

Le football du futur : couleur des chaussures, Big Data et stratégie

Le football est probablement le sport le plus diffusé à travers l’Europe. Avec 380 matchs de Ligue 1 auxquels s’ajoutent les matchs de coupes, de championnats internationaux et les matchs de sélections nationales, ce sont près de 500 matchs diffusés par an (soit plus de 750 heures). Soit 15 000 heures de vidéo pour les 20 dernières années en France, et bien plus lorsqu’on ajoute les championnats étrangers : Angleterre, Allemagne, Espagne et Italie notamment pour ne citer que les grands championnats européens. La masse de données que représentent ces vidéos est donc significative. Et cela, les entraîneurs l’ont déjà compris depuis longtemps. Ce sont aujourd’hui de véritables équipes d’analystes vidéo qui s’attèlent à déceler les points forts et faibles des équipes adverses, à axer les stratégies de jeu et à affiner les recommandations pour les joueurs (Opta Sports par exemple). Sans rentrer dans les détails techniques, la suite de cet article propose une vision globale d’une manière d’automatiser le processus d’analyse vidéo des matchs de football. Enfilez vos crampons et suivez-nous jusqu’en Finale !
Football et Big Data, un mariage possible ?
Alors que modèles prédictifs et Big Data sont utilisés en production dans de nombreux domaines, depuis le marketing prescriptif jusqu’à la maintenance prédictive, il semble tout à fait envisageable d’en utiliser les concepts pour l’analyse de dizaines de milliers d’heures de matchs passés. Si on enregistre pour un grand nombre de matchs les positions de chaque joueur et du ballon sur le terrain ainsi que leurs interactions (passes, tirs, interceptions), il serait possible:
o De réaliser des études statistiques pour des publics divers : l’entraîneur de l’équipe, la presse spécialisée, le grand public, le monde des paris sportifs…
o De créer des modèles pouvant répondre à la question suivante : Avec telles positions de joueurs et de ballon, quelle action a le plus de chance d’être un succès (passe réussie, dribble, tir etc.) ? Avec quel potentiel pour aboutir in fine à un but ?
Comment arriver à enregistrer ces positions ? Deux types de solutions se dessinent : (1) Les solutions intégrant l’utilisation d’un tracking device porté par les joueurs (exemples de solutions: Catapult Sports, Benfica) et (2) les solutions détectant les joueurs à partir d’images vidéos de caméras fixes (par exemple les solutions proposées par la Technische Universität München ou Sentioscope). Seulement, il y a un léger soucis : ces solutions sont tout à fait adaptées pour décortiquer les phases d’entraînement (solutions avec tracking device) ou les matchs à domicile (chaque club est libre d’installer son système avec caméras fixes dans son stade). Par contre, elles ne peuvent pas être utilisées sur des images historiques issues de diffusions télévisées. Détecter automatiquement les joueurs à partir de ces vidéos est un exercice qui présente plusieurs difficultés majeures, comme des angles de prise de vue qui varient rapidement (selon la sensibilité du réalisateur et les déplacements du ballon) ou des moyens techniques variables.
Utiliser la masse historique de données télévisuelles implique donc l’automatisation d’un processus spécifique de traitement et d’analyse des images :
1. Détection de la typologie de la captation des images
2. Détection des joueurs
3. Identification des joueurs
4. Détection du ballon
5. Identification des limites du terrain et calcul de la position des joueurs et du ballon 6. Etude des interactions entre ballon et joueurs.
Bref, pour arriver à une base de données historiques des positions de joueurs et ballon et être en mesure de traiter en temps réel les prochains matchs, c’est tout un programme !
Détection de la typologie de la captation des images
Cette étape consiste à évaluer quelles images peuvent être utilisées pour détecter les joueurs et leur position : caméra plan large vs. détails d’une action, pages de publicité, images du public, … Plusieurs solutions peuvent être envisagées, par exemple un algorithme de classification à partir de l’histogramme des couleurs des images tel que décrit ci-dessous. Chaque pixel des images de la vidéo contient un valeur d’intensité pour chacune les trois bandes : Rouge, Vert et Bleu. En étudiant la distribution de ces valeurs pour une image complète, on obtient une sorte de signature colorimétrique de l’image : l’histogramme des couleurs, qui peut être utilisée pour une répondre au problème de classification suivant: Quelles sont les images représentant le terrain en plan large, qui permettent de visualiser la position des joueurs sur le terrain? Dans notre cas, on s’attendra à ce que le vues en plan large aient un nombre de pixels “verts” bien supérieur aux autres types d’images.
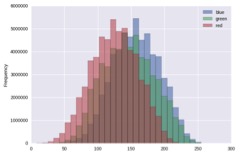
Exemple d’histogramme des couleurs d’une image.
Evaluation de la topologie des images vidéo de football. Détections des images en plan large permettant la détection des joueurs et du ballon. Dans cet exemple, seule la première partie de la vidéo peut être utilisée pour détecter les positions des joueurs et ballon. Le gros pas sur le gardien de but n’apport pas d’information. Quantmetry 2017, travaux de développement internes.
Détection des joueurs
Un joueur de foot est un objet mobile sur un fond vert… en termes d’images vidéos bien entendu. Il s’agit en fait d’amas de pixels variables se déplaçant sur un fond plus ou moins uni, analogue à celui -bien célèbre- du présentateur météo. Et pour détecter les joueurs il suffit de compter ces amas. C’est une première approche simpliste évidemment, mais qui donne des résultats assez intéressants… à condition que les joueurs ne s’agglutinent pas dans une même zone. Dans ce cas la séparation des amas de pixels est rendue difficile.
Pour plus de précision, un modèle de détection des joueurs devra pour chaque image de la vidéo catégoriser les objets présents.
Plusieurs méthodes peuvent être alors envisagées :
– L’utilisation des HAAR Cascade, traditionnellement utilisées pour la détection de visages.
Cette méthode fut proposée dès 2001 par Viola et Jones (Rapid Object Detection using a Boosted Cascade of Simple Features). Son principal intérêt réside dans sa grande rapidité de classification, d’où son utilisation courante pour l’analyse vidéo.
Pour l’entraînement d’un modèle de type Haar-Cascade, il faut utiliser un grand nombre d’échantillons d’image « positives » (correspondant à des formes humaines) et un grand nombre d’images « négatives ». Sur une image du jeu d’entraînement, réduite à ses niveaux de gris, il s’agit à faire varier la position et l’échelle d’une fenêtre mobile (« kernel »). A chaque position et échelle sont alors calculées les valeurs de variables explicatives (« features ») en soustrayant la somme des valeurs des pixels du rectangle représenté en blanc par la somme des valeurs des pixels du rectangle représenté en noir.
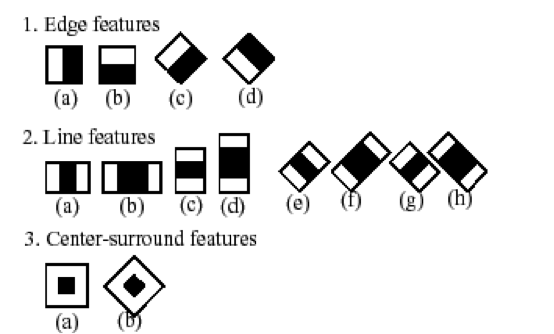
Haar-like features utilisées dans l’algorithme de Haar-classification d’openCV.
Source : http://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html
Il en résulte pour chaque image un grand nombre de « features » (16 000 pour une zone considérée de 24*24 pixels), nombre qui peut être réduit selon l’importance des features pour la classification (détermination de la « feature importance » à l’aide d’Adaboost).
Ensuite, pour déterminer si un objet avec correspond à une forme humaine, l’algorithme HAAR Cascade utilise des « weak classifiers ». Chaque « weak classifier » utilise un nombre réduit de features (en moyenne 10 et généralement moins de 100) parmi les features les plus importantes. Pour l’évaluation finale, les « weak classifiers » seront appliqués les uns après les autres (c’est la notion de Cascade). Un objet sera alors considéré comme une forme humaine si tous les « weak classifiers » le classent ainsi. Pour plus d’information sur les HAAR classifier, le lecteur est invité à se référer à
– L’utilisation de HOG Classifier (histogramme de gradient orienté), parfois plus précis que la méthode HAAR Cascade, mais moins rapide. Calculer les gradients orientés d’une image consiste en chaque point à déterminer dans quelle direction les variations de valeur de pixels sont les plus fortes et de quantifier ces variations.
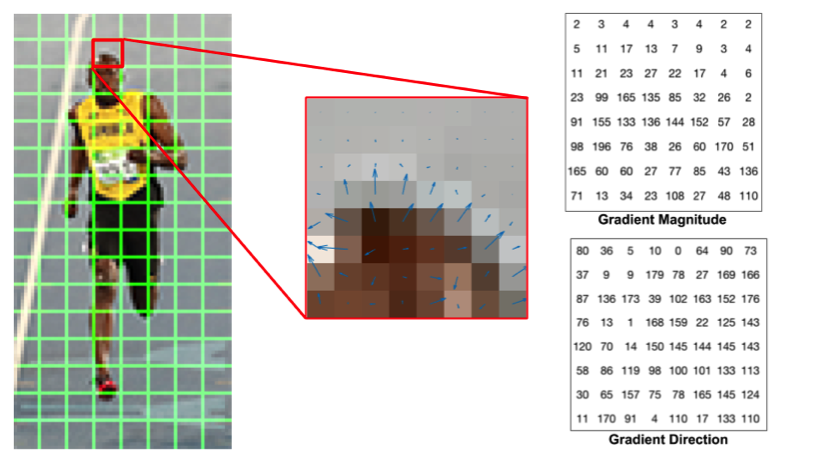
Détermination des directions et valeurs des gradients dans une image
Source : http://www.learnopencv.com/histogram-of-oriented-gradients/
A partir de ces directions de gradients et de leurs valeurs il est alors possible de déterminer la signature d’une image en termes de l’histogramme des valeurs des gradients orientés selon leur direction. Chaque classe de l’histogramme correspond à une orientation définie et la valeur de chaque classe correspond au cumul des valeurs des gradients dans cette classe.
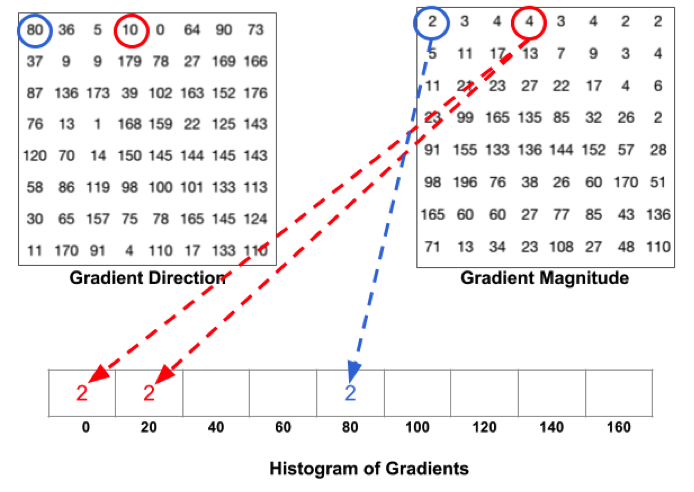
Création des histogrammes de gradients orientés.
Source : http://www.learnopencv.com/histogram-of-oriented-gradients/
A l’aide d’un jeu d’entraînement comportant un grand nombre d’images « positives » de formes humaines et un grand nombre d’images « négatives » (sans formes humaines), il est possible d’entraîner un classifieur basé sur les histogrammes des gradients orientées (ou HOG).
Pour des classifications plus rapides, il s’agira de les réaliser en plusieurs temps, en analysant d’abord une image grossière « pixellisée » avant de calculer les HOG de zones plus précises.
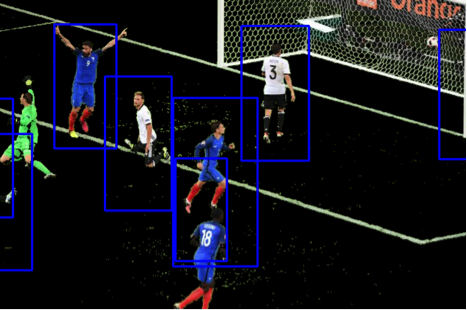
Détection des joueurs basé sur un HOG classifier, openCV.
Quantmetry 2017, travaux de développement internes.
– Dernière méthode à envisager : L’utilisation de réseaux de neurones profonds (voir l’article de blog de Nicolas Gibaud), standards ou à convolution (voir les articles de Nicolas Thiebaut [1] et [2]) promet des performances élevées en terme de précision.
Identification des joueurs
A présent nous avons détecté les joueurs. Mais comment différencier Griezmann de Giroud ?
Deux solutions se dessinent pour permettre d’identifier les joueurs :
o Utiliser les numéros inscrits sur les maillots : il s’agit alors d’un problème de reconnaissance de caractère. Même si la reconnaissance de texte est une méthode développée depuis des années (nous citerons les travaux de Yann LeCun sur la lecture automatisée de chiffres manuscrits dès 1998), cette opération est considérée complexe dans notre cas. Elle nécessite en effet une bonne qualité d’image, ainsi qu’un positionnement spécifique des joueurs. Si un footballeur est placé de face ou de côté par rapport à la caméra, son identification via son numéro sera impossible.
o Identifier les joueurs à partir des couleurs de maillot, de la peau, des cheveux et… des chaussures. Chaque joueur a des caractéristiques physiques propres (ainsi que des chaussures bien distinctes – merci les sponsors). Il s’agit donc d’isoler ces caractéristiques et d’entraîner des modèles de classification spécifiques.
Détection du ballon
La détection du ballon semble simple : un objet sphérique, de taille définie, très peu complexe. En fait, cet objet est tellement peu complexe qu’un algorithme de détection aura tendance à générer un grand nombre de faux positifs : point central, point de pénalty, tête chauve d’un joueur, coloration blanche des cheveux, chaussures blanches…
L’utilisation de réseaux de neurones pour la détection du ballon peut être envisagée mais dans la plupart des cas, une comparaison entre chaque zone d’une image vidéo (avec une fenêtre mobile) et un image « template » de ballon simple semble une solution plus directe. Pour plus de précision, et notamment pour éviter les effets de flou lors des déplacements rapides de la balle, le template devra se mettre à jour à chaque image pour une meilleur détection sur la suivante.
Pour détecter le ballon de manière encore plus performante, la prise en compte de sa dynamique est essentielle. Ainsi, on restreindra la zone de recherche au voisinage proche du ballon tel que détecté sur l’image précédente. Et lorsque le ballon n’est pas détecté sur une image (par exemple avec joueur passant devant), la zone de recherche s’agrandira graduellement.

Template pour la détection du ballon
Evaluation des déplacements de la caméra et de la position du ballon en utilisant l’algorithme matchTemplate d’openCV en quasi temps réel. Quantmetry 2017, travaux de développement internes.
Identification des limites du terrain et calcul de la position des joueurs et du ballon
Détecter les limites du terrain permet de calculer l’angle de vue de la caméra puis d’en déduire la position des joueurs et du ballon sur le terrain. Il s’agit alors de détecter des objets bien définis tels que les lignes blanches, les angles de la surface de réparation ou encore les intersections en entre rond central et ligne de démarcation.
Trois problèmes se posent alors : celui de la nécessité de points de contrôle pour gérer les transformation géométriques dû à l’angle de prise de vue, celui de la qualité de la vidéo (peut-on bien discerner de manière nette ces points) et celui des dimensions du terrain.
Dans le premier cas, si l’image ne montre par exemple qu’une ligne de touche sans aucun autre point de repère, il est impossible, même pour l’œil humain, de connaître avec précision la position d’un joueur ou du ballon. Dans le second cas, si les limites du terrain sont faiblement discernables à cause d’une mauvaise qualité vidéo, il sera difficile pour un algorithme d’évaluer la position des joueurs. Ces deux situations sont de moins en moins rencontrées dans les vidéos de matchs récents, pour lesquels l’utilisation de la haute définition permet aux réalisateurs de filmer des plans plus larges (donc présentant potentiellement plus de points de repères) et des images plus précises. Le troisième cas est plus complexe à traiter : chaque terrain de foot a des dimensions qui lui sont propres. La FIFA ne donne pas des dimensions précises mais plutôt des intervalles acceptables pour la longueur (entre 90 et 120 mètres) et pour la largeur (entre 45 et 90 mètres). Il est donc nécessaire de connaître a priori les dimensions de chaque stade où sont joués les matchs.
Une fois l’étape d’identification des limites du terrain et les étapes précédentes réalisées, il est alors possible d’enregistrer chaque position de joueurs et de balle sur le terrain.
De multiples outils statistiques peuvent être alors créés : des « heat maps » de positionnement de joueurs (montrant les positions les plus occupées par tel ou tel joueur), des cartes de trajectoires de la balle, voire des modèles de classification des déplacements du ballon.
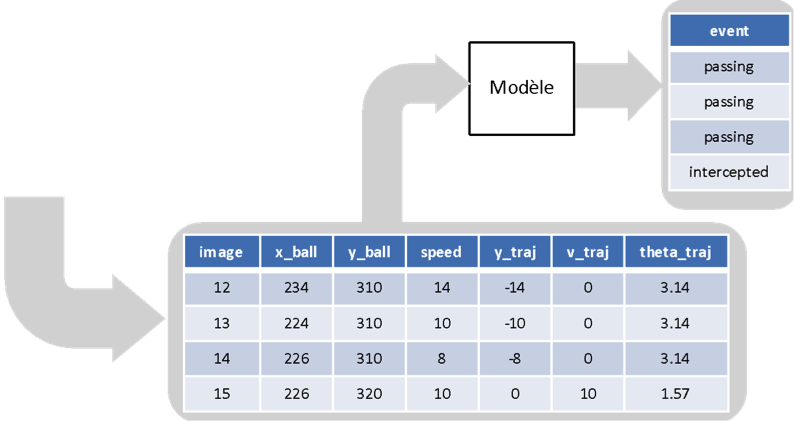
Exemple schématique d’un modèle de classification des déplacements du ballon à partir des enregistrements
de position, vitesse et trajectoire.
Et au-delà de ces quelques cas d’usage, que pourrions-nous faire de cette gigantesque base de données de position et de déplacements de joueurs et de ballon ? Que pourrions-nous imaginer pour le futur du sport à la télévision ?
Etude des interactions entre ballon et joueurs.
Enfin, nous y sommes, c’est à cette étape que toute le potentiel du Big Data et du Machine Learning intervient.
L’étude des interactions entre joueurs et ballon constitue un axe de recherche à elle seule, pouvant permettre de créer une véritable valeur ajoutée.
Idéalement une fois la base de données des positions, vitesses, déplacements de chaque joueur créée, nous pourrons réaliser des modèles prédictifs solides, voire prédire la meilleure décision selon une situation : je suis un attaquant face à un défenseur, à telle position et à telle distance du ballon, de mes coéquipiers et de mes partenaires. Que devrais-je faire ? Passer ? Tirer ? Simuler une faute ? Avec quelle probabilité de succès ?
Imaginez un futur où bien confortablement assis devant un écran, le spectateur pourrait lire en temps réel la probabilité de succès d’un tir du joueur ayant la balle. L’expérience en serait certainement plus excitante !
Par ailleurs, d’autres axes de recherche sont actuellement étudiés pour l’évaluation des interactions joueurs-ballon, telles que l’analyse des positions corporelles de joueurs pour déduire si il va tirer ou non.
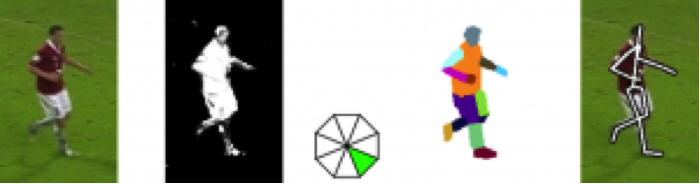
Source : Technische Universität München
Bref, un univers énorme de données disponibles et des applications multiples.
Et quels potentiels alors pour d’autres sports tels que le tennis ou l’athlétisme ? Nous verrons si le mariage Big Data-sport tiendra ses promesses dans les années à venir.
Références:
Gibaud, N., 2016, Le Deep Learning : plongée en eaux profondes, Article de blog – Quantmetry: https://www.quantmetry.com/single-post/2016/10/18/Le-Deep-Learning-plong%C3%A9e-en-eaux-profondes
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P., 1998. Gradient-Based Learning Applied to Document Recognition, Proceedings of the IEEE, 86(11):2278-2324
Satya, M., 2016, Histogram of Oriented Gradients, LearnOpenCV: http://www.learnopencv.com/histogram-of-oriented-gradients/
Thibaud, N., 2016, Abeille ou bourdon ? Activons les neurones (2/2), Article de blog – Quantmetry: https://www.quantmetry.com/single-post/2016/10/24/Abeille-ou-bourdon-Activons-les-neurones-22
Thibaud, N., 2016, Abeille ou bourdon ? Activons les neurones, Article de blog – Quantmetry: https://www.quantmetry.com/single-post/2016/01/21/Abeille-ou-bourdon-Activons-les-neurones
Viola, P. and Jones, M., 2001; Rapid Object Detection using a Boosted Cascade of Simple Features. Accepted conference on computer vision.
Open Source Computer Vision, Face Detection using Haar Cascades tutoriel: http://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
