

Etat de l’art Kubernetes (K8s) mi-2018
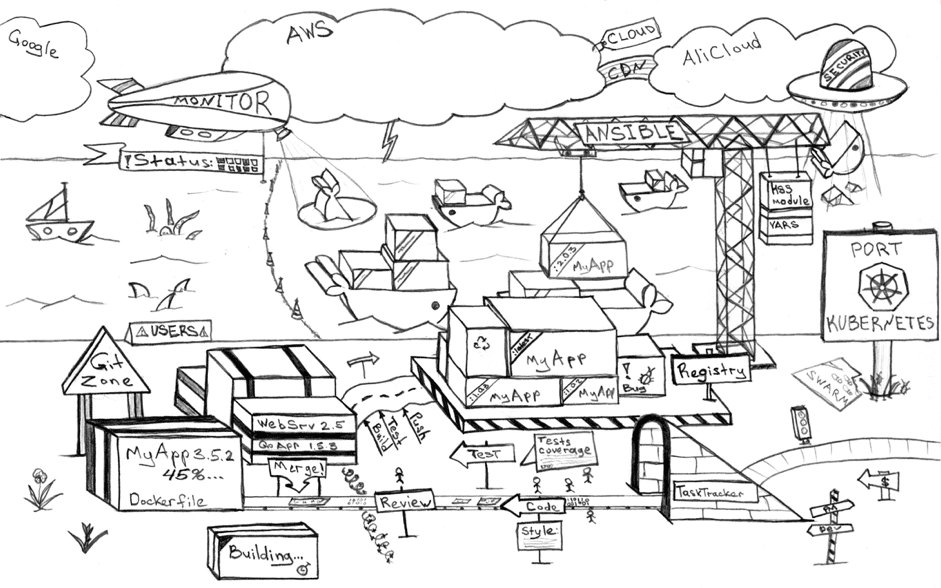
Cet article s’adresse à un public novice sur les technologies de conteneurisation (i.e. Docker et Kubernetes). Il s’agit d’une mise à jour de l’état de l’art de l’écosystème Kubernetes à mi-2018. La technologie K8s n’est pas récente, en revanche de nouveaux usages émergent du fait de son enrichissement par des solutions complémentaires.
Introduction
L’écosystème Kubernetes est fortement influencé par la mouvance de développement d’application DevOps. Notamment, lorsque la partie Dev est prépondérante au regard des aspects Ops.
D’après Wikipédia, l’objectif d’un conteneur est le même que pour un serveur dédié virtuel : héberger des services sur un même serveur physique tout en les isolant les uns des autres. Un conteneur est cependant moins figé qu’une machine virtuelle en termes de taille de disque et de ressources allouées.
La configuration, le déploiement et la gestion de plusieurs conteneurs pour de multiples microservices peuvent s’avérer fastidieux et se complexifier au fur et à mesure de la croissance du Système d’Information (SI).
C’est là qu’intervient Kubernetes. K8s est un orchestrateur de conteneurs. La principale mission de ce dernier est d’automatiser le cycle de vie des conteneurs : le déploiement, les mises à jour, le contrôle d’état et les procédures de basculement.
Ci-dessous, les différentes étapes du développement d’application dans un contexte conteneurisé

Kubernetes tire ses origines dans le projet de recherche Google Borg initié dans les années 2003/2004. K8s est un projet au code source ouvert (open source) offert à la Cloud Native Computing Foundation (CNCF) en 2015. Le 6 mars 2018, Kubernetes est le premier projet de la CNCF à être gradué (graduated project) : ce statut reflète le niveau de maturité avancé de l’écosystème. Selon la CNCF, il s’agit désormais de la plate-forme d’orchestration de conteneurs la plus populaire au monde.
Intérêts
Les intérêts de cette solution sont nombreux. Elle permet de :
- Se focaliser sur la façon dont les applications doivent fonctionner, plutôt que sur des détails spécifiques d’implémentation.
- Éviter l’enfermement propriétaire : les applications sont agnostiques à l’infrastructure physique. Seule la configuration de la grappe (cluster) Kubernetes est spécifique à chaque hôte.
- Faciliter la transition et migrer en douceur vers une nouvelle architecture sans bouleverser les applications existantes. Par exemple, passer d’une architecture monolithique vers une architecture microservices. Ou, dans un SI plus urbanisé, évoluer d’une architecture microservices vers une architecture émergente sans serveur (serverless), également appelé Fonction en tant que Service (Function as a Service ou FaaS)
- Cloisonner les logiciels, chaque application est packagée avec toutes ses dépendances. Elles possèdent un cycle de vie indépendant les unes des autres.
Sous le capeau
Historique
Kubernetes est une technologie mature, forte de quinze années d’évolution. Elle a été inspirée par divers projets de recherches et solutions internes de Google : principalement Borg et Omega. Le premier est notamment à l’origine de bon nombre de technologies autour des conteneurs tel LXC, Docker, etc.
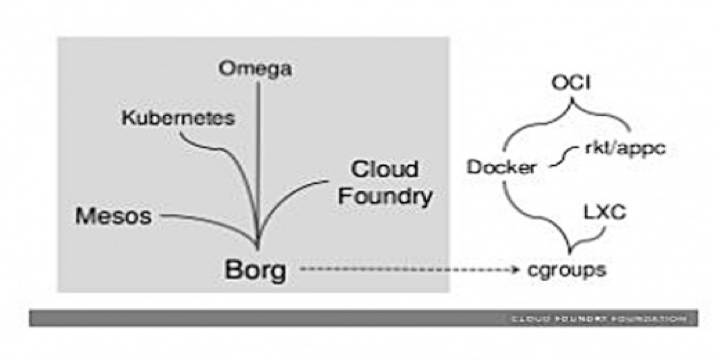
En 2014, Google exécute deux milliards de conteneurs par semaine avec ces systèmes. Lors de la DockerCon 2017, Docker annonce qu’il supporte désormais nativement Kubernetes. L’orchestrateur historique, Docker Swarm, n’est plus l’unique solution supportée.
Quelques notions de conteneurs
K8s est étroitement lié à la technologie de conteneurisation sous-jacente. Docker étant le gestionnaire de conteneur le plus couramment utilisé, les exemples suivants seront basés sur cette technologie.
Avant d’aller plus loin, il est important d’avoir en tête trois notions de base propre à cet univers :
- Les images de conteneurs : c’est un logiciel léger, autonome et exécutable comprenant tout ce qui est nécessaire pour exécuter une application: code, runtime, outils système, bibliothèques système et paramètres.
- Les conteneurs eux même : les images de conteneur deviennent des conteneurs au moment de l’exécution. Disponible pour les applications Linux et Windows, le logiciel conteneurisé fonctionnera toujours de la même manière, quelle que soit l’infrastructure. Les conteneurs isolent les logiciels de leur environnement et garantissent un fonctionnement uniforme malgré les différences, par exemple, entre le développement, la recette et la production.
- Le dépôt d’image de conteneurs (repository) : Service généralement haute disponibilité, car point unique de défaillance d’un SI architecturé autour des conteneurs. Il existe des services publics et privés, hébergés dans les nuages ou sur site : Docker Registry (projet à source ouverte), Docker Trusted Registry (partie de la version entreprise), Google Container Registry, etc.
Ci-dessous, le schéma mettant en avant les différentes couches physique d’un serveur d’applications conteneurisées :
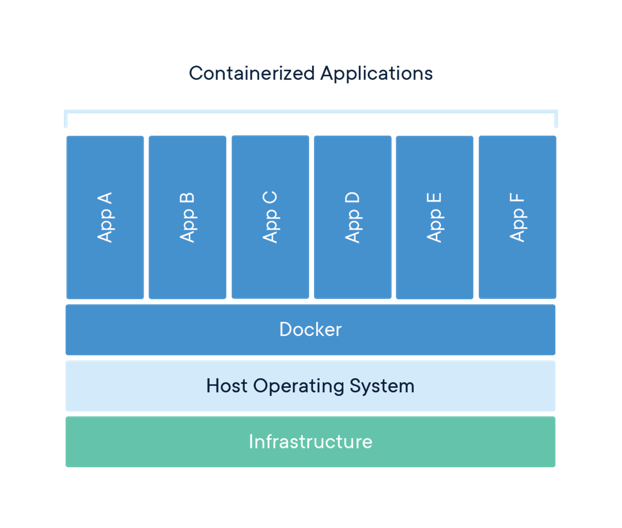
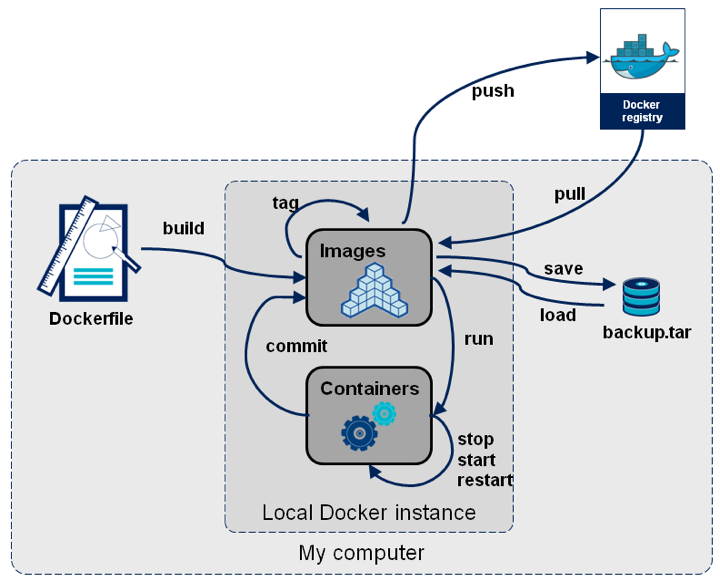
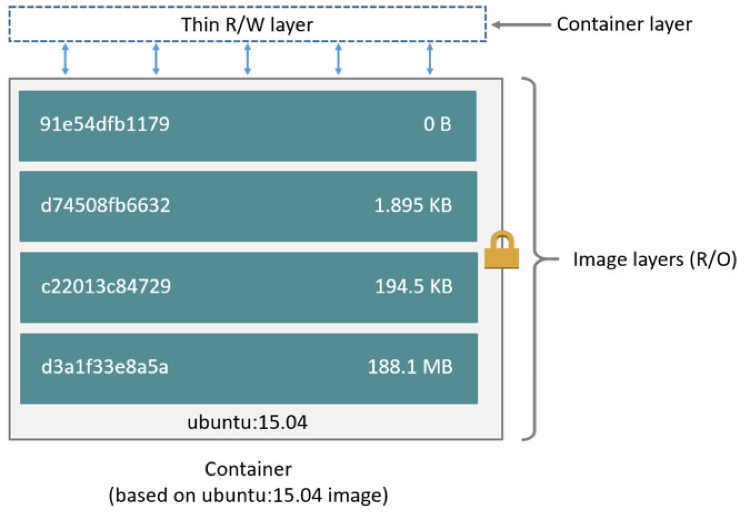
Le délai de disponibilité d’un nouveau conteneur est corrélé à sa taille et à la complexité des traitements réalisés lors de la phase de démarrage de celui-ci (i.e. l’exécution du code définit via les instructions CMD et ENTRYPOINT du Dockerfile). La construction de conteneurs optimisés repose sur deux principaux concepts :
- L’utilisation d’une image racine minimaliste comme alpine Linux en lieux et place d’une distribution standard (i.e. Ubuntu ou CentOS). Ce type d’image fait quelques dizaines de méga-octets contre plusieurs centaines pour une Ubuntu ou Debian.
- L’usage de la fonctionnalité multi-stage lors de la phase de construction des images des conteneurs Dockerfile.
Outre les performances accrues, l’utilisation d’images minimalistes contribue fortement à renforcer la sécurité du SI. Le nombre restreint de services et/ou applications disponible réduit le périmètre des failles de sécurité.
Un point d’attention mérite d’être apporté concernant la manière dont les données sont persistées au sein d’un conteneur. Toutes les données stockées directement au sein du conteneur lui-même sont perdues lorsque le conteneur est supprimé. Pour persister les données en dehors de la durée de vie des conteneurs, il faut stocker les données sur un système externe (i.e. HDFS, S3, GCS, Base de données, etc.).
Quelques notions d’orchestration de container
Avant d’aller plus loin, il est important de rappeler la définition d’un orchestrateur. Ci-dessous, la vision de Hewlett Packard Enterprise :
les applications sont généralement constituées de composants mis en conteneur individuellement (souvent appelés microservices) qui doivent être organisés au niveau du réseau afin que l’application puisse fonctionner correctement. Ce mode d’organisation des conteneurs est appelé orchestration de conteneur.
Dans le développement moderne, les applications ne sont plus monolithiques, au contraire, elles sont composées de douzaines voire de centaines de composants mis en conteneurs, peu structurés, qui doivent fonctionner ensemble pour permettre à telle ou telle application de fonctionner correctement. L’orchestration de conteneur désigne le processus d’organisation du travail des composants individuels et des niveaux d’application.
Les concepts clés de K8s
L’architecture Kubernetes repose sur trois notions fondamentales expliqué ci-après :
- Pods
- Services
- Equilibrage de charge (Load Balancer)
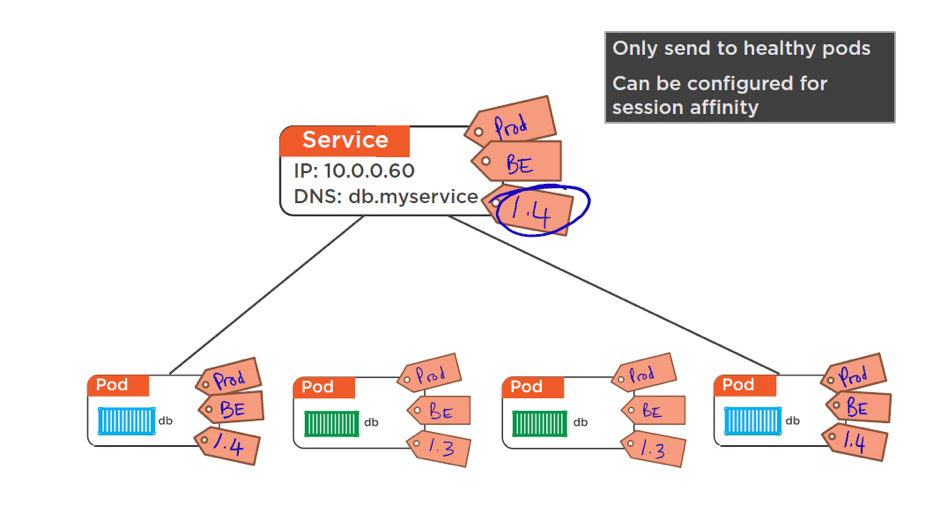
Le schéma ci-dessous illustre les interactions entre ces notions :
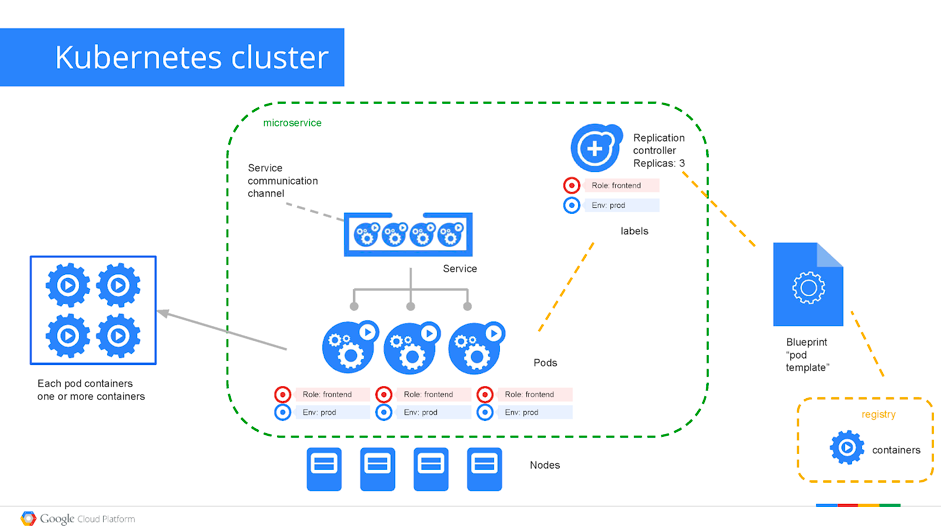
L’autre concept clef de l’architecture K8s, c’est la notion de services applicatifs. D’après Wikipédia, il s’agit d’un groupe de pods travaillant ensemble. Par exemple, une couche dans une application multicouche. L’ensemble des pods qui constituent un service est défini par un label selector (i.e. sur le schéma précédent, Role = frontend et Env = prod).
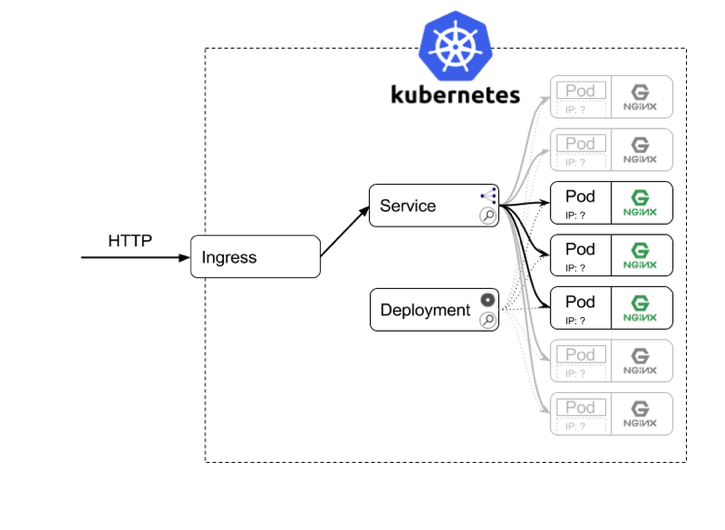
Par défaut, les services ne sont pas exposés à l’extérieur de la grappe K8s. Une façon simple d’exposer un service, consiste en l’utilisation d’un service de type équilibrage de charge.
Ci-dessous, un exemple d’implémentation (le bloc ingress représente l’équilibreur de charge) :
Interactions entre Docker et K8s
Kubernetes est un orchestrateur de conteneurs, il peut être vu comme un système d’exploitation dédié aux centres de données.
Bien qu’il existe d’autres orchestrateurs, Kubernetes est à ce jour l’unique solution recommandée par la CNCF pour couvrir les besoins en orchestration de conteneur.
K8s répond à l’ensemble des problématiques ci-dessous :
- Comment démarrer les conteneurs ?
- Comment exposer vos services containerisés ?
- Comment gérer les conteneurs arrêtés suite à une erreur ?
- Comment gérer les pannes des hôtes/nœuds ?
- Comment gérer la maintenance de vos hôtes/nœuds ?
- Comment gérer les mises à l’échelle
- Au niveau applicatif : plutôt scalabilité horizontal ou vertical ?
- Au niveau de l’infrastructure du SI : couverture géographique, haute disponibilité ?
- Comment gérer la multiplication du nombre de composants à déployer ?
- Comment gérer les mises à jour de vos composants ?
L’un des principaux rôles de k8s consiste à planifier l’ajout/suppression des pods sur les différents noeuds qui composent la grappe kubernetes.
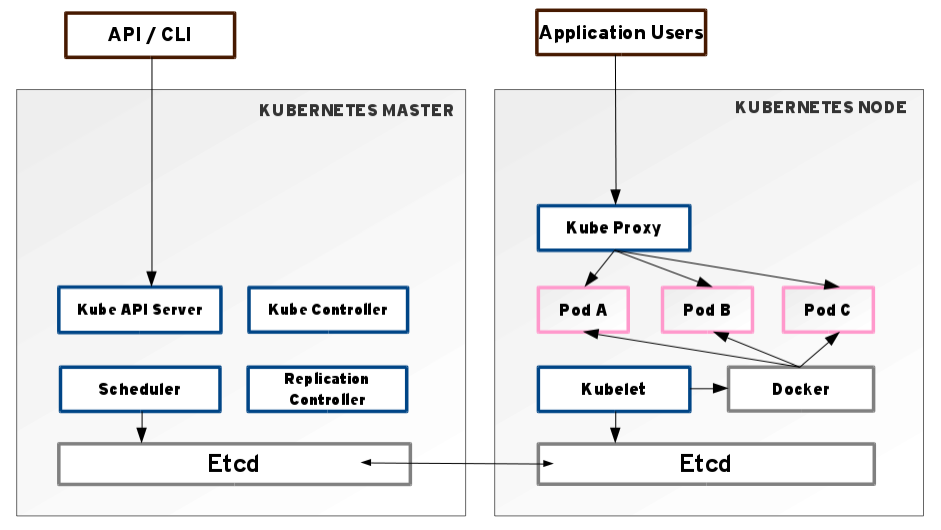
Aperçu de l’architecture technologique
À l’instar de bon nombre de technologies de l’univers des données massives (en anglais Big Data), K8s repose sur le concept d’infrastructure distribuée basée sur deux entités :
- Un serveur maître (master). Généralement redondé deux fois pour garantir un service haute disponibilité.
- “n” serveur(s) nœud(s) (node(s)). Il est possible de spécialiser tout ou partie d’entre eux : calcul intensif, cartes vidéos, disque dur à mémoire, etc.
D’un point de vue macroscopique, les deux composants clés de la technologie K8s sont :
- Etcd : D’après Wikipédia, “Unité de stockage distribuée persistante et légère de données clé-valeur développée par CoreOS, qui permet de stocker de manière fiable les données de configuration du cluster, représentant l’état du cluster à n’importe quel instant.”. Attention, celui du serveur maître est le principal point de défaillance (Single Point Of Failure ou SPOF) de l’ensemble de la grappe Kubernetes.
- Kubelet : Toujours d’après Wikipédia, “Responsable de l’état d’exécution de chaque nœud (c’est-à-dire, d’assurer que tous les conteneurs sur un nœud sont en bonne santé). Il prend en charge le démarrage, l’arrêt et la maintenance des conteneurs d’applications (organisés en pods) dirigés par le plan de contrôle.”
Fonctionnalités K8s avancées
Après avoir défini ce qu’était un orchestrateur de conteneur et donné un aperçu de l’architecture technologique, explorons un panel de fonctionnalités avancées en mesure de répondre aux problématiques d’orchestration induites par l’architecture distribuée de k8s. Un sujet majeur consiste à optimiser la planification des pods sur les noeuds. Dans la pratique, il est intéressant de spécialiser un certain nombre de noeuds. Par exemple, s’assurer que les applications disposent de ressources spécifiques (i.e. disque dur SSD, carte graphique, TPUs, etc.). Autre cas d’usage, la sécurité : pour des questions de confidentialité, il peut être intéressant de configurer directement les droits d’accès aux bases de données sensibles sur un nombre limité de noeud de la grappe.
K8s offre la possibilité de contraindre un pod à ne pouvoir s’exécuter que sur des noeuds en particuliers ou à préférer s’exécuter sur des noeuds en particuliers. Trois options sont possibles :
- La sélection des noeuds (nodeSelector)
- L’affinité des pods à un noeud (nodes Affinity)
- Les teintes et les tolérances (taints and tolerations)
Chacune d’entre elles se base sur des sélecteurs d’étiquettes (tags) pour effectuer la sélection. En règle générale, ces contraintes sont inutiles, car le planificateur effectue automatiquement un placement raisonnable (par exemple, répartir les pods sur l’ensemble des nœuds ou ne pas placer un pod sur un nœud avec des ressources libres insuffisantes, etc.) mais dans des circonstances bien précises il est important de contrôler finement le mécanisme de planification. Par exemple s’assurer qu’un pod se retrouve sur un noeud avec un SSD qui lui est attaché ou pour co-localiser des pods de deux services différents qui communiquent beaucoup dans la même zone de disponibilité.
Affinité des pods à un nœud
L’affinité des nœuds est conceptuellement similaire à nodeSelector, elle permet de contraindre les nœuds sur lesquels un pod peut être programmé, en fonction des étiquettes du nœud.
Les teintes et les tolérances
Le concept de teinte est l’inverse du concept d’affinité des nœuds : il permet à un nœud de repousser un ensemble de pod. Par exemple, s’assurer qu’une liste de noeud n’héberge aucun pods avec la dernière version des applications (i.e. étiquette latest).
Les teintes et les tolérances fonctionnent ensemble pour garantir aux pods de ne pas être planifiés sur des nœuds inappropriés. Une ou plusieurs teintes sont appliquées à un nœud. Cela indique que ce dernier ne doit accepter aucun pod qui ne tolère pas les contraintes. Les tolérances sont appliquées aux pods et permettent (mais n’exigent pas) aux pods de programmer sur des nœuds avec des teintes correspondantes.
Les diapositives 27 à 79 de la présentation https://www.slideshare.net/CoreOS_Slides/kubernetes-15-and-beyond illustrent visuellement ce principe complexe à appréhender (en anglais).
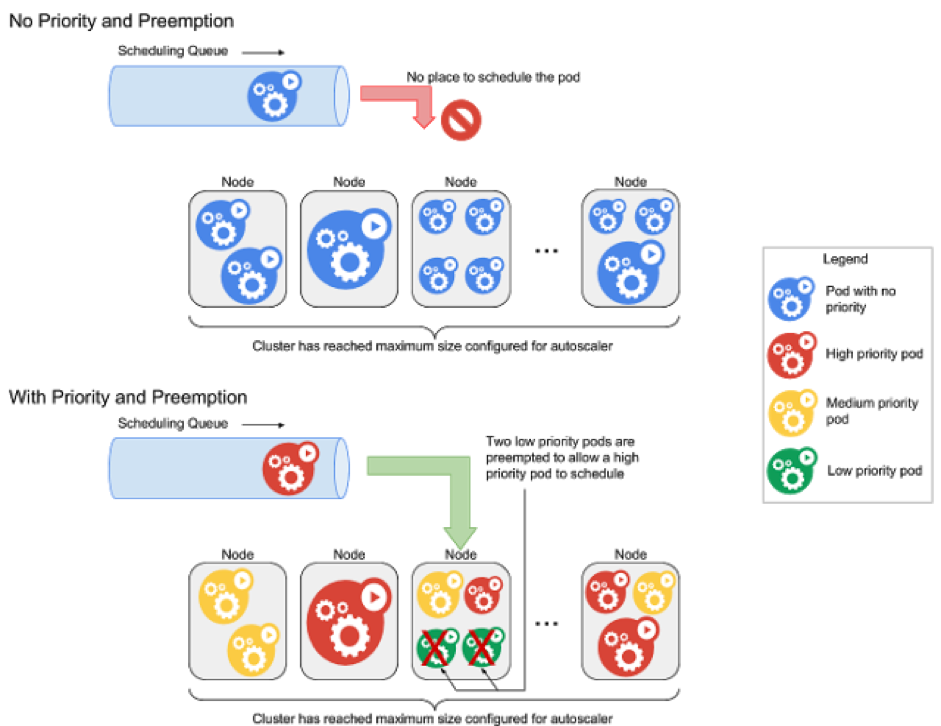
Priorité et préemption (en anglais priority and preemption)
Les pods peuvent contenir une notion de priorité. Cette dernière indique l’importance d’un pod par rapport aux autres. Si un pod ne peut être planifié, le planificateur essaie de préempter (expulser) les pods de priorité inférieure pour permettre la planification du pod en attente. Cette fonctionnalité garantie l’exécution de processus critique sans surdimensionner la grappe k8s. Ceci est particulièrement intéressant lorsque la grappe k8s traite majoritairement des lourdes et longues tâches. Attention, les applications planifiées sur des pods susceptibles d’être expulsés doivent le prendre en compte au niveau applicatif : traitement idempotentes. Les tâches peuvent êtres arrêtées brutalement et re-exécutées sans intervention sans créer de dysfonctionnement.
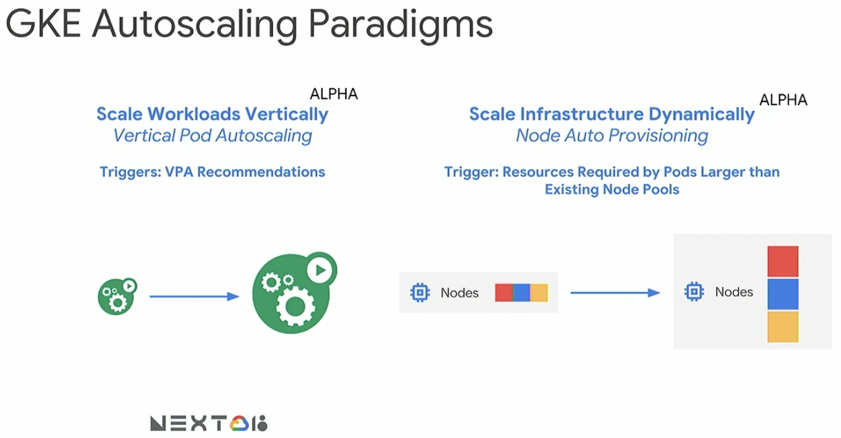
Scalabilité verticale
La scalabilité horizontale fait partie intégrante de principe de Kubernetes (i.e. replicat controller). En revanche, cette dernière ne permet pas de résoudre tous les problèmes de gestion dynamique des ressources. Par exemple, dans le cadre de la data science, l’utilisation d’un notebook Jupyter requiert une scalabilité verticale sans perte d’état (i.e. dynamique) pour optimiser les ressources (i.e : lors du traitement d’importants volumes de données, un surplus de mémoire est alloué).
K8s développe deux types de scalabilité verticale :
- Au niveau d’un pod
- Au niveau d’un nœud
Pour le moment, l’augmentation de la puissance des pods n’est pas dynamique. Ce dernier est stoppé, redimensionné, puis redémarré.
Environnement d’exécution
Un des fondements de K8s est d’abstraire les problématiques physiques liées aux applications par l’exposition d’une unique interface de programmation applicative (Application Programming Interface ou API).
Kubernetes est un produit largement démocratisé, celui-ci est disponible sur de nombreuses plateformes.
Infrastructure sur site
La solution de prédilection pour mettre en place une grappe K8s sur un seul nœud est d’installer Minikube. Celui-ci est idéal pour le développement local d’applications sous K8s. Un grand nombre de ressources est présent : installation logicielle, configuration et supervision de la grappe, etc.
Infogéré dans les nuages
Les trois principaux fournisseurs de service d’informatique dans les nuages proposent nativement, à l’état de disponibilité générale (General Availability ou GA) un service totalement infogéré de la solution Kubernetes.
Chez Google, ce service s’appelle Google Container Engine (GKE), chez Microsoft Azure, il s’agit d’Azure Container Service (AKE) enfin chez Amazon EKS pour Elastic Container Service.
Le tableau ci-dessous énumère les principales différences entre ces fournisseurs :
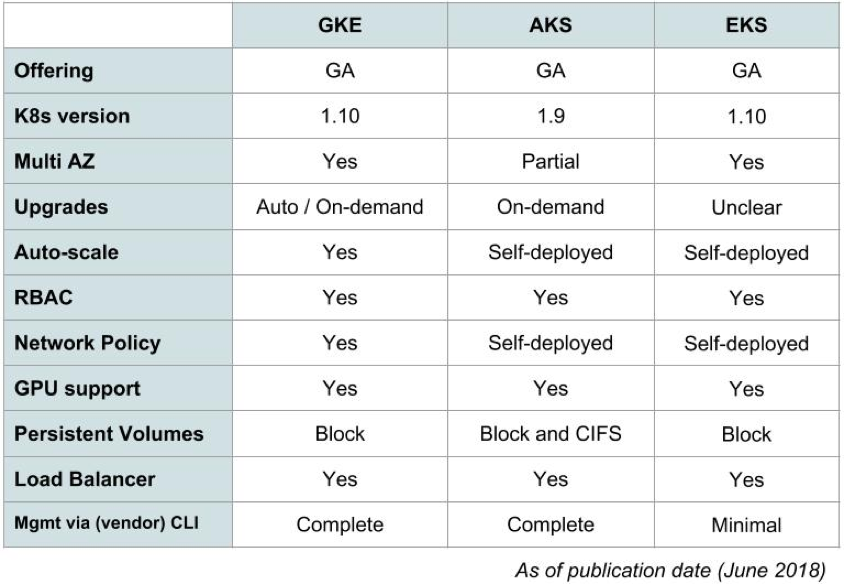
La plateforme de Google est la seule à permettre l’utilisation des TPUs nativement sur K8S.
L’intérêt d’utiliser un service infogéré, réside dans la prise en charge native de la haute disponibilité. Par exemple, chez Google, la partie ectd n’est pas accessible, celle-ci est exclusivement administrée par ce dernier. Dans la même veine, en quelques cliques, la grappe K8s est déployée sur plusieurs zones géographiques et/ou régions.
Sur site
L’installation et configuration d’une grappe K8s ex nihilo offre le contrôle totale.
Google propose la solution GKE On-Prem, un moyen fiable, efficace et sécurisé d’exécuter des grappes Kubernetes sur votre propre infrastructure. Une expérience d’installation et de mise à niveau rapide et simple, validée et testée par Google.
Outils d’administration
L’outil d’administration en ligne de commande (Commande Line Interface ou CLI) livré nativement avec K8s est kubectl.
Lors du déploiement d’une grappe Kubernetes dans un environnement de production, les installations automatisées/scriptées permettent une flexibilité et une personnalisation supplémentaires. Pour faciliter le processus de déploiement, vous pouvez profiter de l’un de ces outils :
- Kops
- Kubeadm
- Kubespray
- Kubo
Les quatre technologies ci-dessus s’adressent plutôt à des utilisateurs avec de solides compétences dans l’administration de système.
La deux technologies ci-dessous, à la philosophie relativement proche, s’adressent plus à des profils “développeurs” :
- Ksonnet
- Helm
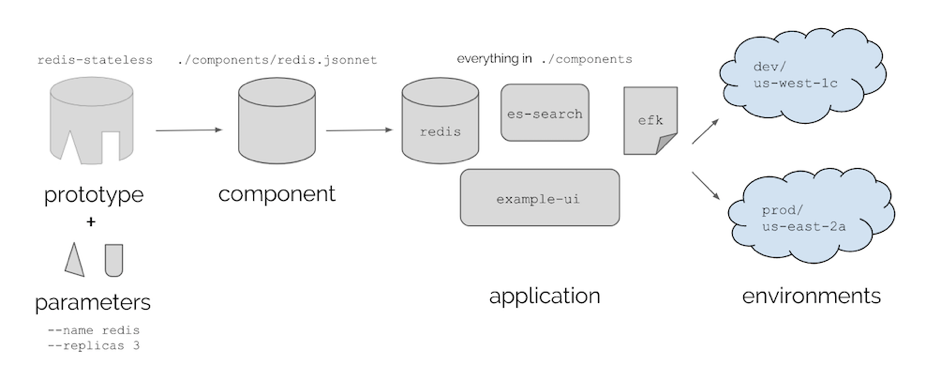
Ksonnet aide à reproduire les déploiements complexes de Kubernetes grâce au code en adoptant une approche réutilisable, composable et extensible. Il s’agit d’une bibliothèque Jsonnet qui génère des fichiers de configuration Kubernetes au format YAML. La philosophie consiste en la personnalisation des composants souhaités parmi un ensemble de modèles (i.e. bibliothèque de prototypes génériques).
Ce principe est résumé par le schéma ci-dessous :
De son côté, Helm est la technologie sélectionnée par la CNCF pour les problématiques liées à la gestion des packages (package management). Lors de la rédaction de l’article, Helm est au niveau incubation. Contrairement à Ksonnet qui est orienté “développeur”, Helm est inspiré de la philosophie Dockerhub : un magasin applications. Celui-ci permettant de déployer sur notre cluster des applications potentiellement complexes et/ou multi-tiers de manière automatique en une ligne de commande. On peut le voir comme une version industrialisée du docker-compose.
Helm est axé autour de trois notions :
- Charts : Collection de fichiers YAML variabilisés décrivant des ressources qui, misent bout à bout, donnent une application déployable sur Kubernetes.
- Helm : Client permettant de récupérer des Charts et de les appliquer sur un cluster Kubernetes.
- Tiller : Partie serveur permettant à un client Helm donner des ordres au cluster Kubernetes visé.
Extensions
Divers projets se couplent particulièrement bien avec K8s. Ci-dessous, une sélection de projets qui méritent l’attention.
La vidéo https://www.youtube.com/watch?v=kKC-VgAptII publiée à l’occasion du Google Next 2018, met en avant l’implémentation des solutions Istio et Spinnaker pour gérer un SI dans les nuages multi-fournisseur.
Intégration aux principaux outils CI/CD
GitLab offre une bonne interconnexion avec Kubernetes, via la définition d’un manifest YAML, celui-ci est en mesure d’actualiser l’ensemble de la couche applicative suite à la réception d’un événement (i.e. publication de nouvelles modifications de code).
À l’instar de GitLab, Travis CI offre également une intégration de K8s similaire, à savoir, le déclenchement de la chaîne de déploiement sur réception d’événements.
Spinnaker
Spinnaker une plate-forme de diffusion continue à code source ouvert développée par Netflix pour gérer les opérations de CD à grande échelle sur son réseau d’informatique dans les nuages. Avant d’aller plus loin, deux mots sur les concepts de CI/CD :
- Le CI est un mécanisme permettant de fusionner et de tester des modifications de code de manière continue, notamment grâce à un outil tel que Jenkins.
- Le CD est une méthode de développement de logiciels DevOps avec laquelle les changements de code sont automatiquement générés, testés et préparés pour une publication dans un environnement de production. Cette pratique étend le principe de l’intégration continue en déployant tous les changements de code dans un environnement de test et/ou un environnement de production après un processus de validation automatisé.
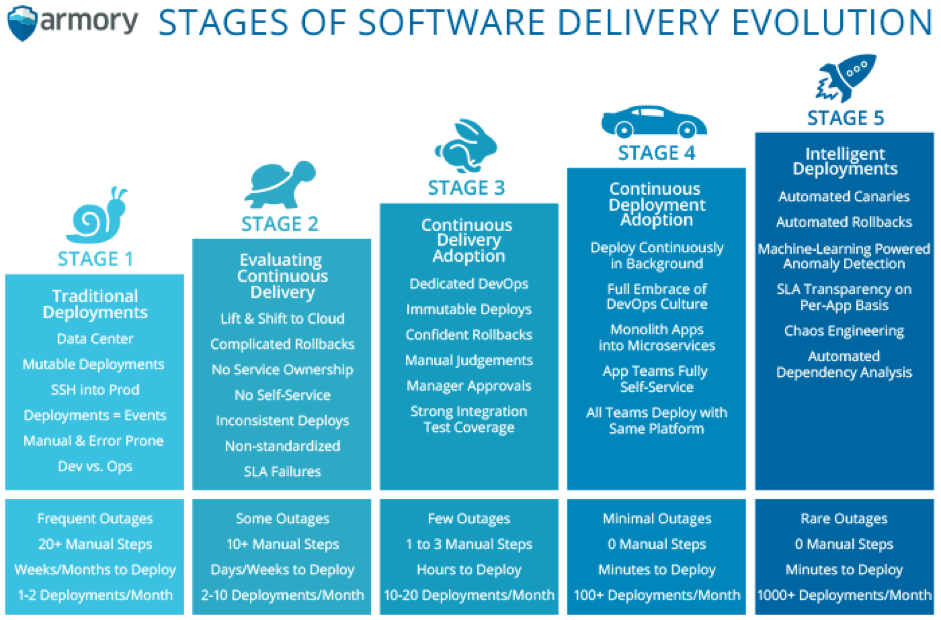
L’illustration ci-dessous montre les différents niveaux de maturité des solutions de déploiement d’applications :
Spinnaker est un outil de gestion de pipelines natif dans les nuages qui prend en charge les intégrations dans tous les principaux fournisseurs, à savoir Amazon Web Services (AWS), Azure, GCP et OpenStack. Il prend en charge nativement les déploiements Kubernetes.
Spinnaker est différent de la plupart des autres outils CI. Les technologies CI construisent du code et exécutent des tests sur ce dernier. Les technologies de CD se concentrent davantage sur l’affichage de l’état actuel de l’environnement. CD permet à la livraison de logiciels de progresser encore davantage en testant automatiquement le logiciel et en le mettant en production à l’aide de techniques telles que le test canari et le test bleu-vert.
Spinnaker ne remplace pas les outils CI. Il fonctionne parallèlement au bourreau de travail éprouvé de Jenkins : un travail Jenkins peut toujours gérer la création et le stockage d’artefacts pour la partie CI et, une fois terminé, le travail peut déclencher une chaîne de traitements (en anglais pipeline) Spinnaker qui déploie l’application sur Kubernetes la partie CD.
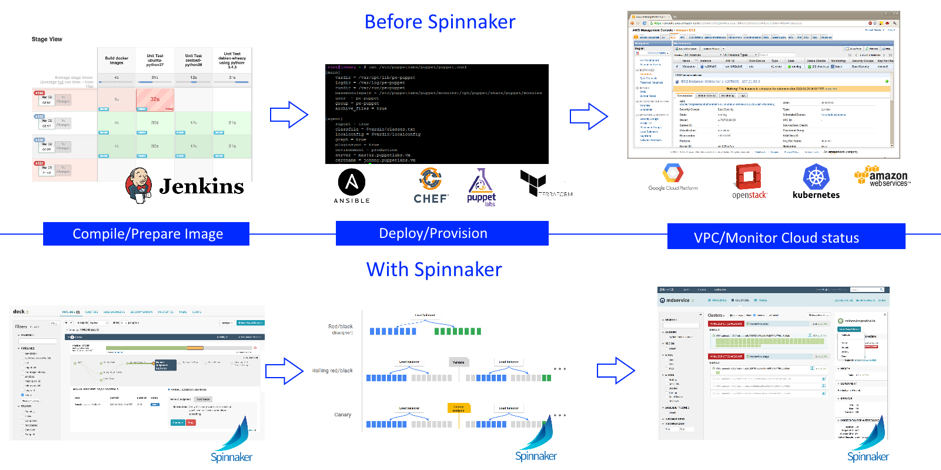
Une bonne livraison continue permet aux développeurs de toujours disposer d’un artéfact prêt au déploiement après avoir suivi un processus de test normalisé. Ci-dessous, la comparaison du déploiement d’application avec et sans Spinnaker :
Le document https://www.cncf.io/free-ebook-ci-cd-with-kubernetes/ (en anglais) publié en juin 2018 par TheNewStack dédie un chapitre très détaillé sur les concepts de Spinnaker, ses points forts et fournit un exemple d’implémentation au sein de l’organisation.
Istio
Les plateformes d’informatique dans les nuages offrent de nombreux avantages aux organisations qui les utilisent. Il est indéniable que l’adoption de l’informatique dans les nuages peut mettre à rude épreuve les équipes DevOps. Les développeurs doivent utiliser des microservices pour concevoir la portabilité, tandis que les administrateurs systèmes gèrent des déploiements hybrides et multi-fournisseurs de solutions dans les nuages extrêmement volumineux. Istio vous permet de connecter, sécuriser, contrôler et observer des services.
À un niveau élevé, Istio aide à réduire la complexité de ces déploiements et facilite la tâche de vos équipes de développement. Il s’agit d’un service entièrement code ouvert qui se superpose de manière transparente aux applications distribuées existantes. Il s’agit également d’une plateforme, comprenant des APIs qui permettent son intégration dans toute plateforme de journalisation, système de télémétrie ou de stratégie. Les différentes fonctionnalités d’Istio vous permettent d’exécuter avec succès et efficacement une architecture de microservices distribuée et fournissent un moyen uniforme de sécuriser, de connecter et de surveiller les microservices.
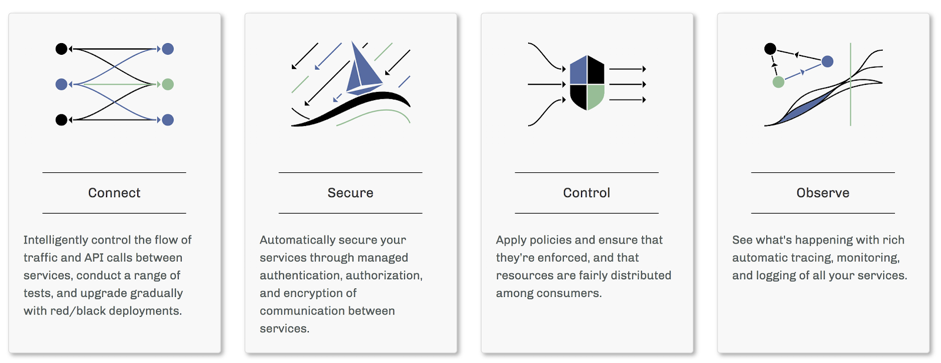
La vidéo https://www.youtube.com/watch?v=gauOI0O9fRM publié à l’occasion du Google Next 2018, décrit l’utilisation d’Istio avec GKE.
Architecture sans serveur/Fonctions en tant que Service
Étroitement liée à l’évolution de l’architecture des SI ces dernières années, l’architecture sans serveur révolutionne la consommation des services d’informatique dans les nuages. Le schéma ci-dessous, retrace les grandes évolutions technologique des SI au cours de ces trente dernières années :
Ce type d’architecture est plébiscité par les principaux fournisseurs de solutions d’informatique dans les nuages. A date, l’implémentation de l’architecture sans serveur est propre à chaque fournisseur. Le code n’est pas portable facilement entre les différentes plateformes : le risque est, à terme, l’enfermement propriétaire. K8s permet de résoudre deux principaux problèmes :
- Migrer facilement d’une architecture existante vers l’architecture sans serveur sans augmenter les coûts de fonctionnement : c’est la grappe de l’architecture existante qui porte les nouveaux usages.
- Construire un SI agnostique au fournisseur d’informatique dans les nuages.
À date, il existe plusieurs projets (les deux premiers sont optimisés pour K8s) :
- Knative : https://cloud.google.com/knative/
- Kubeless : https://kubeless.io/
- Apache OpenWhisk : https://openwhisk.apache.org/
- OpenFaaS : https://docs.openfaas.com/
Cas d’usages
Apprentissage machine
Une des grandes annonces de KubeCon + CloudNativeCon 2017 début décembre 2017 concernait Kubeflow : un projet à source ouvert dédié à rendre l’apprentissage machine sur Kubernetes facile, portable et évolutif. Kubeflow s’adresse aux utilisateurs qui souhaitent des plateformes portables, plus de contrôle, simplifier les composantes technologies d’apprentissage machine ou déployer via Kubernetes sur différentes plates-formes, sur site, etc.
Par exemple, une vision pour Kubeflow serait d’avoir différentes équipes (Data Scientists, Devs, IT, etc.) partageant ou distribuant des systèmes sans se soucier de savoir qui pourrait encore avoir à gérer l’infrastructure sous-jacente.
Kubeflow vise à tirer parti de la capacité de Kubernetes à déployer sur diverses infrastructures, à déployer et à gérer des microservices faiblement couplés et à évoluer en fonction de la demande.
Il est possible d’utiliser Kubeflow sur différentes plateformes :
- Localement avec Minikube.
- Dans les nuages de Googles via GKE.
- Sur une grappe K8s générique. ou via Ksonnet.
Les deux vidéos suivantes sont une bonne introduction à l’utilisation de Kubeflow :
- https://www.youtube.com/watch?v=K347ekvIJJg
- https://www.youtube.com/watch?v=K347ekvIJJg : Pourquoi utiliser Kubeflow pour l’apprentissage machine (minute 4:27).
Pachyderm est une autre solution libre dédiée à la science des données industrialisée d’apprentissage machine qui passe à l’échelle. Cette technologie permet de déployer et de gérer des chaînes de traitements de données multicouche et indépendantes des langages de programmation utilisés tout en conservant une reproductibilité et une provenance complète.
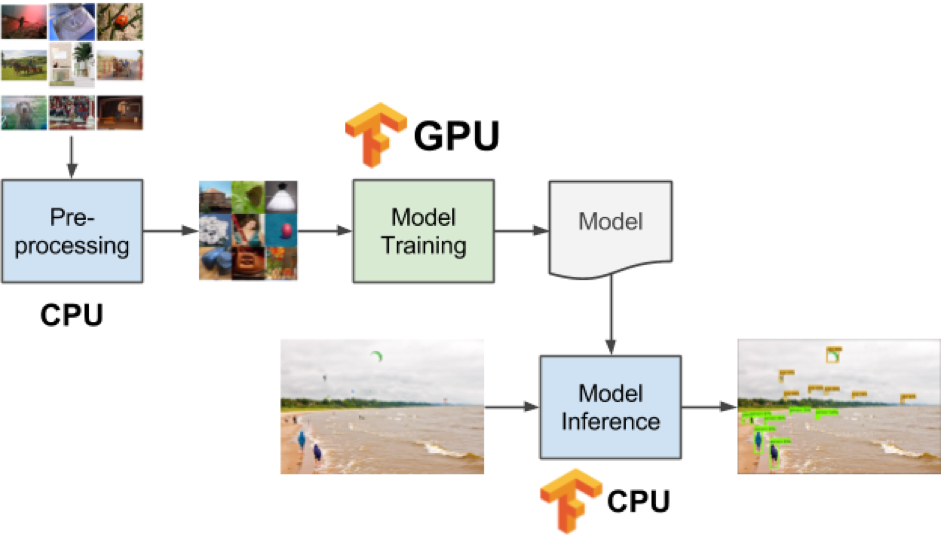
Exemple du cycle de vie d’apprentissage machine type :
Ci-dessous, un exemple d’architecture d’apprentissage machine avec K8s et Pachyderm :
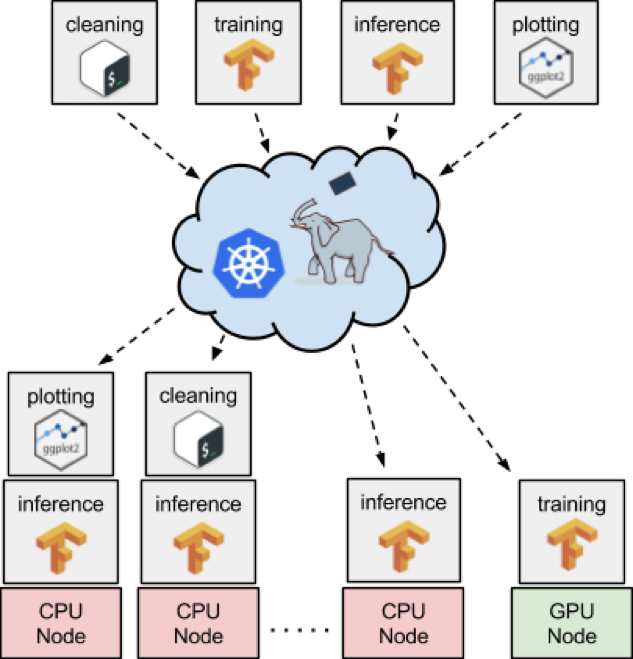
Les avantages dans l’utilisation de K8s dans l’apprentissage machine sont :
- Simplification de la chaîne de traitement : focus sur l’aspect à forte valeur ajoutée, à savoir, la logique applicative et algorithmique.
- Optimisation des ressources : les traitements s’exécutent sur des nœuds spécialisés (i.e. carte graphique, TPUs, …).
Optimisation des stratégies de déploiements
Il existe une variété de techniques pour déployer de nouvelles applications en production. Le choix de la bonne stratégie est donc une décision importante, qui évalue les options en termes d’impact du changement sur le système et sur les utilisateurs finaux.
Les principales stratégies sont les suivantes :
- Recréer (en anglais recreate) : la version A est terminée, puis la version B est déployée.
- Montée en puissance (en anglais, ramped ; également appelé mise à jour évolutive ou incrémentielle) : la version B est lentement déployée et remplace la version A.
- Bleu/Vert (en anglais Blue/Green) : la version B est publiée avec la version A, puis le trafic passe à la version B.
- Canary : la version B est publiée sur un sous-ensemble d’utilisateurs, puis procède à un déploiement complet.
- Test A/B (en anglais A/B testing) : la version B est publiée sur un sous-ensemble d’utilisateurs dans des conditions spécifiques.
- Masquée (en anglais shadow) : La version B reçoit du trafic réel avec la version A et n’affecte pas la réponse.
Les avantages et inconvénients des différentes stratégies sont illustrés dans le tableau ci-dessous :
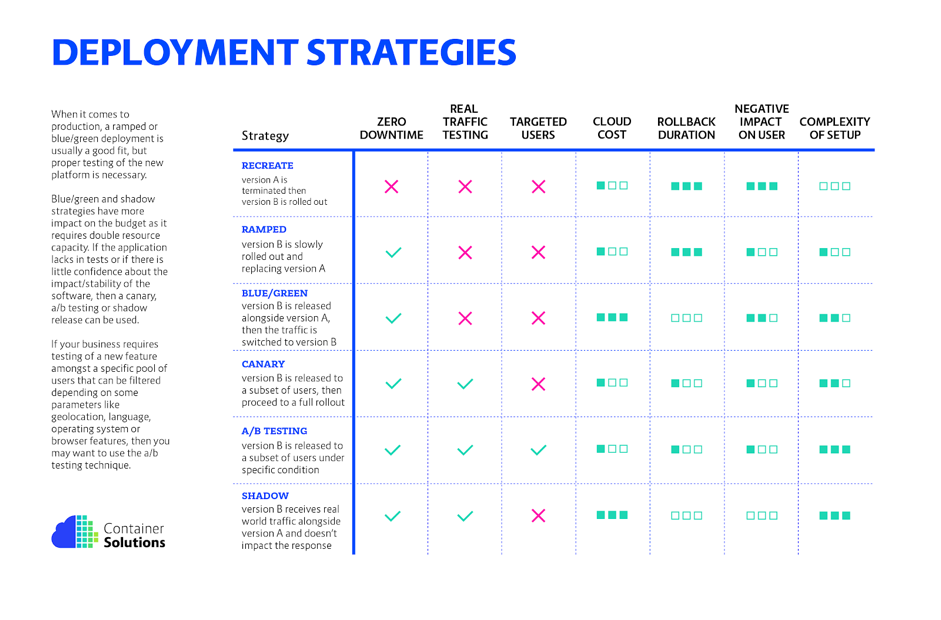
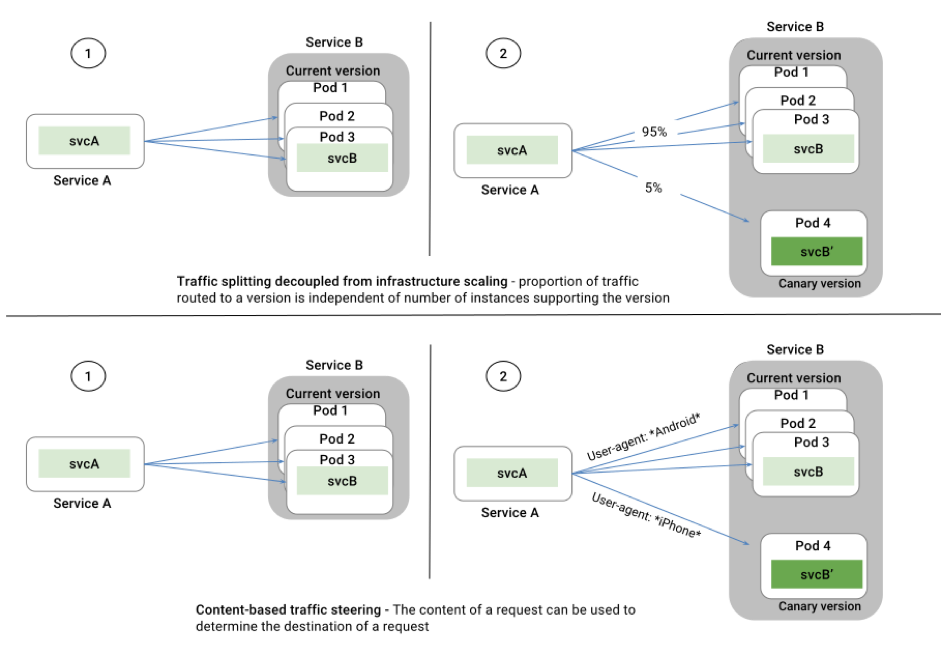
L’utilisation de K8s couplé à istio modélise les stratégies de déploiement sous forme de règles. Par exemple, dans le cas d’un test A/B, il est possible d’exposer une application (inclut une version spécifique) à un type de trafic spécifique (i.e. les utilisateurs sur iPhone X). Les schémas ci-dessous illustrent le présent exemple :
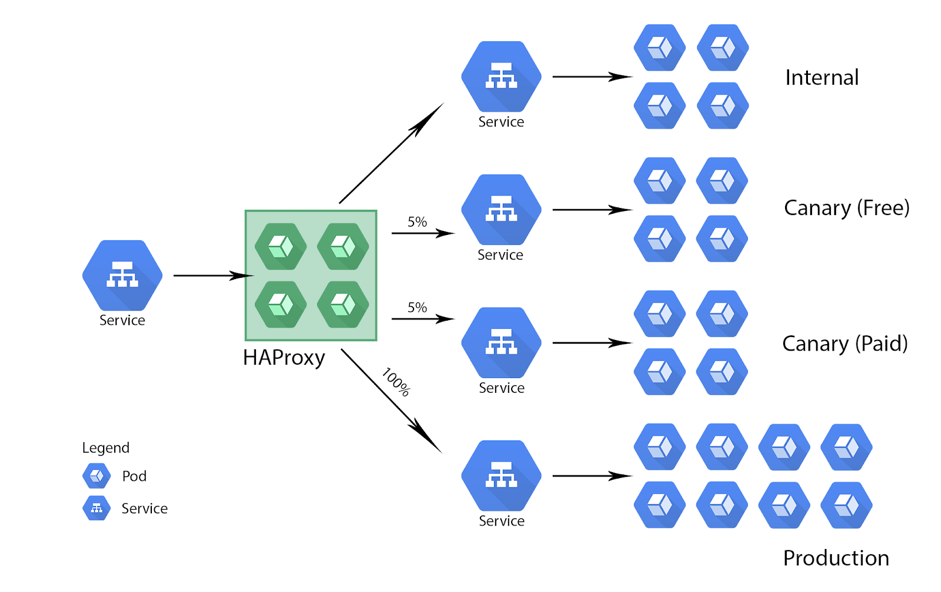
Autre cas d’usage, l’automatisation du déploiement d’applications avec la stratégie canary. Ci-dessous, un exemple d’architecture :
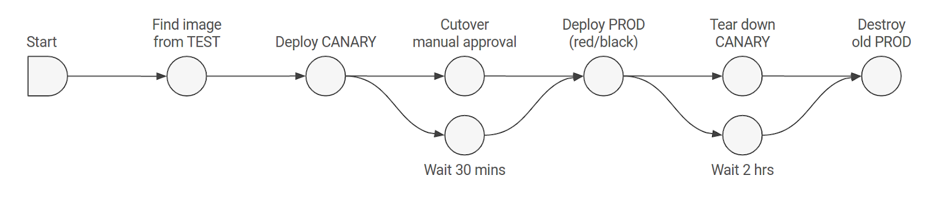
Avec Kubernetes et Spinnaker, le trafic envoyé sur les applications à tester est facilement automatisable. Ci-dessous, un exemple de cycle de vie de déploiement automatique :
La caractéristique même des conteneurs, à savoir, une instanciation et démarrage ultra rapide des applications offre une très bonne réactivité lors des changements de versions. Ceci inclut les cas de reprise sur pannes et gestion de la scalabilité.
Formation
Les principales plateformes de cours massivement en ligne (en anglais
Massive Open Online Course, plus connus sous l’acronyme MOOC) dispensent des formations sur K8s, ci-dessous, quelques exemples (en anglais) :
- https://www.edx.org/course/introduction-to-kubernetes (édité par la fondation Linux)
- https://www.coursera.org/learn/google-kubernetes-engine (spécifique au produit GKE de la plateforme GCP)
- https://eu.udacity.com/course/scalable-microservices-with-kubernetes–ud615 (édité par Google)
- https://fr.coursera.org/learn/deploy-micro-kube-icp (édité par IBM)
La fondation Linux propose d’autres formations sur Kubernetes ainsi que des certifications.
Exercices pratiques
À travers le scénario https://www.katacoda.com/kubeflow/scenarios/deploying-kubeflow-with-ksonnet, vous apprendrez à déployer différentes charges de travail d’apprentissage machine à l’aide de Kubeflow et de Kubernetes. L’environnement interactif est une grappe Kubernetes à deux nœuds qui vous permet de faire l’expérience de Kubeflow et de déployer de véritables charges de travail pour comprendre comment résoudre vos problèmes. Le scénario https://tutorials.ubuntu.com/tutorial/get-started-kubeflow#0 est une alternative éditée par Ubuntu.
Pour aller plus loin, l’exercice https://codelabs.developers.google.com/codelabs/cloud-gke-workshop-v2/index.html?index=..%2F..%2Fio2018#0 disponible sur la plateforme codelab présente certaines des fonctionnalités avancées de Google Kubernetes Engine et explique comment exécuter un service qui tire le meilleur parti des fonctionnalités de Google Cloud Platform. Cela suppose de posséder une connaissance de base des conteneurs Docker et des concepts Kubernetes.
Merci pour votre lecture et à bientôt pour un prochain article !
