

Le fléau de la dimension : techniques de sélection de variables

La révolution Big Data a mené la communauté scientifique à se poser des questions sur les infrastructures et les architectures capable de traiter de gros volumes de données variées. Ainsi, de nombreuses solutions professionnelles et open source apparaissent sur le marché facilitant le traitement et l’analyse de données en grande dimension.
Cependant, quand vient l’analyse de données, le Big Data soulève des problèmes théoriques et mathématiques qu’il faut également chercher à résoudre. De nombreux algorithmes statistiques classiques sont mis à mal par un passage à l’échelle et des problèmes de robustesse et de stabilité se posent.
Plus spécifiquement, nous allons nous intéresser à un phénomène qui est observé lorsque la dimension de l’espace des variables (c’est-à-dire le nombre de variables) grandit si vite que les données qu’il inclut deviennent éparses et éloignées. Les méthodes statistiques usuelles auront tendance dans ces situations à donner des résultats faussées et biaisées : c’est le « fléau de la dimension ».
Si la question se pose plus que jamais à l’heure du Big Data, le fléau de la dimension est un concept introduit en 1961 par Bellman (Curse of Dimensionality). Encore aujourd’hui il pose des problèmes théoriques et pratiques et fait l’objet de nombreux travaux et nombreuses réflexions au sein de la communauté scientifique.
Une solution à ce fléau consiste à faire appel à des méthodes de réduction de dimension. On distingue souvent dans cette catégorie les méthodes par extraction de variables (comme l’Analyse en Composante Principale) des méthodes par sélection de variable. Cet article a pour vocation de faire un rapide état de l’art des méthodes de réduction de dimension par sélection de variable. Nous détaillerons les enjeux de la sélection de variable avant de présenter la théorie derrière certaines des méthodes utilisées. La dernière partie se focalise sur l’utilisation pratique de ces méthodes, notamment grâce au logiciel R.
LES ENJEUX DE LA SÉLECTION DE VARIABLE EN GRANDE DIMENSION
L’augmentation de l’espace de représentation des données pose des problèmes de comparaison et d’interprétation des écarts entre ces données. En effet, l’augmentation de la dimension à tendance à rendre les données plus éparses et donc à fausser les manières traditionnelles d’analyser les données. Toutes les méthodes statistiques qui nécessitent le principe de significativité statistique sont impactées par le manque de densité des données dans l’espace.
Egalement, classer des données correspond souvent à un regroupement d’individus ayant des propriétés similaires. En grande dimension, les dissimilarités s’accentuent au même titre que les individus s’écartent les uns des autres. On perd ainsi la capacité des méthodes à trouver des individus se ressemblant.
La réduction de dimension semble être un enjeu majeur pour faire face à un phénomène encore peu maitrisé de la communauté scientifique mais de plus en plus présents dans les applications. En premier lieu la biostatistique (avec la génomique), la finance ou encore le traitement de l’image font de plus en plus souvent face au fléau de la dimension.
Ainsi, le fléau de la dimension nécessite des techniques de réduction de dimension afin de pouvoir représenter les données dans un espace adéquat et plus facilement interprétable par les distances usuelles et les algorithmes d’analyse de données classiques.
LES DIFFÉRENTES APPROCHES DE SÉLECTION DE VARIABLE POUR LA RÉDUCTION DE DIMENSION
LES MODÈLES DE RÉGRESSION PÉNALISÉS
L’approche par modèle pénalisé permet de régler le problème de la multicolinéarité entre les variables dans les situations où toutes les variables sont gardées. Nous allons voir que certaines pénalisations sont très avantageuses dans les cas habituellement difficiles à traiter lorsque le nombre de variable est supérieur au nombre d’individus
Considérons dans la suite une méthode de classification binaire. Notons Y la variable cible qui peut prendre pour valeurs 0 ou 1, et X le dataset des variables explicatives de taille n x p.
Les méthodes de régressions pénalisées permettent de calculer le classifieur et d’effectuer la sélection de variable en même temps. L’idée est de trouver l’estimateur β qui minimise une fonction objectif pénalisée :
Où représente le dataset des
Le paramètre lambda λ de l’équation permet de trouver un compromis entre la complexité du modèle et son rapprochement aux données. Un λ qui tend vers 0 entrainera une plus grande complexité et donc des
prédictions potentiellement mauvaise. A l’inverse, un λ qui tend vers l’infini donne un modèle plus général mais qui peut oublier de l’information dans les données. Le cas particulier
La fonction pen() désigne la fonction de pénalité. Une fonction de pénalité correctement paramétrée et calculée permettra d’avoir des estimations de β strictement égales à 0. C’est ainsi qu’on effectue la sélection des variables. Il existe plusieurs types de fonctions de pénalisations. Nous allons en détailler certaines des plus utilisées dans la suite.
RIDGE
La regression Ridge correspond à une pénalisation de type norme L²
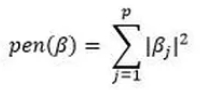
Cette fonction a la particularité de ne pas annuler les coefficients β mais plus de les réduire et de les faire tendre vers 0. On parle de « shrinkage » des coefficients.
LASSO
La régression LASSO (Least Absolute Selection and Shrinkage Operator), introduite par Robert Tibshirani, est une régression pénalisée par la norme L¹ des coefficients β. On définit le critère de pénalisation par :
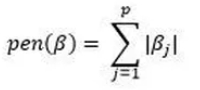
Cette pénalisation est recommandée dans les cas en grande dimension de variable, c’est-à-dire lorsque p>n
Cependant, la sélection n’est pas adéquate dans le cas où les variables non pertinentes sont fortement corrélées à celles qui le sont.
La principale différence entre la régression Ridge et la régression LASSO se fait au niveau de la parcimonie (c’est-à-dire la tendance à sélectionner des modèles moins complexes). En effet, plus la pénalisation augmente via le coefficient λ plus la fonction en L² aura tendance à réduire les coefficient sans les annuler. A l’inverse une pénalisation L¹ annulera beaucoup plus de coefficients, sélectionnant des modèles plus parcimonieux.
ELASTIC NET
Si la parcimonie est un concept fondamental en statistique, il peut être intéressant de profiter de la pénalisation Ridge en gardant les capacités parcimonieuses de la régression LASSO. C’est ici qu’entre en jeu la régression Elastic Net qui combine les deux méthodes de pénalisation présentées plus haut. Ainsi, la formule de minimisation du risque empirique devient :
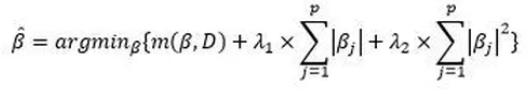
Cette méthode a l’avantage de pallier au problème de la sélection LASSO dans les cas de fortes corrélations de certaines variables. Cependant, la régression Elastic Net peut pêcher dans la double procédure de shrinkage qui peut mener à de faibles performances en prédiction. Les auteurs préconisent un redressement des coefficients estimés en les multipliant par (1 + λ_2) pour résoudre le problème.
D’AUTRES FORMES DE PÉNALISATION
Il existe de nombreuses sélections de variable alternatives à ces trois méthodes, parmi lesquelles :
-
La sélection Adaptive LASSO qui repondère les pénalisations des variables.
-
La sélection Group LASSO qui permet de sélectionner des groupes de variables définis en amont. Elle s’utilise dans les cas où des groupes de variables sont pertinents ensemble et ne doivent pas être séparés.
-
La sélection Fused LASSO qui pénalise à la fois les coefficients et leur différence successive. Elle est utile dans les cas en grande dimension où l’on peut parler d’ordre sur les variables.
SÉLECTION DE VARIABLE PAR ARBRE RÉGULARISÉ
Les arbres régularisés sont utilisés comme méthode de sélection de variable dans les classifieurs par arbre. Ils peuvent ainsi se généraliser à toute méthode statistique utilisant des arbres de décision ou de régression, y compris les forêts aléatoires ou le gradient boosting. La sélection dans les méthodes par arbre permet d’éviter les problèmes de redondances. L’idée est d’éviter, lors de la sélection de la variable optimale pour la scission d’un nœud, de choisir une variable qui soit trop corrélée à celle sélectionnée dans la scission précédente.
Certaines méthodes de sélection de variable permettent déjà une sélection d’un sous-échantillon de K variables à partir de la mesure d’importance d’une forêt aléatoire. Cependant, la redondance possible dans les variables fait que le sous échantillon de variables ne peut pas être garanti comme la meilleure combinaison de K variables parmi les p disponibles. On trouve encore d’autres méthodes éliminant à chaque itération les variables les moins importantes au sens du score d’importance défini dans l’algorithme. Ces méthode peuvent mener à l’élimination de variables utiles mais peu importantes au moment de leur suppression et ne semble donc pas être une approche viable.
REGULARIZED RANDOM FORESTS
Récemment, le concept de Regularized Random Forest a été mis en avant comme permettant une sélection de variable efficace au sein d’une forêt aléatoire. La validité du sous-échantillon de features est vérifiée à chaque nœud de chaque arbre.
Notons gain(X_j) la mesure d’évaluation calculée pour la variable X_j
Dans le cas d’un arbre traditionnel, la scission à un nœud se fait en maximisant cette fonction. Notons maintenant F l’ensemble des variables utilisées dans le noeud précédent. L’idée de la pénalisation est d’éviter de sélectionner une nouvelle variable X_j C’est à dire n’appartenant par à F. On note alors :
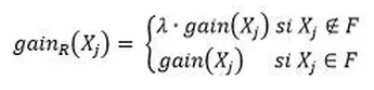
où λ ∈ [0,1]
Comme pour la régression pénalisée, plus le coefficient λ est faible, plus la pénalisation est grande.
Ainsi une nouvelle variable est ajoutée à F uniquement si elle ajoute suffisamment d’information prédictive à Y. Dans le cadre d’une forêt aléatoire, F représente l’ensemble des variables utilisées dans la scission précédente à la fois de l’arbre courant, mais également de tous les arbres depuis le début de l’algorithme.
GUIDED REGULARIZED RANDOM FORESTS
Afin d’alléger les calculs effectués à chaque nœud et pour des temps de calcul plus optimisée, les Guided Regularized Random Forests ont été proposées. Elles utilisent l’importance calculées sur un Random Forest classique en amont pour « guider » la pénalité λ à chaque calcul du gain d’information.
Ainsi, pour chaque variable X_j , on calcule le λ_i associé
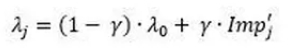
où
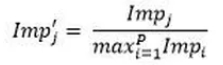
Ici les Imp_j sont les scores d’importance de chaque X_j calculé à partir d’un random forest classique.
APPLICATION
Les méthodes présentées plus haut sont toutes implémentées et utilisables depuis le logiciel R. Voici une rapide présentation de leur utilisation.
LES RÉGRESSIONS PÉNALISÉES
Partons d’un dataset créé spécialement pour l’exemple. Les données contiennent des variables colinéaires du fait de leur création par combinaisons linéaires. D’autres variables sont indépendantes et apportent de l’information sur la cible Y. Nous allons donc voir l’intérêt de la sélection de variable en présence de variables corrélées. Ce dataset est construit pour l’exemple mais l’utilité de la sélection de variable se généralise dans les cas de très grande dimension.

Un des packages référence pour la régression pénalisée est le package glmnet. Il implémente les méthodes de sélection de variable présentées plus haut.
Afin de comparer les résultats avec ceux d’une régression linéaire simple, on peut lancer comme baseline un simple lm().

On peut maintenant tester les 3 régressions pénalisées présentées plus haute.

On observe bien que la sélection LASSO mène au modèle le plus parcimonieux alors que la sélection Ridge a plutôt tendance à faire tendre les coefficients vers 0 sans les annuler.
La sélection Elastic Net est un intermédiaire entre les deux puisqu’elle annule certains coefficients et en réduit d’autres. On peut facilement jouer avec le paramètre alpha pour donner plus d’importance à la sélection LASSO ou Ridge dans l’équation.
Il est possible d’observer l’évolution du « shrinkage » des coefficients en fonction de la valeur de λ avec le graphique suivant :

Enfin, d’autres packages R existent, notamment pour les formes plus spécialisées de sélections par pénalisation. On citera notamment le package lqa qui implémente, en plus des méthodes de pénalisations LASSO, Ridge et Elastic Net, les sélections Adaptive LASSO ou encore Fused LASSO.
LES REGULARIZED RANDOM FORESTS
Une implémentation des Regularized Random Forests et des Guided Regularized Random Forests existe dans le package RRF. La fonction RRF fonction de la même manière que la fonction randomForest du package du même nom. Il existe en plus un paramètre falgReg qui vaut 0 pour une forêt aléatoire classique et 1 pour une forêt aléatoire pénalisée.
Le paramètre coefReg permet d’implémenter les Guided Redularized Random Forests. Il s’agit du coefficient de régularisation. Il prend pour valeur soit un scalaire, correspondant au cas où toutes les variables ont le même coefficient, soit un vecteur de la taille du nombre de prédicteurs.
Pour conclure, la sélection de variable est un enjeu majeur pour contourner le problème du fléau de la dimension. Nous avons évoqué certaines méthodes de régression pénalisées ainsi qu’une méthode de régularisation d’arbre. Cependant, il existe de nombreuses autres méthodes, soit basées sur une information obtenue a priori sur les variables (théorie de l’information, entropie, …), soit basées sur des modélisations pénalisées.
La subtilité et le rôle du data scientist consiste à comparer ces méthodes et à sélectionner la plus adéquate en fonction du cadre, des données et des méthodes de modélisation choisies.
