

Documenter son propre code : petit guide de survie

Fournir un code qui fonctionne c’est bien, pouvoir en transmettre la connaissance c’est mieux. L’article d’aujourd’hui va nous permettre de mieux comprendre les problématiques et les outils existants pour la documentation d’un projet. Nous avons préféré scinder ce sujet complexe en deux parties. Ce premier article introduit les outils existant, les pièges à éviter et les best practice pour une transmission de connaissances projet réussie. Dans un deuxième article nous présenterons un outil développé par Quantmetry permettant spécifiquement de documenter et de gérer son projet de data science de façon automatisée.
Pourquoi la documentation est-elle systématiquement mal faite ?
En théorie, n’importe quel projet informatique possède une documentation, elle fait partie du format de livrable standard. Toutefois le contexte (deadlines, itérations, changements de dernières minutes, …) est souvent propice à l’échec de cette phase. Cet échec est aussi relié au syndrome du « dernier kilomètre » bien connu des chefs de projet. La finition d’un projet est souvent sous-estimée car le produit reste fonctionnel sans cette étape. La documentation est à tort considérée comme un « bonus ». En conséquence, la plupart des développeurs procrastinent jusqu’aux ultimes semaines avant de s’attaquer à cette partie. Ou alors, encore pire, une documentation est commencée très tôt, sans doute avec les meilleures intentions du monde, mais celle-ci est oubliée au cours du temps. Le problème est que le code évolue alors que la documentation reste statique. On aura tendance à reprendre cette dernière telle quelle et bâtir dessus en « oubliant » qu’elle n’est plus à jour.
La solution apparaît d’elle-même en observant ces principaux freins. La transmission de la connaissance est mal faite car elle est systématiquement vue comme une brique séparée du reste du projet. Il faut donc trouver un moyen de faire coïncider l’implémentation de la solution et l’écriture de la documentation. Ce conseil est valable tant pour la documentation du code, que pour la rédaction d’un manuel utilisateur ou d’un pipeline de data science.
La solution : l’automatisation
Le processus d’écriture de code est déjà lui-même très riche en termes de documentation. Il arrive souvent de décrire dans des commentaires (ou mieux dans des docstrings) ce qu’on est en train de faire, ce qui motive nos choix d’implémentations et les potentiels évolutions à amener au code par la suite. Il faut donc profiter de cette ressource pour l’intégrer automatiquement à notre documentation. Il est très simple et très enrichissant de décrire une fonction sur le moment alors qu’il est très coûteux de recoller les morceaux à la toute fin du projet.
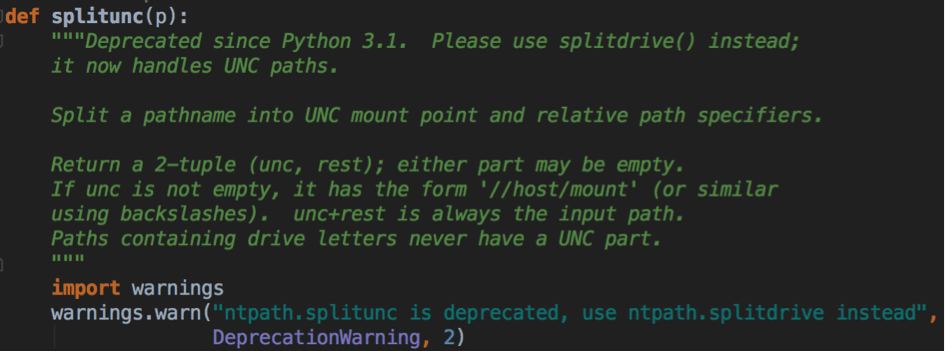
Un exemple de docstrings python
Sphinx : un outil intégré
Il existe des solutions permettant de récupérer « à la volée » la documentation écrite dans le code.
C’est le cas de Sphinx, sorti en 2008. Cet outil open source permet d’éditer une documentation pour son code et facilite son export sous divers formats (page web html, Pdf). Une fonctionnalité très appréciée est la découverte automatique des dépendances du code et la génération automatique de la documentation associée à chaque classe et fonction utilisée. Sphinx recherche justement les « Docstrings » des fonctions afin de les intégrer à la documentation. L’outil est ensuite capable de construire une application web reprenant la structure des packages python du code et permettant de naviguer pour rechercher des explications sur une partie du projet.
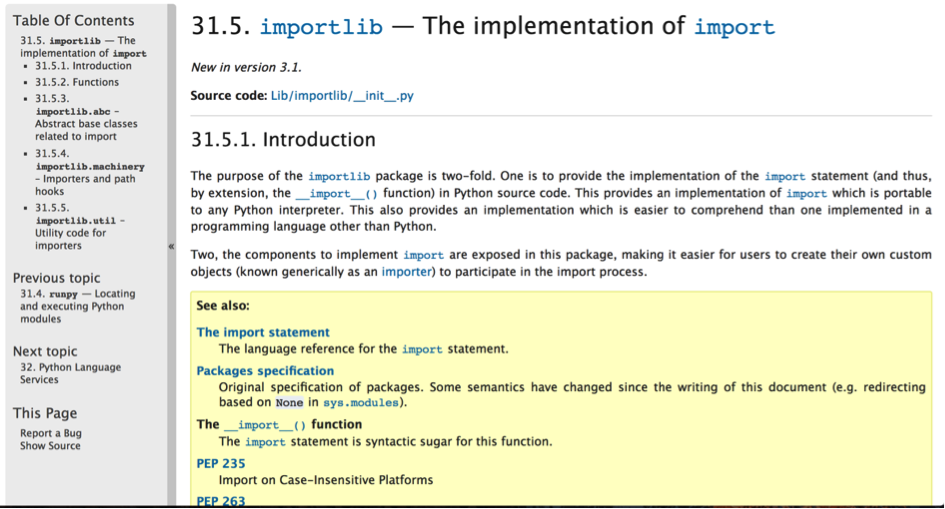
La documentation officielle de Python est générée avec Sphinx
Bien que Sphinx soit initialement développé pour Python, il offre un support pour la vaste majorité des langages existants. Toutefois ceci requiert un peu de configuration. On pourra citer d’autres librairies permettant la génération automatique de la documentation du code comme par exemple Doxygen, Pandoc, Dr explain ou encore Natural Docs.
Et la documentation de la data science dans tout ça ?
Vous l’avez compris : on peut documenter notre code, et c’est déjà très bien. Toutefois la data science nous impose également un autre type de documentation : celle de la donnée. Nous aimerions tous pouvoir documenter nos sources et nos pipelines de transformations de données de façon automatisée.
Le problème est différent de la documentation du code. Il existe une méthodologie de développement pour s’en sortir, mais il faut poser pour cela un peu plus de contraintes sur la manière de programmer. En effet, la documentation d’un pipeline de traitement de la donnée nécessite de se doter d’un outil capable de gérer les dépendances entre les différentes sources et les transformations qui ont été effectuées sur chacune d’elles. On doit donc utiliser ou construire une librairie capable de construire et d’exploiter ces dépendances, voir de créer un graphe d’exécution des différentes modifications sur nos données. Un Framework comme Luigi peut être utilisé dans cette optique.
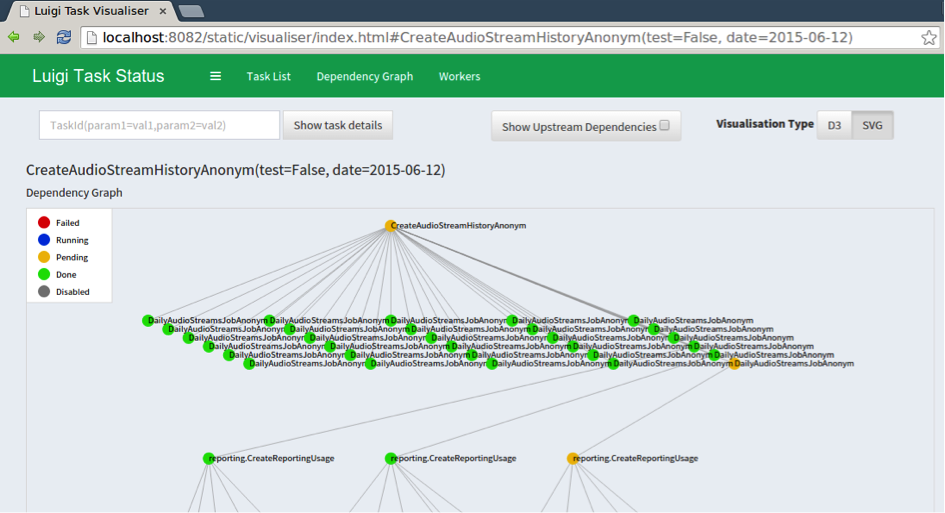
Gestion de tâches dépendantes les unes des autres sur Luigi
Une deuxième étape importante est de créer un objet représentant une « transformation », c’est-à-dire une opération sur les données. Cette transformation peut être élémentaire (agir sur une colonne d’une base de données) ou plus complexe, l’important est de garder une structure unique et paramétrable pour la décrire. Il s’agit d’un nouveau paradigme de développement, car le développeur devra encapsuler toutes les modifications d’une source de données dans un objet « Transformation ». Ceci n’enlève toutefois rien à la généricité de ce qu’il peut entreprendre. Chaque transformation pourra donc éditer une documentation spécifique et dépendante de la donnée. Le résultat d’une jointure entre deux bases pourra être documentée, tout comme la performance d’un modèle. Au-delà d’une simple documentation il s’agit donc d’un modèle permettant une traçabilité totale et uniformisée des opérations et des sorties réalisées sur les données.

Un exemple de documentation générée automatiquement
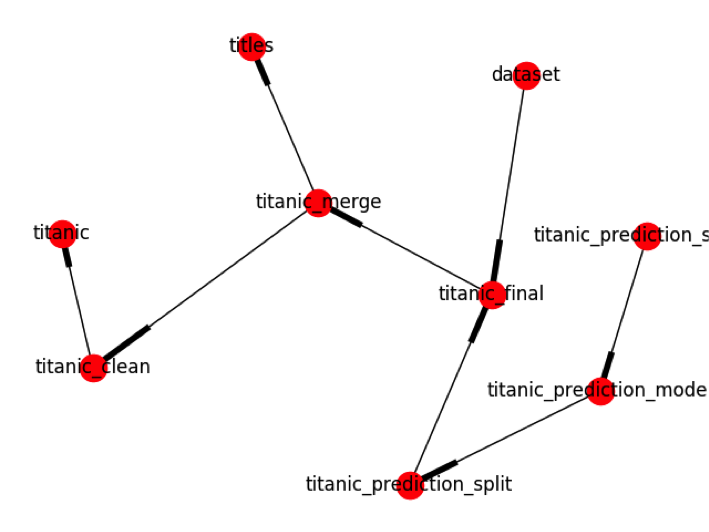
Un exemple de graphe d’exécution généré automatiquement
En conclusion
Au-delà des soucis de transmission du code d’un projet la documentation de la donnée permet de s’assurer d’une traçabilité totale des modèles que l’on crée, de se donner les moyens de communiquer efficacement nos modèles et d’utiliser une méthode exhaustive, générique, fiable et traçable.
En tant que data scientist, grâce aux moyens entrepris pour documenter mon code et mes données mon projet de data science sera plus facilement industrialisable.
J’espère que cet article vous aura permis de réaliser l’importance de la documentation dans nos métiers et que les outils pour faciliter cette étape sont nombreux et performants. Nous entrerons plus en détail dans ce qu’on pourrait appeler la « data-documentation » dans un prochain article. Nous étudierons pour cela un outil de documentation développé par Quantmetry permettant de dépasser la simple problématique de transmission de connaissance. Stay tuned !
