

Intelligence Artificielle en Data Science ? Et si l’automatisation du Machine Learning suffisait ?

Introduction
Chaque Data Scientist, que cela soit durant sa formation, une compétition ou dans sa vie professionnelle s’est posé au moins une des questions suivantes “Quel modèle est le plus intéressant à utiliser ?” “Quelle transformation de mon jeu de données faut-il effectuer ?”.
Bien que le métier de Data Scientist s’est vu décerner la palme du “métier le plus sexy du siècle”, il est tout de même nécessaire de se salir les mains afin d’obtenir des résultats qui soient à la fois satisfaisants et qui réussissent à expliquer le phénomène du problème. C’est à ce moment là qu’intervient l’automatisation du Machine Learning. L’objectif étant de délester le Data Scientist des tâches laborieuses et répétitives lui permettant d’allouer plus de temps à son expertise sur le domaine des données.
L’automatisation du Machine Learning est un terme souvent utilisé de paire avec l’éviction du Data Scientist. Pour autant cette conclusion est fausse. Effectivement, si une personne possède des connaissances mathématiques solides mais éprouve quelques difficultés en informatique, l’automatisation du machine learning permettrait de se passer d’un Data Scientist pour la modélisation. Toutefois, il manquerait certainement des fondements statistiques pour fournir des conclusions viables. De plus, une personne très éloignée des mathématiques ne tirera aucun bénéfice de l’automatisation du Machine Learning pour les raisons citées ci-dessus.
Machine learning et intelligence artificielle sont souvent confondus dans leur définition, quelques mots pour rappeler la différence. L’intelligence artificielle propose à une machine d’apprendre et de comprendre des concepts lui permettant d’effectuer des tâches qu’on pourrait considéré comme “intelligentes”. Le machine learning quant à lui, est une branche de l’intelligence artificielle qui permet à la machine d’apprendre par elle-même au fur et à mesure qu’on lui fournit les données.
Lorsqu’un Data Scientist s’intéresse au Machine Learning, ce dernier fait face à un processus qui est souvent identique au cours de ses projets :
- Collecte des données
- Assemblage des données
- Nettoyage des données
- Modélisation des variables
- Sélection de l’algorithme
- Affinage du modèle
Sur le papier cela semble très intéressant. Toutefois, les trois premières sections prennent à elles-seules 70% du temps du Data Scientist, pour autant, aucune expertise particulière n’est demandée pour effectuer ces tâches. L’automatisation du Machine Learning prend ici tout son sens. Cette solution propose d’effectuer tout le processus en tentant en plus de l’optimiser pour répondre au mieux aux problématiques qui peuvent être à la fois diverses et variées (classification, régression, prédiction, contrainte de temps, …).
En résumé, l’automatisation du Machine Learning semble révolutionnaire. On fournit un jeu de données, on lui indique notre problème et on récupère la modélisation qu’il nous suffit d’interpréter.
De nombreuses personnes ont déjà contribué à l’automatisation du Machine Learning en commençant par des compétitions, des sites ou encore des librairies telles que :
- auto sickit-learn : Tuning d’hyper-paramètres, feature engineering et sélection de modèle(s), fonctionne sur un jeu de données petit ou moyen mais plus difficilement sur un large jeu de données. Utilise la recherche bayésienne pour le Deep Learning
- TPOT : Fournit un pipeline très complet au Data Scientist, mais n’est pas adapté au NLP
- H2O : Bon pour le Deep Learning, fait ses propres algorithmes
- MLBox : Data cleaning, sélection d’hyper-paramètres et sélection de modèle
Chacun ayant ses avantages et ses inconvénients.
Cet article est divisé en deux parties, une première avec une présentation plus complète sur le cycle de modélisation d’un Data Scientist, suivi d’une focalisation sur l’optimisation.
Cycle de modélisation
Comme cité plus haut, le rôle d’un Data Scientist n’est pas uniquement d’effectuer des modélisations mathématiques et statistiques. La première étape, souvent oubliée, mais qui représente une phase décisive du métier n’est autre que l’exploitation des données brutes. Qu’elles soient issues d’un fichier ou de web scraping, l’objectif du Data Scientist sera de sélectionner, nettoyer et transformer ces informations brutes en données adaptées à sa problématique.
La phase de sélection des données est une tâche propre au Data Scientist et non à l’automatisation. C’est un travail qui nécessite du bon sens et une certaine expertise à la fois concernant la science des données mais aussi du métier auquel on tente de répondre à la problématique, pour choisir les informations qui sembleraient utiles au sujet.
C’est à partir de la phase de nettoyage que l’automatisation du processus d’apprentissage statistique prend tout son sens. En effet, une solution offrant une structure claire aux données ainsi que la gestion de tout élément bloquant la modélisation comme les Not a Number (NaN) en proposant différentes possibilités telles que la suppression des observations qui en possède ou en les remplaçant par la moyenne offrirait un gain de temps certain ainsi que des intuitions intéressantes aux Data Scientist. L’auto ML peut aussi transformer automatiquement des types de données (string, datetime) pour qu’ils soient interprétable pour toute modélisation, c’est ce qu’on appelle l’encodage des données. De façon très simple un one hot encoding peut être une solution.
La phase de pré-traitement se situe entre le nettoyage du jeu de données et la transformation des variables. L’objectif est d’harmoniser l’ensemble des données en utilisant par exemple une normalisation, une standardisation ou tout autre type de mise à l’échelle. Là encore, quel pré-traitement est le plus intéressant pour notre problématique ? Serait-il judicieux de combiner deux pré-traitements ? De plus, si on ajoute les possibilités du paragraphe précédent, cela commence à faire beaucoup. Une nouvelle fois, l’automatisation du Machine Learning est une solution tout à fait intéressante car elle effectue les combinaisons disponibles en considérant les contraintes.
La suite est d’autant plus complexe qu’il n’y a pas de limite. Cette phase peut durer quelques instants comme plusieurs semaines, c’est le Feature Processing, comprenez le traitement des variables explicatives. Il existe deux notions bien distinctes :
- Le Feature Engineering qui s’intéresse aux transformations des variables disponibles
- La Feature Selection qui quant à elle s’occupe de conserver les variables selon certains critères.
Le Feature Engineering reste cependant un moment délicat dans le processus du Machine Learning car les mêmes variables explicatives peuvent avoir un effet totalement contradictoire pour différents jeux de données. Dans le cadre de l’automatisation, il paraît judicieux de fournir des transformations simples qui soient reconnues le plus souvent comme source de valeur ajoutée, on pensera par exemple :
- Analyse en Composantes Principales (ACP)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
- Polynomial Features
- Transformation de la variable explicative des dates
Il existe des libraires sous python permettant du Feature Engineering telles que :
La Feature Selection permet, une fois que les variables sont créées, de ne conserver que celles qui semblent convenir selon les contraintes proposées. Ces méthodes peuvent être :
- Filtre : Corrélation, hypothèse de test, gain supplémentaire d’une variable
- Wrapper : Sélection de type forward, backward ou encore stepwise
- Embedded : Lasso, Random Forest
- La combinaison de plusieurs feature selection
Dans le cadre de l’automatisation du Machine Learning, le Feature Processing est très intéressant. Il offre la possibilité de créer de nombreuses variables puis de sélectionner uniquement celles qui semblent les plus pertinentes.
La partie suivante est consacrée à la sélection de l’algorithme ainsi que l’affinage du modèle qui se fait à l’aide d’optimisations et plus principalement, l’optimisation bayésienne.
L’optimisation
Quand on parle du métier de Data Scientist, on fait souvent référence à la section consacrée à la modélisation. En effet, c’est maintenant que tout ce qui a été fait auparavant est utilisé pour mettre sur pied le modèle. De nouveau, on doit effectuer un choix, quel modèle correspond le mieux aux données : Un modèle linéaire, un modèle à arbre, une méthode de bagging, de boosting, d’autres modèles non-linéaires ? Les possibilités sont nombreuses, d’autant plus qu’il existe des méthodes qui consistent à assembler les prédictions de différents modèles entre eux ou encore utiliser la prédiction d’une modélisation pour construire une nouvelle variable explicative pour un autre modèle ! Autant de possibilités que de doutes. Une nouvelle fois l’automatisation du Machine Learning peut être utile. Mais ne manque-t-il pas un petit détail ? Choisir le type de modèle selon la situation, c’est bien, mais encore faut-il choisir les hyper-paramètres, et là, les possibilités sont presques infinies. C’est pour cette raison que nous utilisons l’optimisation bayésienne !
Si l’on devait définir très rapidement ce que sont des hyper-paramètres, ils correspondent aux paramètres généraux d’un algorithme, qui restent fixes sur l’ensemble de la modélisation.
Avant de nous concentrer sur l’optimisation bayésienne, il serait intéressant de discuter des autres méthodes disponibles.
La première méthode et la plus pragmatique est celle dite “Manuelle” où l’on décide des hyper-paramètres selon notre intuition, une fois le premier résultat obtenu on affine afin d’obtenir une meilleure métrique. C’est intéressant, mais avouons le, c’est long et fastidieux.
La seconde méthode, qui est sûrement la plus répandue, est le grid search. On donne une plage de valeurs que les hyper-paramètres prendront afin de tester toutes les combinaisons possibles entre eux. Cette méthode a le mérite de très bien fonctionner, mais son grand défaut réside dans le temps de calcul parfois long pour entraîner des modèles sur des grands jeux de données. A titre d’exemple, si l’on donne trois valeurs pour trois hyper-paramètres le grid search effectuera 27 combinaisons.
La troisième méthode se situe légèrement entre les deux, c’est le random search, le principe est comme le grid search : on fournit une plage de valeurs pour les hyper-paramètres que l’on souhaite tester et on décide arbitrairement de limiter le nombre de modélisations. Le random search choisira aléatoirement des combinaisons de valeurs pour ses hyper-paramètres.

KDnuggets propose une visualisation intéressante des 3 méthodes.
Il existe d’autres solutions pour l’optimisation des hyper-paramètres telles que la méthode Evolutionnaire (qui est utilisée par TPOT) ou Particle Swarm Optimization mais elles ne sont pas beaucoup utilisées.
Venons en à la méthode qui nous intéresse, l’optimisation bayésienne !
L’optimisation des hyper-paramètres, au-delà de l’auto-ML est un pan important de la recherche. L’optimisation bayésienne permet de répondre au mieux à ce besoin.
En mettant de côté les mathématiques, imaginons une pièce dans laquelle vous connaissez la température aux quatre coins de celle-ci, la connaissance de ces dernières vous permettra de prédire avec plus d’assurance la température des autres emplacements de la pièce.
En ML, la fonction objective y=ƒ(x) est considérée comme une « boîte noire » où y représente la métrique comme la mean squared error et x l’ensemble des hyper-paramètres du modèle. Elle porte ce nom car nous n’avons ni expression analytique, ni dérivée pour la résoudre. On ne peut évaluer la fonction qu’en échantillonnant au point x. C’est exactement le problème auquel fait face un Data Scientist, tant qu’il n’a pas effectué sa modélisation, il est impossible pour lui de connaître la valeur de sa métrique (Courbe Roc, précision, R2). Il est vrai que lorsque la fonction possède un faible coût, il paraît plus intéressant d’effectuer un grid ou random search. Cependant, dès lors qu’on fait face à un réseau de neurones ou un énorme dataset par exemple, il semble nécessaire de minimiser l’échantillonnage au sein de cette boîte noire. C’est l’objectif de l’optimisation bayésienne, trouver l’optimum global en un minimum d’étapes :
![]()
La modélisation pour approcher la fonction objective s’appelle le Surrogate Model, on utilise le passé afin de mieux prédire l’avenir, et en utilisant une Fonction d’Acquisition pour connaître la prochaine valeur de x qui semble la plus intéressante à échantillonner.
![]()
Il existe deux façons bien connues pour modéliser l’optimisation bayésienne :
- Gaussian Process (GP) : basé sur la loi Gaussienne avec une large littérature
- Tree-structured Parzen Estimators (TPE) : qui utilise une structure en arbre
De nombreuses librairies consacrées à l’optimisation bayésienne sont disponibles. Les plus connues sont :
- Hyperopt : TPE
- Hyperopt-sklearn
- Scikit-Optimize : Utile lorsqu’un seul modèle est désiré, excellente documentation
Le processus simplifié d’une optimisation bayésienne est la suivante :
- Choix de la fonction objective
- Domaine des hyper-paramètres
- Surrogate Model de la fonction
- Fonction d’acquisition
- Optimisation et historique
Le Processus Gaussien (GP) est une méthode non-paramétrique. Plutôt que d’inférer la distribution sur les paramètres d’une fonction, le processus va inférer la distribution directement à travers la fonction. Le Processus Gaussien est un processus dit aléatoire (stochastique) en tous points x appartenant à l’espace des Réels de dimension d est assigné une variable aléatoire ƒ(x) et où la distribution jointe d’un nombre fini est :
![]()
en d’autres termes, notre fonction ƒ(x) suit une loi Normale avec :
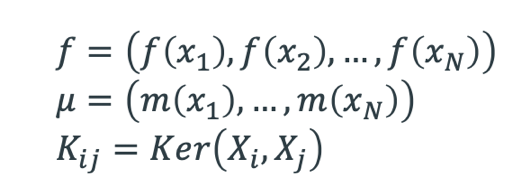
On considère m(x)=0 assez flexible pour bien arbitrer en moyenne. K est défini positif et représente la fonction covariance (ou Kernel).
Un GP prior P(ƒ|X) peut devenir un GP posterior P(ƒ|X, y) après avoir observé quelques points y. Le posterior peut être utilisé pour faire des prédictions ƒ* avec de nouveaux inputs X* :
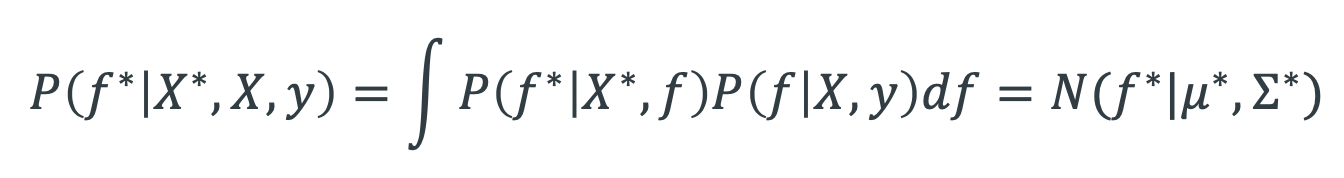
C’est la distribution prédictive postérieure
Par définition du GP, la distribution jointe des données observées y et ƒ*
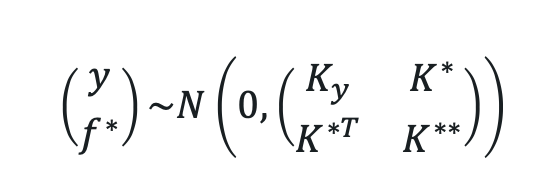
Avec N données d’entraînement et N* nouveaux inputs
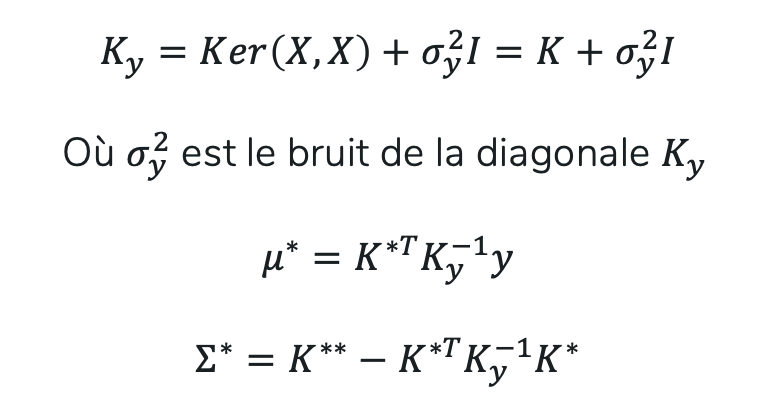
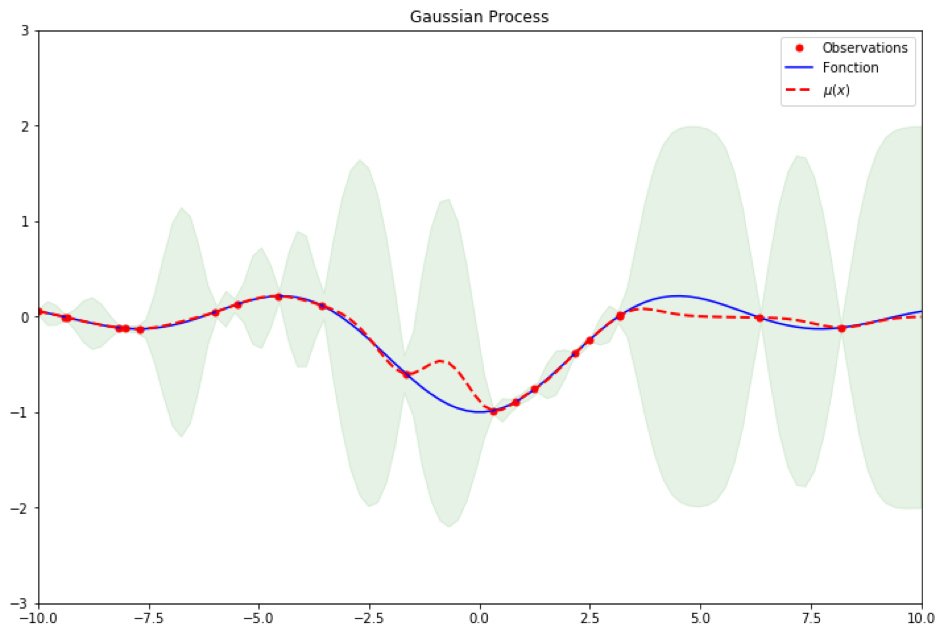
Le GP recherche l’optimum global de la fonction en bleu qui est trop difficile de calculer en tout point. Le GP n’échantillonne que quelques points en rouge, le reste de la fonction provient d’une estimation selon la loi Normale où μ remplace le reste de la fonction en tout point et l’intervalle de confiance le risque. Plus les observations sont proches l’unes de l’autres, plus l’intervalle de confiance est faible.
Toutefois, pour savoir comment ces observations sont choisies, il faut s’intéresser aux fonctions d’acquisitions.
La fonction d’acquisition propose un compromis entre exploitation et exploration durant l’optimisation :
- Exploration : Là où l’incertitude de prédiction est grande
- Exploitation : Là où le Surrogate Model prédit un haut objectif
3 fonctions d’acquisitions sont souvent utilisées dans le cadre de l’optimisation Bayésienne :
- Maximum Probability Improvement (MPI)
- Expected Improvement (EI)
- Upper Confidence Bound (UCB)
La librairie Hyperopt utilisant EI on s’intéressera principalement à cette dernière.
![]()
avec
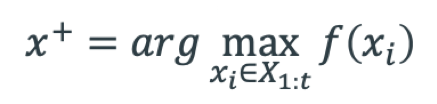
Où ƒ(x+) est le meilleur échantillon jusqu’à présent. Ainsi dans le cadre du GP on a :
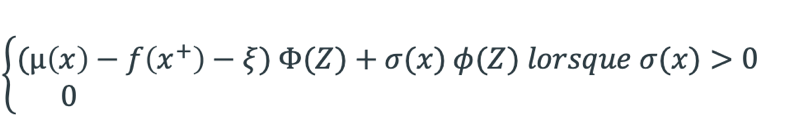
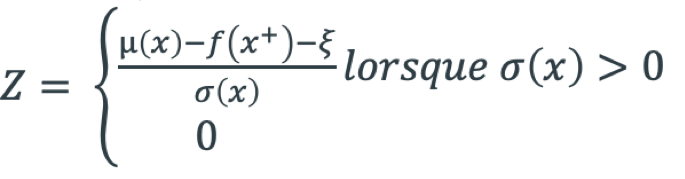
ξ détermine la sensibilité de l’exploration, plus la valeur est élevée plus baisse au détriment de (x)
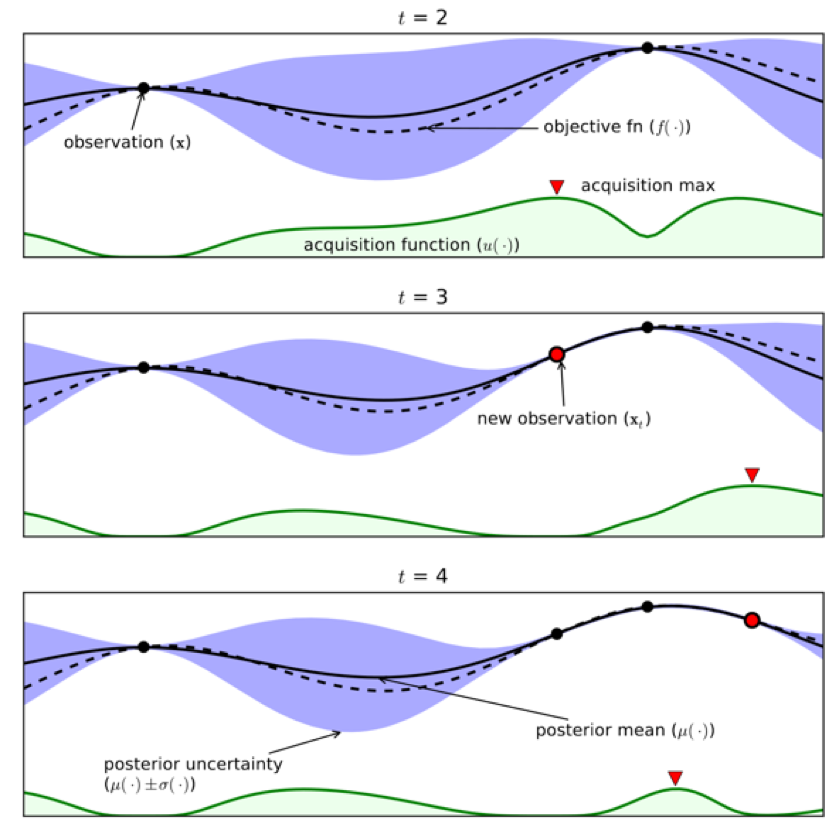
Lorsque t=2 il n’y a que deux observations, en vert on remarque que la fonction d’acquisition, qui est une densité, propose une observation en t=3 et t=4 assez proche du point le plus à droite. L’exploitation a été préférée à l’exploration et la fonction d’acquisition ne se trompe pas, elle se concentre bien sur l’optimum global. L’article
Bien que le Processus Gaussien soit très largement présent dans la littérature mathématique, dans le cadre de l’automatisation du Machine Learning ce ne sera pas notre méthode privilégiée. Pourquoi ? Car le GP ne prend pas en compte les dépendances conditionnelles. Afin de mieux comprendre, intéressons nous à la méthode Tree-structured Parzen Estimators (TPE).
L’algorithme TPE possède une petite différence face aux modèles séquentielles (SMBO). En effet, il ne définit pas une distribution de prédiction sur la fonction objective. Il crée 2 processus l(x) et g(x) en fonction d’un quantile y* qui provient d’une part des y les plus proches du minimum global.
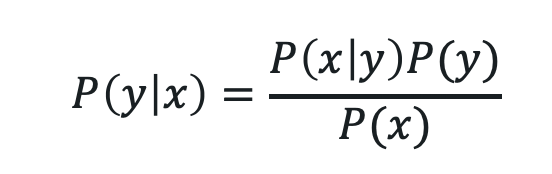
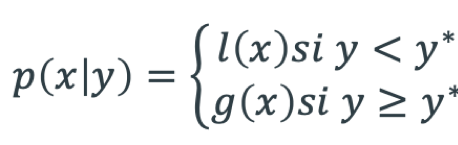
Cela permet de garder la dépendance conditionnelle. C’est cette information qui différencie le TPE du GP. Avec l’algorithme TPE, il est possible de comparer différents modèles avec des hyper-paramètres distincts. Par exemple, un random forest ne prendra pas les mêmes arguments qu’une régression logistique. Et c’est cet avantage qui nous fait choisir la librairie Hyperopt plutôt qu’une autre.
Une fois l’optimisation du modèle terminée il ne reste plus qu’à expliquer les phénomènes statistiques, mais cette phase, laissons là aux Data Scientist ;).
Conclusion
Pour conclure, l’automatisation du Machine Learning est une solution très intéressante, elle permet un gain de temps colossal en terme d’optimisation pour la résolution d’un problème, mais n’est pas magique. En effet, cette dernière ne remplacera, pour le moment, pas la connaissance ni l’intuition d’un Data Scientist. Pour autant, il permet d’identifier des pistes qui n’auraient peut-être jamais été envisagées. De plus, étant donnée l’évolution de l’intelligence artificielle et les solutions proposées par des entreprises en Machine Learning automatisé, il y a fort à croire que cette branche de la Data Science évolue vite et de façon efficace.
Références
Bergstra, James S, Bardenet, Rémi, Bengio, Yoshua, and Kégl, Balàzs. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems, pp. 2546–2554, 2011.
Eric Brochu, Vlad M. Cora and Nando de Freitas. A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning, (NIPS), 2010
M. Feurer, A. Klein, K. Eggensperger, J. Springenberg, M. Blum, and F. Hutter. Efficient and robust automated machine learning. In Neural Information Processing Systems. (NIPS), 2015.
Peter I Frazier. A tutorial on bayesian optimization. arXiv preprint arXiv:1807.02811, 2018.
Hutter, F., Hoos, H.H., Leyton-Brown, K.: Sequential model-based optimization for general algorithm configuration (extended version). Tech. Rep. TR-2010-10, University of British Columbia, Department of Computer Science (2010)