

Consortium scikit-learn - Nouvelles fonctionnalités & intelligibilité

Le 28 mai dernier se tenait le consortium scikit-learn, à Rueil-Malmaison
Etant un utilisateur de longue date de cette bibliothèque bien connue des amoureux de l’apprentissage automatique, Quantmetry était présent lors de ce consortium, principalement dans une optique de veille technologique.
Nous avons décidé de vous faire un petit tour d’horizon des nouveautés et des idées futures. Allez, venez, c’est par ici …
New Features – Roman Yurchak
Après une introduction de Gaël Varoquaux en personne, nous enchaînons sur une présentation des nouvelles fonctionnalités introduites pour la plupart dans les versions 0.20 et 0.21 de scikit-learn. Au moment de la prise de parole de Roman Yurchak, la tension est palpable.
Pré-traitement / pipelining
La première évolution présentée (V0.20) est l’ajout d’un ColumnTransformer.
Ce transformer est en fait un ajout de longue date de certains utilisateurs, qui préféraient prendre des DataFrames pandas en entrée plutôt que des structures numpy, et suivre les transformations par colonne sur ces DataFrames.
Le ColumnTransformer permet donc simplement d’affecter au niveau des colonnes une séquence de transformations à effectuer, et ainsi de construire un pipeline en conséquence. À noter que Quantmetry a récemment mis en ligne un package permettant de faire la même chose sur PySpark, ici.
Chargement de données natif depuis OpenML
Ce petit ajout, non sans conséquence, consiste à faciliter le chargement de sets de données directement depuis OpenML, une plateforme de Machine Learning collaboratif qui met à disposition des jeux de données.
EarlyStopping
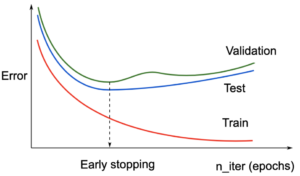
L’EarlyStopping, que nous pourrions traduire par Arrêt Anticipé, est une logique assez simple en apprentissage automatique, qui consiste à arrêter l’entraînement du modèle de manière prématurée, lorsqu’aucune amélioration dans sa capacité de généralisation (training error vs test/validation error) n’est observée, et qui peut être très utile pour :
- Réduire le temps d’entraînement du modèle
- Diminuer le risque de sur-apprentissage – overfitting
La version 0.20 de scikit-learn introduit donc la gestion de l’Arrêt Anticipé via un simple paramètre booléen optionnel, lors de l’instanciation du modèle

Power Transformer – “make data more gaussian-like”
Une autre classe dédiée à la transformation a été introduite dans la version 0.20 : le PowerTransformer. Le but de ce Transformer est de réduire l’asymétrie (skewness) sur un jeu de données, et ainsi d’approcher une distribution normale, la normalité étant un a priori à l’application de bon nombre d’algorithmes. Deux méthodes sont disponibles pour réaliser la transformation : la transformée de Yeo-Johnson et la méthode Box-Cox.
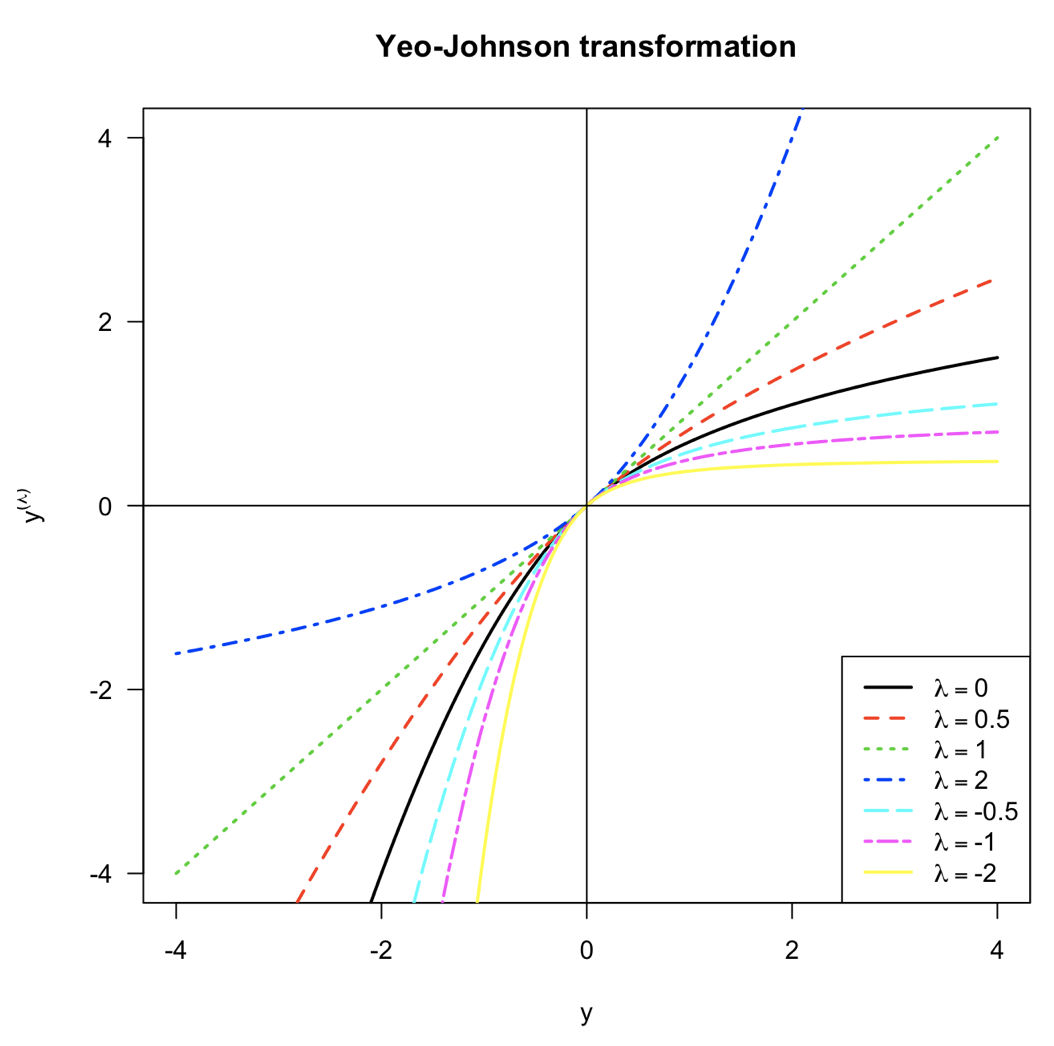
Dans scikit-learn le λ est déterminé automatiquement, pour chacune des colonnes
Gradient Boosting : où en sommes-nous ?
Une nouvelle implémentation du gradient boosting, nommée Histogram Based Gradient Boosting, a aussi vu le jour dans les dernières versions. Cette implémentation consiste principalement à agréger les données d’entrée, dans le but d’en faire des paquets de nombres entiers, en amont de l’entraînement.
Elle présente donc une étape supplémentaire de pré-traitement (integer-values bins), qui permet au gradient boosting entraîné a posteriori de bénéficier de structures de données internes spécifiques aux nombres entiers, et donc de s’entraîner plus rapidement.
Nous notons aussi que cette version :
- est plus rapide à entraîner que l’algorithme historique de gradient boosting de scikit-learn, et plus adaptée à de fortes volumétries de données ;
- est annoncée plus rapide que XGBoost, et un peu moins que lightGBM ;
- voit le jour dans un nouveau namespace nommé sklearn.experimental, qui, comme son nom l’indique, donne accès à des méthodes en cours de définition, qui fournissent par conséquent des garanties limitées en matière de robustesse.

Notre avis
Des efforts considérables ont été faits par les équipes de l’INRIA. Néanmoins, les implémentations actuelles des algorithmes de gradient boosting de scikit-learn souffrent toujours d’un manque de pragmatisme, et donc de support face à des problématiques de la vie réelle que nous rencontrons fréquemment en mission chez Quantmetry, parmi lesquelles :
- la gestion de valeurs manquantes qui n’est pas gérée nativement par l’algorithme de sklearn, mais qui est gérée par lightGBM ;
- la gestion des variables contiguës (données catégorielles) qui, elle, est gérée par xgboost,lightGBM, et bien évidemment CatBoost.
Nous gardons donc un œil sur les évolutions des méthodes de boosting sur scikit-learn. L’approche par histogramme est élégante et puissante, et pourra sûrement se révéler bénéfique à la communauté. Dans un futur proche, nous continuerons à utiliser des algorithmes plus robustes et plus performants, comme XGBoost, lightGBM et CatBoost (Yandex).
Imputation de valeurs manquantes
La plupart des estimateurs présents dans l’écosystème python ne peuvent pas être entraînés sur des jeux de données contenant des valeurs manquantes (le Gradient Boosting Classifier est un exemple typique). L’approche naïve consiste à remplacer les valeurs manquantes d’une variable par la moyenne/médiane pour des variables numériques, ou par le mode pour les variables catégorielles. Néanmoins, dans de nombreux cas d’usages, ce type de pré-traitement, accessible via le SimpleImputer, limitera les performances du modèle entraîné en amont. De cette limite est née une nouvelle classe, tout aussi simple d’utilisation, qui vise ces cas d’usages spécifiquement : IterativeImputer. Cette méthode d’imputation, inspirée de la bibliothèque R MICE, réalise l’imputation en exprimant tour à tour chaque variable comme fonction de la précédente, via un estimateur.
Étape par étape, nous avons donc :
- Une imputation initiale très simple est effectuée : la moyenne est utilisée par défaut. Nous gardons en mémoire les emplacements des valeurs manquantes.
- Tour à tour — par défaut par ordre décroissant du nombre de valeurs manquantes : Chacune des variables contenant des valeurs manquantes est exprimée comme fonction des autres variables, via une régression par exemple ; Les valeurs manquantes sont remplacées via la fonction estimée en a).
- L’étape 2. constituant ce qui s’appelle un cycle, nous répétons un nombre de cycles (paramètre max_iter dans scikit-learn).
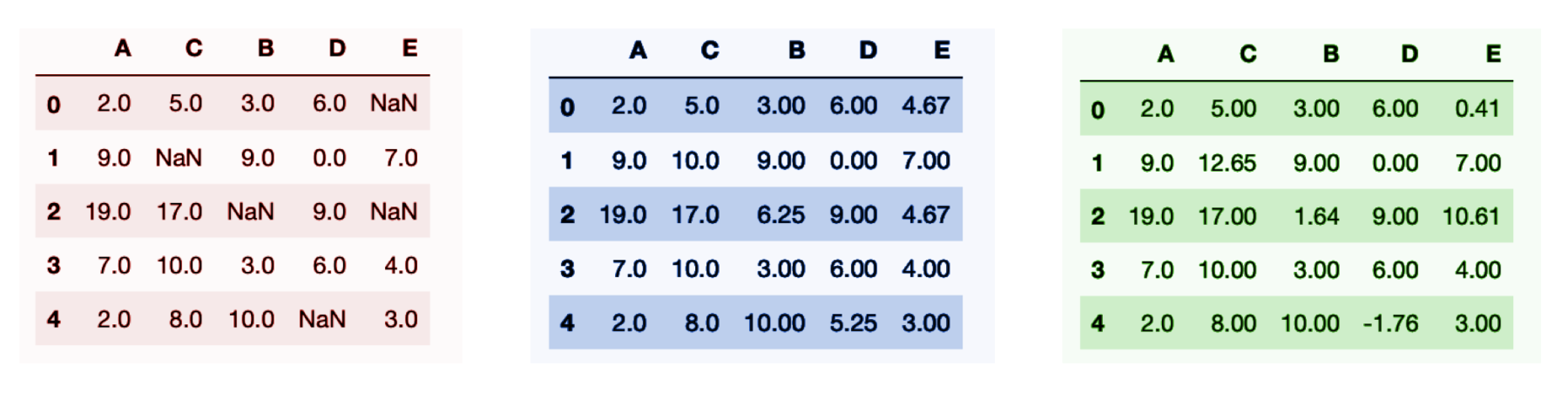
Le jeu de données d’origine, puis l’imputation initiale (moyenne), et le jeu de données final après imputation via MICE
Enfin, nous notons que MICE doit pour l’instant être importé en passant par le namespacesklearn.experimental, tout comme les méthodes de GradientBoosting vues précédemment.
Intelligibilité par Guillaume Lemaître
C’est Guillaume Lemaître qui prend ensuite la parole pour nous présenter les derniers travaux concernant l’intelligibilité.
NB : Dans ce chapitre l’intelligibilité est traitée au sens global (explication des variables à l’échelle du modèle), par opposition aux explications locales, qui, quant à elles, tentent d’expliquer les contributions au moment de la prédiction, et pour une entrée donnée.
Importance des variables
Une approche classique pour évaluer l’impact des variables d’entrée sur l’estimation de la variable de sortie est d’étudier l’importance des variables (Feature Importance).
Dans le cas des modèles se basant sur des arbres (forêts aléatoires, maximisation du gradient …etc.), ce type d’indicateur donne une mesure de l’impact global des variables, découvert lors de l’entraînement, et qui traduit le poids de chaque nœud (split) dans le modèle.
Néanmoins, quelques situations bien connues nous amènent à apporter une critique sur cet indicateur. Le cas dans lequel plusieurs variables sont corrélées entre elles est un exemple typique. Dans ce cas précis, les variables en question se « partagent » l’importance d’un point de vue global, et leurs importances respectives sont diminuées.
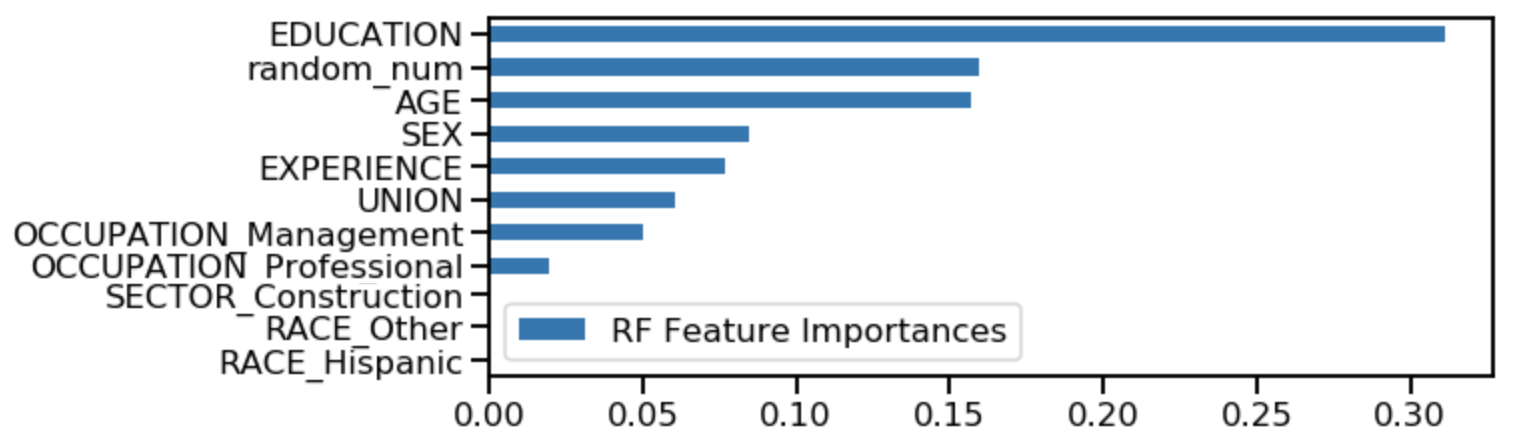
Ici l’expérience et l’âge sont fortement corrélées, ce qui donne des Features Importances plutôt élevées, mais en dessous de la “réalité ».
Ici, l’expérience et l’âge sont fortement corrélées, donnant ainsi des Features Importances plutôt élevées, mais en-dessous de la « réalité ».
Le cas extrême serait d’avoir un grand nombre de variables, qui seraient toutes corrélées entre elles, et se partageraient l’importance de manière plutôt équitable. Une analyse naïve amènerait certainement à supprimer toutes ces variables (qui ont respectivement une importance faible), ce qui entraînerait très certainement une forte chute dans les performances du modèle. Une analyse des corrélations semble donc nécessaire …
L’importance des permutations — permutation importance
Plus récemment, la permutation importance a fait parlé d’elle. Ce type d’approche, historiquement accessible via le package eli5, et bientôt directement dans scikit-learn, agnostique du modèle utilisé et donc plus générique que l’importance des variables, consiste à mélanger aléatoirement les valeurs d’une variable avant d’évaluer la baisse de performance liée à cette permutation. Plus robuste et plus générale que la Feature Importance, cette dernière approche ne résout pas complètement les problèmes de corrélations évoqués précédemment, en plus de présenter des différences sur les importances entre le jeux d’entraînements et le jeux de test …

Proposition : à choisir entre deux variables corrélées, pourquoi ne pas calculer le delta de permutation importance entre le test set et le train set, et choisir la variable qui présente le delta le plus faible (la permutation importance la plus stable) ?
Notre avis
Il n’y a pas de méthode magique pour expliquer les contributions des variables d’entrée suite à la construction d’un modèle prédictif. Les travaux menés chez Quantmetry par Jean-Matthieu Schertzer, ainsi que les récentes missions réalisées, nous montrent que les méthodes qui existent ne sont que des outils, de plus en plus nécessaires, mais insuffisants à l’explication profonde et complète des contributions.
En effet, l’évaluation automatisée des contributions, rendue possible par de nouvelles méthodes (Permutation Importance étant une de ces méthodes) ne signifie pas que le travail d’intelligibilité s’arrête là. Une analyse plus fine, en partenariat avec les métiers et toujours au regard de leurs cas d’usages, reste nécessaire à la construction d’explications tangibles.
En pratique, grâce à l’analyse des corrélations et des causalités, nous en apprenons davantage sur le problème à modéliser. Ces analyses nous permettent, entre autres :
- de réduire la dimension du problème en ne gardant que les variables nécessaires, ce qui nous permet :
- d’être plus fidèle au réel impact des variables conservées dans la modélisation ;
- probablement d’augmenter la robustesse du modèle : moins de sources, donc moins de risques de voir les performances affectées en production ;
- de découvrir des variables confondantes, et pourquoi pas de réitérer avec les métiers pour en savoir plus.
Scikit-learn, qui propose depuis peu de nouveaux outils visant à rendre les modèles plus intelligibles, suit donc une mouvance générale de la communauté, qui pose de plus en plus la question de l’intelligibilité comme condition à l’adoption des modèles prédictifs dans un nombre grandissant d’industries, comme la santé (détection de tumeur) ou encore la banque (score d’octroi).
✍ Article écrit par Remi Adon
Relecture Guillaume Hochard, Alexandre Henry, Nicolas Pletre, Antoine de Daran.