

Introduire des tests à un pipeline de données

C’est assez répandu de développer un pipeline de Machine Learning indépendamment des conditions d’utilisation dans l’environnement de production. Plusieurs paramètres entrent en jeu, mais dans cet article, on se limite à un seul : la donnée. En particulier, le cas où les données changent “légèrement” d’un environnement à l’autre.
Mais qu’est-ce qu’un pipeline de machine learning ? La définition n’est pas unique et voici la mienne : c’est un ensemble de traitements informatiques qui traite et achemine des données afin d’exploiter un modèle de machine learning.
Pour illustrer cette définition, je vais utiliser ce pipeline ci-dessous. La partie modèle de machine learning est représentée par la brique du milieu. À gauche, toutes les étapes de préparation et nettoyage des données, et à droite, la redistribution des résultats (stockage, utilisation, monitoring…).
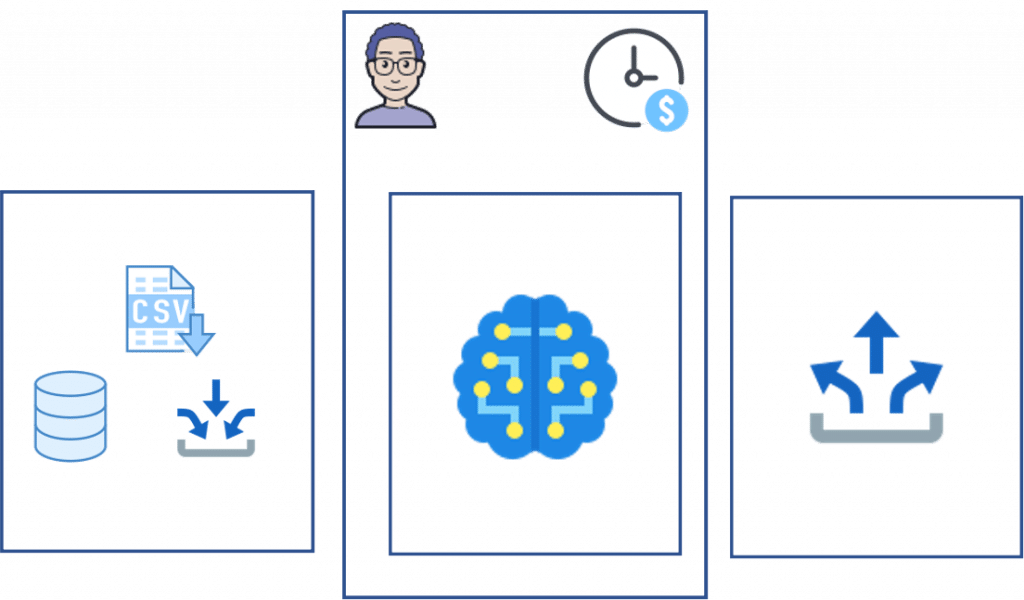
En tant que développeur vous êtes amené à mettre en place la partie modèle ML. Votre modèle doit utiliser une information dont le format est inconsistant, suite à un changement d’environnement de travail entre la sandbox et la production ou bien suite à une mise à jour. La différence est légère au sens humain, mais dans un sens informatique, c’est une donnée complètement différente.

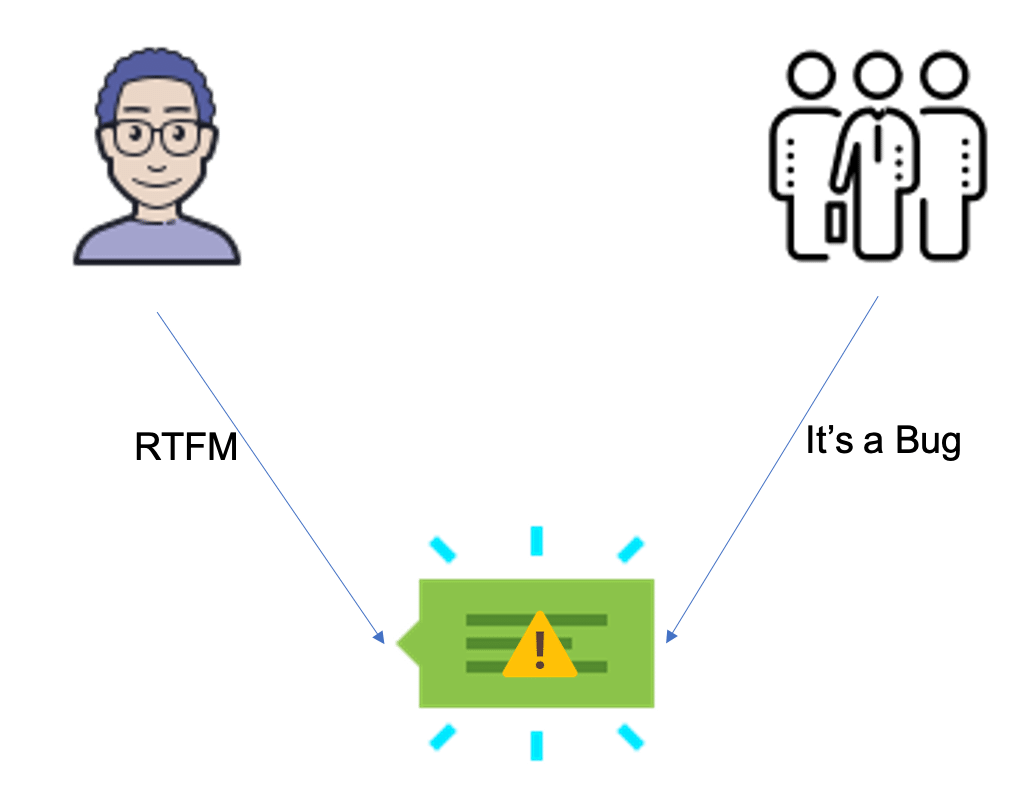
Cet exemple représente la différence entre l’équipe technique qui adopte une vision informatique rigoureuse et le business qui est moins sensible à ces détails.
Quelle que soit l’interprétation, l’origine du problème est la même. Chaque pipeline de ML commence par une donnée, la vitesse avec laquelle on arrive à entraîner et prédire n’est plus importante si vous avez utilisé les mauvaises données. C’est le fameux principe du “garbage in, garbage out”.
La donnée est un élément fondamental dans un pipeline de machine learning, un pipeline qui ne gère pas les mauvaises données est un pipeline incomplet.

Comment peut-on compléter ce pipeline ?
Si on souhaite compléter ce manque au niveau du modèle ML, personnellement, j’ai une préférence pour la solution du filtre. Cette approche ressemble à un circuit de traitement de signal, où différents filtres sont utilisés pour éliminer un bruit ou bien le corriger.
Cette solution est facile à mettre en place, car elle vient s’ajouter à la pipeline sans modifier l’existant.
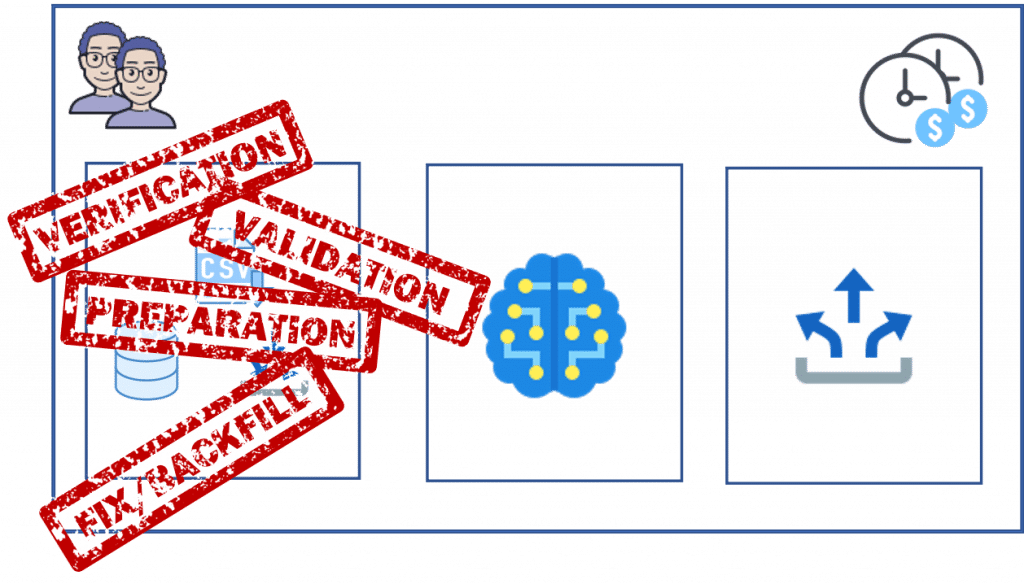
Une deuxième approche consiste à gérer les mauvaises données à la source, certes, plus propre et plus efficace s’il y a plusieurs briques de machine learning. L’inconvénient de cette approche est son coût :
– Les technologies utilisées dans la première et la deuxième brique sont différentes. La première se focalise sur le stockage et la préparation de données, tandis que la deuxième analyse et calcule.
– Le périmètre des données est plus large (volumétrie et diversité).
– Il est possible que la data préparation soit la responsabilité d’une autre équipe.
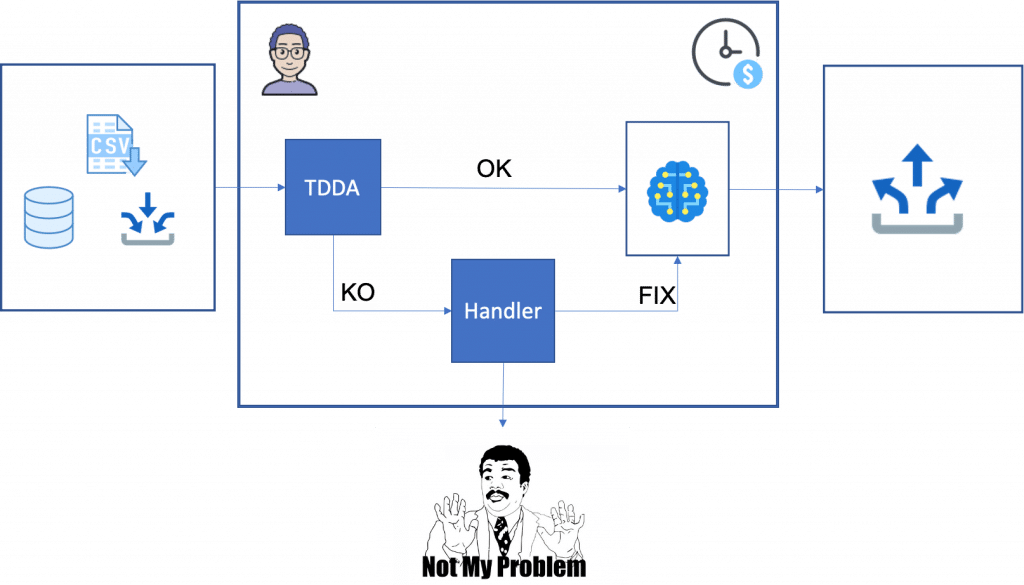
L’intérêt de cet article est de mettre en lumière un outil “TDDA” visible sur la figure ci-dessus. Grâce à cet outil, il est possible de créer facilement des filtres sur les données. Selon la manière dont il est utilisé, on peut mettre en place des “tests unitaires” sans vraiment les écrire. Je vous laisse avec ce guide pratique qui vous aidera à prendre en main cet outil.
