

Capsule Network
1- History :
« Dynamic Routing Between Capsules »[1] was published in 2017 by Geoffrey Hinton and his team, and introduced a new architecture of neural networks based on the concept of capsule. Capsule networks have given excellent initial results for number recognition and classification of small images. The success of this architecture is based on the idea that spatial information (part-whole relationships in the data) need to be preserved throughout the network. This retention of information is done by reconstructing the input from the output capsule vectors and replacing max-pooling layers with convolutional strides and dynamic routing.
2- What are the limits of Convolutional Neural Networks (CNN)?
CNNs were built upon the principles of weight sharing and translation invariance; the latter is achieved by using convolutional filters/kernels. This network architecture show great performances for image classification when the new data is very close to the training data: convolutional networks are less performant at detecting and classifying images if the images have been rotated, reversed or tilted: in these cases, performance drops drastically.
The issue of invariance for neural net is addressed with pooling layers.
However, pooling layers cause location information in the higher layers; it means that the network keeps the information of parts of the target object, but it is agnostic of their spatial layout. This loss of precise spatial relationship between higher-level parts leads to triggering false positive for images which have the components of the object but not in the right order. This is why convolutional neural nets are sensitive to adversarial attacks.
The representation of data through Convolutional Neural Networks does not integrate spatial relationship and orientation between different parts of the object.
How do we build algorithms that are more able to preserve spatial relationship of object in the image and that easily generalize to unseen data?
Hinton’s work on capsule networks gives us the following clue: instead of invariance, we should be looking for equivariance.
Invariance ensures that the CNN is less sensitive to small changes in perspective. Performances are acceptable for image classification but make it challenging to perform object detection which require precise location. The fact that capsules are equivariant makes it very promising for this application.
How do we achieve Equivariance with CapsNet?
In the CapsNet architecture, each object is represented by a vector and scalar values of this vector represent different instantiation parameters of the object (e.g texture, lighting, etc.) and use the vector length/norm as indicator of object presence.
It means that the vector components are equivariant and its length representing a probability is invariant.
3 – WHAT’S NEW with CapsNet ?
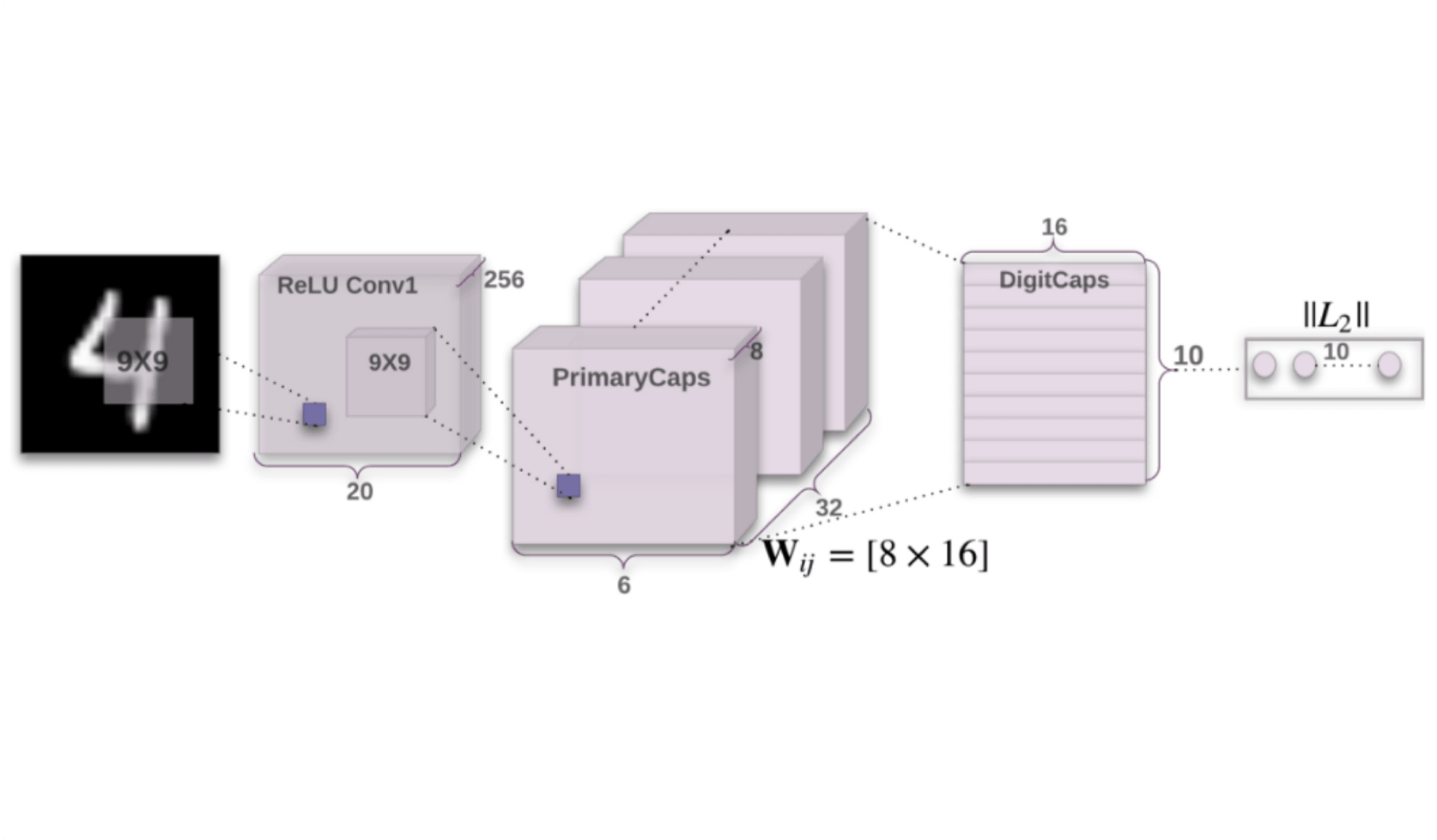
CapsNet Architecture
The architecture encapsulates neural layers: in a traditional neural network, the layers are added depending on the final configuration; in capsule networks, layers are added inside a nest of layers.
The output of one capsule is represented by a vector giving the information of the existence of one specific entity inside the image. The properties of this vector (like orientation) give information about the entity. The second level of capsule integrates a composition of the previous layer and represents an object composed of parts represented by lower level capsules. The relationship between capsule levels is done by a routing mechanism. This algorithm is described below.
Routing
In this routing algorithm, output vectors from lower level capsules are sent to the next layer of capsules agreeing with its input. This output represents a prediction vector and is calculated based on multiplying its own weight and a weight matrix.
Then, the scalar product is calculated with each possible capsule of the upper level and the largest scalar prediction vector product, increases the capsule bond and is integrated in a feedback loop. This loop will integrate the effect of coupling : the routing process will increase the coupling for spatial related upper capsule while it will decrease it for the capsule not related.
Squashing
As the length of the output of a capsule represents a probability, the squashing function is used to normalize the size of the vector.
Instead of having a non-linearity function to each layer like how you do in CNN, you add the squashing function to a nested set of layers. This function is applied to the vector output of each capsule.
4- CapsNets applications, advantages and limits
CapsNets are a promising alternative to CNN and introduce a new building block to improve hierarchical relationships for deep learning algorithms. What are their current applications and their theoretical limits that have not yet been solved?
Experimental results show that CapsNets are significantly better than CNNs on small datasets.
The dynamic routing operations are computationally expensive, making them significantly slower than other modern deep networks.
Robustness tests have shown that this new architecture still fails Adversarial Attacks as its has be demonstrated by SAP lab] https://github.com/jaesik817/adv_attack_capsnet
“CapsNet also fall in the trap of every type adversarial examples. This structure can be one of the hint to solve adversarial problem, however experiment results show capsnet is not free to adversarial attack.” One of the next challenges would be to define structure improvement to ensure more resistance against attacks.
✍Article écrit par Adèle Guillet
[1] S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic routing between capsules,” in Advances in Neural Information Processing Systems, 2017