

Kaggle : COVID-19 Open Research Dataset Challenge (CORD-19)
✍Luis Blanche / Reading time: 5 min
A Doc2Vec model to match tasks descriptions to articles
Introduction
As a response to the COVID-19 crisis, Kaggle is hosting a challenge sponsored by AI2, CZI, MSR, Georgetown, NIH & The White House . The dataset is a corpus of around 30 000 scientific articles related to the virus. The challenge is organised around tasks that are stated as “What is known about transmission, incubation, and environmental stability?” for instance. Every task is explained with a small text detailing what information is needed.
At quantmetry we decided to spend some time on this challenge, here is what we got so far.
Methodology
The notebook on Kaggle : https://www.kaggle.com/luisblanche/cord-19-match-articles-to-tasks-w-doc2vec
The contribution presented in this article can potentially be used for each of the tasks. Its main goal is to match the aforementioned tasks descriptions to articles.
If you want to analyse a corpus, you will probably want to apply tasks that are suited for numeric data like clustering. This notebooks presents a way to translate long texts into vectors using a technique called document embedding.
A very common task in NLP is to train word embeddings. Word2Vec is a famous algorithm for this task. You can find a very thorough explanation of this algorithm in this amazing blog post.
The main idea behind Word2Vec is beautifully resumed in this quote by John Rupert Firth :
You shall know a word by the company it keeps
Word2Vec authors came up with this very innovative idea where you train a neural network on a task (finding a word given its surrounding words – or the reverse : finding surrounding words given a word) but you are not interested in the output of this task, rather in the weights of the network’s hidden layer. which will be used to form the word vectors.
Doc2Vec fixes a higher objective which is to have one vector for a sequence of words.
The first idea that comes to mind to solve this task would be to just take the mean vector of the Word2Vec vectors of each word in the sequence. The Doc2Vec authors had a smarter idea (see the article here).
It follows the same principle as Word2Vec: training a network on a synthetic task and retrieving the doc vectors as the weights of the hidden layer. However the paragraph matrix to be learnt (1 vector per paragraph) is added along the words vectors (see figure 1).
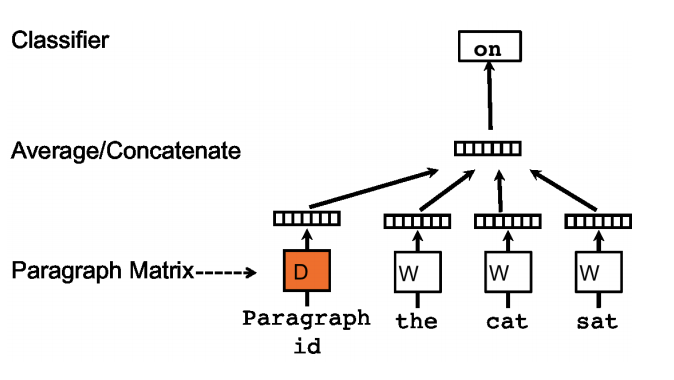
Distributed Memory Model of Paragraph Vectors (PV-DM) – See the original article for the alternative implementation (Distributed Bag of Words)
When you train this network on the synthetic task, the weights matrix D will evolve and you will get each column as a paragraph vector.
Implementation
Fortunately the famous NLP library Gensim comes with an optimized class to train the Doc2Vec model. We used another Kaggler’s work for the preprocessing. This allows us to easily get a text corpus to train our Doc2Vec model on.
After several experiments, we realised that it seemed more efficient to train the model on the abstracts, because the size of the abstract being closer to our task definitions. When the model was trained on the full texts, we would alway get the same text matched to all the tasks. Lesson Learned : Size of text matters when using Doc2Vec.
Once the Doc2Vec model is trained, it can be used to embed tasks descriptions into the same vector space as the abstracts. This allows us to use classical numeric methods, in particular to compute distances between abstracts and tasks.
The notebook shows how to retrieve the nearest neighbours articles for each task using the ball tree algorithm implemented in Scikit-Learn.
Example
The closest articles to each articles can then be printed out. For instance, here is an example output for Task 1:
Task = What is known about transmission, incubation, and environmental stability? Text index = 11633 Distance to bullet = 3.242 Title: Dynamic Transmission Modeling: A Report of the ISPOR-SMDM Modeling Good Research Practices Task Force-5 Abstract Extract: The transmissible nature of communicable diseases is what sets them apart from other diseases modeled by health economists. The probability of a susceptible individual becoming infected at a Text index = 15628 Distance to bullet = 3.274 Title: A Review and Update on Waterborne Viral Diseases Associated with Swimming Pools Abstract Extract: Infectious agents, including bacteria, viruses, protozoa, and molds, may threaten the health of swimming pool bathers. Viruses are a major cause of recreationally-associated waterborne disea
In conclusion, this methodology is like building a search engine for the articles. Indeed you could embed any text you want using the trained Doc2Vec model. It could also be used to find similar articles. For a state of the art search engine implementation you can check this notebook by a fellow kaggler.
Visualisation
The abstracts and the tasks are now represented by vectors of size 100. As a result, they can be visualised in 3D using Principal Component Analysis (PCA).
Using yellowbrick, a machine learning visualisation library, we find the optimal number of clusters for a KMeans clustering on the abstracts vectors.
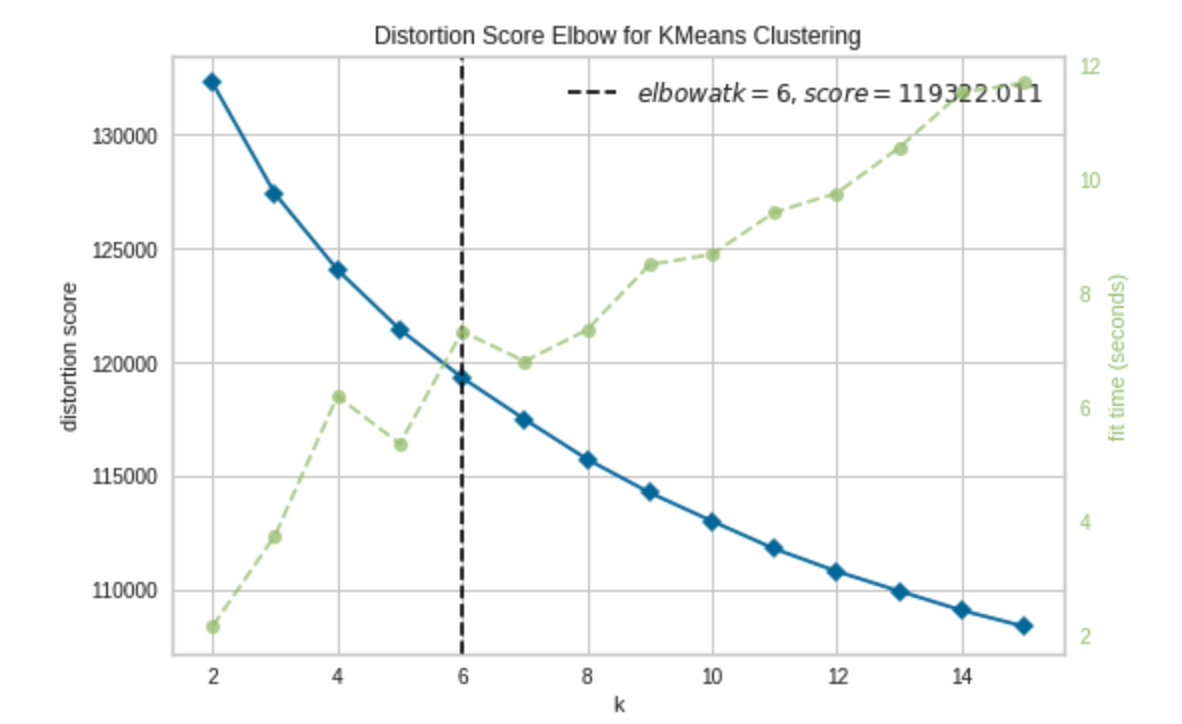
Elbow Curve for optimal number of KMeans clusters – the green curve represents the fit time
Following the results on this figure, we fit a KMeans on 6 clusters on the abstract vectors.
After that we can fit a PCA on the abstracts to reduce to 3 dimensions and use a 3D scatterplot to visualise the clusters. The PCA reduced task description vectors were also added in black.
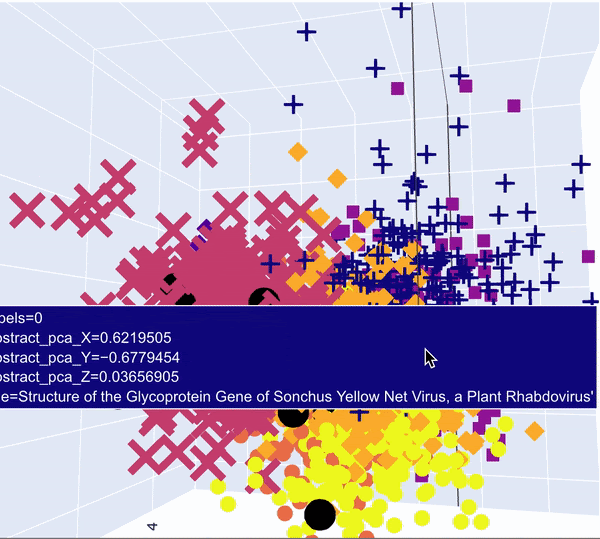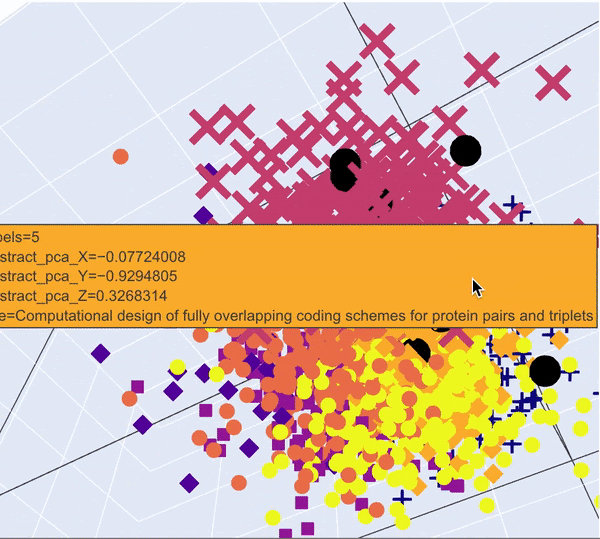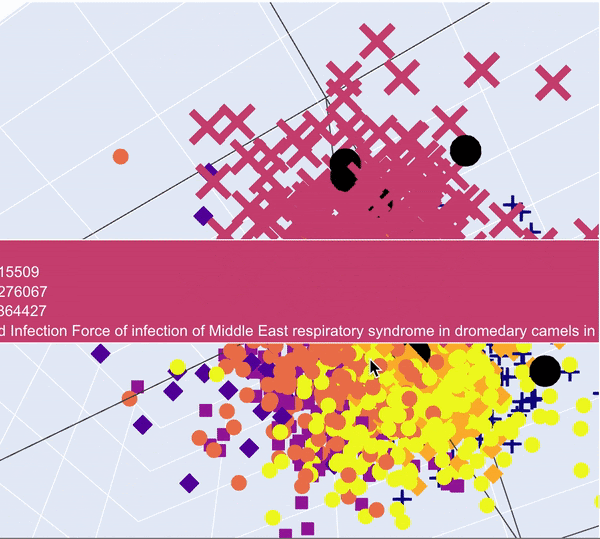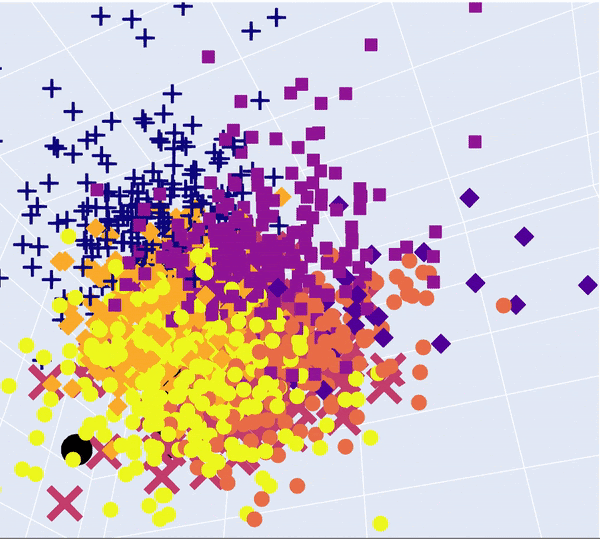
PCA 3D Visualisation of articles. Tasks are in big black dots and are concentrated in different clusters
What we can see is that some tasks seem to fall in the same clusters, which means they are semantically close.
It also seems that some tasks fall out of the clusters. Once again it might be due to the inconsistencies between the lengths of the tasks texts and the abstracts on which the Doc2Vec model was trained.
Conclusion
This article explains and shows how to train a Doc2Vec model on a text corpus. It then demonstrates how the obtained document vectors can be used to conduct meaningful analyses like search or clustering.
Recently language models like BERT have been under the spotlight for various NLP tasks, however, long sequences representation using this kind of models is still an open research field.
Regarding the clustering and dimensionality reduction techniques like T-SNE or UMAP could have been used as well but they are harder to tune than PCA and also require more computing.
Some work on the formulation of the tasks could also improve the results. For instance task 1 description does not contain the words « coronavirus » or « COVID ».
