

Intelligence Artificielle et éthique : comment définir et mesurer l’équité algorithmique ?

[latexpage]
Les techniques de Machine Learning sont de plus en plus utilisées dans des contextes de prise de décision avec des implications sociétales importantes. Ces mécanismes automatisés de décision agissent sur la base de conceptions explicites ou implicites de la notion de l’équité.
Parfois, cette équité est difficile à définir et à implémenter, ou même n’est pas prise en compte dans le développement d’une solution d’intelligence artificielle.
Un des cas les plus connus montrant l’importance et la complexité de cette problématique est COMPAS (Correctional Management Profiling for Alternative Sanctions). Un logiciel d’aide à la décision utilisé aux États-Unis, déterminant la probabilité qu’un accusé puisse devenir récidiviste. Dans un article publié en 2016, ProPublica démontre un biais flagrant dans les prises de décision de COMPAS envers certaines populations en leur attribuant systématiquement un risque significativement plus élevé.
Les dérives liées à l’équité des modèles algorithmiques sont réelles et mènent la recherche à s’intéresser au problème en publiant chaque année de plus en plus de papiers scientifiques sur le sujet.
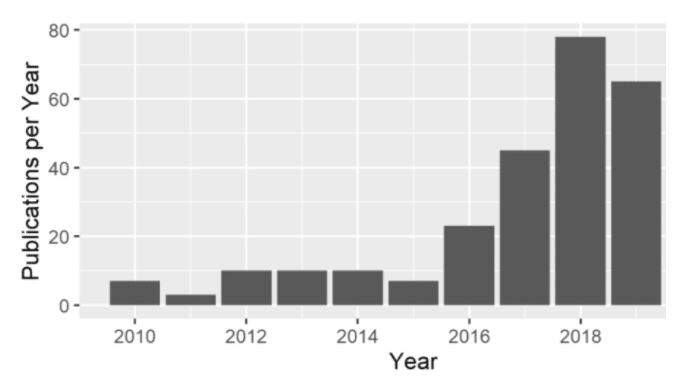
Figure 1 : Nombre de papiers scientifiques liés à l’équité en Machine Learning
Ces dérives ont mené les instances de l’Union Européenne à se pencher sur la question de la confiance des algorithmes d’IA et ainsi publier un livre blanc en février 2020 qui s’appuie essentiellement sur 7 exigences préparant une nouvelle législation sur l’utilisation de tels algorithmes. Nous vous en parlions en novembre dernier dans cet article. Parmi ces exigences, une en particulier nous intéresse ici : Diversité, non-discrimination et équité. Cette exigence pointe du doigt les biais qui existent dans les données d’entraînement d’un algorithme d’IA.
Cette volonté d’instaurer un cadre réglementaire incite les entreprises à prendre les mesures nécessaires afin de développer des algorithmes équitables, notamment celles des secteurs les plus sujets à discrimination, entre autres : médical, bancaire, judiciaire, ressources humaines.
Pour aider ces entreprises dans cette transition, Quantmetry a conçu QM Auditor, une méthodologie d’audit de modèles unique répondant à ces préoccupations :
- Limiter les biais et mieux intégrer les préoccupations éthiques dans la conception des modèles.
- Répondre aux exigences métiers clés pour l’adoption des algorithmes d’IA
- Anticiper la future réglementation sur l’IA basée sur les travaux en cours de la CNIL et de l’UE

L’objectif premier de cet article est d’introduire et sensibiliser à la complexité de la problématique de l’équité dans l’intelligence artificielle : Comment définir et quantifier les biais algorithmiques ? Comment les corriger pour assurer une solution plus juste ? Et enfin, quels sont les outils déjà existants sur le sujet ?
Comment définir l’équité algorithmique ?
Il n’existe pas aujourd’hui de définition universelle de l’équité. Dans le cadre algorithmique de la prise de décision, Mehrabi et al. donnent la définition très générale suivante qui inclut deux éléments essentiels que sont la discrimination et la distinction de groupes :
L’équité algorithmique correspond à l’absence de tout favoritisme ou discrimination à l’égard d’un individu ou d’un groupe formé par des caractéristiques innées ou acquises.
Il s’agit donc de vérifier et d’évaluer l’absence de tout tort, discrimination que pourraient engendrer les décisions prises par un algorithme. L’enjeu consiste alors à définir précisément ces biais que l’on souhaite éviter afin de mettre en place des métriques permettant de les mesurer et les corriger.
Variables protégées / sensibles
Les groupes évoqués dans la définition précédente peuvent être définis à partir de variables appelées variables protégées ou variables sensibles. Ces variables permettent de caractériser socio-culturellement chaque donnée. Par exemple, l’origine ethnique, l’orientation sexuelle, et les convictions religieuses et politiques sont des caractéristiques explicitement et légalement définies comme sensibles. Il est intéressant de noter qu’il peut exister d’autres variables non sensibles liées à ces premières indirectement (par exemple une variables corrélée à une variable sensible).
Supprimer des variables directement ou indirectement sensibles lorsque l’on entraîne un modèle de Machine Learning n’est pas nécessairement une bonne stratégie. En effet, il peut malgré tout subsister un biais algorithmique en sortie du modèle. Les supprimer peut même empirer les biais existants. En revanche, il est nécessaire de croiser les variables sensibles avec les décisions du modèle afin de pouvoir identifier les potentiels biais existants correspondant à des décisions discriminatoires prises par le modèle.
Mesures de l’équité algorithmique

Il existe une multitude d’aspects de l’équité algorithmique, chacun est associé à des mesures mathématiques permettant de le quantifier.
On pourrait imaginer constituer un ensemble de métriques formant un cadre universel permettant de déterminer les biais décisionnels introduits par un algorithme, mais en réalité, combiner certaines de ces métriques se révèle souvent difficile voire impossible. En particulier, cet article montre l’incompatibilité entre la calibration (voir ci-dessous) et les métriques cherchant à équilibrer les classes de la variable cible pour les différents groupes.
Par exemple, dans le cas COMPAS introduit plus haut, un critère particulier de l’équité a été choisi. Les discriminations identifiées sont dues à son incompatibilité avec d’autres mesures de l’équité.
Pour cet article introductif, nous présentons uniquement le cas de la classification binaire. Outre sa simplicité, il s’agit également du cas le plus étudié dans la littérature et qui trouve des applications multiples (octroi de crédit, embauche, scoring client, etc.). Afin de clarifier ces définitions, elles sont illustrées par l’exemple de l’octroi de crédit qui consiste à prédire la probabilité qu’une somme prêtée soit bien remboursée par la personne, c’est-à-dire calculer le risque associé au défaut de crédit.
On introduit au préalable les notations suivantes :
Y : classe cible que l’algorithme cherche à prédire.
S : variable représentant le score associé à la prédiction de l’algorithme (valeur entre 0 et 1).
Ŷ : décision prise par l’algorithme.
G : la variable sensible qui définit les groupes pour lesquels on souhaite mesurer les différents biais.
1. Independence
Les métriques qui cherchent à satisfaire le critère d’independence mesurent l’influence des groupes définis par la variable sensible sur la classe prédite.
Parmi ces mesures, on retrouve notamment la définition suivante :
Statistical Parity
Cette métrique évalue si chaque groupe a la même probabilité d’appartenir à la classe prédite positive :
$$Pr(\hat{Y}=1|g_i) = Pr(\hat{Y}=1|g_j)$$
Dans le cas de l’octroi de crédit, par exemple, il s’agit donc de comparer les probabilités de pouvoir rembourser un crédit (données par le modèle) selon que l’on est un homme ou une femme. Si 4 hommes et 12 femmes demandent un crédit, et si l’algorithme décide d’octroyer 8 crédits, on souhaite que 2 hommes et 6 femmes soient sélectionnés (2/4 = 6/12).
2. Separation
Les critères d’independence ne prennent pas en compte la variable cible Y.
Les définitions basées sur le critère de separation prennent en compte cette variable cible afin de mesurer l’indépendance entre le score obtenu par l’algorithme et la variable sensible conditionnée par la variable cible. Ces définitions autorisent G à être explicatives de Y, contrairement aux définitions précédentes qui émettent l’hypothèse que Y est indépendante de G. Elles prennent donc en considération une potentielle influence de la variable sensible sur la variable cible.
Equal opportunity
Cette métrique compare les taux de vrais positifs appartenant aux différents groupes :
$$Pr(\hat{Y}=1|Y=1 \& g_i) = Pr(\hat{Y}=1|Y=1 \& g_j) $$
Dans notre exemple précédent, on observe ainsi les probabilités que le modèle prédise le remboursement du crédit, selon qu’il s’agisse d’un homme ou d’une femme, sachant que la personne a effectivement remboursé la somme empruntée.
On considère un échantillon de 100 personnes contenant 50 femmes et 50 hommes. Parmi les 50 femmes, 40 ont remboursé leur crédit, et seulement 20 parmi les hommes. On imagine que parmi les personnes sélectionnées par l’algorithme, 30 personnes ont effectivement remboursé leur crédit (les autres personnes sélectionnées constituent donc des erreurs de l’algorithme). Alors l’algorithme satisfait la métrique introduite si parmi ces 30 personnes, 20 sont des femmes et 10 sont des hommes (20/40=10/20).
Cette métrique prend donc en considération l’information apportée par la variable sensible sur la variable cible, c’est à dire dans cet exemple que les hommes sont moins fiables que les femmes lors d’un octroi de crédit.
3. Sufficiency
Les métriques regroupées autour du critère de sufficiency cherchent à mesurer l’indépendance de la variable cible Y par rapport au groupe G conditionné par la variable de score S. Cette famille de métrique est incompatible avec les métriques d’équilibre des classes positives et négatives.
Test fairness ou calibration
On teste ici que la probabilité d’appartenir à la classe positive est la même pour un score donné :
$$Pr(\hat{Y}=1|S=s\&g_i) = Pr(\hat{Y}=1|S=s\&g_j)$$
Dans l’exemple précédent, on considère un score donné par le modèle, et pour toutes les personnes ayant obtenu ce score, on compare les probabilités que cette personne ait effectivement remboursé le crédit selon qu’il s’agit d’un homme ou d’une femme.
Et en pratique, comment corriger ces biais ?
L’analyse et la correction des biais algorithmiques peut s’intégrer dans les différents niveaux d’un projet de Machine Learning : pré-processing, in-processing, post-processing.
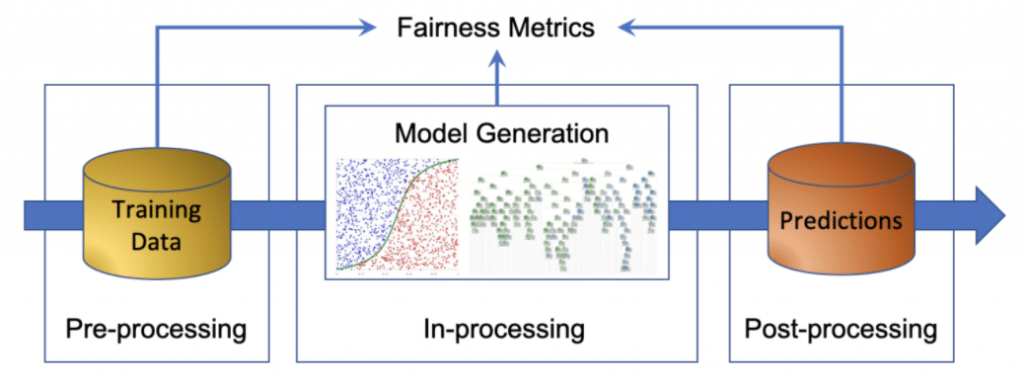
Figure 2 : Interventions possibles pour corriger un modèle biaisé
Pré-processing (données)
Cette étape permet d’analyser et de traiter la distribution des données d’entraînement du modèle (variables sensibles discriminatoires, déséquilibre de classes). L’objectif est d’appliquer des transformations sur les données en entrée pour mitiger les biais et les rendre plus équitables.
Ce genre de transformations risque d’impacter fortement l’interprétabilité du modèle. Par exemple, en projetant les données sur un espace orthogonal à la variable sensible, on peut gagner en équité mais perdre le sens des variables indépendantes.
In-processing (modélisation/optimisation)
Dans cette étape, les principaux traitements consistent à définir des métriques d’équité à optimiser conjointement avec les métriques de performance pendant l’entraînement du modèle. L’implémentation et l’exploitation de ces méthodes doivent donc être portées par les Data Scientists/Machine Learning Engineers.
Post-processing (résultats)
L’objectif de cette étape est d’analyser et de transformer les résultats du modèle pour identifier et traiter les potentiels biais liés à des variables protégées ou à des sous-groupes liés à ces variables.
Comme les traitements de pré-processing, les méthodes de post-processing n’exigent pas la transparence du modèle et peuvent le traiter comme une boîte noire. Cela permet notamment d’utiliser les librairies de Machine Learning directement sans modification explicite. En revanche, elles peuvent rendre le modèle moins interprétable.
À rendre un modèle équitable, on peut en oublier son interprétabilité
On présente dans le tableau ci-dessous des exemples de méthodes de correction communément utilisées :
| Méthode | Description | Phase |
| Adversarial Learning | On entraîne un adversaire à déterminer si le modèle est équitable, et lorsque ce n’est pas le cas, le retour obtenu est utilisé pour améliorer le modèle. | Pre-processing |
| In-processing | ||
| Reweighing | Cette approche n’altère pas les données mais attribue uniquement des poids différents aux données d’entraînement. | Pre-processing |
| In-processing | ||
| Transformation | Ces approches visent, à travers l’application de transformations sur les données d’entraînement, à apprendre une nouvelle représentation ayant de meilleures garanties vis-à-vis de l’équité. | Pre-processing |
| Post-processing | ||
| Regularization/Constrained Optimization | Il s’agit d’ajouter des pénalités ou des contraintes dans le processus d’apprentissage pour pénaliser les iniquités. | In-processing |
| Post-processing | ||
| Calibration | Consiste à s’assurer de l’équilibre entre la distribution des données et la distribution des prédictions (la proportion de prédictions positives est égale à la proportion d’exemples positifs), et dans le contexte de l’équité, le même principe est appliqué également à tous les sous-groupes dans les données | Post-processing |
| Thresholding | Cherche, pour le classifieur, des seuils de décision garantissant un équilibre entre les taux des vrais et des faux positifs pour l’ensemble des sous-groupes. | Post-processing |
Quels outils à notre disposition ?
Chez Quantmetry nous avons pour habitude d’utiliser des solutions open-source pour répondre aux problématiques de nos clients. Cela nous permet de facilement nous adapter aux exigences des systèmes d’information tout en pouvant contribuer et partager l’état de l’art en intelligence artificielle. De grandes entreprises, non étrangères à l’intelligence artificielle, (IBM, Microsoft, Google) ont chacune leur initiative liée à l’intelligibilité des algorithmes, l’éthique, la robustesse, l’équité.
Trusted AI d’IBM promeut la construction de services d’IA de confiance et gravite autour de trois packages : AI Explainability 360, AI Adversarial Robustness 360 et AI FactSheets 360. Microsoft quant à lui a fondé le groupe FATE (Fairness, Accountability, Transparency, Ethics), composé principalement de chercheurs, pour partager leurs connaissances à la fois innovantes et éthiques. Enfin, Google, avec son écosystème PAIR (People + AI Research), permet de regrouper des guides, articles et des événements pour participer à la conception d’IA mettant l’Homme au cœur du processus.
Ces initiatives sont accompagnées d’articles, de papiers scientifiques et de packages python dont certains traitent l’équité et les biais algorithmiques.
| Package Python | Contenu | Commentaire |
| AI Fairness 360 | On y retrouve l’implémentation des métriques citées plus haut ainsi que certaines méthodes de correction. Un démonstrateur est disponible pour se faire une idée de l’impact d’une correction de biais sur les performances et le caractère inéquitable d’un modèle prédictif. Les données d’exemples sont issus de Compas, d’un modèle de scoring de crédit ainsi que d’un modèle de prédiction de salaire. | Propose le plus grand contenu en métriques et algorithmes correctifs |
| Essaye de suivre le paradigme scikit-learn, en cours de développement. | ||
| Fairlearn | Ce package se concentre sur un nombre plus restreint de métriques mais met à disposition un dashboard afin de visualiser à quel point les groupes sensibles sont impactés négativement par un modèle, il est également possible de comparer plusieurs modèles (avant/après correction) avec les métriques d’équité associées. | Dashboard de comparaison d’équité et de performance |
| Suit le paradigme Scikit-Learn | ||
| Projet Github le plus actif des quatre | ||
| Fairness Indicators / Tensorflow Constrained Optimization | Ces deux bibliothèques constituent un ensemble pour mesurer l’équité d’un modèle ainsi que soumettre une contrainte d’optimisation dans l’entraînement du modèle pour satisfaire une contrainte d’équité. | Orienté pour des modèles Tensorflow |
| La correction du modèle est plus compliquée à mettre en place |
Ces librairies sont un très bon socle pour se familiariser avec les métriques d’équités et les méthodes correctives. Que l’on suive le paradigme Scikit-learn ou Tensorflow, une solution s’offre à nous. AI Fairness 360 et Fairlearn restent néanmoins plus complets que les solutions Google.
Conclusion
Les techniques de Machine Learning étant de plus en plus utilisées dans des contextes de prise de décision importantes, il devient nécessaire de s’assurer que cela ne génère pas d’impact imprévu
avec des implications sociétales négatives. Celles-ci doivent être spécifiées au cours du projet afin d’identifier les biais existants dans les données pour en déduire les bons indicateurs.
Une multitude de méthodes existent pour corriger ces biais et peuvent être intégrées dans les différentes étapes d’un projet de Machine Learning. Le choix de ces méthodes dépend, entre autres, des métriques choisies et des contraintes d’interprétabilité. Ces métriques et méthodes de correction peuvent d’ors et déjà être retrouvées dans des librairies python open-source.
Néanmoins, il n’existe pas de consensus scientifique et technologique sur le choix du bon algorithme de correction en fonction du cas d’usage métier, tout en gardant un bon compromis équité/performance, même si certains s’y sont déjà essayé.
Références
[1] FAIRNESS IN MACHINE LEARNING: A SURVEY
[2] https://github.com/wikistat/Fair-ML-4-Ethical-AI#annexe-extraits-du-guide-des-experts-de-la-ce-pour-une-ia-digne-de-confiance
[3] https://papers.nips.cc/paper/2020/file/7ec2442aa04c157590b2fa1a7d093a33-Paper.p
[4] https://arxiv.org/abs/1609.05807
[5] https://arxiv.org/abs/1908.09635
[6] https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_fr.pdf
[7] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing