

La gouvernance de la data, cette aventure humaine

✍ Par Gill Morisse / Temps de lecture : 7 minutes.
La gouvernance de la data n’est pas uniquement un défi technologique ! Gérer la donnée, c’est gérer un capital de connaissances et de savoir-faire qui émanent des activités humaines au sein des organisations.
Les acteurs technologiques se multiplient et promettent aux professionnels une totale maîtrise des flots de data au sein de l’entreprise. Les données vont se croiser à grande échelle pour générer une valeur qui bouleversera les équilibres concurrentiels. Les Data management systems permettront de tracer et de coordonner les flux de données et leurs traitements en conformité totale avec les nouveaux règlements européens (GDPR).
Mais, vu des laboratoires de data science, la réalité est bien entendue différente. Une donnée, quelle qu’elle soit, n’a de valeur que si des femmes ou des hommes savent la remettre dans son contexte de production puis de traitement. Elle ne pourra être utilisée pour une application grande échelle que si d’autres personnes prennent la responsabilité d’en surveiller la qualité et de mettre en oeuvre des actions correctives bien au-delà des systèmes informatiques. Et surtout, la donnée repose sur un langage d’entreprise, des référentiels ontologiques qui nécessitent, pour être généralisés, une appropriation par toute l’entreprise d’une culture orientée data, c’est-à-dire affranchie des silos traditionnels (finance, marketing, production..).
Loin d’être un simple fait technologique, la transformation par la data prolonge donc et accentue le rythme de transformation des organisations par le digital. Toutes les strates de la société, de l’ouvrière au top management vont désormais produire de la donnée et porter la responsabilité personnelle et collective de permettre à d’autres qu’eux d’utiliser facilement la donnée qu’ils produisent. Autant dire que les freins organisationnels sont nombreux et que l’outillage technologique est loin d’être la problématique principale.
L’objectif de cet article sera donc double. Je rappellerai quel cadre méthodologique est en jeu pour la gouvernance de la donnée. Mais j’essaierai également de partager notre expérience et nos principales recommandations pour implémenter une gouvernance de manière pragmatique.
LA GOUVERNANCE DE LA DATA, QU’EST-CE QUE C’EST ?
La gouvernance de la data est un chantier au coeur de la transformation digitale des entreprises. Après des années d’expérimentations qui ont démontré l’intérêt des intelligences artificielles, sa mise en oeuvre est une étape obligatoire vers l’industrialisation des solutions data et donc la conversion de promesses en gains.
Pour simplifier, la gouvernance de la data poursuit trois objectifs majeurs :
Objectif #1 Favoriser l’accessibilité et le partage
- Favoriser l’utilisation de la donnée par des utilisateurs en garantissant la diffusion d’une connaissance et d’un savoir partagé (documentation, vision partagée…).
- Permettre le partage effectif de la donnée dans des conditions adaptées aux usages (access management, référentiels, interfaces, architecture…).

Le véhicule connecté, et bientôt autonome, est bardé de capteurs qui remontent des températures, des pressions, des images. Pour exploiter de façon pertinente une donnée de température, il faudra savoir où est situé le capteur (intérieur ou extérieur ? A l’avant ou à l’arrière ?), ce que signifie la valeur (Celsius ou Fahrenheit ? quelle est la valeur maximum ?), dans quelles conditions est-elle collectée (périodiquement ?, sur événement ?), comment interpréter une valeur aberrante (anomalie de conception ? réel défaut ?). Cette connaissance est aujourd’hui dispersée entre l’ingénierie, l’exploitation, l’IT. Comment mutualiser cette connaissance ?
Objectif #2 Gérer la qualité et l’intégrité
- Adopter une définition commune partagée par l’ensemble des services et des règles de gestion qui garantissent un niveau qualitatif suffisant pour l’usage attendu. Tout en sachant prévenir, détecter et corriger des erreurs.
- Maîtriser le cycle de vie de la donnée (data lineage) en identifiant la source, les transformations et l’utilisation.

La compréhension et la fiabilité des données sont des concepts essentiels qui garantissent une bonne utilisation et gestion. Est-ce la même notion pour tout le monde ? Est-elle accessible ? D’où vient-elle ? Comment est-elle transformée ? Quels sont les systèmes ou les processus qui l’utilisent ?
Dans cette compagnie d’assurance et mutuelle, plusieurs départements définissaient le chiffre d’affaires de manière différente. Une des approches proposées était de s’assurer que le chiffre d’affaires désignait la même notion et soit partagée par tous. Pour cela, Quantmetry a accompagné dans l’initialisation et la diffusion des outils organisationnels (règles de gestion, comité organisationnel…)
Objectif #3 Garantir la conformité réglementaire
- Renforcer et maintenir la conformité aux exigences règlementaires et notamment aux règlements européens (GDPR) : référentiel des traitements, durées de conservation, collecte du consentement, traçabilité..
Objectif #4 Confidentialité et sécurité
- Renforcer la sécurité des données personnelles, sensibles ou confidentielles
- Clarifier et partager les process relatifs à la sécurité des données (access management…)
L’atteinte de ces objectifs va s’appuyer sur un déploiement progressif d’un ensemble de ressources et de principes organisationnels. De manière synthétique, on peut distinguer quatre grands leviers qui soulèvent des questions clés :
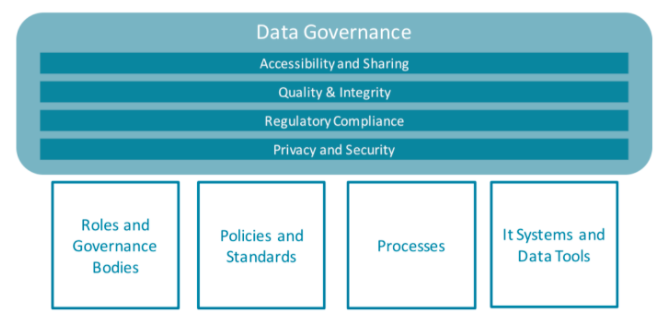
Levier #1 Rôles et organes de gouvernance :
C’est certainement le levier clé. La data porte l’expertise des femmes et hommes qui la produisent. Sans un engagement clairement porté par une organisation, il ne sera pas possible d’atteindre les objectifs.
- Quels sont les rôles clés à mettre en œuvre au sein de l’organisation et des sociétés (Chief Data officer, Data owner, Data manager, Data Steward) et quelles sont leurs responsabilités opérationnelles ?
- Pour chaque périmètre de données, qui est responsable de quoi ; qui est le Data Owner ?
- Les comités de gouvernance à mettre en place pour définir et suivre la bonne marche de la gouvernance de la donnée : au niveau des sociétés, au niveau du groupe ?
De nouveaux rôles et fonctions apparaissent ainsi et présentent la particularité de se répartir dans l’ensemble de l’organisation côté métiers et côté IT.
Le Chief Data Officer : il s’assure de la bonne définition et mise en place du cadre de gouvernance data à l’échelle de l’entreprise. Il propose et pilote des projets stratégiques et/ou transverses en la matière, travaille avec les sponsors métiers et l’IT pour hiérarchiser et résoudre les problématiques rencontrées dans le cadre de la gouvernance data
Le data manager : Il est garant de la collecte des données d’un périmètre de données, en s’assurant de leur exploitabilité au service d’un ensemble d’usages identifiés.
Il s’assure, sur ce périmètre, de la mise en œuvre des processus et politiques définis par la gouvernance de la donnée. Il contrôle l’application des contraintes réglementaires. Il anime la gouvernance opérationnelle relative à son périmètre de données
Le data steward : Il gère et administre opérationnellement tous les aspects d’un sous-ensemble de données. Il porte la responsabilité du contrôle technique des données : les aspects de sécurité, de qualité et d’accessibilité
Le data owner : Il est le référent métier au sein de l’entreprise sur un périmètre identifié de données.
Il est garant des définitions métiers et des référentiels associés. Il porte la responsabilité de la qualité de la donnée. Il délivre les autorisations d’accès à la donnée, en lien avec des cas d’usage identifiés.
Levier #2 Règles et normes :
Les règles et normes structurent l’action de la gouvernance et doivent faire l’objet d’un partage et d’un consensus au sein de l’entreprise.
- Quel niveau de confidentialité et de sécurité faut-il mettre en place, par typologie de données ?
- Quel cadre de règles (qualité, cohérence, propriété, documentation…) à mettre en œuvre, préalable au chargement des données dans une plate-forme Big Data ?
- Quels KPI choisir pour évaluer le niveau attendu de qualité de la donnée ?
Choisir des KPI de qualité
Choisir des KPI pertinents qui peuvent faire l’objet d’un monitoring dans le temps est souvent un enjeu appréhendé d’un point de vue technique : complétude, doublons, erreurs. Loin d’être inutiles, ces KPI ne sont pourtant généralement pas suffisants pour porter l’évaluation de l’accessibilité aux données. Deux méthodologies majeures émergent pour définir des KPI adaptés au contexte :
- Choisir des KPI qui intègrent de manière très pragmatique la quantité de connaissances acquises et disponibles sur une data : documentation associée, ownership et intégration dans un plan de gouvernance. On peut alors distinguer plusieurs questionnements. La data est-elle :
– définie ?
– de qualité et monitorée par un responsable ?
– accessible ?
– collectée dans un datalake ou un entrepôt central ?
– exploitable, c’est-à-dire dans un format qui permette son usage (papier, texte non structuré, fichier Excel) ?
Ces KPI devront être mis en oeuvre par les data owners et stewards.
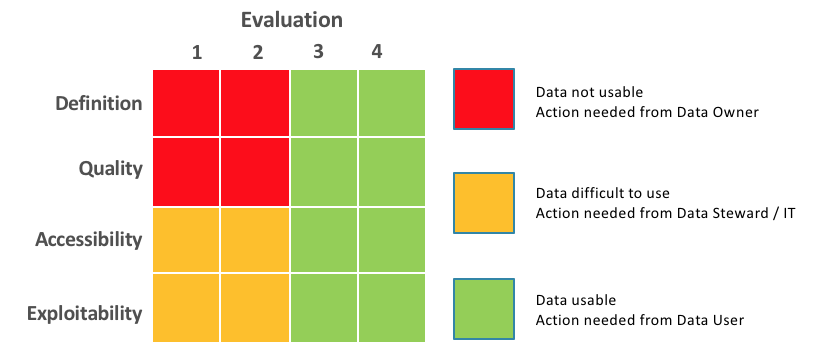
Exemple de matrice de monitoring de la qualité d’un jeu de donnée / Quantmetry 2018 – tous droits réservés – reproduction interdite
- Choisir des KPI déclaratifs qui émanent des utilisateurs de la donnée. Dans les entreprises les plus matures, ceci permet d’intégrer des feedbacks et des commentaires sur un modèle proche des E-commerçants. La palette de questions peut alors s’élargir : est-ce que la data a été utile et dans quel cas ? Quelle capacité de jointure avec les autres data du groupe ?
Levier #3 Les processus :
Les processus permettent d’instancier les règles et normes de la gouvernance et d’identifier clairement les responsabilités des acteurs impliqués.
- Quels processus pour identifier et gérer la propriété (data ownership) et l’accès aux données ?
- Quels sont les processus pour définir, mettre en œuvre et contrôler le respect des règles et des normes (qualité, sécurité,…) ? Au chargement sur une plateforme big data, dans le cadre d’un projet consommant ou produisant de la data ?
- Quelles règles de gestion pour le maintien des référentiels clés ?
- Quels sont les processus d’audit à mettre en place pour se conformer aux réglementations internes, externes ?
Levier #4 Les systèmes d’information et les outils informatiques :
- Comment implémenter les standards de sécurité des données dans l’architecture IT ? (chiffrement, gestion des droits d’accès aux données,…)
- Quels standards d’architecture mettre en place pour la collecte, l’exposition et l’utilisation de la donnée ?
- Quels outils pour assurer la documentation des données (data dictionary..) et le lineage (data management systems)?
- Quels outils pour monitorer la maturité des données ?
QUELQUES CONVICTIONS POUR IMPLÉMENTER UNE GOUVERNANCE DE LA DATA ADAPTÉE AUX ENJEUX DE L’ENTREPRISE
Conviction #1 : Il faut être conscient de sa data
L’enjeu d’une cartographie des données est de porter un regard sur le patrimoine data de l’entreprise et de dessiner la carte du monde en s’affranchissant des frontières traditionnelles représentées par les systèmes d’information. Loin d’être anecdotique, c’est bien une tendance de fond qui se dégage avec, à terme, la volonté des acteurs économiques de définir un patrimoine valorisable au même titre que le patrimoine immobilier ou intellectuel. Les Laboratoires Roche ont récemment fait l’acquisition de Flatiron health pour 1.9 milliards de dollars. Ils mettent ainsi la main sur un acteur qui a construit un asset data unique sur le marché de la santé. Ceci démontre que la valorisation de la data comme asset stratégique est plus que jamais d’actualité.
La cartographie de la donnée, quelques précisions méthodologiques :
Les cartographies de la donnée sont des représentations très concrètes, utilisant un langage métier pour décrire les grands groupes de données. Cette carte du monde permettra ensuite de structurer la stratégie de gouvernance et d’identifier des experts clés qui deviendront Data owners. L’objectif est de favoriser l’appropriation de la data par tous les interlocuteurs sans le filtre habituel du système ou de l’ERP. Selon la typologie d’entreprise, on peut l’organiser par process (finance..), produits (chaîne de valeur), client (approche customer-centric) ou choisir de représenter des flux (dynamique de la data).
L’essentiel est de la construire avec les métiers et de coller à des perceptions partagées.
Conviction #2 : Il faut être use case driven
Gouverner la donnée dans son ensemble est une vue de l’esprit. Il faut commencer pas à pas en se concentrant sur des cas d’usage qui font sens dans l’organisation. Les POC puis l’industrialisation vont permettre de prototyper l’organisation ad hoc et de dépasser les difficultés organisationnelles. Selon la maturité des entreprises, l’effort d’organisation ne sera pas le même. Essayer et apprendre reste la meilleure méthode pour expérimenter et suivre une courbe d’apprentissage réaliste, tirée par la création de valeur.
Conviction #3 : Il faut s’appuyer sur des hommes et des femmes
Comme l’indique le titre de l’article, la gouvernance de la data est avant tout une aventure humaine. Fondamentalement, le succès de la mise en place d’une gouvernance de la donnée repose sur une adhésion de l’ensemble de la société aux principes clés de l’intelligence artificielle, de la data science et du Big Data.
Pour gouverner la donnée, il faut accompagner les métiers, donner du sens et convaincre sans heurts. Ce besoin d’acculturation rejoint cette nécessité d’être Use case driven, c’est à dire d’écrire une histoire qui suscite l’adhésion avant de déployer massivement des rôles, des processus ou des outils. Un dispositif de gouvernance des données reposera toujours en partie sur des individus non dédiés fonctionnellement (c’est le cas des data owners par exemple) et qui, pourtant, auront un rôle clé, celui de documenter et partager leurs connaissances.
A ce titre, l’implication de la communication interne mais également des Ressources Humaines sont clés pour emporter une adhésion progressive et animer une “communauté data”.
Conviction #4 : Il faut un chef de projet gouvernance de la data et un soutien de la hiérarchie
La plupart des sociétés qui se lancent dans un chantier de structuration d’une gouvernance de la data, le font en s’appuyant sur des professionnels dédiés à la question. Naturellement, le rôle revient au Chief Data Officer mais comme pour tout projet, un leader technique est nécessaire pour mener des actions de concertation et d’évangélisation de l’entreprise. Sans ressource dédiée sur le sujet, sans un sponsorship clair ni ressources financières, il ne sera pas possible d’aborder un sujet qui touche le coeur de l’organisation. Même constat du côté de la mise en application du nouveau règlement général sur la protection des données. L’identification d’un chef de projet est incontournable.
Conviction #5 : Il faut être pragmatique
Dans la continuité d’une conduite du changement tirée par les cas d’usage et donc par la valeur, il faut privilégier des approches pragmatiques qui vont faire leur preuve : un data catalogue sous excel est en soi une excellente première étape sur la route du data management system.
La plupart des solutions clé en main du marché, que ce soit Zeenea (Cocorico!), Collibra, Talend Data Management, Informatica Axon, présentent des fonctionnalités d’une grande richesse. Mais leur coût de licence et d’implémentation reste généralement prohibitif et inadapté à l’approche incrémentale constituée d’expérimentations autonomes sur des périmètres de données bien ciblés. Ces outils pourront trouver leur place en régime nominal une fois les fonctionnalités attendues éclairées par l’expérience. Utiliser un fichier Excel ou développer en interne un outil de type “data catalogue” permettra aux acteurs clés de s’approprier et de construire une démarche adaptée à la culture et aux enjeux de l’entreprise.
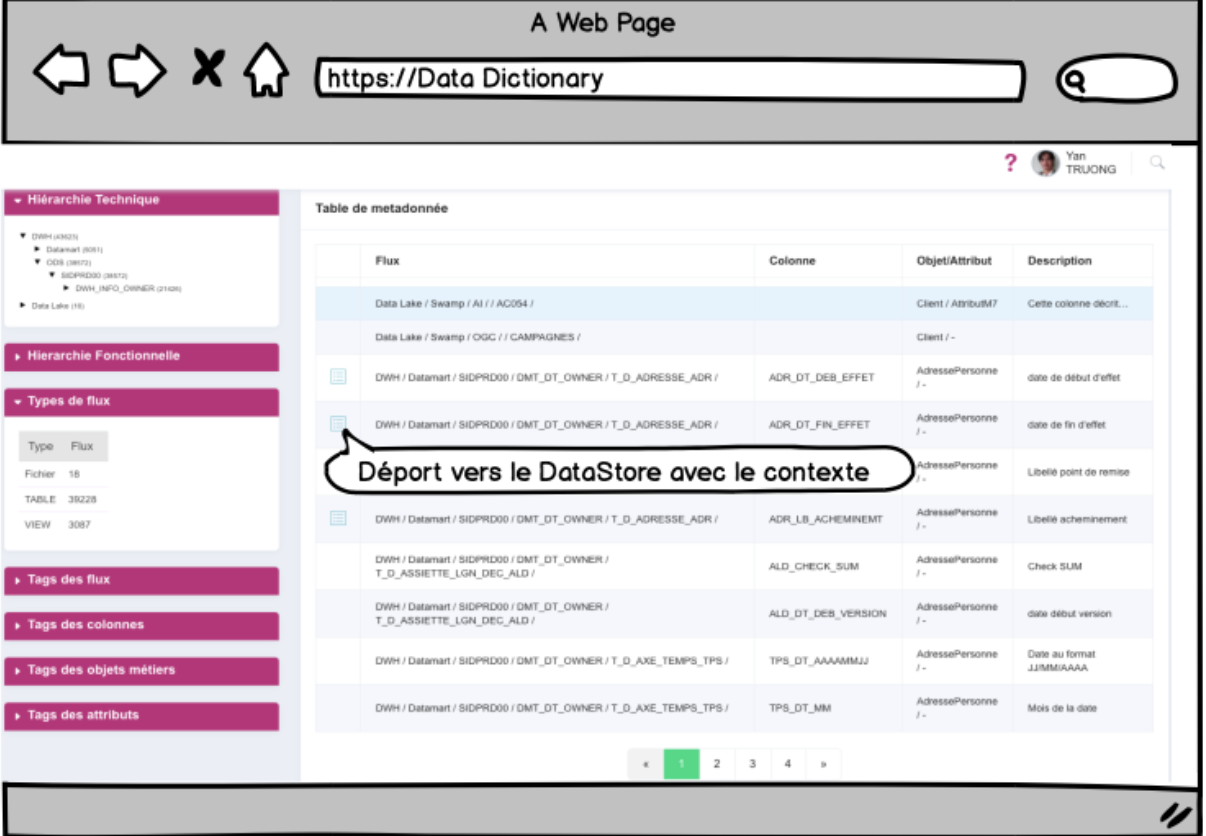
Une solution tailor made pour un acteur de la santé
Afin d’accélérer la mise en place d’outils de capitalisation, Quantmetry a construit un outil simple permettant d’automatiser la cartographie d’un datalake. En restreignant fortement le périmètre fonctionnel (collecte d’informations métiers sur chaque champ de table, collecte de quelques metadata, moteur de recherche simple, ergonomie minimaliste, data ownership), cette mutuelle a fait le pari d’une solution simple pour en favoriser l’appropriation par des utilisateurs métiers peu enclins à se former à des outils complexes à un stade expérimental.
Conviction #6 : Il faut lancer des chantiers clés pour mobiliser
Certaines organisations complexes on fait le choix d’adopter une approche originale pour susciter naturellement les besoins de gouvernance sans les imposer par le Top management. Cette approche consiste à imaginer quelques chantiers clés, très structurants pour la stratégie de l’entreprise et dont dérivent des besoins de gouvernance.
Cet opérateur industriel a ainsi choisi de commencer par implémenter une plateforme “open data” interne pour favoriser la publication de jeux de données de l’entreprise (liste des usines, liste des formations, chiffres financiers publiés officiellement lors de l’assemblée générale des actionnaires). Couplée à la mise en oeuvre de formations et de challenges data, cette stratégie a permis de légitimer le besoin de monitorer la qualité des données publiées et d’en déduire un certain nombre d’actions organisationnelles.
Le lancement de “chantiers autour de la data” qui acquièrent rapidement une visibilité vont permettre de travailler concrètement à l’acculturation des individus d’une entreprise et de diffuser un “data mindset” indispensable.
