

GPT-3, la dernière révolution du NLP ?

Introduction
GPT-3, le dernier modèle de traitement automatique du langage développé par Open AI, est indiscutablement spectaculaire. Il se distingue par une capacité de généralisation singulière. Il atteint des performances étonnantes avec un nombre très réduit d’exemples. Par ailleurs son architecture originale permet de répondre à un très grand nombre d’applications. Les agents conversationnels, la traduction, le résumé automatique ou la génération de texte ne sont qu’un éventail du champ des possibles. Le modèle est d’ailleurs pensé dans une perspective d’application industrielle avec de nombreux plugins destinés à faciliter son intégration.
Malgré son arrivée tonitruante dans le monde du traitement automatique du langage, GPT-3 s’inscrit pourtant dans le sillon des évolutions récentes de la chaîne de valeur NLP. Les modèles, de plus en plus complexes, sont paradoxalement de plus en plus accessibles. Le développement de l’Open Source permet la démocratisation de la recherche. Les librairies créées par des acteurs comme Hugging Face ou Open AI, facilitent l’utilisation des modèles qui peuvent être manipulés en quelques lignes de code. Cette transformation participe à l’évolution de l’expertise du traitement du langage. Plus besoin d’avoir des compétences pointues en Deep Learning ou en Machine Learning pour pouvoir utiliser les tout derniers modèles. GPT-3 vient encore abstraire la dimension technique puisque le modèle est accessible directement via une API. Par ailleurs, il peut être utilisé directement et sans aucune modification sur n’importe quel cas d’usage.
Cette direction passionnante n’est pourtant pas sans poser de question. La simplification extrême de l’utilisation de GPT-3 se fait au dépend de la transparence. En effet, le modèle n’est pas Open Source mais conditionné à l’utilisation d’une API propriétaire. L’accès se fait aujourd’hui en version bêta dont l’accès est fastidieux et qui sera payant à terme. D’un point de vue pratique, le modèle est uniquement disponible en anglais. Par ailleurs, le nombre incroyable de paramètres et de données utilisés pour l’entraînement rendent extrêmement complexes sa reproduction. Finalement, la quantité de données produit des biais inévitables difficiles à contrôler.
La transformation de la chaîne de valeur en NLP
En l’écho à l’accélération de notre société moderne, le traitement automatique du langage semble également connaître une évolution exponentielle. Cette transformation s’est d’abord illustrée par des progrès techniques et démocratise ainsi le traitement de cas d’usages complexes. La chaîne de valeur en NLP s’est ensuite progressivement déplacée au fur et à mesure que la communauté gagnait en maturité, de la conception de modèles from scratch à la mise à disposition de modèles pré-entraînés en Open Source ou via des API. C’est donc bien une rupture technologique catalysée par de nouveaux moyens de diffusion des modèles qui a permis une transformation de la chaîne de valeur en NLP. Finalement, ces évolutions déplacent les enjeux techniques vers un focus sur les cas d’usages.
Rupture technologique
De nouvelles architectures de réseaux de neurones : De nouvelles architectures de réseaux de neurones : les Transformers, sont introduits dans le papier scientifique Attention is all you need paru en 2017. Ces modèles se parallélisent facilement et permettent d’adresser de nombreux cas d’usages avec des architectures standardisées. Ils permettent des progrès significatifs pour toutes les applications de traitement automatique du langage : traduction, système de questions/réponses ou encore résumé automatique. Selon le populaire benchmark GLUE d’évaluation des modèles, les performances humaines ont été dépassées par les algorithmes depuis 2019 !
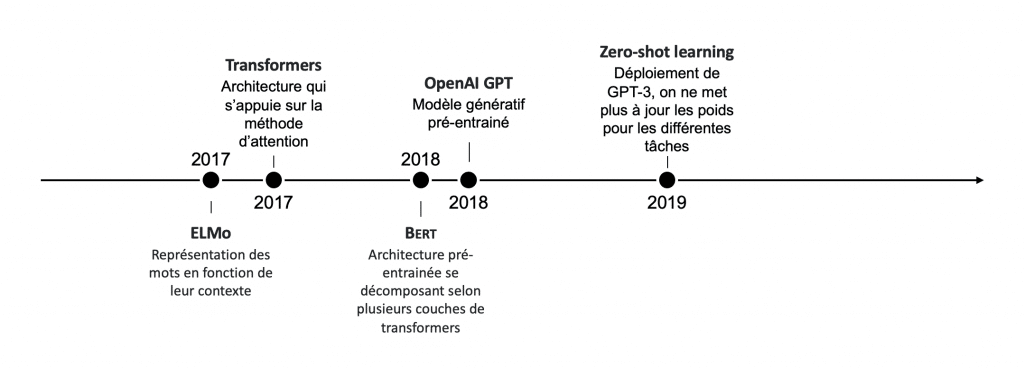
Figure 1 : Récentes publications qui ont illustrent les ruptures technologiques en NLP
De nouveaux paradigmes d’apprentissages pour les algorithmes : Les transformers introduisent de nouvelles méthodes d’apprentissages. Ces dernières permettent d’améliorer les propriétés de généralisation des modèles et de réduire drastiquement le volume de données labellisées nécessaires à la résolution d’une tâche. Dans cette configuration, le modèle est entraîné en deux temps. Il est d’abord pré-entraîné sur une tâche auto-supervisée comme prédire des mots manquants dans une phrase. Cette opération nécessite des quantités très importantes de données brutes mais pas de labellisation. Il peut ensuite être mis à jour de manière incrémentale sur n’importe quelle tâche (fine-tuning). Si la portée de généralisation obtenue pendant l’étape de pré-entraînement est suffisante, comme pour GPT-3, on peut même ne pas effectuer de fine-tuning. On parle de zero shot learning. Ainsi, à l’instar de ce qui a pu être observé en Computer Vision il y a quelques années, l’accès aux données tend à être un critère moins discriminant lors de la priorisation des cas d’usages en NLP. En effet, il est possible d’obtenir de très bonnes performances avec moins de données labellisées, souvent difficiles à obtenir pour les entreprises.
Des performances portées par la multiplication de la puissance de calcul : Les modèles de NLP ont vu leur nombre de paramètres drastiquement augmenter. GPT-3 cumule 175 milliards de paramètres, soit environ 1000 fois plus que les modèles récents, pourtant déjà gourmands en paramètres. Au-delà des progrès systémiques déjà évoqués, le nombre de paramètres semble être l’un des facteurs décisifs dans l’amélioration des modèles. Ceci est permis par l’incroyable augmentation de puissance de calcul et des volumes de données disponibles. Ces deux phénomènes semblent ainsi l’un des facteurs déterminant des progrès récents en IA. Notons toutefois que cette démesure nécessite une puissance de calcul importante qui peut induire des émissions de CO2 selon les équipements utilisés.
Une nouvelle manière de diffuser et partager les modèles
Une combinaison des acteurs académiques et industriels : La course au développement de modèles dans le NLP s’articule tant autour du monde académique qu’industriel. GPT-3 est développé par OpenAI qui se présente comme une entreprise à but non lucratif pour la recherche sur la recherche industrielle. Sur son blog, l’entreprise annonce un engagement de financement s’élevant à 1 milliard de dollars mais dont une fraction seulement serait utilisée dans les premières années.
Le développement de l’Open Source : A l’instar de l’ensemble des branches de l’intelligence artificielle, les progrès techniques en traitement automatique du langage sont portés par un partage très rapide des idées, des données et des modèles. La culture de l’Open Source importée de la Silicon Valley a permis une diffusion des savoirs sans précédent et ainsi l’établissement d’un écosystème ultra-dynamique autour de l’IA. Que ce soit à travers des repositories GitHub personnels, le développement de librairies comme Scikit-Learn (44k stars sur GitHub) pour la mise à disposition de modèles ML classiques ou le développement de frameworks de Deep Learning comme TensorFlow (152k stars sur GitHub) ou PyTorch (45k stars sur GitHub), les derniers outils pour pratiquer la Data Science sont accessibles à tous et dynamisent la recherche. Par exemple, la startup Hugging Face met à disposition les derniers modèles pré-entraînés à travers sa librairie Transformers. Ces derniers sont manipulables en quelques lignes de code et facilitent ainsi leur diffusion au sein des entreprises. Le modèle de base de BERT est par exemple téléchargé plus de 35 millions de fois par mois. Il n’est donc plus nécessaire dorénavant d’avoir des compétences pointues en Deep Learning ou en Machine Learning pour appliquer l’état de l’art en NLP.
NLP as a service : Au-delà de l’Open Source on pourrait maintenant parler on pourrait parler de “NLP as a service”. Le traitement automatique du langage se décline aussi avec des outils sur étagère extrêmement performants sans se confronter directement aux complexes algorithmes sous-jacents. Ces derniers permettent d’adresser des cas d’usages spécifiques sans besoin de compétences techniques dans le domaine. Les outils de traduction proposés par Google, Reverso ou DeepL sont extrêmement populaires. Avec l’apparition des APIs très génériques comme AutoNLP proposés par HuggingFace ou GPT-3 par OpenAI, plus besoin de se concentrer sur les aspects techniques, seules les spécificités métiers restent à la main des utilisateurs.
Le dernier né de cette évolution : GPT-3
Difficile de résumer ce modèle pantagruélique en quelques lignes. L’une de ses spécificités est de concrétiser “general task-agnostic model”, c’est-à-dire avec une architecture unique permettant d’adresser l’ensemble des cas d’usages du NLP. Pour cela, toutes les problématiques de traitement du langage sont ramenées à de la génération de texte. Par exemple, pour résoudre un problème de classification binaire de commentaires (“positifs” ou “négatifs”), on va soumettre les commentaires au modèle. Ce dernier génère ensuite la réponse en langue naturelle, dans notre cas, “positif” ou “négatif”. Ce paradigme est intéressant car il peut être adapté pour tous types de catégories et plus largement de tâches. On ne met pas à jour les poids du modèle, on parle de zero-shot learning.
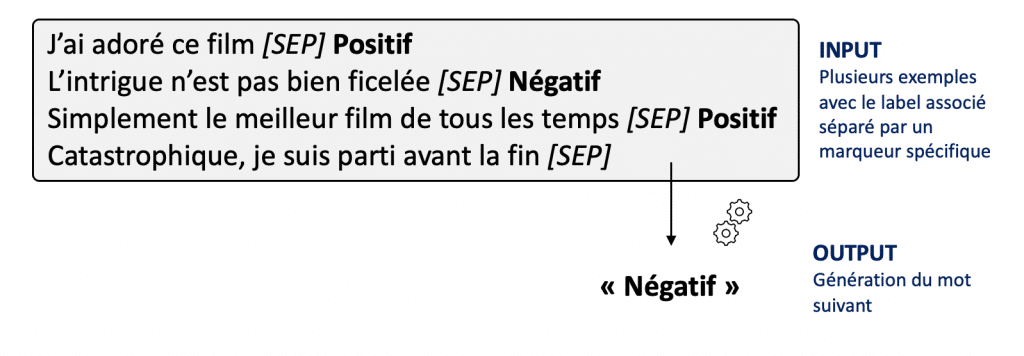
Figure 2 : Fonctionnement de GPT-3 pour résoudre des cas d’usages
Malgré le nombre de paramètres, l’architecture du modèle est remarquablement simple. Dans le sillon creusé par les modèles d’attention, GPT se décompose en une succession de couches de décodeurs. L’architecture présente des similarités avec celle de Bert qui se compose d’encodeurs. La méthode d’entraînement est également relativement semblable puisque pendant la phase de pré-entraînement, le modèle cherche à prédire le mot suivant en fonction des précédents.
Nous avons pu tester le modèle en tant que bêta-testeurs. L’interface de test est extrêmement simple et intuitive. Si les performances brutes du modèle peuvent être discutées en fonction de chaque tâche, nous avons été impressionné par les capacités générales du modèle. Nous vous proposons quelques exemples que nous avons étudiés.
Un exemple de traduction :
Input: Quantmetry est un cabinet de conseil pionnier en IA qui opère de bout en bout sur les problématiques de ses clients, de la stratégie à l’industrialisation. Cette volonté d’être présent de l’identification du besoin à sa résolution en passant par la conception originale de la solution et toujours à l’état de l’art, nous l’appelons la Quant Approach.
GPT-3: Quantmetry is a pioneer in artificial intelligence consulting operating end-to-end on its clients’ problems, from strategy to industrialization. This will to be present from the identification of the need to its resolution through the original conception of the solution and always at state of the art, we call it the Quant Approach.
Un petit exemple de reformulation :
Input: Quantmetry is a pioneer in artificial intelligence consulting operating end-to-end on its clients’ problems, from strategy to industrialization. This will to be present from the identification of the need to its resolution through the original conception of the solution and always at state of the art, we call it the Quant Approach.
GPT-3: Quantmetry is a company that helps other companies do their jobs better. They help companies figure out what to do, and then they help them do it.
L’analyse critique de QM
Le traitement automatique du langage, en pleine révolution depuis quelques années, est arrivé à un nouveau stade de maturité illustré par la transformation de sa chaîne de valeur. Celle-ci ouvre de nouvelles voies inexplorées jusqu’alors pour de nombreux cas d’usage et ouvre le champ des possibles pour de nombreuses entreprises. Cependant ces changements soulèvent dorénavant de nouvelles questions, qu’il faudra prendre en considération dans le futur.
L’application pratique de GPT-3
GPT-3 épate par ses performances, sa facilité d’usage, et sa capacité de généralisation avec très peu de données. Sur le papier, il ne fait aucun doute qu’il est un outil très efficace pour des développements rapides de tâches complexes. En effet les barrières techniques et de ressources en données, obstacles récurrents sur des projets d’intelligence artificielle, sont amoindries.
En revanche de nouvelles contraintes doivent être mises en avant, en alignement avec les directives européennes qui régissent l’IA de confiance. En effet, la Commission Européenne exige qu’une IA soit transparente, intelligible et respecte la diversité, la non-discrimination et l’équité. Or, l’amélioration des performances et l’accessibilité des modèles ont mené à un déficit évident en contrôle et intelligibilité. On ne maîtrise pas la complexité du modèle et on ne sait pas les raisons qui ont poussé à ces architectures. Aussi, quand bien même on souhaiterait ajouter une couche d’interprétabilité, on ne pourrait pas car le modèle est seulement utilisable pour de l’inférence. Enfin, on ne maîtrise pas les données utilisées pour l’entraînement. Par conséquent, on ne mesure pas le risque d’avoir des comportements non désirés comme par exemple des biais sociétaux.
Par ailleurs, GPT-3 est conditionnée à l’utilisation d’une API propriétaire actuellement en version bêta. Cette configuration ne nous semble pas aujourd’hui une solution aisément industrialisable. Aujourd’hui, l’accès à cette API est fastidieux et sera payant à terme. GPT-3 n’est pour l’instant pré-entraîné qu’en anglais limitant ainsi les applications sur des données textuelles en français. Qui plus est, l’utilisation d’API soulève la question de la sécurité et de la propriété des données. En effet, l’utilisation de cette solution implique de fournir des données privées de clients à une entité auxiliaire, suscitant de nombreux problèmes de gouvernance de la données.
Pour l’ensemble de ces raisons nous privilégions à l’heure actuelle des approches basées sur d’autres modèles pré-entraînés à l’état de l’art et disponibles en Open Source, par exemple via la librairie Transformers de HuggingFace : BERT ou GPT-2 par exemple selon les cas d’usages. S’ils nécessitent des données et des compétences pour être adaptés sur chaque tâche, ils offrent néanmoins un meilleur contrôle et permettent de se libérer des contraintes mentionnées précédemment. Notons que des modèles pré-entraînés en français comme FlauBERT et CamemBERT sont disponibles et continuent d’être développés par des acteurs industriels ou académiques !
Les implications de GPT-3
Et le data scientist dans tout ça ? GPT-3 représentant la dernière grande évolution au sein du traitement automatique du langage, nous nous devons de nous interroger sur la place du data scientist dans un monde post-GPT3. En effet, si l’apparition des modèles pré-entraînés relayait au second plan les compétences en Deep Learning ou en Machine Learning du Data Scientist, GPT-3 vient encore abstraire la dimension technique de résolution des cas d’usages. Directement accessible via une API et directement utilisable sans aucune modification sur n’importe quel cas d’usage, l’utilisation de GPT-3 ne nécessite pas les connaissances techniques requises pour exercer le métier de Data Scientist. Il est certain que pour résoudre un cas d’usage en utilisant ce type de modèle, les compétences nécessaires sont différentes. Moins centrées sur la data science, mais plus vers le data engineering et moins vers les connaissances des modèles statistiques mais plus vers les connaissances métiers, du discours technique vers le discours humain. Finalement, nous avons la conviction chez Quantmetry que si GPT-3 présente à première vue une menace pour le Data Scientist, c’est dans sa capacité à accompagner la société dans la révolution de l’Intelligence Artificielle que le Data Scientist apportera toute sa valeur.
Qu’est ce que l’Intelligence Artificielle ? Chaque pas que nous faisons vers des systèmes plus autonomes semble nous faire réaliser la distance vers des systèmes véritablement intelligents. Les algorithmes effectuent aujourd’hui des tâches dont on pensait hier qu’elles étaient l’appanage de l’Homo Sapiens. Conduire des voitures, résumer des textes, écrire des romans, dessiner sont autant d’applications dont on pensait qu’elles nécessitent les facultés cognitives propres à notre espèce. Pourtant les récents progrès en Intelligence Artificielle n’ont pas été synonymes de ruptures de paradigmes mais plutôt d’amélioration des méthodes existantes. GPT-3 en est l’illustration, s’appuyant sur une amélioration constante de la puissance de calcul et des données toujours plus volumineuses, il pousse à leurs extrêmes des méthodes d’apprentissages statistiques. Sans accéder à un processus cognitif, les modèles continuent de mimer les facultés des humains pour des problématiques de plus en plus nombreuses. D’un point de vue pratique, cette tendance ouvre néanmoins de nombreuses portes et continue d’élargir le champ des possibles pour les entreprises.
