

Datalab, Datafab… Comment repousser ses limites ?

“Suis-je en retard en matière de maturité IA ?”. Cette question récurrente est posée pour toute innovation marquante : elle l’a été en son temps pour le digital, où les acteurs économiques, persuadés, à juste titre, d’être en présence d’un levier majeur d’amélioration de performance se sont inquiétés de savoir si leur timing d’adoption était le bon. En effet, un retard les aurait depositionnés sur l’expérience client, le chiffre d’affaires, les processus internes voire la création de relais de croissance. Nous assistons aujourd’hui au même phénomène pour la transformation data driven.
C’est pourquoi, Quantmetry a mis en place un baromètre de maturité des organisations data qui a pour but de quantifier cette maturité en observant une vision “démoyennée” à plusieurs dimensions. Les résultats de ce baromètre nous ont permis de constater certaines limites que nous détaillons dans un premier article, et nous permettent aujourd’hui d’analyser quels pourraient être les leviers permettant de les repousser.
Une maturité analysée suivant 7 axes
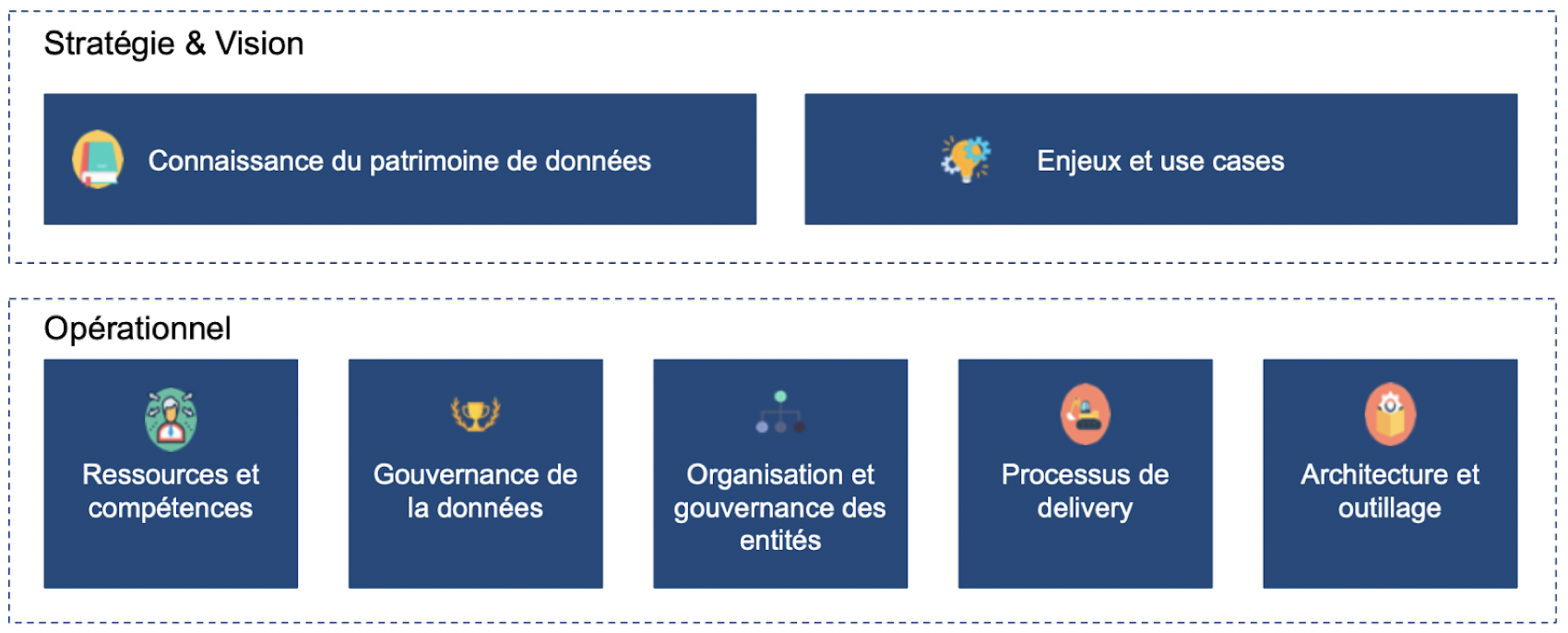
Suivant une grille de lecture exploitée depuis quelques temps par nos équipes, nous avons choisi 7 axes d’analyse répartis sur 2 niveaux : sur la stratégie et la vision d’une part (le quoi), et sur le modèle opérationnel d’autre part (le comment). Nous avons ensuite utilisé un système de notation (de 1 à 4, détaillé ci-dessous) pour chacun des axes afin de factualiser notre évaluation.
Stratégie et vision
L’identification des cas d’usage et leur positionnement sur une roadmap permet de juger de la capacité de l’entreprise de se saisir de cette innovation pour servir leur enjeux business. Une note de 1 dénote des cas d’usage peu en phase avec les enjeux alors qu’une note de 4 démontre l’existence d’une roadmap solide et partagée.
Cela ne peut se faire sans la connaissance du patrimoine data se traduisant généralement par une cartographie des données partagée par toutes les parties prenantes et l’existence de référentiels associés. Une note de 1 traduit une faible conscience du patrimoine data alors qu’une note de 4 exprime que le patrimoine est déjà connu et bien formalisé.
Modèle opérationnel
La première brique du modèle opérationnel data repose sur les compétences. Une note de 1 révèle que l’entreprise ne dispose pas de ressources spécialisées et dédiées, alors qu’une note de 4 matérialise l’existence de ressources expérimentées, disponibles, diversifiées (avec des profils aussi bien techniques que fonctionnels) et bien réparties dans l’organisation, le tout associé à une vraie stratégie de recrutement de gestion des compétences.
Ensuite vient la gouvernance des données. Si connaître son patrimoine est une première étape nécessaire, elle reste une vision statique. La gouvernance des données a pour objectif de standardiser les pratiques et méthodes garantissant une gestion des données dynamique. Une note de 1 signifie que les données sont silotées, peu accessibles et sans contrôle de la qualité tandis qu’une note de 4 témoigne qu’une organisation spécifique est mise en place, que les standards sont largement partagés, et que les données sont exploitables par tous dans une démarche d’amélioration de la qualité
Une organisation spécifique ne doit pas se limiter à la gouvernance des données, mais doit bien être le liant entre stratégie, projets, ressources, méthodes et outils. Elle peut prendre plusieurs formes, et doit s’adapter au contexte de l’entreprise (cf. notre article sur les limites que l’on a pu constater chez nos clients). Une note de 1 affiche des sujets data portés de manière désordonnée et sans cohérence globale alors qu’une note de 4 démontre que l’organisation est data driven, pilotant à la fois la stratégie, la gouvernance, et l’acculturation tout en étant tirée par l’industrialisation des cas d’usage.
L’entité data est également en charge de définir le processus de delivery qui assurera une méthodologie commune entre tous les acteurs permettant de piloter la roadmap de manière cohérente. Une note de 1 révèle que la réalisation des cas d’usage est à un stade expérimental, sans optique d’industrialisation, sans pilotage des gains et avec une logique “artisanale”, tandis qu’une note de 4 prouve que les processus intègrent une logique de déploiement en continu, impliquant dès le début toutes les parties prenantes ainsi qu’un pilotage strict des bénéfices.
Enfin, tout cela doit s’appuyer sur une architecture et une plateforme adéquate, avec les bons outils facilitant le partage de données et les expérimentations tout en garantissant le passage à l’industrialisation. Une note de 1 traduit des données silotées dans des bases de données hétérogènes, sans plateforme centrale alors qu’une note de 4 signifie que des outils de data management sont systématiquement utilisés, qu’un schéma général d’architecture data existe, et que les technologies sont déployées et maintenues.
Ce découpage reflète notre vision de la maturité de nos clients et des facteurs qui nous semblent primordiaux pour réussir cette transformation aujourd’hui. Ils seront amenés à évoluer au fur et à mesure que la maturité de nos clients augmentera et que leurs priorités changeront. Ainsi par exemple, la notion de cycle de vie des modèles sera probablement une dimension supplémentaire lors de notre prochaine édition.
Une maturité constatée faible avec de fortes disparités
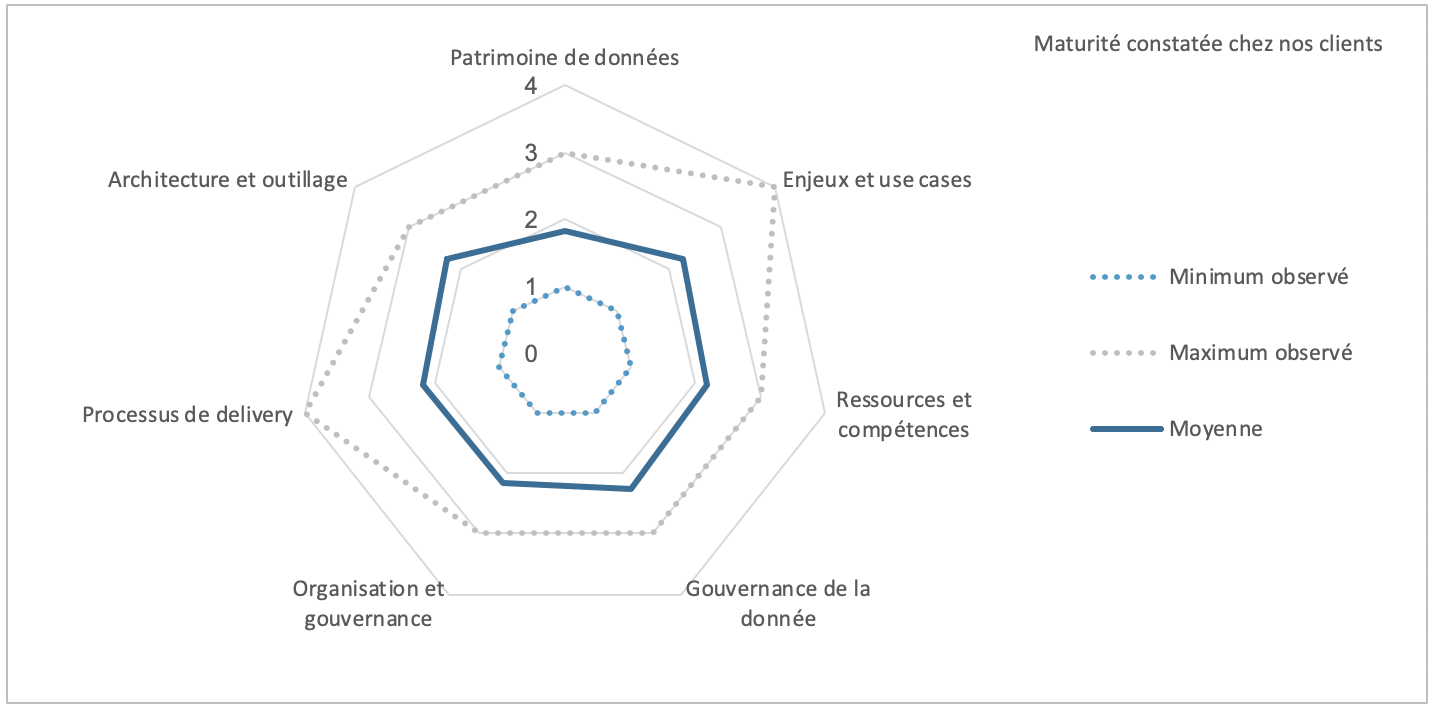
Notre baromètre fait apparaître des disparités de maturité entre les entreprises mais également quelques grandes tendances. Le premier constat est qu’en moyenne, les organisations data ont posé les premières briques nécessaires à l’amorçage de la transformation data driven mais qu’une bonne partie d’entres elles sont encore au milieu du gué : elles doivent développer ou structurer l’ensemble de ces axes afin de passer au stade suivant, celui de l’industrialisation impliquant des projets marquants pour la transformation business globale de l’entreprise.
Cela est plutôt logique, les organisations data restent relativement jeunes et il est normal qu’elles n’aient pas encore mis en place l’ensemble des éléments nécessaires à l’accélération de leur activité dans un contexte post-POC. D’ailleurs seulement 1/3 des clients observés a, au moins, un projet déjà industrialisé ! En effet, si la grande majorité a déjà lancé ses premières expérimentations depuis 1 à 3 ans, pour une bonne partie d’entre eux, 2019 devrait véritablement être l’année de l’industrialisation et du déploiement à plus grande échelle.
Pour les organisations qui se sont lancées plus récemment dans des projets data, il est logique de trouver un “radar” déséquilibré car elles n’ont pas pu encore investir dans chacun des axes observés. Nous devrions retrouver un développement des 2 critères “vision” (enjeux et cas d’usage et connaissance du patrimoine de donnée) plus important car c’est la première étape indispensable. Pourtant, ce n’est pas toujours ce que nous constatons et cela pourrait rapidement devenir limitant pour accélérer.
Nous sommes donc dans le momentum où beaucoup d’organisations data sont confrontées à une première “crise de croissance” et se posent la question des éléments à mettre en place pour dépasser leurs limites et rattraper l’éventuel retard accumulé.
Casser le plafond de verre d’une organisation centrée sur le POC
La suite de cet article a pour vocation d’expliquer comment combler le retard quand il existe et de mettre en avant les facteurs clés de succès pour accélérer sa transformation data driven.
Construire une vision data partagée
De nombreux datalab / datafab sélectionnent les cas d’usage selon une logique plus opportuniste que réfléchie. Seule une minorité d’entre eux positionne sur une feuille de route les cas d’usage sélectionnés selon des critères partagés avec l’ensemble des parties prenantes. Les entités data naviguent le plus souvent à vue, à la recherche du prochain projet à valeur sans avoir un cap clairement défini. En effet elles restent souvent happées par le delivery des projets et n’arrivent pas à prendre assez de temps pour construire une vision globale.
Cela est bien souvent un frein pour aller chercher les projets les plus ambitieux, ceux qui donneront un coup d’accélérateur à la transformation data de l’entreprise. En effet, définir et partager cette vision, sur ce que sont l’IA et la data, sur la façon dont ils peuvent contribuer à transformer les processus métier et les modèles économiques, est essentiel pour optimiser sa transformation data driven. La consolidation et le partage de cette vision commune au sein de l’entreprise est même un prérequis dès lors que l’entreprise veut aller plus loin que la phase d’expérimentation.
La première étape pour construire cette vision partagée est d’identifier son patrimoine de données afin d’identifier son potentiel de transformation. Notre étude montre que la mauvaise connaissance de son patrimoine est l’un des premiers écueil à l’accélération de la transformation des entreprises.
La seconde étape est la formalisation d’une feuille de route de cas d’usage data priorisés. Cela nécessite de réunir l’ensemble des parties prenantes au sein de l’organisation. Quels doivent être les grands objectifs de l’exploitation de ses données ? Quelle contribution à la stratégie d’entreprise? Plutôt moderniser sa relation, mieux connaître son marché ou optimiser ses processus métier ? Quels métiers ou quelles applications faut-il prioriser ? La formalisation de la feuille de route oblige à se poser toutes ces questions.
Sans cette étape il sera compliqué de définir les moyens adaptés et un modèle opérationnel pertinent permettant de soutenir cette ambition.
Structurer les processus et méthodologies projet
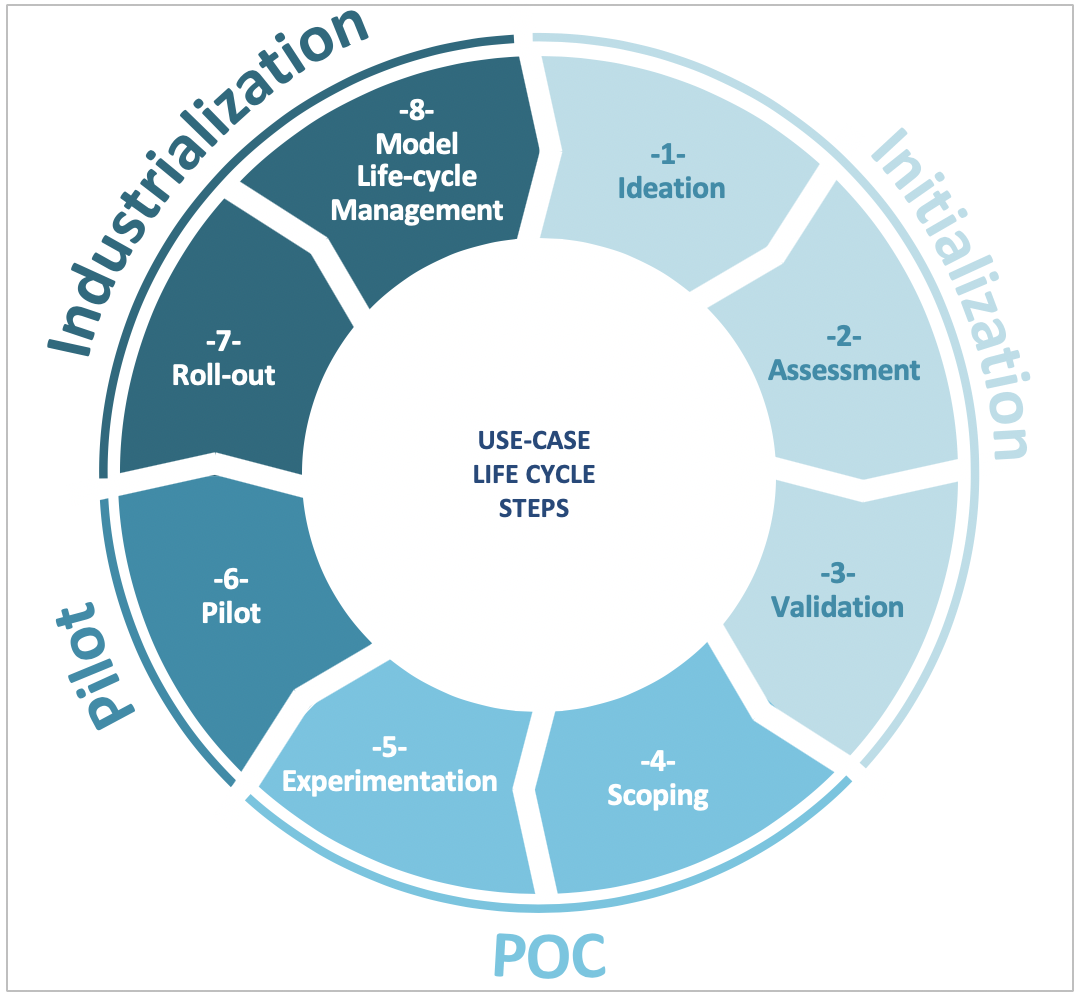
Les organisations ne sont pas encore très matures dans la structuration des processus et la mise en place d’une gouvernance globale des projets data. Les processus sont plus souvent empiriques que réellement formalisés. Cela a favorisé le démarrage rapide des premières expérimentations mais devient un frein lors des phases d’industrialisation et de mise en production. Nous avons pu observer quelques bonnes pratiques pour assurer le bon déroulé des projets et ne pas surinvestir dans des cas d’usage qui ne donneront rien :
- Impliquer dès le démarrage les équipes métier et IT concernées dans la définition des rôles et responsabilités tout au long du cycle de vie du cas d’usage data. Il est important de bien préciser le rôle de chacun à chaque phase, depuis le cadrage et jusqu’au run des projets, en passant par l’expérimentation et l’industrialisation. Si les méthodologies projet du datalab / datafab et de l’IT ne sont pas coordonnées, alors il y a peu de chance que la mise en production du projet data soit un succès.
- Formaliser et partager les critères de sélection des cas d’usage afin de s’assurer d’investir collectivement dans les bons projets
- Définir les livrables et instances obligatoires pour pouvoir passer à la phase suivante : quelles sont les conditions pour qu’un cas d’usage passe du stade du cadrage à celui de MVP ? Quels livrables et quelle documentation du code sont obligatoires pour garantir le bon passage à l’échelle ? Quels KPIs surveiller pour monitorer les algorithmes en production ? Dans quels cas faut-il arrêter le projet ? (ce qui n’est pas forcément un aveu d’échec). Répondre à ces questions et structurer la conduite des projets data sont essentiels pour optimiser les chances de succès d’un projet data.
Implémenter une politique de gouvernance de la donnée
Peu d’entreprises ont déjà implémenté une politique complète de gouvernance de la donnée. Si une part majeur des données commence à être cartographiée, les référentiels ne sont pas assez diffusés et les experts métiers pas assez impliqués. Rendre les données de l’entreprise connues, accessibles, de qualité et partageables est une condition nécessaire à l’installation d’une véritable culture data. Il s’agit d’un travail de longue haleine qui paye aujourd’hui pour les acteurs les plus en avance : ils sont maintenant capables de déployer des cas d’usage beaucoup plus rapidement, n’étant plus freinés par des problèmes de qualité et d’accessibilité des données.
La majorité des entreprises a pris conscience de cette nécessité et commence à recruter des compétences ad hoc mais ne sait pas par où commencer et comment mener à bien ce chantier qui est avant tout une véritable aventure humaine.
Notre conviction est qu’il faut y aller pas à pas en commençant par définir les grands principes fédérateurs des 4 piliers de la gouvernance de la donnée:
- rôles et responsabilités pour mobiliser l’ensemble des parties prenantes
- outils pour tangibiliser et donner corps à la gouvernance
- processus associés à chaque utilisation de la donnée
- standard et politiques pour, par exemple, clarifier ce qu’est une donnée de qualité ou une donnée accessible
Il sera ensuite temps de tester ces principes de gouvernance sur un cas d’usage clé et de sélectionner le(s) bon(s) outil(s) adapté(s) à ses besoins. Ce n’est qu’une fois réalisé l’ensemble de ces tâches que l’on pourra commencer à implémenter une politique globale de gouvernance de la donnée.
Renforcer et diversifier ses compétences
Enfin, nous en parlions déjà dans notre précédent article sur les limites des organisations data, les compétences data restent rares et difficiles à acquérir. Notre étude montre que les entités data se sont d’abord construites autour de quelques profils de Data Scientists. Pour grandir les organisations doivent répondre à 3 défis :
- Effectuer un rééquilibrage des forces de Data Scientists au profit de Data Architects et Data Engineers dans une optique d’industrialisation des modèles de data science. Ces derniers doivent d’ailleurs pouvoir être mobilisés dès le début des projets pour éviter les problèmes dans les phases ultérieures du projet;
- Intégrer des expertises data scientists de plus en plus pointues. Il sera utile d’associer aux data scientists “généralistes”, des experts pointus en modèles de prévision, d’analyse sous contrainte ou de NLP selon les besoins;
- Enfin, la volonté d’accélérer sa transformation fait également apparaître un nouveau rôle chargé de faire le pont entre les équipes data, métier et IT. Parfois appelé « data translator », ce rôle peut être considéré comme un équivalent des products owners pour les projets digitaux. Il doit être le chaînon manquant pour garantir la bonne atteinte des objectifs métier des projets en étant capable de comprendre aussi bien les enjeux métier que les spécificités d’un projet data et ses challenges scientifiques et techniques.
Rome ne s’est pas construite en un jour…
Les entreprises ayant enclenché leur transformation data driven se frottent à des premières difficultés d’ordre organisationnelles, structurelles, humaines et techniques. Ces organisations doivent donc encore faire évoluer leur modèle opérationnel afin de gagner en maturité pour supporter pleinement l’industrialisation et le RUN des projets data. Il n’y a pas de solution miracle pour réussir ce passage. Cela exige de la maturité et de la vision dans de nombreux domaines: l’embauche et la fidélisation de ressources complémentaires et qualifiées, la mise en œuvre des processus, l’infusion de la culture data bien au delà des frontières du datalab / datafab notamment à travers la gouvernance de la donnée… et d’avoir posé des bases solides à l’origine. Tout cela ne peut évidemment pas se réaliser en quelques mois, la clé de la réussite se trouve souvent dans la persévérance des organisations pour, étape par étape, gagner en maturité.