

Le BERT NLP de Google AI sur le banc de test !
Nombreuses sont les problématiques auxquelles on peut aujourd’hui répondre en recourant à l’Analyse de Données Textuelles (ADT), au Traitement Automatique du Langage (TAL ou NLP en anglais), à l’extraction de thématiques, d’entités nommées et à l’amélioration d’un modèle de classification grâce à l’intégration des données textuelles.
Mais avec son algorithme BERT, Google va encore plus loin. Il apporte une promesse de résultats supérieurs, pour de nombreux use-cases et sans forcément posséder une grande quantité de données labellisées grâce à une phase de “pre-training” sans label lui permettant d’acquérir une connaissance plus fine de la langue.
Or, pour certaines problématiques, le moindre gain de performance peut être crucial. Il peut par exemple se chiffrer en milliers de mails transférés vers la bonne entité d’une assurance ou en jours de délai de réponse gagnés pour leurs clients ! De même, Google expérimente l’utilisation de l’algorithme pour affiner ses résultats de recherches et estime que cela pourrait impacter et améliorer le résultat d’une requête sur 10 !
Une meilleure compréhension du contexte (plus fine et sur une fenêtre bi-directionnelle très large) et une meilleure prise en compte de l’importance de l’ordre des mots sont les points forts mis en avant par Google dans le cadre d’analyse de requêtes. Nous avons cherché à évaluer le potentiel de BERT dans un contexte d’industrialisation pour des cas d’usages en français.
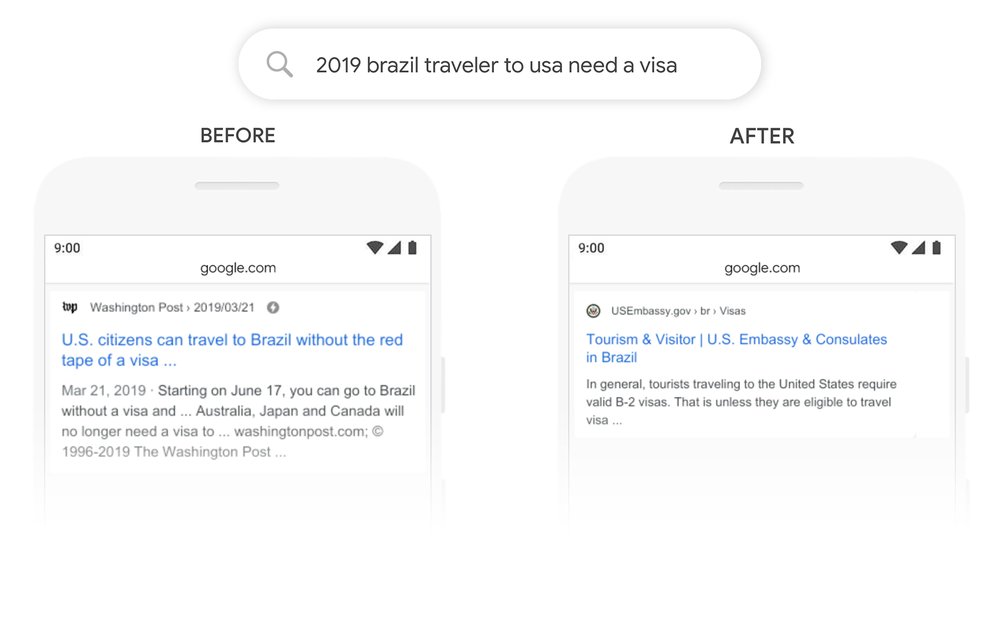
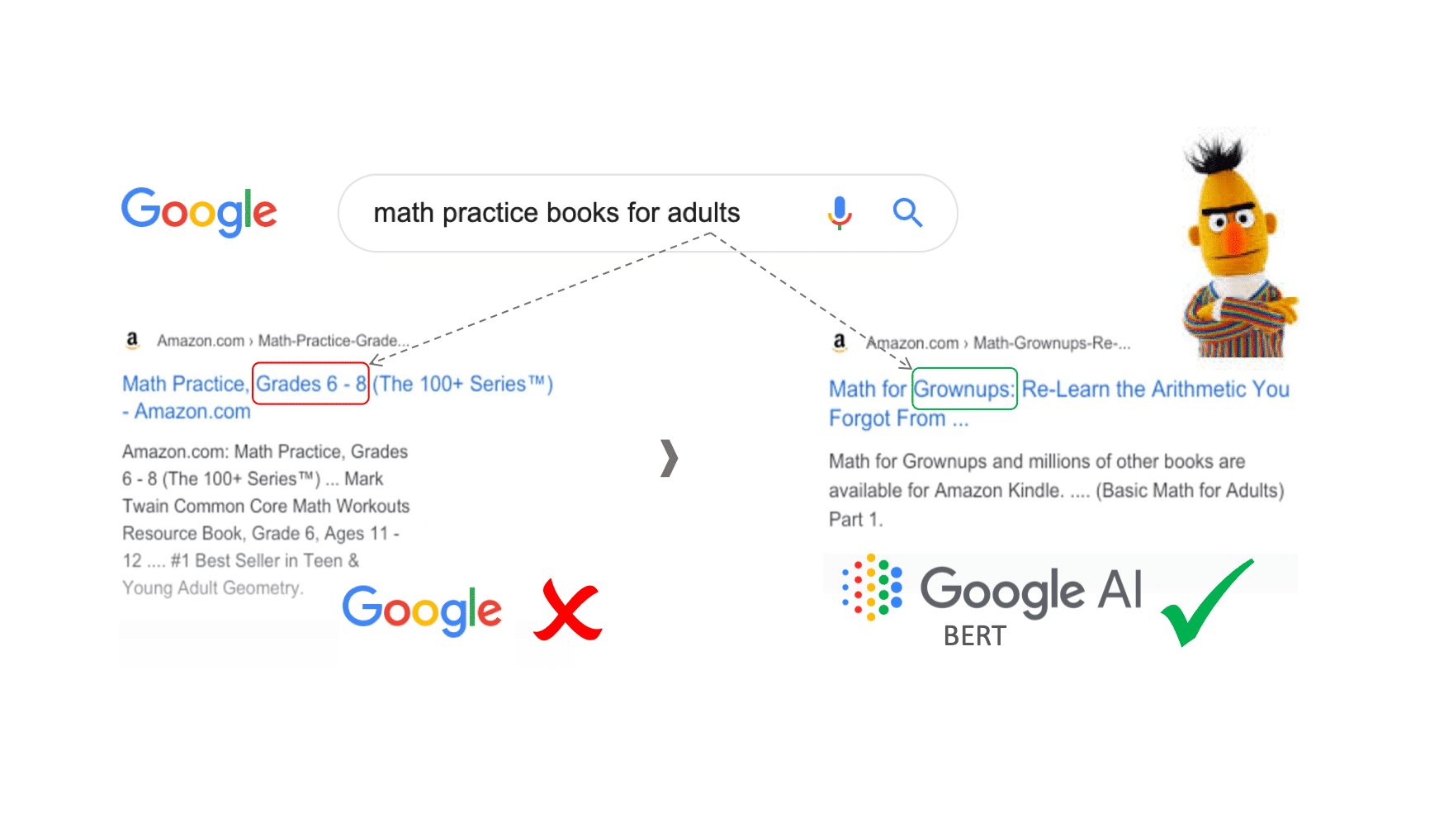
Figure 1. Cette image vous donne un exemple d’amélioration apportée par Bert pour le résultat de requête Google Search : une identification de l’importance du mot “to” dans ce contexte qui désigne la destination. https://www.blog.google/products/search/search-language-understanding-bert/
Présentation de BERT NLP, l’un des algorithmes de Google
L’acronyme BERT correspond à “Bidirectional Encoder Representations from Transformers”. Comme son nom l’indique, il s’agit d’un modèle de représentation du langage qui repose sur un module qu’on appelle “Transformer”. Un transformer étant un composant qui s’appuie sur des méthodes d’attention et qui est construit sur la base d’un encodeur et d’un décodeur comme décrit dans l’image suivante.
Un encodeur se compose de couches d’attentions reliées à l’encodeur précédent (ou l’entrée pour le premier) et de couches denses. Un décodeur, de manière similaire, comprend des couches d’attentions reliées au décodeur précédent et de couches denses ainsi que d’une nouvelle couche d’attentions intercalée entre ces deux couches et reliée à la sortie du dernier encodeur. BERT se compose lui d’une suite d’encodeurs seulement (N = 12 ou 24 suivant la version : Base ou Large). Pour plus d’informations, voici une référence didactique.
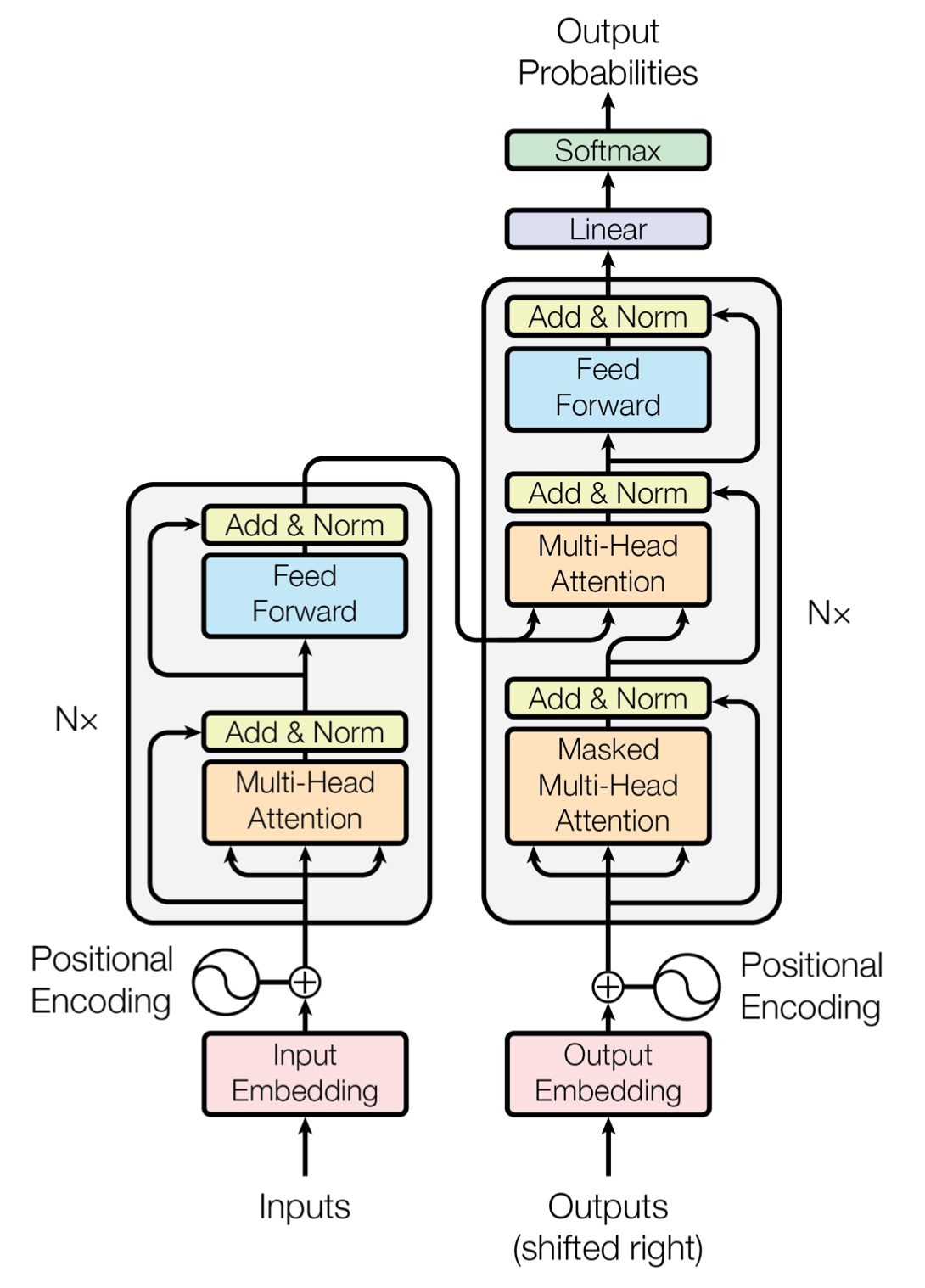
Figure 2. Attention Is All You Need (https://arxiv.org/pdf/1706.03762.pdf)
Le modèle BERT s’inscrit par ailleurs dans le paradigme du transfer learning qui suppose de procéder en deux temps.
Tout d’abord, on effectue un “pre-training” de l’algorithme en apprenant à représenter le texte à l’aide une tâche auto-supervisée. BERT utilise à l’origine pour cela deux tâches de pré-entraînement. Il masque une partie des mots (15%, même si cela s’avère en réalité plus complexe) et apprend à les retrouver. Cela lui permet d’acquérir une connaissance générale et bidirectionnelle du langage. BERT apprend aussi à reconnaître si deux phrases sont consécutives ou non.
Dans un second temps, l’algorithme est spécialisé pour une tâche précise, c’est le fine-tuning. Cette méthode est extrêmement performante comme l’atteste le benchmark GLUE qui cherche à évaluer les capacités des algorithmes à comprendre le langage naturel. Les meilleurs scores sont obtenus à l’aide de méthodes dérivées de BERT comme illustré ci-dessous. Figure 3.
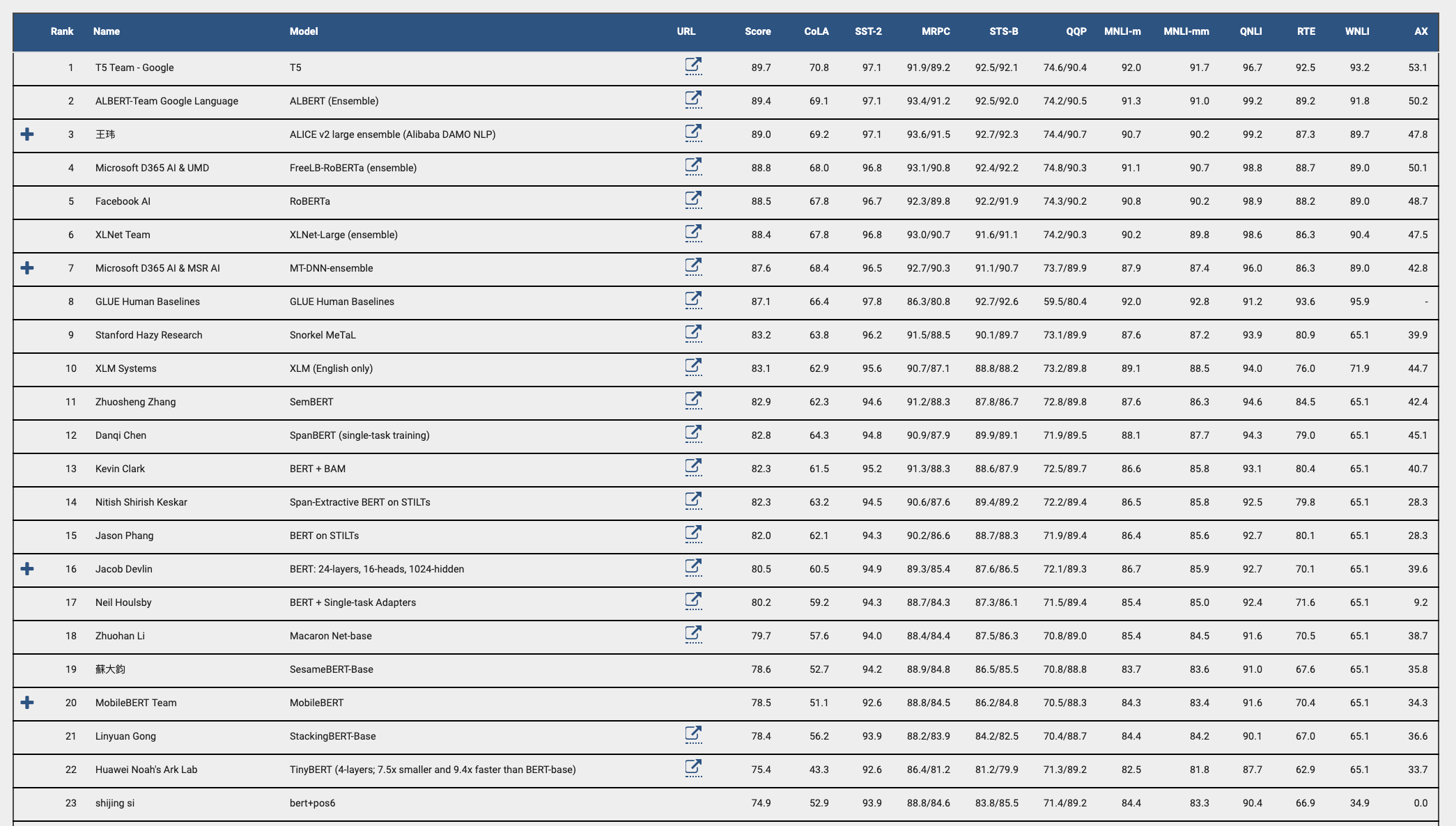
Figure 3. Le référentiel d’évaluation de la compréhension générale du langage (GLUE) est un ensemble de ressources pour la formation, l’évaluation et l’analyse des systèmes de compréhension du langage naturel. (https://gluebenchmark.com/)
Ce tableau représente un référentiel d’évaluation de la compréhension générale du langage (GLUE), qui est un ensemble de ressources pour la formation, l’évaluation et l’analyse des systèmes de compréhension du langage naturel.
Une autre caractéristique de BERT est son incroyable quantité de paramètres. Le modèle que nous avons utilisé (bert base multilingual) en compte 110 millions en étant pourtant une version allégée du modèle que l’on retrouve dans les meilleures scores des classements : BERT Large ! Il est donc complexe de prendre le modèle en main. Il faut notamment une infrastructure importante et adaptée pour la phase de pré-entrainement. Nous nous sommes appuyés sur la librairie Transformers développée par Hugging-Face (voir image en-dessous). Elle propose une implémentation des modèles en Pytorch et Tensorflow mais aussi des modèles pré-entrainés en anglais et multilingue. Ainsi nous n’avons donc effectué que la phase de fine-tuning sur les données de notre cas d’usage.
![]()
Figure 4. La librairie 🤗Transformers fournit des architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet …) pour la compréhension du langage naturel (NLU) et la génération de langues naturelles (NLG) avec plus de 32 modèles préformés dans 100+ langues. (https://github.com/huggingface/transformers)
Un problème de Data Engineering
Si la phase de pré-entrainement est la plus gourmande en ressources, la taille des modèles suppose d’être particulièrement bien équipé lors de la phase de fine-tuning également. Le facteur limitant étant notamment la mémoire vive sur les GPUs. Dans notre cas, nous avons fine-tuné le modèle sur une carte Nvidia P100 avec 16Gb de RAM, par ailleurs nous avons utilisé le modèle Bert Base, moins gourmand en ressources.
Pour nos paramètres, nous étions déjà à la limite pour charger le modèle et procéder à l’entraînement. Au-delà de l’architecture matérielle, nous avons donc outillé les outils sur notre serveur en utilisant notamment des outils implémentant des méthodes mathématiques afin d’optimiser les calculs : NVIDIA Apex et Cuda Toolkit. Ces derniers permettent d’approcher la descente de gradients avec des méthodes nécessitant moins de ressources. Ces outils sont particulièrement intéressants car ils procurent une utilisation quasi transparente une fois outillés sur les outils de haut niveau : Pytorch et Python. Nous nous sommes inspirés de la démarche de Scaleway pour ce type d’optimisations.
Figure 5. Outillage de l’infrastructure data science
Méthode d’apprentissage
L’architecture de BERT permet de résoudre des cas d’usages très différents. Le modèle est donc suffisamment souple pour prendre en entrée plusieurs structures. Il est notamment possible de proposer deux entrées textes distinctes comme illustré dans le schéma suivant. Ce dernier représente une procédure de fine-tuning du modèle BERT (Architecture et format des inputs) et une stratégie de cross validation.
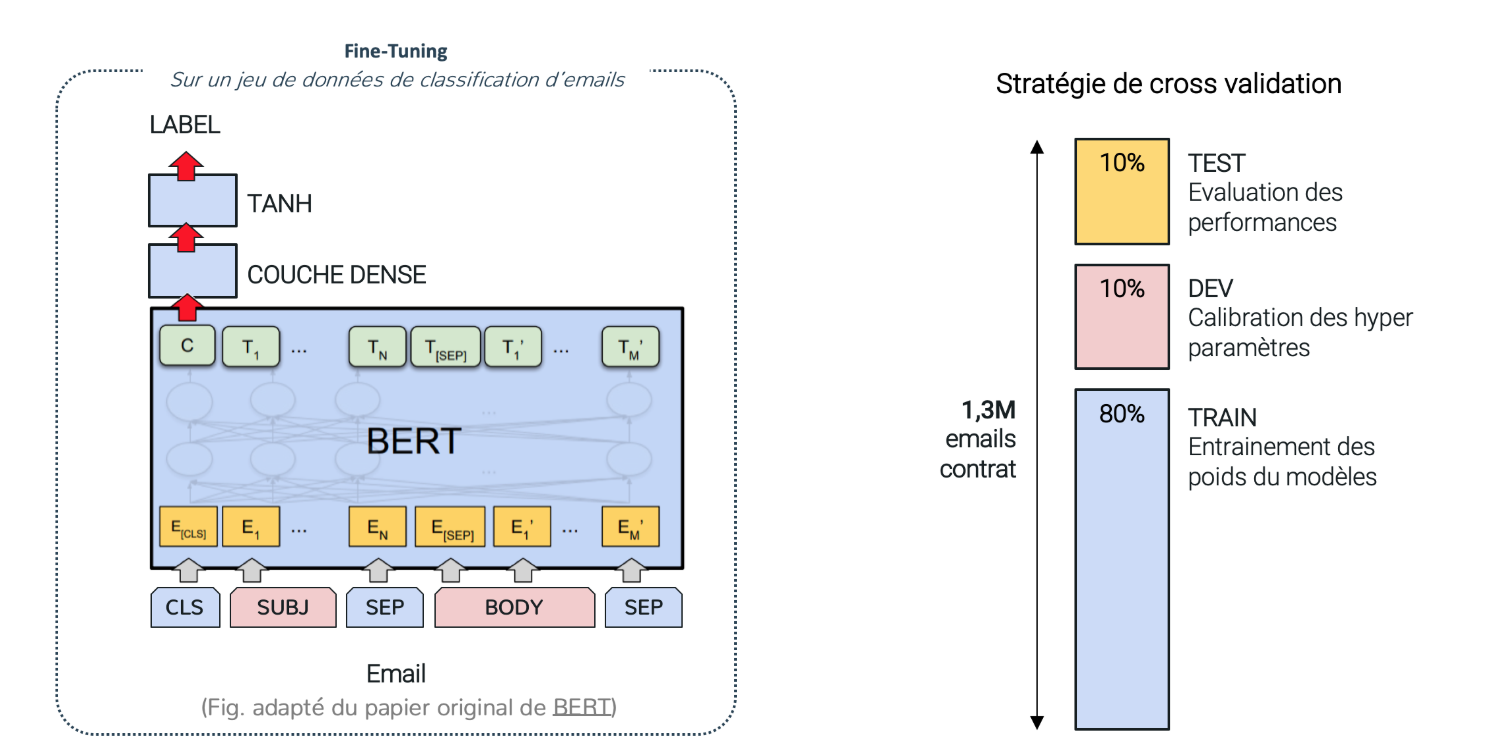
Figure 6. Procédure de fine-tuning du modèle BERT (Architecture et format des inputs) et stratégie de cross validation
De notre côté, nous cherchons à fine-tuner le modèle pour un cas d’usage de classification d’emails. Nous avons donc utilisé en entrée du modèle le sujet (SUBJ) et le corps du mail (BODY) séparés par des tokens spéciaux utilisés lors du pre-training. En pratique, les embeddings sont « contextualisés » dans les couches successives du transformer. Le modèle de BERT a été pré-entrainé sur un corpus multilingue, puis fine-tuné sur le corpus d’emails. Pour la classification, on utilise une couche dense suivie d’une activation tangente hyperbolique. Seul l’embedding du premier token est utilisé. Pour représenter les mails, on utilise la moyenne des embeddings des phrases.
De même, en pratique, le modèle est entraîné de manière assez standard. La procédure de cross validation utilisée est un train/dev/test aléatoire avec une répartition de respectivement 80/10/10 de l’ensemble du dataset. Par ailleurs, le problème est une classification multi-classe, la distribution des labels sur les trois splits cherche à approcher la distribution originale. La fonction de perte utilisée est la Cross Entropy Loss sans pondération en fonction de la fréquence des classes malgré le déséquilibre du jeu de données. En effet, cette dernière ne permettait pas en pratique d’améliorer les performances.
Le modèle est entraîné pendant 10 epochs par batch de 64 mails selon un ordre aléatoire. L’optimisation est effectuée avec l’optimiseur FusedLAMB de Nvidia Apex et un learning rate de 3e-5.
Résultats et métriques
Maintenant, voici quelques métriques intéressantes mesurées lors du fine-tuning. Nous observons qu’il est possible de fine-tuner le modèle de BERT en utilisant simplement un GPU. Sur nos données d’entraînement, une epoch dure en moyenne 4h. Bert n’est donc pas un modèle que l’on poussera en premier lieu dans un projet de par son coût de mise en place, mais plutôt dans un second temps, lorsque le ROI du projet est avéré et l’industrialisation réussie afin d’aller chercher des performances supérieures.
Concernant l’utilisation de BERT dans un contexte de projet industrialisé, nous avons mesuré un temps d’inférence court : 50ms. Cela est très prometteur pour une utilisation en production et nous permettrait de ne pas dégrader les performances actuelles, avec un processus complet de traitement d’email <500 ms. Pour information, Nvidia annonce des temps d’inférence de l’ordre de 5 ms sur le modèle Bert Large à l’aide d’optimisations spécifiques.
En revanche, pour la taille en RAM, c’est une réelle problématique lors du fine-tuning lorsque l’on utilise un unique GPU mais aussi puisque les ressources des machines en production sont généralement très réduites. Même Google doit aujourd’hui revoir son architecture pour Google Search et utiliser des TPUs (Tensor Processing Unit) afin d’avoir les ressources suffisantes pour répondre aux recherches des utilisateurs avec BERT. Finalement, le pré-entrainement du modèle est très lourd en ressources, notamment en électricité et donc en émissions de CO2 selon la centrale de production. Néanmoins, le fine-tuning est une étape moins coûteuse en énergie et émet donc moins de CO2 (environ 12kg pour le fine-tuning du modèle).

Figure 7. Voici une estimation des métriques de fine-tuning à partir des données de : Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and Policy Considerations for Deep Learning in NLP. arXiv preprint arXiv:1906.02243.
Les performances sont intéressantes, mais elles n’égalent pas encore celles obtenues avec un algorithme utilisant des embeddings pré-entrainés sur notre corpus et les méta-données associées à chaque exemple en plus des données textuelles. Cependant, en utilisant seulement une partie des données disponibles et un modèle qui n’est pas pré-entrainé spécifiquement sur le français, les résultats sont très encourageants. Nous envisageons donc les pistes d’améliorations suivantes :
Au niveau de la préparation des données, il faudrait tester différentes manières d’agréger les messages de l’historique de la conversation comme dans le schéma ci-dessous. Figure 8.
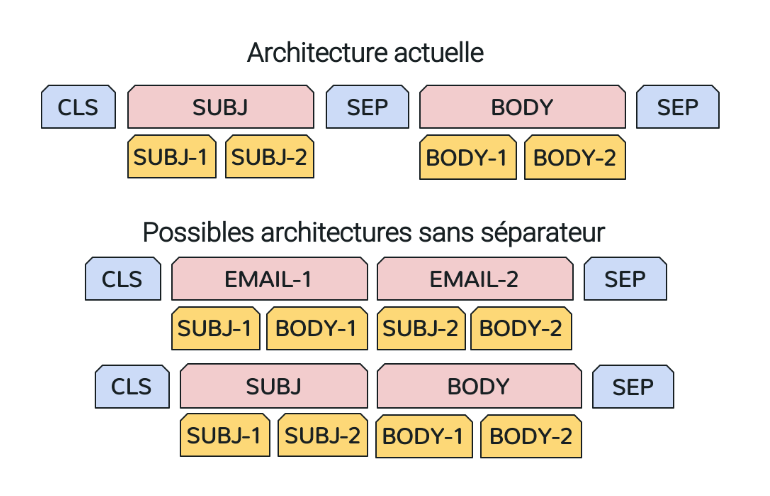
Figure 8. Agrégation des inputs
Ajouter les méta-données après l’encodage du texte comme les types des pièces jointes, l’heure d’envoi …
Utiliser différentes architectures de transformers comme DistillBERT RoBERTa ou bien sûr un modèle pré-entrainé en français. Un modèle vient d’ailleurs tout juste d’être proposé en open-source : CamenBERT. Ce dernier est issu de RoBERTa, une variante de BERT. CamenBERT est pré-entraîné en français !
Utiliser la procédure de cross validation pour ajuster les hyper-paramètres du modèle : taille de batch, longueur de phrase maximum, fonctions d’activation, top-layers après Bert, class_weights pour l’optimiseur …
Notre impression après notre test de BERT
Nous sommes très satisfaits de la possibilité de prendre en main des modèles complexes tels que BERT grâce aux implémentations open-source et des librairies bas niveau pour le calcul sur les cartes graphiques. BERT propose des performances en inférence qui sont très intéressantes, notamment au niveau du temps d’exécution. Néanmoins certaines métriques restent encore à estimer, comme le temps d’inférence sur CPU ou la taille du modèle en RAM pour évaluer la possibilité de le déployer sur un serveur de production aux ressources souvent réduites.
Si les promesses de BERT sur des jeux de données académiques sont largement au-dessus d’autres méthodes, pour notre cas d’usage, les gains restent encore à évaluer. Nous sommes dépendants du besoin d’un modèle performant en français et il est difficile de savoir si le phénomène de transfer learning sera aussi efficace sur nos données que dans le cas du benchmark GLUE par exemple.