

Découverte de Snowflake comme solution de Data Mesh

Snowflake est ce que l’on appelle une « Cloud Data Warehouse » car elle combine 2 caractéristiques : celle d’être une base de données de type data warehouse et la seconde est de fonctionner uniquement en mode SaaS.
La société Snowflake est récente puisqu’elle a été créée en 2012. Mais elle a connu une croissance fulgurante ces dernières années au point d’être valorisée plus de 70 milliards de dollars fin 2020.
Dans cet article, je vais illustrer les points saillants de cette solution par rapport aux autres solutions « Cloud native » déjà présentes comme AWS Redshift, Azure Synapse Analytics ou GCP BigQuery. J’évoquerai également les points forts de la solution qui font que Snowflake permet de construire une solution de type data-mesh.
Snowflake, une solution de type Datawarehouse
Un Data Warehouse est utilisé pour collecter, transformer, historiser et préparer les données en vue, notamment, de les présenter au travers de dashboards de type Business Intelligence ou bien d’être exploitées en vue d’entraîner des modèles de Machine Learning.
Les solutions de type Datawarehouse sont relativement anciennes (une trentaine d’années) et très présentes dans les entreprises pour le pilotage de leur activité.
De nombreux acteurs sont présents comme Teradata, Oracle, IBM (Netezza, Db2 Warehouse), Microsoft (Azure Synapse Analytics, ex « Azure SQL Datawarehouse »), AWS (Redshift), Google (BigQuery), sans oublier la plateforme Cloudera / Hortonworks (Impala, Hive). Chaque acteur a ses spécificités. Par exemple, ils peuvent être installés on-premise, en mode hybride (on-premise et dans le Cloud managé par l’éditeur) ou dans un Cloud public uniquement. De même, le modèle économique est différent (licence à la capacité de traitement offerte, licence au volume stocké, licence à l’utilisateur, paiement à l’usage, paiement au volume de donné brassé lors des requêtes etc.).
La particularité des Datawarehouse est de ne traiter que des données structurées (données tabulaires par exemple) ou des données semi-structurées (JSON, XML…) pour certains moteurs. Les données de types vidéo, audio, images etc. sont hébergées dans un Datalake.
Une solution en mode SaaS uniquement
Snowflake a la particularité de n’être proposée qu’en mode SaaS depuis AWS, Azure et GCP. Il ne sera donc pas possible de l’installer « from scratch » sur son DataCenter privé.
Pourquoi ce choix ? Snowflake tire parti au maximum des avantages du Cloud, comme :
– L’élasticité de la solution (pouvoir adapter les ressources de calculs aux besoins des utilisateurs)
– Une installation standardisée (très peu d’options à sélectionner) et rapide (quelques minutes) depuis la Marketplace des Cloud Provider
– Une haute disponibilité assurée, les données étant répliquées 3 fois sur la région choisie
– Un coût de stockage réduit
Snowflake ne pourra donc pas convenir à tous les usages (contraintes réglementaires notamment) du fait que les données sont hébergées en dehors de l’Entreprise.
Ecosystème Snowflake
L’écosystème autour de Snowflake est conséquent et adapté pour un usage de bout en bout, depuis les plateformes d’ETL (Talend, Trifacta, Pentaho..), de restitution (Tableau, Qlik, PowerBI…) ou d’analyses (SAS, Dataiku…).
Ecosystème : source Snowflake
En quoi Snowflake est-elle différente ?
Outre le fait que la solution est « Cloud Native » et s’appuie sur les points forts des Cloud Provider, 3 caractéristiques principales font la différence :
1.Le découplage entre le stockage des données et le « moteur » de base de données
2.La facilité de partager des données avec des partenaires
3.La possibilité de copier instantanément des données sans les dupliquer
Snowflake : fonctionnement interne
Les données dans Snwoflake sont stockées dans un espace de type « blob storage » comme AWS S3.
Le requêtage des données se fait à l’aide de « serveurs », dont le nombre dépend du choix de l’utilisateur (1 à 128).
Le nombre de serveurs s’adapte automatiquement (à la hausse comme à la baisse) aux sollicitations des charges de travail. Dans le cas où il n’y a aucune activité, aucun serveur n’est alloué ; quelques secondes sont nécessaires pour rendre actif un serveur.
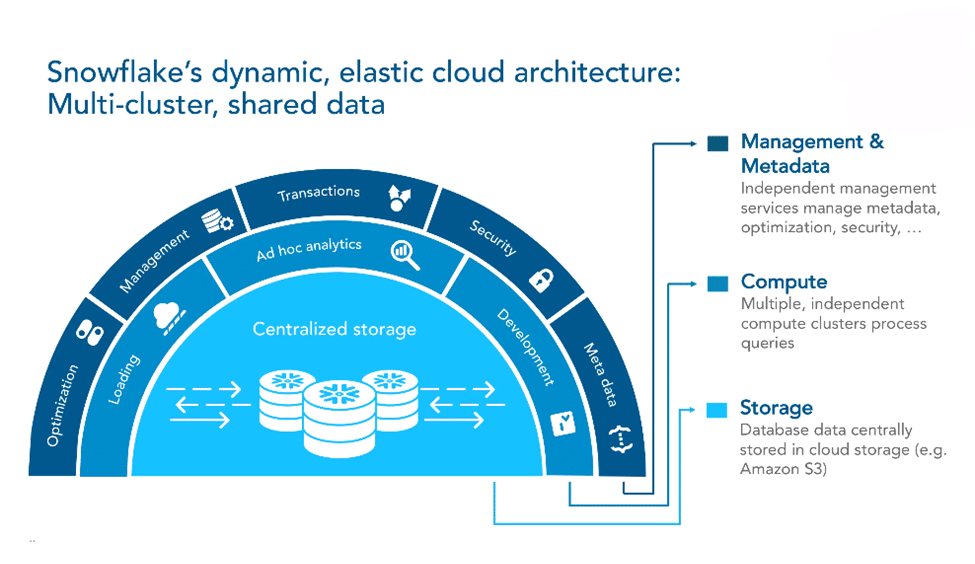
Architecture : source Snowflake
Le coût est déterminé selon la quantité de données stockées et du nombre de secondes où les serveurs ont été sollicités.
Retrouvez plus de détails sur les coûts via cette URL https://docs.snowflake.com/en/user-guide/warehouses-overview.html
Snowflake versus AWS Redshift
Les données dans AWS Redshift sont stockées au sein des nœuds de calcul Redshift. Au fur et à mesure que la volumétrie des données augmente, il est alors nécessaire d’ajouter des nœuds Redshift (et de re-équilibrer les données au sein du cluster, ce qui peut durer plusieurs jours). Il y a donc une corrélation très forte entre volume de données et capacité de calculs.
Le modèle économique est au nombre de nœuds Redshift provisionnés : le coût est le même que le cluster ne traite aucune requête ou que le cluster soit très sollicité.
Snowflake versus GCP BigQuery
Tout comme Snowflake, le stockage des données et le « moteur » de GCP BigQuery sont séparés, permettant d’évoluer indépendamment. La capacité de calcul du « moteur » s’adapte en fonction de la sollicitation afin de répondre aux requêtes le plus rapidement possible.
Le modèle économique dépend de la quantité de données stockées (comme Snowflake) et du volume de données brassées lors de la requête. Il s’agit donc d’un paiement à l’usage mais, contrairement à Snowflake, non pas basé sur la capacité de calcul du « moteur », mais sur la quantité de données requêtées.
Snowflake versus Azure Synapse Analytics
Azure Synapse Analytics est une solution complète de traitement de la donnée (de l’intégration, leur transformation, le Machine Learning, le DataLake, la Visualisation…). Elle intègre la brique « SQL Data Warehouse » qui s’apparente aux fonctionnalités de Snowflake. Cette brique SQL permet d’interroger les données stockées dans Azure Data Lake ou dans Azure Blob Storage, en utilisant des ressources provisionnées (comme Redshift) ou à la demande.
Quelques spécificités de Snowflake versus autres compétiteurs
|
Snowflake |
Redshift | Azure Synapse Analytics
(ex Azure SQL DW) |
BigQuery |
|
| Elasticité |
Automatique et limité au nombre de serveurs max allouables |
Manuelle | Manuelle | Automatique et non limité |
| Gestion des index |
Non |
Limité (sort key) | Oui | Non |
| Distribution des données |
Automatique |
Hash, round-Robin, Replicate | Hash, round-Robin, Replicate | Automatique |
| ACID (*) |
Oui |
Eventuellement Cohérente | Oui |
Oui |
|
Clés Unique / Primaire / Etrangère (**) |
Oui | Non | Primaire et Unique |
Non |
(*) ACID : Atomicité, Cohérence, Isolation, Durabilité
(**) : dans le cas de larges tables, positionner des clés est contre-productif du fait de la lenteur induite par les vérifications lors des modifications des données. Ces propriétés peuvent être toutefois intéressantes à mettre en œuvre dans le cas de tables de références à volumétrie faible (référentiel produits, base clients…) afin d’en garantir la qualité (cas des doublons notamment).
L’architecture de Snowflake
L’architecture Snowflake est composée de 3 couches.
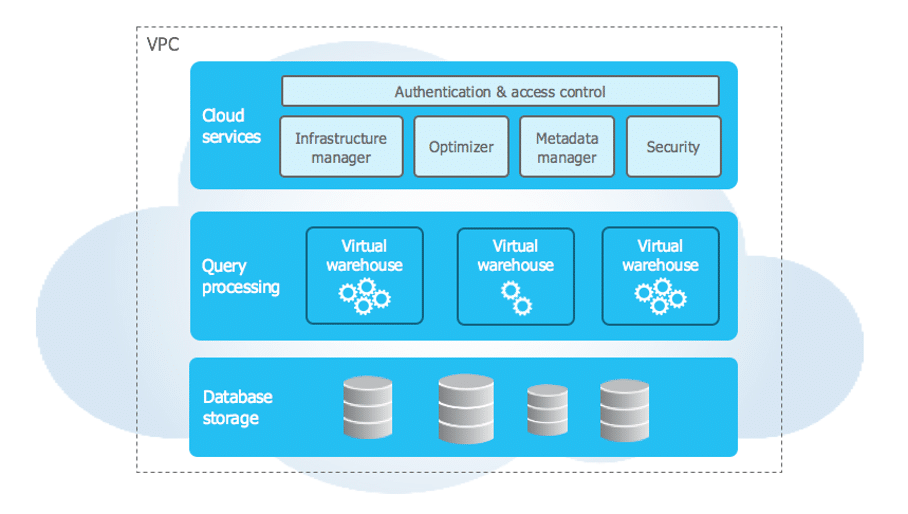
Architecture : source Snowflake
Cloud Services
« Cloud Services » est un ensemble de services coordonnant les activités à travers Snowflake. Ces services relient tous les différents composants de Snowflake afin de traiter les demandes des utilisateurs, de la connexion à l’envoi des requêtes.
Query Processing
L’exécution de la requête est effectuée dans la couche de traitement. Snowflake traite les requêtes en utilisant des « entrepôts virtuels » (virtual warehouse). Chaque entrepôt virtuel est un cluster de calcul MPP composé de plusieurs nœuds de calcul alloués par Snowflake à partir d’un Cloud provider (AWS, Azure ou GCP).
Chaque entrepôt virtuel est une grappe de calcul indépendante qui ne partage pas les ressources de calcul avec d’autres entrepôts virtuels. Par conséquent, chaque entrepôt virtuel n’a pas d’impact sur les performances des autres entrepôts virtuels.
Il est donc possible d’avoir plusieurs « virtual warehouse » pour son projet, chacun pouvant être responsable d’une activité (chargement de données, requêtes pour le dashboarding, requêtes ad-hoc par des analystes…). Ainsi, on peut limiter les contentions : dans le cas où un chargement massif de données est réalisé, cela n’aura pas d’impact sur les requêtes provenant des utilisateurs, les capacités de calcul étant différentes.
Database Storage
Lorsque les données sont chargées dans Snowflake, Snowflake réorganise ces données dans leur format interne optimisé, compressé et en colonnes. Snowflake stocke ces données optimisées dans des « blob storage » (comme AWS S3, offrant un coût de stockage réduit et une durabilité de 99,999999999 %).
Snowflake gère tous les aspects de la manière dont ces données sont stockées. L’organisation, la taille des fichiers, la structure, la compression, les métadonnées, les statistiques et d’autres aspects du stockage des données sont gérés par Snowflake.
Zero-Copy Data Cloning
Une fonctionnalité très intéressante est la possibilité de « cloner » des données provenant d’une base, un schéma ou d’une table sans copier les données.
Dans l’exemple ci-dessous, une table (en bleu) est clonée pour donner, en quelques secondes, 2 autres tables, copies exactes de la table initiale (mais sans que les données ne soient dupliquées).
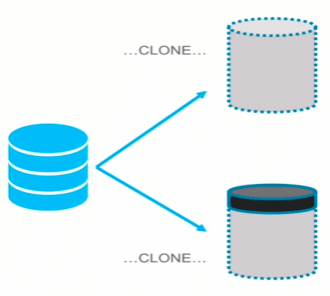
Clonage de données : source Snowflake
Il est possible de requêter les tables clonées de la même manière que la table initiale.
Il est de plus possible d’effectuer des opérations de modification des données clonées (ajout, suppression, mise à jour, etc.) : seules les différences sont stockées (en noir dans le schéma ci-dessus).
Les cas d’usage sont multiples :
- Audit et réglementation: avoir l’image des données d’une base à un moment donné
- Tests et développements: mise à disposition de données de Production dans un environnement de Développement en quelques secondes, afin de fiabiliser les développements (volumétrie cible, jeux de tests cohérents etc.)
- Application d’une correction d’une base en production :
- cloner la table incriminée
- apporter une correction
- tester le résultat
- promouvoir la table clonée comme table de production
Le Data Sharing selon Snowflake
Une autre fonctionnalité très importante est la faculté de Snowflake de partager simplement des données, en lecture uniquement, à d’autres intervenants, sans dupliquer les données (uniquement si la même région « cloud » est utilisée).
Snowflake a 3 types de comptes impliqués dans le partage :
1. Le « Data Provider » : c’est le compte qui est responsable de rendre disponible des donnés à des consommateurs. Il détermine quelles sont les données à partager (table, vue…) et qui peut y accéder (en référençant les comptes Snowflake). Les données ne sont pas dupliquées durant le partage.
2. Le « Data Consumer » : c’est le compte Snowflake, référencé précédemment comme pouvant accéder aux données, qui interroge les données via des requêtes. Le coût du stockage des données est supporté par le « Data Provider » (puisqu’il n’y a pas de recopie de données) mais le coût des requêtes est supporté par le « Data Consumer ». Le « Data Consumer » peut créer de nouvelles données, en croisant les données mises à disposition par le « Data Provider » avec celles présentes dans son propre environnement Snowflake.
3. Le « Reader Account » : il ne possède pas de compte Snowflake mais ce compte particulier a été créé par le « Data Provider » afin de lui permettre d’accéder aux données et de les requêter ; aucune action d’écriture n’est possible. Les coûts sont supportés par le « Data Provider ».
Les cas d’usage sont multiples :
- Monétisation des données, en permettant simplement de les partager avec des partenaires qui n’ont pas d’environnement Snowflake
- Mise à disposition de données à ses clients, en filtrant, par client, les données disponibles
- Constitution d’un environnement de type « data mesh », en mettant simplement à disposition des données d’un domaine vers d’autres domaines de l’Entreprise. Ce type d’environnement permet de casser les silos et de rendre responsable chaque domaine dans la constitution du patrimoine data de l’Entreprise.
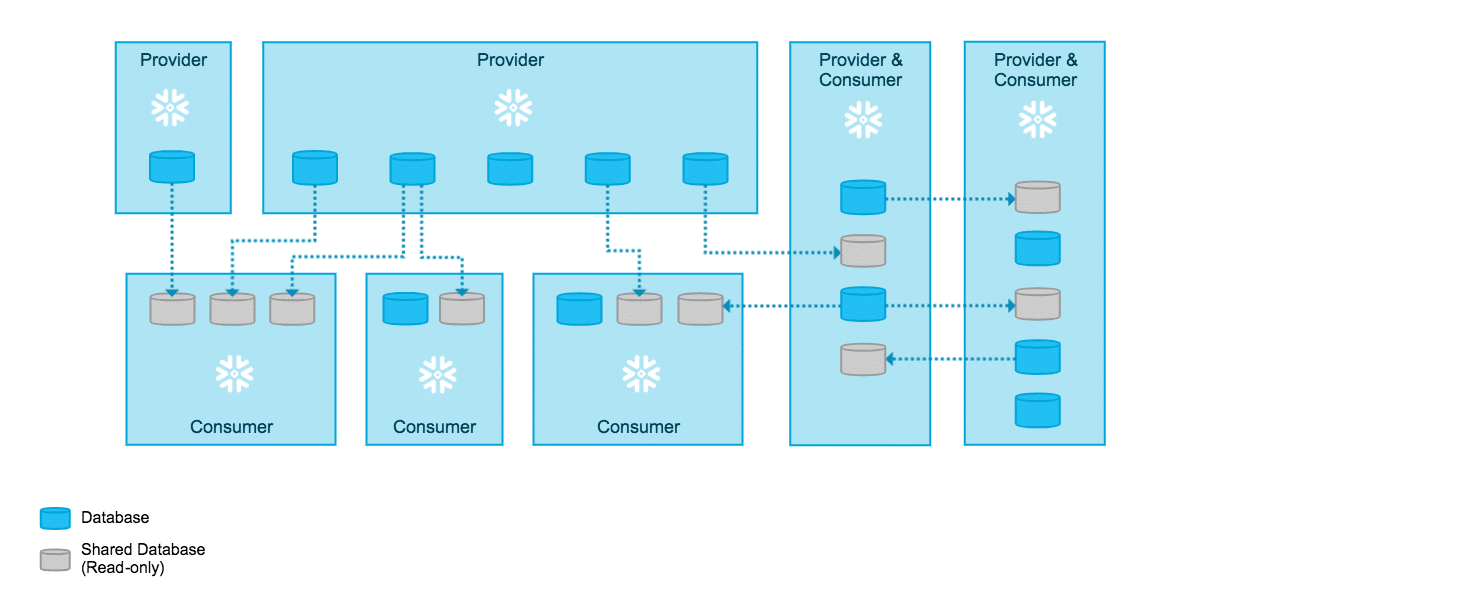
Partage des données : source Snowflake
Data-mesh
Le Data Mesh est un concept focalisé sur les produits, la gestion décentralisée des données et l’architecture des données autour de domaines métiers.
Snowflake, par sa conception, permet de « cocher » les caractéristiques de ce que l’on entend par « data mesh ».
Les domaines métiers
Le partage aisé des informations de Snowflake permet, non plus de centraliser le développement du Datawarehouse, mais au contraire de laisser l’autonomie à chaque domaine métier de développer son propre silo pour ses propres besoins, avec une équipe dédiée et proche du domaine fonctionnel du domaine, puis de mettre à disposition les données au rester de l’Entreprise.
Par exemple, les domaines :
- « Commercial » est responsable de mettre à disposition les données relatives à la base Clients
- « Ventes » est responsable de mettre à disposition du chiffre d’affaires, par client et par gamme
- « Service après-ventes » est responsable d’identifier les réparations effectuées
Chaque domaine est responsable de la qualité des données fournies, du respect de la mise à disposition avec une fraicheur convenue et d’assurer le suivi et des évolutions.
La gestion décentralisée des données
Il est fréquent, dans le cas d’organisations internationales, que des domaines soient répartis sur des zones géographiques différentes et que des partenariats régionaux aient été conclus avec des fournisseurs Cloud différents.
Dans le cas où Snowflake est la solution globale retenue par l’Entreprise, le partage des documents entre régions différentes (on l’a vu précédemment, le partage sans recopie de données n’est possible que région par région) est possible via une réplication de données (les données sont automatiquement copiées d’une région à une autre).
Snowflake étant agnostique du fournisseur Cloud sur lequel il est installé, le transfert de données peut se faire de manière transparente (attention toutefois aux coûts facturés par les fournisseurs Cloud dans ce cas).
La figure ci-dessous représente un cas de partage de données extrême : certaines données contenues dans la tableA du compte AcmeProviderAccount1 (stockées sur AWS de la région US West) sont répliquées (à travers la view1) sur une autre région (US Est) d’un autre compte de l’organisation Acme : AcmeProviderAccount2 où Snowflake est installé sur Azure. Le contenu de latableA est alors partagé, sans recopie de données, à un « ConsumerAccount » de la même région à travers une vue view1.
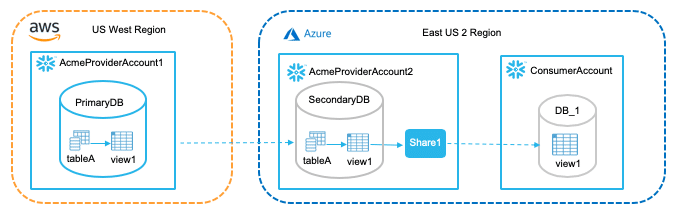
Partage des données via réplication : source Snowflake
Le produit
En partageant les données mises à disposition par les domaines à travers Snowflake, où qu’elles se situent (géographiquement et physiquement) et en les croisant, il est alors possible d’avoir une vue consolidée de l’activité de l’Entreprise (ex : vue à 360° de ses clients).
Snowflake a introduit en 2020 une nouvelle solution : le « Snowflake Data Marketplace« , accessible à tous les clients Snowflake, permettant à des fournisseurs de données de référencer les données et les monétiser.

Exemples de dataset : source Snowflake Market Place
Snowflake et la Data Science
Snowflake ne met en place aucun outil spécifique pour le machine learning. Il se positionne comme un accélérateur pour les Data Scientist, en centralisant toutes les données de l’Entreprise dans une unique solution : les données sont facilement accessibles, via les partages, et ne sont pas dupliquées.

Environnement Data Science : source Snowflake
En cela, Snowflake est différent des produits comme :
- Azure Synapse Analytics, qui se veut comme une plateforme Data complète, intégrant les outils de ML de Microsoft
- GCP BigQuery, où BigQuery ML permet de créer et d’exécuter des modèles de machine learning directement dans BigQuery, à l’aide de requêtes SQL.
Snowflake se rapproche de Redshift, qui est une solution ne comprenant que la brique Datawarehouse, pour servir de puits de données à AWS Sagemaker par exemple.
Que peut-on retenir de Snowflake ?
Snowflake apparaît comme un produit novateur :
- Son approche « Cloud Native » tire au mieux les avantages du Cloud (Saas, élasticité, haute disponibilité) ;
- Son approche « zero-copy » permet un gain sur les coûts de stockage et sur la rapidité de mise en œuvre de « replicas » ;
- Son partage simple des données contribue à la mise en place d’une architecture de type « data mesh »
Ces qualités permettent d’envisager de nouveaux cas d’usage et une rapidité de mise en œuvre inédite pour ce genre de produits. Pour un acteur des services B2B nous avons par exemple recommandé le déploiement de ce produit car il proposait le meilleur ratio entre fonctionnalités avancées et facilité d’exploitation pour l’équipe Data en comparaison d’autres produits (Open-source ou solutions cloud public).
Pour le Data Scientist, le principal avantage est de pouvoir se constituer un dataset plus efficacement, via la mise à disposition simplifiée des données que propose Snowflake (que ce soit au travers de données réalisées par des Domaines ou des données mises à disposition via la « data Marketplace »). Cela lui évite la très longue phase de consolidation des données (ETL) vers un unique lieu de stockage, qui peut occuper 80% du temps de travail d’un Data Scientist.
