

Uncategorized
03/07/2018
Les freins à l’industrialisation des projets de Data Science – Récit d’un petit déjeuner
Temps de lecture : 6 minutes

Que ce soit dans le domaine de la santé, de la lutte anti-fraude, de la maintenance prédictive de la supply chain, etc., le passage d’un projet de Data Science depuis la phase exploratoire de Proof Of Concept (POC) à la phase de Pilote voire d’Industrialisation est généralement complexe sous divers aspects : budgétaire, organisationnel, technique, etc.
Cette difficulté a été déjà abordée dans notre livre blanc Y a t-il une vie après les POCs ?, disponible gratuitement en téléchargement.
Cette difficulté elle est là, elle existe…
Quels sont ces freins à l’industrialisation des POC ? Et surtout : Quelles solutions existent ?
C’est pour répondre à ces questions que Quantmetry et Saagie ont organisé conjointement un petit déjeuner – networking le 21 juin, dans les nouveaux locaux de Quantmetry.
Une déco branchée, un public de qualité trié sur le volet, des échanges riches et des croissants pour un moment d’échange et de convivialité. Pour les malheureux qui n’ont pas pu assister à l’évènement, voici les grandes lignes de ce qui a été présenté.
Partons d’un constat
Dans la salle, ce sont majoritairement les liens entre le Data Lab / Data Fab / Data Factory et le service IT de l’entreprise qui a été pointé du doigt : Comment les modèles de Data Science, développés au fil de l’eau lors de POCs avec des technologies spécifiques (Python / R pour ne citer que les langages de programmation les plus communs en Data Science) peuvent s’intégrer dans les process IT en validant robustesse, sécurité et même au-delà : SLA, etc.
Et hors de la salle, dans le monde de la Data Science dans sa globalité, voici ce que nous apprend le site Kaggle dans son rapport 2017 sur « l’état de la Data Science et du Machine Learning » :
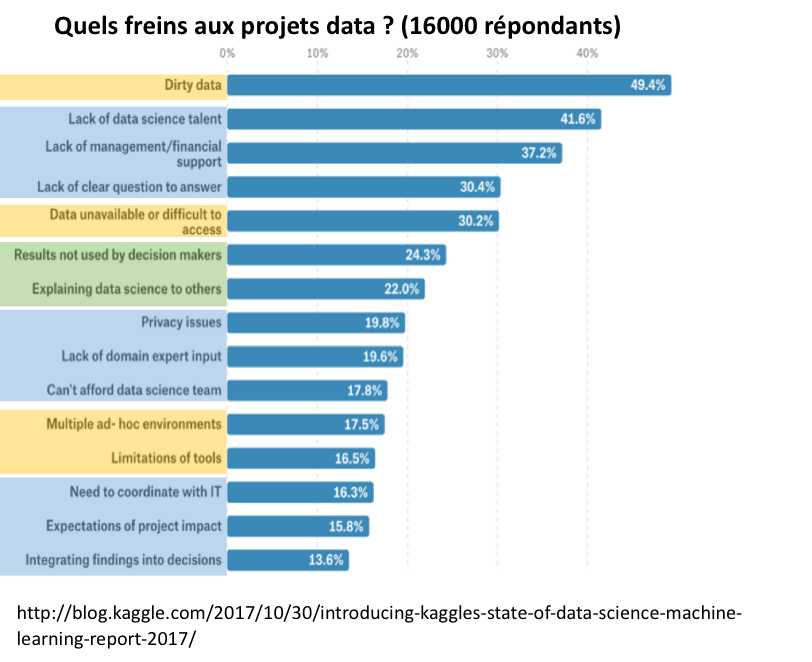
Ces freins nous pouvons donc les classer en 3 catégories :
- Freins organisationnels et de gestions de projet Data ;
- Freins au niveau de l’interprétabilité ; et
- Freins au niveau du code, de la chaîne de traitement des données et des aspects techniques.
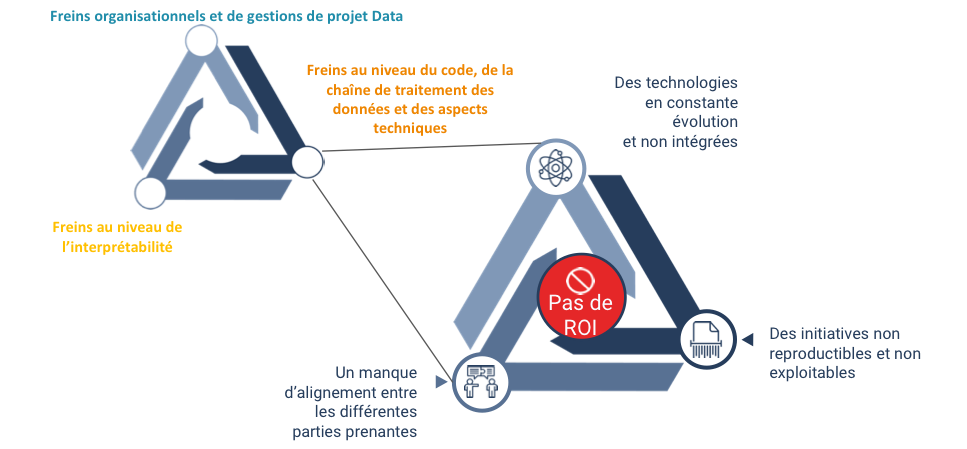
C’est cette dernière catégorie, « les freins au niveau du code, de la chaîne de traitement des données et des aspects techniques », qui a été la pièce centrale de notre discussion, tant les problématiques à prendre en compte sont nombreuses :
Concrètement : une réflexion autour d’un cas d’usage
Donnons-nous un cas d’usage, un scénario, regardons de quelle manière une équipe de Data Science lambda aurait répondu à la demande du client puis évaluons de quelle manière nous aurions pu dès les premières phases de POC anticiper une mise en pilote.

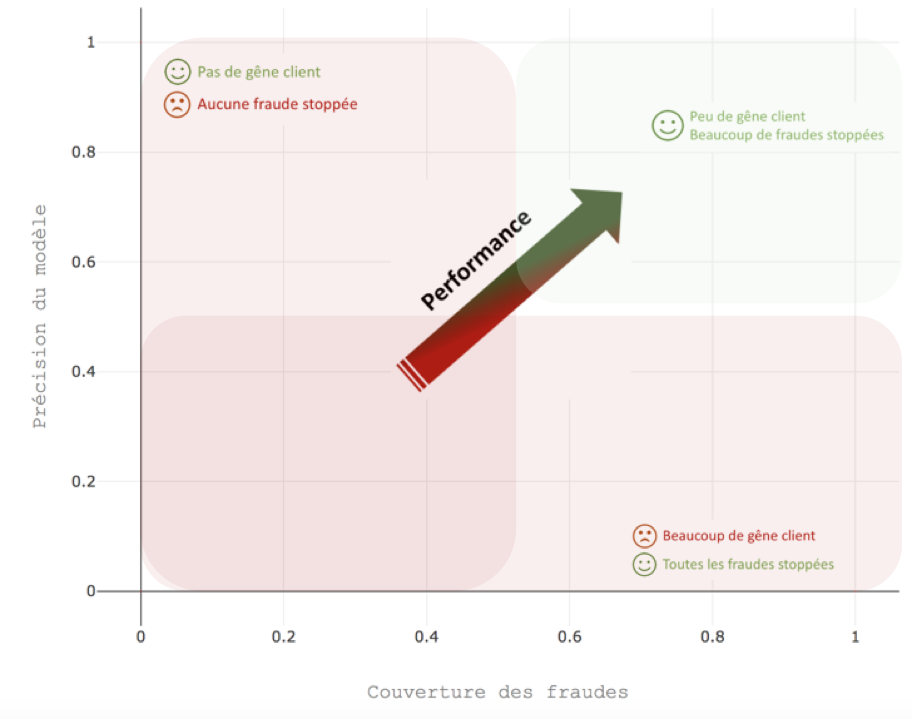
Dans ces conditions, pour un tel cas d’usage, nous avons d’une part :
- L’équipe Data Science qui a besoin de vérifier la faisabilité d’un tel algorithme ;
- Et d’autre part le métier qui nécessite une réponse rapide à sa question, tout en conservant une flexibilité permettant d’investiguer plusieurs pistes
La réponse usuelle dans de telles condition est d’aller vers le fameux Jupyter Notebook.
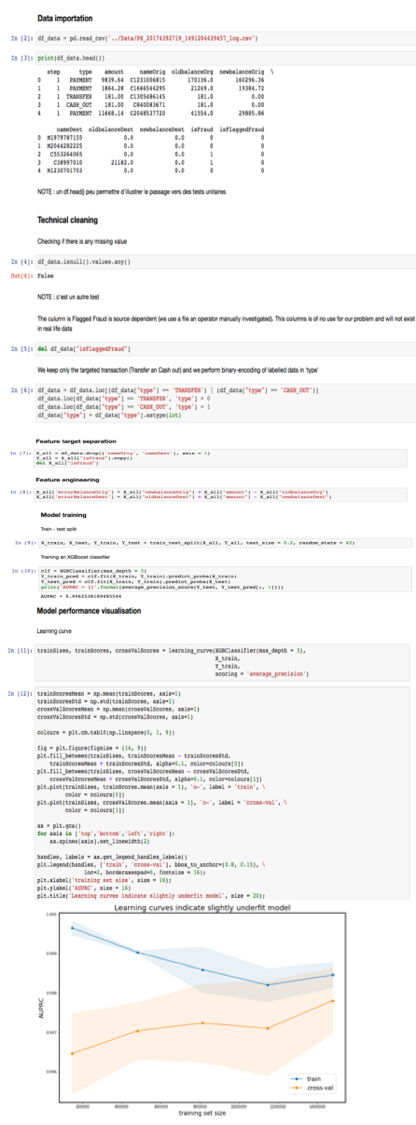
Un script – procédural – parfois non-modulable – intégrant au même niveau intégration des données, préparation, entrainement d’un modèle de machine learning, prédiction et visualisation…
La tentation est grande, mais utiliser ce raccourci à outrance rendra inévitablement plus difficile la mise en pilote.
Que se passera-t-il en fin de de POC ? Nous aurons un métier heureux, qui a eu un résultat à sa question… et dont l’ambition sera maintenant : « Je veux réaliser ce projet en vie courante, en production ».
Donc :
- Les données et le périmètre changent (plus de csv, nous devons nous connecter directement aux bases de données en respectant les contraintes de sécurité) ;
- Le code doit être modulable et robuste (avec tests…) ;
- Les améliorations futures doivent être facilitées ;
- Des travaux d’autres équipes doivent être intégrées à la solution ;
- L’ensemble doit être documenté…
En bref, nous nous retrouvons face aux problématiques habituelles de l’industrialisation
Aurait-on pu l’anticiper au niveau du code ?
Oui nous l’aurions pu. Quantmetry prône l’utilisation de structure de code basée sur le l’approche de développement logiciel Domain Driven Design (DDD). La reference: Evans, E., 2003, Domain Driven Design Tackling Complexity in the Heart of Software. Pub. Addison Wesley (et pour les pressés : http://blog.infosaurus.fr/public/docs/DDDViteFait.pdf ).
Cette approche est particulièrement bien adaptée à la Data Science car elle se base sur la collaboration entre les experts techniques et les experts du domaine métier afin d’affiner de façon itérative un modèle conceptuel.
Le design du code sera conçu en s’appuyant sur une représentation schématique du domaine métier, chaque traitement logique y étant individualisé.
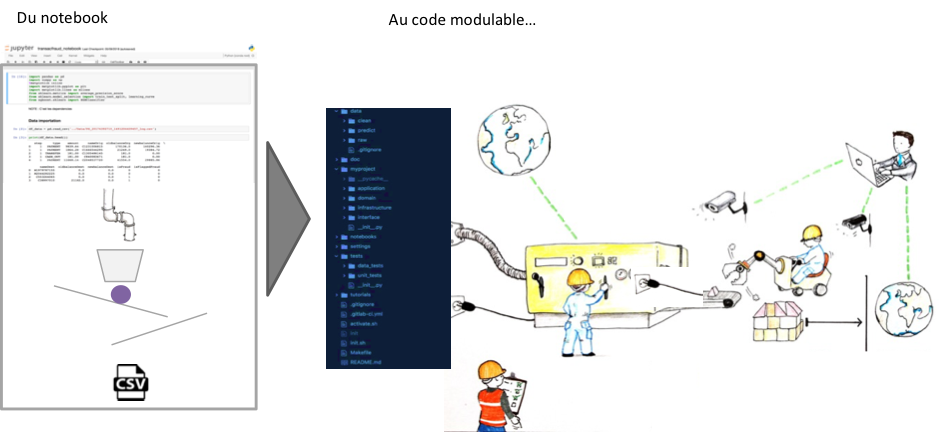
Concrètement il s’agira de sortir du Notebook Jupyter pour mettre en place une structure de code facilitant la modularité par la séparation des taches individualisées.
Nous séparerons ainsi :
- L’ensemble des briques fonctionnelles de connexion aux données dans une couche « infrastructure » ;
- Les traitements spécifiques à la problématique (aux « domaines métiers ») dans une couche « domain » ;
- Les traitements complets / pipeline de traitement dans une couche (« application ») ;
- Les visualisation et l’interface avec le monde extérieur (dont l’interface utilisateur) dans une couche « interface ».
Les règles du jeu : Seules les couches « infrastructure » et « interface » peuvent interagir avec le monde extérieur, chaque couche ne peut appeler qu’uniquement des fonctions et instancier des classes définies dans la même couche ou au niveau de la couche précédente.
On garantit ainsi une modularité de code : si la source change on ne modifie qu’une brique de la couche infrastructure sans impacter les autres briques. De même, si un traitement / une modélisation change, on ne change qu’une brique de la couche demain sans impacter les autres.
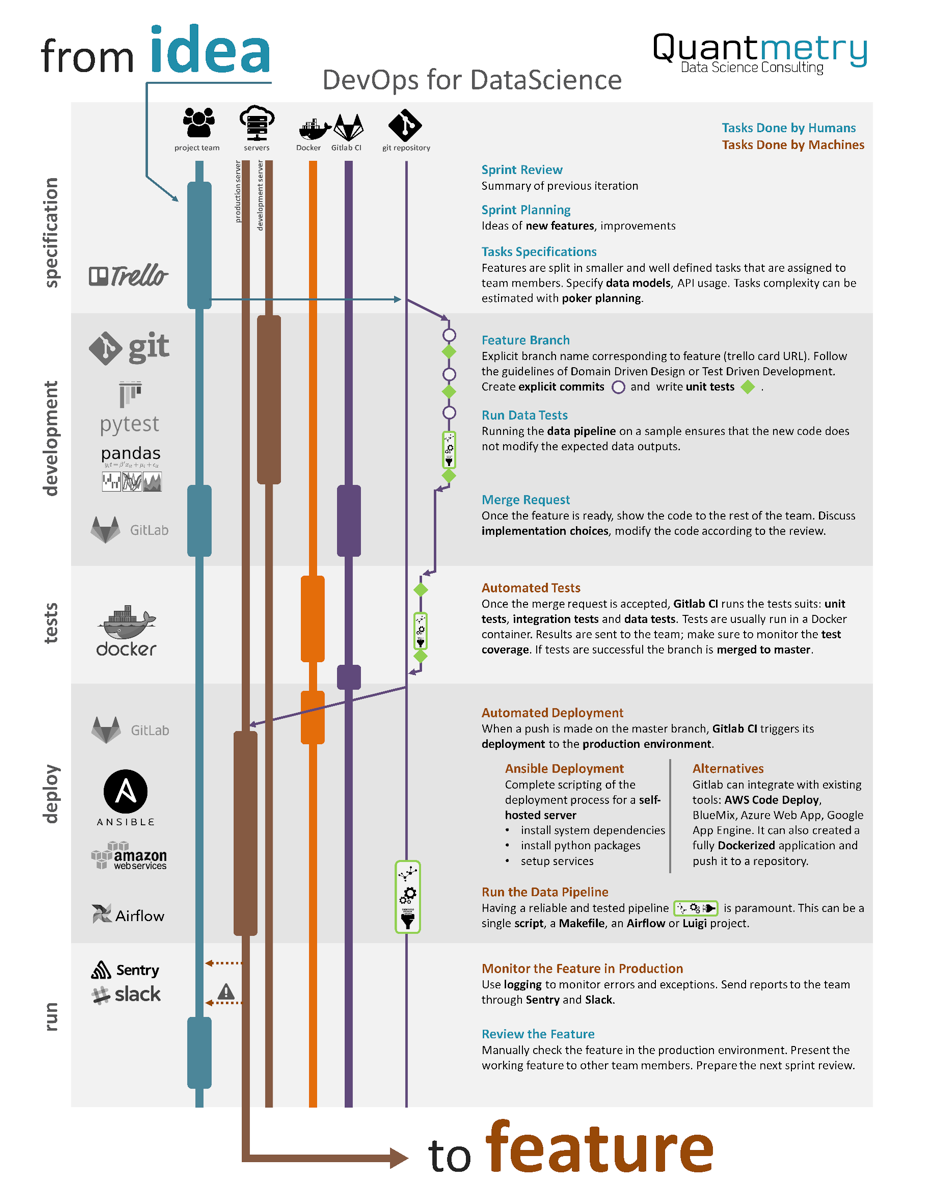
Une telle structure de code facilite la construction de tests, de pipeline de traitement de la données, d’ordonnancement, de déploiement, d’amélioration continu… Ces méthodes de DevOps, nous les maitrisions et comme il vaut mieux un petit schéma qu’un long discours, ci-dessous l’infographie de Benjamin Habert :
Aurait-on pu l’anticiper au niveau de la solution technique ?
Oui, nous l’aurions pu. Et si ce petit déjeuner a été organisé conjointement avec Saagie, c’est bien pour illustrer le fait que des solutions techniques existent pour faciliter le passage en production de codes de Machine Learning.
La Data Fabric, produit phare de Saagie, permet d’ordonnancer et de planifier les traitements découpés en briques fonctionnelles individualisées. Elle permet notamment d’être en capacité de faire évoluer les briques indépendamment les unes des autres, et propose un niveau de paramétrage avancé pour garantir la répétabilité du traitement dans différents contextes.
La plateforme se base sur la technologie HDFS et peut être déployée sur un cloud Saagie, un cloud tiers, ou on-premise sur l’infrastructure client. Cela tout en gérant facilement le portage de la pré-production à la production.
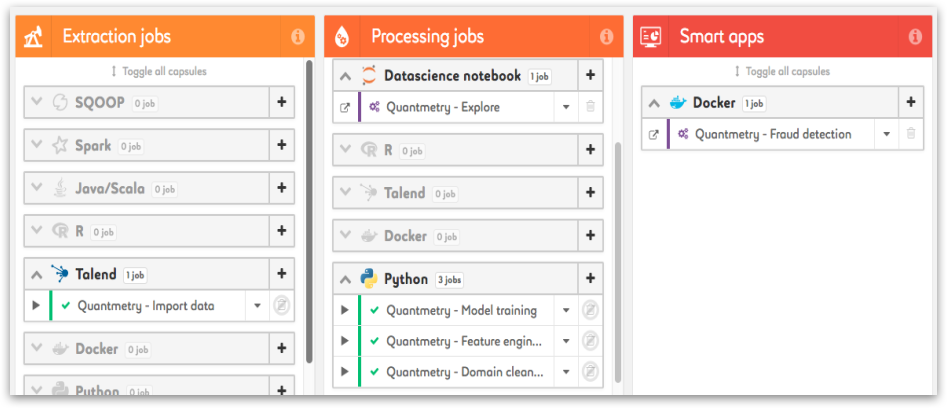

Autre point intéressant : il est tout à fait possible d’intégrer des briques fonctionnelles (des « Jobs ») de langages (python / R / Spark …) et de technos (Talend, Docker…) différents. Ce qui est très utile lorsque dans une organisation, dans une grande entreprise, ces jobs sont produits par des acteurs différents qui utilisent des technologies variées.
Les évolutions futures de la plateforme concerneront l’intégration de modules de Data Gouvernance et de travail collaboratif d’équipes autours de projets dédiés tout en garantissant une gestion fine des niveaux d’accès pour chaque utilisateur.
En résumé…
Industrialiser un POC, requiert du savoir-faire et des outils, c’est pour cela qu’aujourd’hui c’est au-delà des Data Scientists que nous dirigeons notre effort de recrutement chez Quantmetry : vers des Data Engineers et des Data Architects. C’est pour cela aussi que nous cherchons à développer nos relations avec des éditeurs d’outils et de solutions tiers : ETLs, outils de Data Préparation, outils de Data Viz, Solutions Cloud, bases de données, etc.
Ce fut en conclusion un excellent petit déjeuner dans une ambiance conviviale et des discussions très intéressantes, notamment sur un autre frein à l’industrialisation : l’interprétabilité / l’explicabilité / l’intelligibilité des modèles de Machine Learning.
Contrainte majeure d’un point de vue règlementaire et pour garantir un niveau de confiance suffisant du métier dans les prédictions des modèles de Machine Learning, l’interprétabilité est au cœur des travaux de R&D actuels de Quantmetry. Nous développons ainsi nos prestations sur ce thème pour être toujours à la pointe de l’Etat de l’Art et apporter les meilleures réponses aux problématiques de nous clients. Je vous invite à consulter à ce sujet les articles https://www.quantmetry.com/recherche.
✍Écrit par Pierre Boszczuk
