

Initiation au Clustering
Le machine learning est sans conteste l’un des atouts majeurs permettant de comprendre les enjeux de la société d’aujourd’hui et de demain. Parmi les différentes composantes qui constituent cette discipline, je vais me concentrer sur l’un des sous-domaines d’application qui le caractérise : le clustering. Ce champ d’études couvre des domaines ainsi que des sujets divers et variés, et permet d’étudier les problématiques associées selon des perspectives différentes. En effet, l’algorithme ne sera pas influencé par le data scientist quant aux différentes typologies qui caractérisent la population à partitionner (consommateurs, gènes, objets, textes,…) : on parle d’objectivité algorithmique. Cet article présente succinctement certains sujets d’étude de cette forme d’intelligence artificielle afin d’initier le lecteur au champ de possibilités qui lui sont associées et d’illustrer certaines méthodes sans entrer dans l’exhaustivité de celles-ci.
CLUSTERING VS CLASSIFICATION : OÙ ? QUAND ? COMMENT ?
Le terme clustering est l’un des curieux anglicismes du data scientist ; celui-ci désigne le concept de classification non supervisée, appartenant à la grande famille de l’apprentissage non supervisé. L ‘étape préliminaire de cet article va consister à distinguer les deux grands types de classification : « supervisée » (classification en anglais) ou « non supervisée » (clustering). La distinction principale est expliquée dans ce qui suit, et est accompagnée de quelques exemples illustratifs de domaines d’application et de possibilités de sujets associés à ces deux groupes de méthodes.
-
La classification supervisée nécessite de fournir à l’algorithme une population déjà partitionnée. L’idée est de lui apprendre quelle est la loi qui régit la répartition afin qu’il puisse affecter un nouvel individu à sa classe d’appartenance.
On pensera tout d’abord au challenge Kaggle incontournable concernant la reconnaissance de chiffres manuscrits. D’autre part, on constate une réelle ouverture du monde de l’entreprise dans sa globalité à la classification supervisée. On peut citer l’exemple d’un grand opérateur téléphonique ayant récemment décidé d’intégrer le machine learning à sa méthodologie afin de « cartographier les talents » déjà présents en interne. Cela permettra dans un premier temps de déterminer rapidement et facilement quels employés positionner sur le lancement d’un nouveau service. Grâce à ses réponses au questionnaire, l’algorithme détermine auquel des 8 profils le salarié appartient. Dans la poursuite d’un objectif complètement différent, la classification supervisée a été, il y a peu, mise au service du e-commerce à travers un challenge de Data Science concernant la catégorisation de produits en fonction de leur image et de leur description[1].
Enfin, parmi les incontournables domaines d’application de la classification, on citera notamment la biologie, champ d’études très vaste et bien connu de l’analyste, à travers par exemple l’établissement de diagnostics médicaux : catégorisation de la nature de tumeur associée au cancer du sein (maligne ou bégnine), stade de maladie d’un patient, etc …
-
Le clustering vise quant à lui à déterminer une segmentation de la population étudiée sans a priori sur le nombre de classes, et à interpréter a posteriori les groupes ainsi créés. Ici, l’homme n’assiste pas la machine dans sa découverte des différentes typologies puisqu’aucune variable cible n’est fournie à l’algorithme durant sa phase d’apprentissage.
Là encore, les exemples d’application sont divers et variés. Dans le monde de l’entreprise, on rencontre ce sous-domaine du machine learning à travers la segmentation de clientèle, sujet d’une importance considérable dans le milieu marketing. Un autre cas d’usage correspond à la détection d’outliers, applicable à de nombreux domaines. On pourra penser plus particulièrement à la détection de fraudes, que ce soit dans les transports en commun, dans le cadre d’un remboursement de santé complémentaire ou encore au sujet de la consommation électrique… Les applications sont nombreuses.
On peut à nouveau citer le domaine du biomédical comme l’un des champs d’applications étendus de ces méthodes de classification, à travers, entre autres, le regroupement de gènes différentiels selon leur profil d’expression dans un phénomène biologique au cours du temps.
Pour les plus mélomanes, ces algorithmes peuvent aussi être utilisés dans une problématique de recommandation, afin de répartir différentes musiques en clusters et proposer à l’utilisateur une chanson « semblable » à celle qu’il vient d’écouter. Enfin, on peut constater que quelques « sériephiles » débordent d’imagination concernant les nouveaux domaines d’applications du clustering. Certains prévoient sur la toile d’appliquer ces méthodes aux personnages de Game of Thrones afin de détecter des typologies d’individus, et qui sait, peut-être déterminer scientifiquement quels seront les vrais prétendants au trône de fer. Le clustering, il y en a définitivement pour tous les goûts.
De nombreuses méthodes de classification non supervisée ne peuvent s’appliquer qu’à des données quantitatives. Je me placerai donc dans ce cas pour illustrer mes propos. Remarquez cependant qu’il est possible de traiter ces données en amont afin de se ramener au cas quantitatif. En effet, en présence d’un mélange de variables quantitatives et qualitatives, on peut gérer le problème d’hétérogénéité des données en réduisant d’une part les données quantitatives, et en utilisant d’autre part une méthode telle que l’Analyse Factorielle des Correspondances Multiples (AFCM) afin de créer des coordonnées quantitatives à la population. Cette méthode de réduction de dimension calculée sur les variables qualitatives correspond à une AFC du tableau disjonctif complet, et va mener à une production de scores[2]. Ces derniers peuvent alors être utilisés comme coordonnées quantitatives des individus.
Le clustering revient à chercher une structure « naturelle » dans les données, puisqu’aucune typologie cible n’est fournie préalablement à l’algorithme. L’idée est de déterminer des classes devant être à la fois les plus homogènes possibles tout en se distinguant au mieux les unes entre les autres. C’est alors que l’on commence à toucher du bout des doigts la nécessité de déterminer une mesure de séparabilité des classes, de (dis)similarité entre les individus.
Cette notion ne sera en réalité pas le seul choix du data scientist dans sa recherche de clusters d’individus. Les principaux seront les suivants (dans le cas quantitatif dans lequel nous nous sommes placés) :
-
le concept de dissimilarité, de dissemblance ou encore de distance entre les individus que je viens d’évoquer. En pratique et dans notre cas, le choix de la matrice identité en tant que matrice de produit scalaire semble être élémentaire, et est néanmoins assez courant. Cependant, dans le cas de variables de variances hétérogènes, il est fortement conseillé de les réduire (comme dans le cas d’une ACP). La matrice associée au produit scalaire correspond alors à la matrice des inverses des écarts-types (sur la diagonale donc). Attention au terme utilisé pour désigner ce concept selon le type de vos individus, on ne pourra pas, par exemple, parler de distance dans le cas qualitatif,
-
la notion d’homogénéité des classes: elle est mesurée à partir de la matrice variance-covariances intra-classe (ou interclasses pour l’hétérogénéité des classes entre elles),
-
le nombre de classes, noté K.
Enfin, selon la méthode retenue, il peut être nécessaire de définir un critère d’arrêt de l’algorithme (convergence vers un minimum local ou nombre d’itérations maximum fixé).
Maintenant que vous connaissez tous les choix cornéliens que vous devrez effectuer, entrons un peu plus en détails dans la description de deux grandes catégories du clustering : la classification hiérarchique non supervisée et les méthodes de partitionnement.
LA CLASSIFICATION HIÉRARCHIQUE NON SUPERVISÉE
La première étape de cette méthode consiste à définir un tableau de distances ou de dissemblances entre les individus, qui sera recalculé à chaque étape. La Classification Ascendante Hiérarchique (CAH) va, en partant de la classification donnée par les singletons, regrouper les éléments (singletons ou classes) les plus proches jusqu’à l’obtention d’une seule classe.
Cette méthode permet d’obtenir une représentation graphique similaire à un arbre, appelé dendrogramme. Il représente l’ensemble des classes créées au cours de l’algorithme. Celles-ci ont été regroupées au fur et à mesure des itérations en s’appuyant sur la comparaison des distances ou dissemblances entre les individus et/ou les classes. La taille des branches du dendrogramme est proportionnelle à cette mesure entre les objets regroupés.
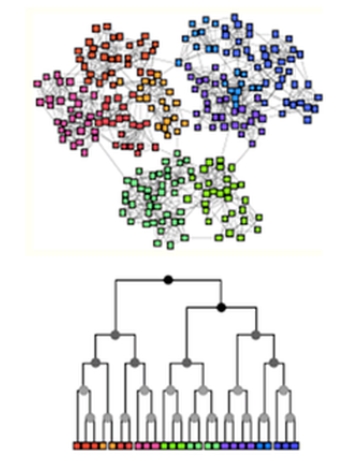
Exemple de classification (en haut) et dendrogramme associé (en bas).
Graphiquement, c’est donc à l’endroit où les branches du dendrogramme sont les plus élevées qu’il faut « couper », c’est-à-dire arrêter la répartition en classes.
Le tracé de l’évolution de l’inertie intra-classe en fonction du nombre de clusters aide lui aussi graphiquement l’analyste au choix de K. Celle-ci diminue lorsque le nombre de classes augmente. En effet, elles sont de plus en plus homogènes, de plus en plus petites et les individus de plus en plus « proches » du centre de gravité de leur cluster.
Puisque l’on cherche à minimiser ce critère, on aurait tendance au premier abord à vouloir sélectionner un nombre de classes K très élevé. Un tel choix ne serait néanmoins pas judicieux puisque la classification n’apporterait que très peu d’information. Son interprétation n’en serait que plus difficile. C’est pourquoi c’est en fait une diminution “brutale” de l’inertie intra-classe en fonction du nombre de clusters qu’il faut rechercher.
Différentes stratégies d’agrégation entre deux classes A et B peuvent être considérées lors de la construction du dendrogramme, dont les plus connues sont les suivantes :
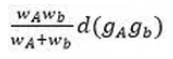
-
Le saut minimum ou lien simple correspondant à la plus petite distance parmi l’ensemble des distances calculées entre un individu de A et un de B,
-
Le saut maximum ou lien complet correspondant à la plus grande distance parmi l’ensemble des distances calculées entre un individu de A et un de B,
-
Le saut moyen ou lien moyen correspondant à la moyenne des distances entre les individus de A et ceux de B,
-
Le saut de Ward, qui vaut
en considérant d comme la distance euclidienne et gA et gB les barycentres des classes considérées, wA et wB étant les pondérations respectives des classes A et B.
Deux questions se posent alors en pratique : quel saut choisir et pourquoi ?Voici quelques éléments généraux de réponse. Le lien simple va être associé à l’arbre couvrant minimal. Il génère des classes de diamètres très différents et a une tendance à l’effet de chaînage : il favorise généralement l’agrégation plutôt que la création de nouveaux clusters et présente une sensibilité aux individus bruités.
Le lien complet créera quant à lui des classes compactes et arbitrairement proches. Il est lui aussi sensible au bruit.Le lien moyen correspond à un bon compromis entre séparation et diamètre des classes, c’est en fait un bon compromis entre lien simple et lien complet. Néanmoins, les clusters présenteront généralement des variances proches.
Enfin, à chaque itération (ou étape de regroupement), le saut de Ward choisit de minimiser l’augmentation de l’inertie intra-classe. Ce lien aura tendance à créer des classes plutôt sphériques et d’effectifs égaux pour un même niveau du dendrogramme. Il présente aussi une certaine facilité d’utilisation : même dans le cas où la distance entre individus n’est pas euclidienne, son expression n’est pas modifiée. C’est pour l’ensemble de ces raisons que la palme d’or du choix le plus courant des utilisateurs revient sans conteste au saut de Ward.
Il est important de noter que la classification hiérarchique non supervisée est assez chronophage. Elle n’est à appliquer qu’à des datasets peu conséquents en termes de nombre d’individus. Le dendrogramme est d’ailleurs de moins en moins lisible lorsque ce nombre augmente. Je vous présenterai en fin d’article une manière de remédier à ce type d’inconvénients.
MÉTHODES DE PARTITIONNEMENT (OU DE CENTRES MOBILES)
LES DIFFÉRENTES MÉTHODES
L’originalité de cette méthode provient de son caractère contradictoire, dans le sens où son appartenance aux algorithmes d’apprentissage non supervisé s’oppose à la nécessité d’un nombre de classes K fixé a priori pour cette méthode. Il est important de noter que ces algorithmes sont bien moins conséquents en temps de calculs que ceux introduits précédemment.
Je vais principalement détailler ici la méthode des nuées dynamiques et j’aborderai ensuite les variantes existantes. Le principe est le suivant :
-
Initialisation : Les k centres initiaux sont généralement choisis par tirage aléatoire ou par utilisation des centres d’une méthode de clustering déjà appliquée à la population.
-
Les individus sont affectés à la classe dont le centre est le plus « proche » [3]
-
Les étapes suivantes sont réitérées :
– Les barycentres de ces classes sont calculés et deviennent les nouveaux centres.
– Les individus sont alors affectés à la nouvelle classe dont le centre est le plus proche, et ce procédé est réitéré.
-
L’algorithme s’arrête selon un critère défini par l’utilisateur.
Selon la métrique choisie préalablement choisie.
Deux variantes principales de la méthode des nuées dynamiques existent et se classent dans la famille des méthodes de partitionnement :
-
Les K-means de MacQueen : le choix des centres des classes est effectué par tirage pseudo- aléatoire. Contrairement à la méthode précédente, la méthode K-means de MacQueen n’attend pas d’avoir réaffecté tous les individus pour modifier la position des centres (qui correspondent aux barycentres). À chaque fois qu’un individu est réaffecté à une classe, le centre correspondant est modifié. C’est pourquoi cette méthode peut retourner une classification satisfaisante en une seule itération.
-
Les méthodes de type K-médoïdes: contrairement aux deux algorithmes présentés précédemment, la notion de noyaux fait ici référence à des individus du jeu de données[4]. La méthode consiste à effectuer une réallocation dynamique des individus à des centres de classes correspondant à des points des données, que l’on appellera médoïde Ces algorithmes sont donc plus robustes que ceux de type K-means, puisque moins sensibles aux valeurs atypiques. Un médoïde minimise la moyenne des distances aux autres observations de la classe.
Des variantes de ce type de méthode peuvent être appliquées à des variables qualitatives (ces versions sont appelées les méthodes de type K-modes).
CHOIX DU NOMBRE DE CLASSES EN PRATIQUE : LE POURQUOI DU COMMENT
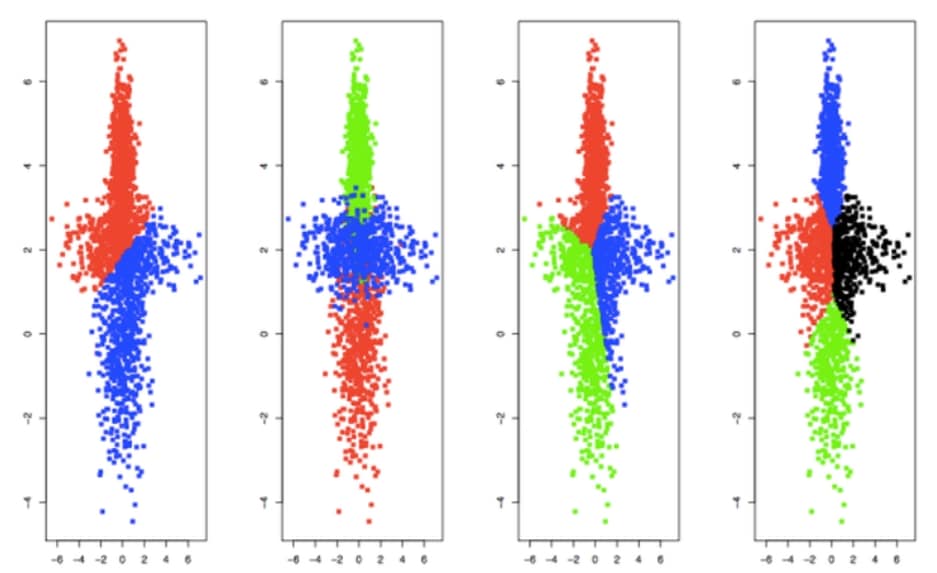
Voici un exemple de classification en utilisant l’algorithme des nuées dynamiques pour 2, 3 et 4 classes et en tirant aléatoirement les noyaux initiaux. La classification a aussi été relancée pour K=3 avec des noyaux initiaux différents.
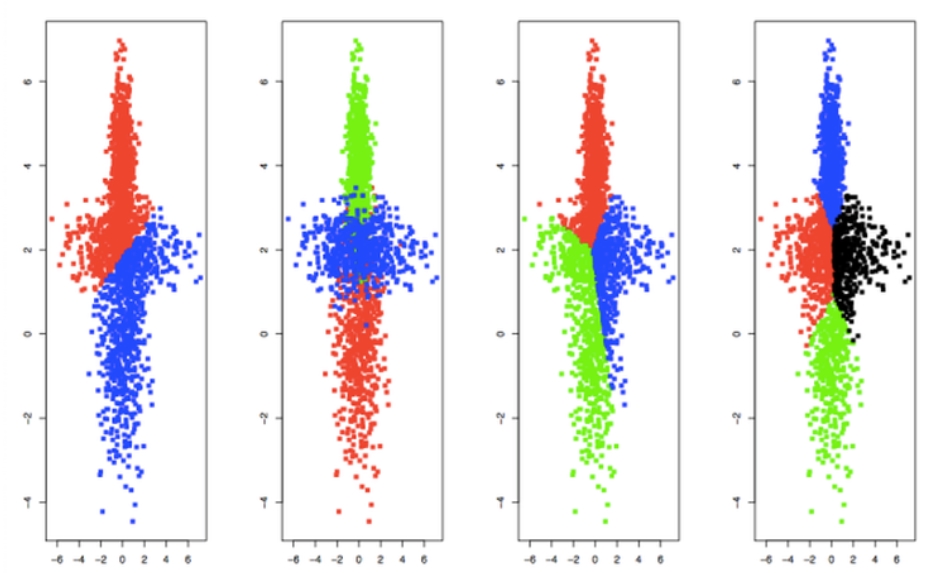
Classifications de données, méthodes des nuées dynamiques pour un nombre de classes K variant de 2 à 4 (différents noyaux initiaux tirés aléatoirement ayant été choisis pour K=3).
On peut constater graphiquement une forte dépendance de la classification au choix des noyaux initiaux dans le cas des exemples pour K=3. De plus, remarquez la sensibilité de la classification au nombre de classes retenu : ce choix est primordial, mais délicat. C’est pourquoi il est nécessaire de se pencher un peu plus sur la question.
Les critères de sélection de K les plus utilisés sont les suivants :
-
Le gap statistique : c’est l’écart entre la dispersion intra-classe des données et celle qui serait obtenue dans le cas de données uniformément réparties. L’objectif est donc de le maximiser,
-
L’inertie intra-classe : c’est en fait une diminution brutale ou « coude » de l’inertie intra-classe en fonction du nombre de classes qu’il faut chercher,
-
Le critère silhouette S(K): il est déterminé en calculant tout d’abord un indice propre à chaque individu i, noté s(i), variant entre -1 et 1. s(i) prend en compte la moyenne, notée c(i), des distances entre i et tous les individus de sa classe, mais aussi la moyenne v(i) avec ceux de la classe la plus proche.
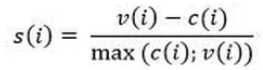
Plus s(i) est proche de 1, plus on peut affirmer que l’individu i se trouve dans la bonne classe. A contrario, s’il est trop proche de -1, l’individu est mal classé. Le critère silhouette S(K) d’une partition à K fixé correspond à la moyenne des s(i). C’est pourquoi on cherche à le maximiser.
Les différents critères n’indiquent pas toujours la même marche à suivre, ce qui peut rendre le choix de K relativement compliqué. Cependant, l’analyse conjointe de plusieurs critères et l’étude de leurs optima (locaux ou globaux) permettent au data scientist d’effectuer ce choix et de continuer sa démarche.
GÉRER LES INCONVÉNIENTS DE CES MÉTHODES ET CUMULER LEURS AVANTAGES : LA CLASSIFICATION MIXTE
En résumé, les caractéristiques des méthodes vues précédemment sont les suivantes :
-
La classification hiérarchique non supervisée permet d’obtenir une partition ayant un nombre de classes quelconque, conduit toujours aux mêmes classifications et est coûteuse en temps de calculs sur d’importants volumes de données,
-
Les méthodes de partitionnement requièrent un nombre de classes fixé au préalable, peuvent traiter des volumes de données conséquents et donnent une classification finale fortement dépendante à la partition de départ (celle-ci est choisie par l’analyste, éventuellement par tirage au sort des points autour desquels sont constituées les classes).
Afin de pallier les inconvénients respectifs des deux types de méthodes, il est possible de les combiner :
-
Étape 0, optionnelle (dans le cas où le nombre d’individus n est élevé) : Lancer plusieurs fois un algorithme de partitionnement en faisant varier les K noyaux initiaux. Cela permet de distinguer ce qu’on appelle des « formes fortes », qui correspondent aux groupes d’individus toujours classés conjointement dans chacune des différentes partitions.
-
Étape 1 : Mettre en place une classification hiérarchique non supervisée en partant des formes fortes de la partition précédemment créée. Ceci permet de gagner en temps de calculs sur cette méthode.
-
Étape 3 : Mettre à nouveau en place un algorithme de centres mobiles en utilisant la partition retenue dans la CAH précédente comme partition de départ. Grâce à cette façon de procéder, on utilise des noyaux choisis pertinemment plutôt que sélectionnés au hasard.
De cette manière, on combine les avantages de ces deux types de méthodes et on s’affranchit des inconvénients propres à chacune. On est assurés d’obtenir un optimum local en un temps raisonnable, et ce même dans le cas de n très grand !
Maintenant que la classification hiérarchique non supervisée et les méthodes des centres mobiles n’ont plus de secret pour vous, je peux clôturer cet article par un exemple visuel assez sympathique de ce type de clustering appliqué à des pixels[5] (dans le cadre de la reconnaissance de formes) :

Les résultats parlent d’eux-mêmes, et c’est assez bluffant !
Si vous souhaitez savoir de quoi s’inspire cet article, vous pouvez cliquer ici, ici ou même ici (et puis ici et ici aussi). Next article is coming !
Références :
1) https://www.datascience.net/fr/challenge/20/details
2) Ce sont les composantes principales de l’ACP des profils-lignes.
3) Selon la métrique choisie préalablement choisie.
4) Des variantes de ce type de méthode peuvent être appliquées à des variables qualitatives (ces versions sont appelées les méthodes de type K-modes).
5) http://chamroukhi.univ-tln.fr/courses/Chamroukhi-cours-image-seg.pdf
