system testing and monitoring in The ML Test Score
ML Based system testing and monitoring in The ML Test Score
Test, test and test again. This is nothing new but it’s essential to check how the elements and services in the stack behave, if every communication channel performs as expected, if all the output files formats are the required ones, if the storage of HTTP request works well, etc.. It takes time though so it’s necessary to consider several testing periods while building the timeframe of the project, and, if the team is running late, postponing the go live to conduct the tests. Below is the test pyramid that covers almost all types of tests on the data, the model and the code which is well described in the Testing and Quality in Machine Learning of the blogpost Continuous Delivery for Machine Learning (CD4ML).
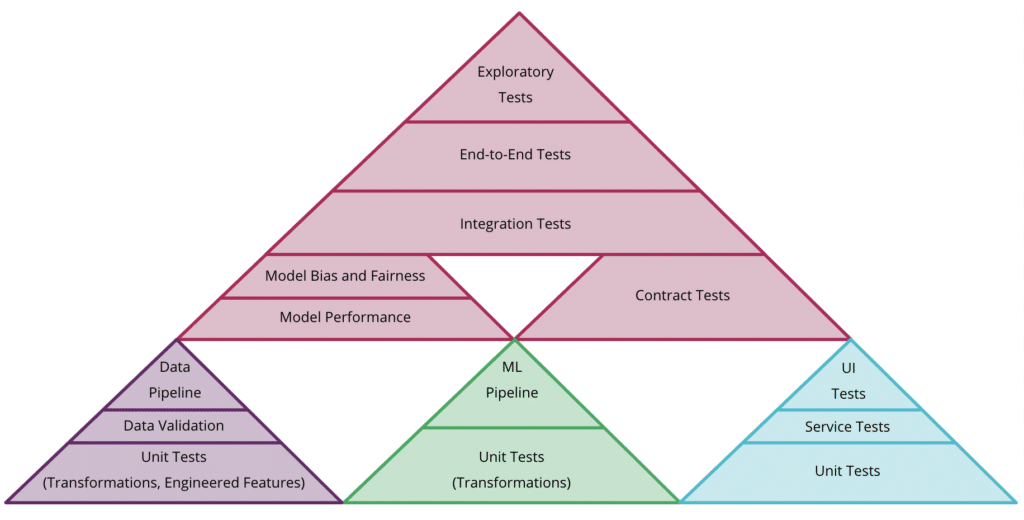 The test pyramid by Martin Fowler
The test pyramid by Martin Fowler
Regardless of the business case, data is usually subject to continuous changes such as evolution in data interpretation (concept drift), changes in the data distributions (data drift) or, for example, updates in the datalake ingestion pipeline by a third party due to technical updates or failures. Thus, it seems necessary to include tests in all the data pipelines to be notified when changes that could alter overall performances occur.
For the recommendation project, before the release, the model performance validation was a visual check by marketing teams. Therefore, in order to reproduce the validation process, we had to visually test the model relevancy at every new version of the model and the business rules. It was a manual and time consuming process since we had to deploy a new container, run through different scenarios and visually check the outputs. To automate this visual testing process and save copy/paste time, the idea was to include in the continuous deployment pipeline the creation of notebooks including templated scenarios and check that the changes meet the features expectations.

Manage configurations wisely, storing settings values in as few places as possible, following standard naming conventions and avoiding any hard coded value. For example, it’s possible to keep environment variables values in a secret store such as Parameter Store or Secrets Store on AWS, to use a settings folder containing Yaml files with an open source library such as Pyhocon / Hydra or to use specific and clean python scripts, containing only project variables. This will prevent an oversight of hard coded values deep inside the python package that could totally ruin the replication capabilities.
Using a secrets storing service has been really helpful for our projects when setting up a production ready continuous delivery pipeline. Indeed, thanks to this service, we could variabilize the Jenkinsfile and, for the container deployment, retrieve the latest parameters (database name, API name and url, etc.) and build containers the exact same way!
Last but not least, talking pipeline reproducibility, it’s a good practice to always fix packages and dependencies versions, especially with machine learning pipelines that use libraries such as xgboost or pandas. That’s to prevent any compatibility issue after major releases of those open source libraries and to simplify inquiry regarding a specific inference when one has to rerun the whole pipeline on a precise date. For this purpose, using Conda environments helps a lot since the package management system checks for package version compatibilities when building (or updating) the environment. Let’s keep in mind that, even if the package versions are all set, there might be environment setup issues if any of those libraries have not fixed their relative imports, so, once again, it’s always better to check environment creation in QA before going into production.
Going further
Despite best efforts and testings, it’s expected that a service (even the whole stack) goes down at a certain point after the go-live… Hence, all those tips and best practices are shared to help delivering machine learning projects into production and get ready for this specific task of resolving technical issues using tests, qualitative logs and quantitative metrics.
For further readings on the MLOps best practices, the projects that motivate this blogpost have been largely inspired by articles from Martin Fowler’s blog Continuous Delivery for Machine Learning (CD4ML), Google Cloud solutions MLOps: Continuous delivery and automation pipelines in machine learning or Christopher Samiullah’s blog How to Deploy Machine Learning Models. Eventually, I would also recommend to get a look at this great article Monitoring Machine Learning Models in Production from Christopher Samiullah and the The ML Test Score paper by Breck et al. (2017).
