

Le serverless

Dans cet article, nous vous proposons de refaire un rapide historique du développement informatique, afin de mieux comprendre les évolutions actuelles et futures, et d’appréhender le rôle du « Software Engineer ». Le 1er service « Serverless » – le FaaS (Function as a Service) – est détaillé, avec les avantages et inconvénients, les cas d’usage où ce service est pertinent ainsi que l’écosystème associé (propriétaires ou open-source).
La course est lancée pour que la scalabilité ne soit plus spécifiquement gérée par le développeur mais aussi par les services proposés (capacité de compute, bases de données…).
Nous terminerons cet article par un cas d’usage dans le domaine de l’énergie, au sein d’une architecture AWS.
Commençons par un peu d’histoire …
Pour bien comprendre ce qu’est le « serverless », il est important de rappeler comment une application est construite, et aussi les évolutions depuis les trente dernières années environ.
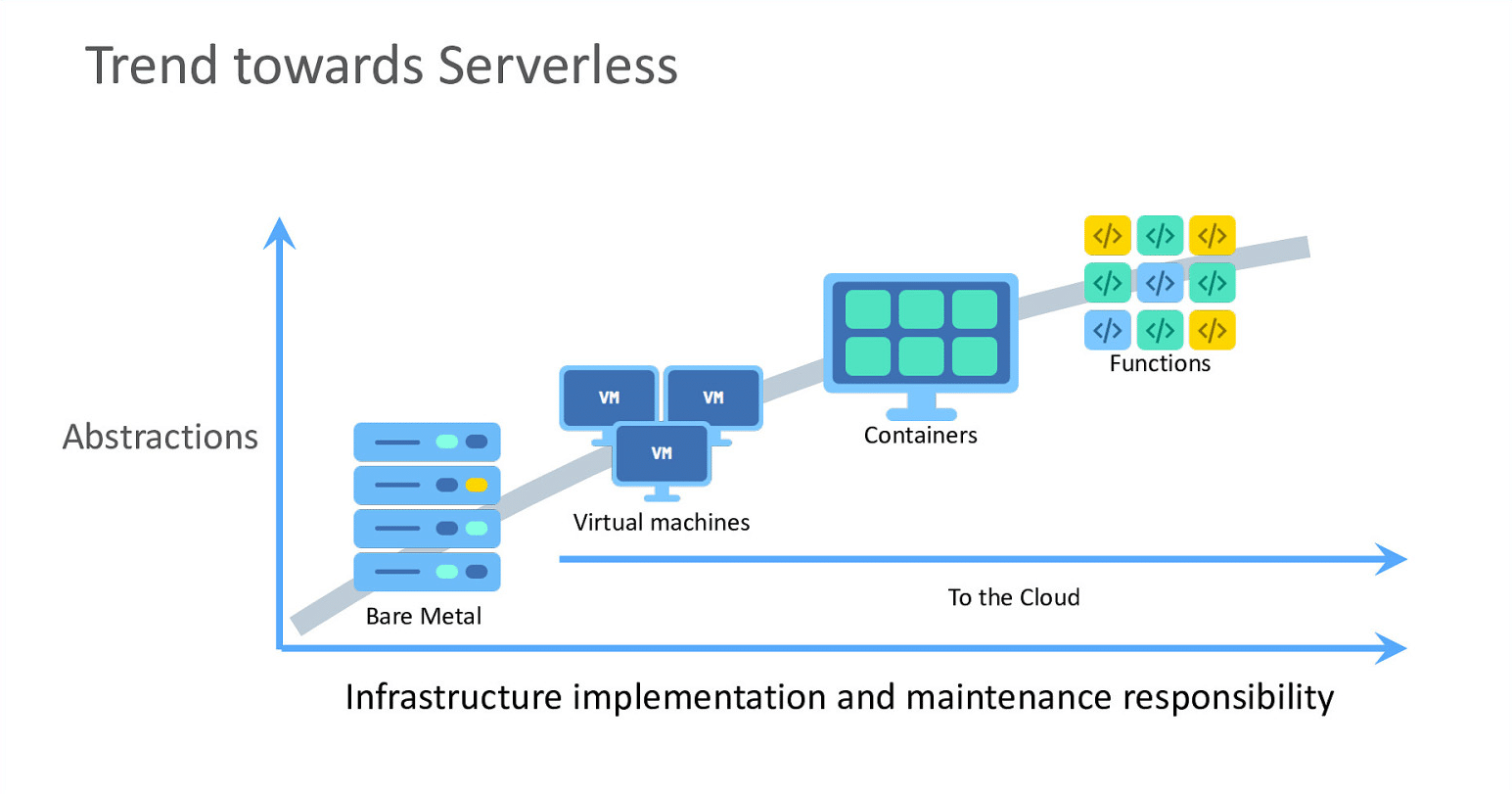
Illustration : Oracle
Avant l’arrivée des environnements virtuels (à la fin des années 90), l’application était hébergée sur un serveur physique ; cela se traduisait par :
- l’achat d’un serveur aux caractéristiques appropriées pour héberger l’application ;
- l’installation du serveur dans un datacenter ;
- la mise en réseau, l’alimentation électrique, le refroidissement etc. ;
- l’application des mises à jour du système d’exploitation, des correctifs de sécurité, la supervision de la machine pour la redémarrer en cas de soucis etc.
Il fallait alors plusieurs semaines pour avoir un environnement de travail opérationnel.
Les environnements virtuels ont permis d’accélérer la mise en place d’une application ; la partie « physique » d’un serveur étant alors « masquée ».
Le développement rapide de cette technologie coïncide avec l’émergence du Cloud, dont la création d’AWS en 2006. Les « couches basses » (l’infrastructure et les serveurs physiques) sont gérées par le Cloud Provider et le Client n’y a pas accès.
En grande majorité, les développements informatiques se font désormais sur des environnements virtuels ; la mise à disposition d’un environnement de travail ne prend plus que quelques minutes, avec la possibilité d’adapter la puissance de la machine (mémoire, CPU…), voire la faire évoluer selon ses besoins.
En 2013, Docker publie son logiciel de conteneurisation : une nouvelle « couche d’abstraction » est créée : le container ne contient plus que l’application, binaires et librairies nécessaires. Le développeur n’a plus à se soucier du système d’exploitation.
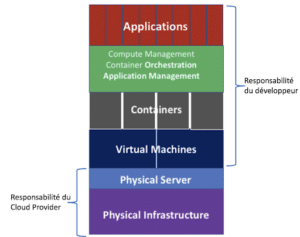
Le développement de « micro-services » se développe afin de rendre plus modulaires les applications, davantage scalables et maintenables.
Des solutions d’orchestration de containers émergent, dont la plus connue est Kubernetes (voir notre article de Blog), permettant de gérer le déploiement, la mise à l’échelle et la gestion automatisée des conteneurs.
En 2015, AWS sort la 1ère version de son service, Lambda, dit « Serverless », où le développeur se concentre uniquement sur le code de la « fonction » à réaliser. Le concept de « Serverless » ne cesse alors de prendre de l’ampleur :
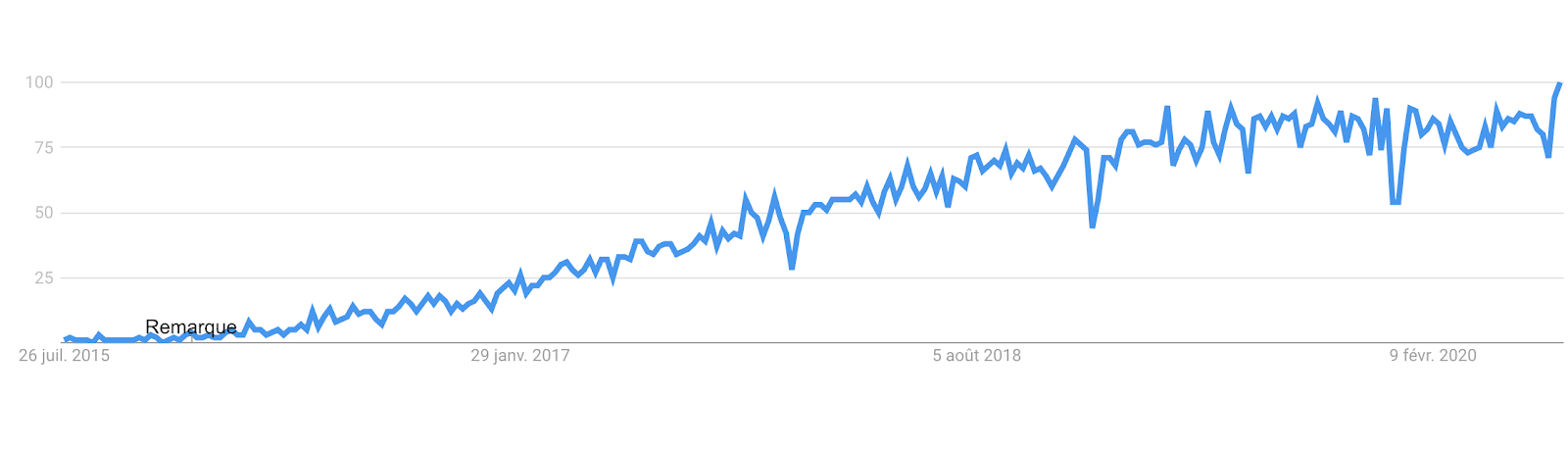
Evolution du nombre de recherches sur Google de “serverless”
La succession de couches applicatives permet désormais au Software Engineer de s’extraire des « couches basses », très techniques, pour ne se concentrer que sur le développement de la solution.
Intéressons-nous au Function as a Service
Le Function as a Service (FaaS) est un moyen d’exécuter des morceaux de code modulaires (écrits dans son langage de prédilection, comme Python, Java, C#…). Ce code forme une « fonction » et un ensemble de « fonctions » un micro-service.
La fonction est généralement exécutée :
- en réponse à un événement, tel qu’un utilisateur qui clique sur un élément d’une application web ;
- de manière ordonnancée, pour exécuter une tâche ponctuelle (un calcul d’indicateur journalier par exemple) ;
- en lien avec d’autres services, comme le dépôt d’un fichier, en sortie d’une file d’attente etc.
Quels sont les avantages du FaaS ?
- Le développeur est plus productif car il se focalise sur la logique applicative, sans se soucier du déploiement de son code sur les serveurs. En effet, la configuration et le provisionnement sont délégués au Cloud Provider : le développeur choisit son langage de programmation (Python, C#, Java…) et la mémoire nécessaire pour son exécution ; plus besoin d’installer le « runtime » d’exécution du programme sur le serveur ni de demander à l’IT une extension de mémoire au serveur pour faire tourner l’algorithme !
- Il est facile de mettre à l’échelle le code. Plusieurs instances du même code peuvent s’exécuter de manière simultanée (chez AWS : 1000 exécutions en parallèle sont possibles par défaut) en réponse à des événements, avec un temps de réaction inférieur à 100 ms (voir article de Blog AWS).
Quels sont les inconvénients du FaaS ?
- Du fait de la limitation en mémoire et en temps d’exécution (sur AWS, une Lambda est limitée à 3 Go de mémoire et 15 minutes d’exécution), tous les cas d’usage ne conviennent pas au FaaS car :
- pour traiter de gros volumes de données, il faut pouvoir les segmenter afin de pouvoir les traiter de manière simultanée (via l’exécution de plusieurs instances de FaaS), ce qui nécessite de limiter le flux de données en entrée de la FaaS et d’organiser les données de manière cohérente pour les traiter simultanément.
- le coût peut devenir important. Par exemple, une AWS Lambda qui serait exécutée l’équivalent de 720h avec 3 Go de mémoire revient à 1200 USD/mois, alors qu’une simple machine virtuelle EC2 avec 4Go de mémoire revient à 40 USD/mois et un container de type Fargate de ressources équivalentes (2 vCPUs et 3 Go de mémoire) revient à 70 USD/mois. Il convient donc de réserver le FaaS à l’exécution de services qui doivent s’exécuter en réponse à des événements et non pour traiter un flux continu de données dont le débit est fixe.
- Chaque Cloud Provider propose sa propre solution FaaS : AWS Lambda, Google Cloud Function, Azure Function. Chaque solution est propriétaire et le risque est grand d’être pris dans le « vendor-locking », chaque Cloud Provider ayant ses spécificités (comme la durée maximale d’une fonction, les langages supportés, le nombre de fonctions pouvant être lancés simultanément etc.).
Principaux cas d’usage du FaaS :
Site Web dynamique
La partie dynamique est traitée par plusieurs FaaS en réponse à une action de l’utilisateur, à travers l’appel d’APIs. Exemple https://aws.amazon.com/fr/serverless/build-a-web-app/
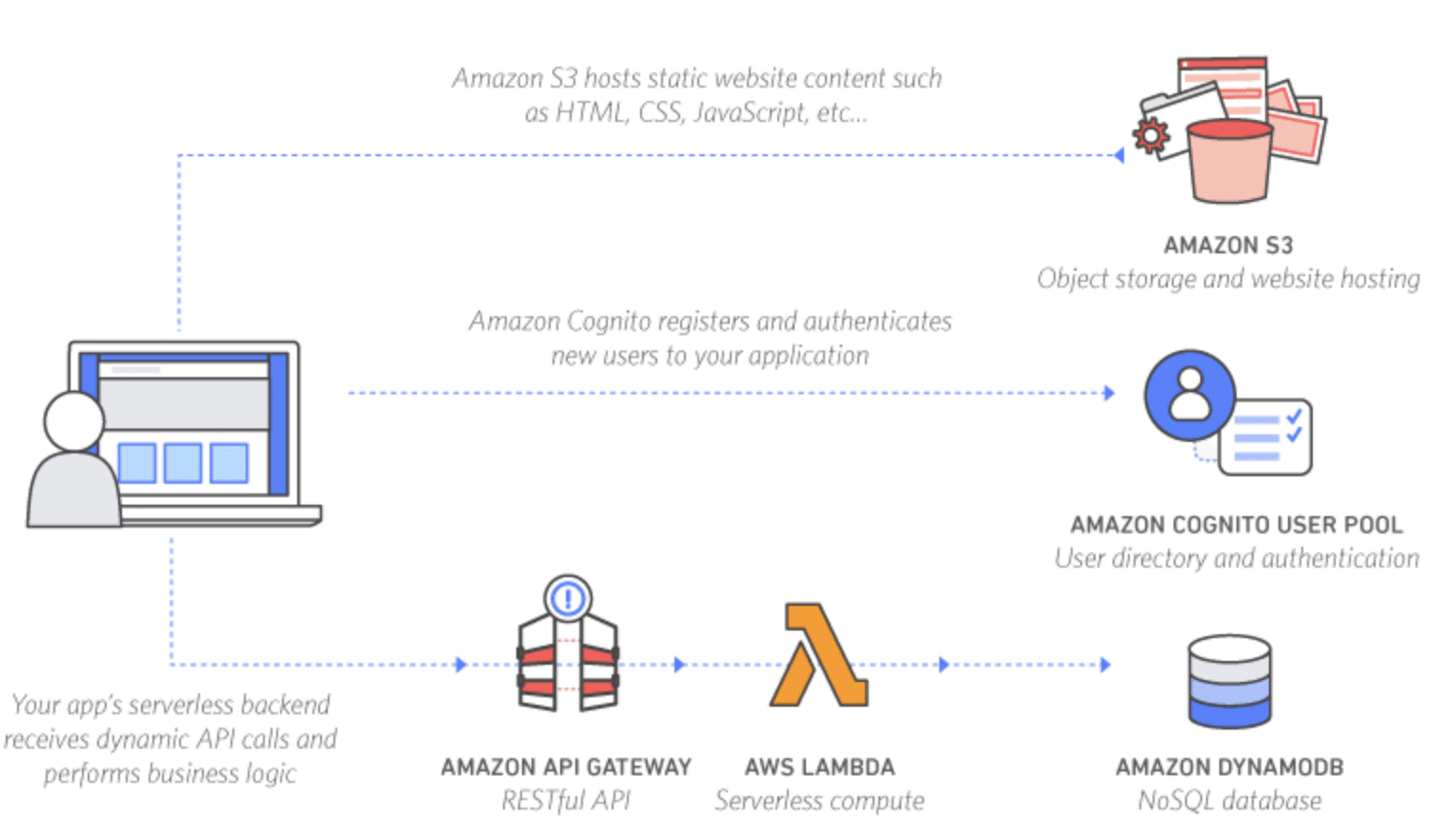
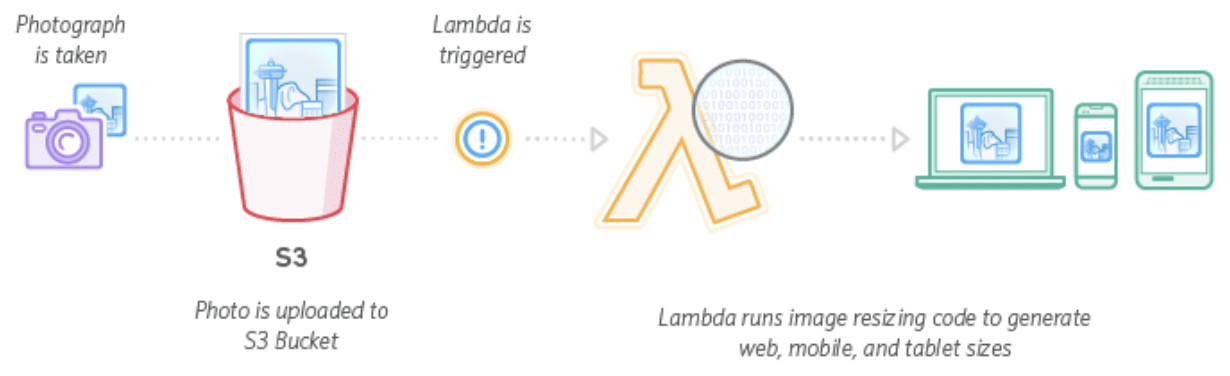
Traitement sur des fichiers
Lors du dépôt d’un fichier, un FaaS s’exécute automatiquement afin de réaliser un traitement (insertion de méta-données dans une base de données, vérification du format, enrichissement par exemple).
IoT
Afin d’interagir avec les données reçues, un FaaS est déclenché (pour chaque événement ou par lot d’événements)

Ecosystème FaaS open-source
Outre les 3 services propriétaires proposés par AWS, Google et Azure (OVHcloud ne propose pas de service propriétaire mais une offre FaaS à travers OVH Managed Kubernetes et OpenFaaS), de nombreux frameworks open-source existent comme OpenWhisk, OpenFaas, Cloudstate, serverless framework. Tous font la promesse d’une meilleure portabilité, d’une plus grande transparence dans le paramétrage et dans l’utilisation d’outils 100% open-source.
Apache OpenWhisk reposant sur des containers
Les autres fonctionnalités
Après le FaaS, de nouveaux services « serverless » ont été développés afin que le développeur se concentre sur la logique métier et laisse au Cloud Provider la responsabilité de la disponibilité, la scalabilité et la sécurité du service.
Par exemple, mi-2018, AWS a mis à disposition une base de données Serverless : le nombre de nœuds mis en œuvre s’adapte à la charge de travail, avec une latence minimale.
C’est possible grâce à 2 points :
- les données ne sont pas stockées « dans la base de données » mais sur des disques réseau, connectés aux serveurs via un réseau à très haut débit ;
- un pool d’instances de base de données en fonctionnement (« up ») est en place (et partagé par tous les Clients) afin de pouvoir réagir à un pic de requêtes (et ajouter un nouveau nœud) dans les meilleurs délais.
Il est donc possible d’avoir une base de données inactive (aucun nœud) si aucune activité n’a lieu ; le coût sera alors dépendant uniquement du volume de données stockées.
Comme pour le FaaS, il est important de considérer l’aspect coût / bénéfice. En effet, il est préférable de mettre en place une base de données managée par le Cloud Provider si cette dernière est sollicitée régulièrement, avec un volume d’activité relativement stable, plutôt que de mettre en place une base de données « serverless » qui est plutôt adaptée pour des charges de travail très fluctuante et intermittente.
Exemple de mise en place d’une infrastructure “Serverless” pour un acteur mondial d’énergie
Notre client traite des données issues de dispositifs de production d’énergies renouvelables (éoliennes, panneaux photovoltaïques). Le but de l’architecture mise en place et présentée ici est la standardisation puis la mise en qualité (QA/QC) des données brutes ingérées par micro-batch. Les consommateurs de cette donnée raffinée sont nombreux puisque les possibilités de cas d’usage sont multiples : KPIs, maintenance préventive, etc.
La fréquence d’ingestion est fortement sporadique : les sources sont variées, les réseaux instables, les partenaires peuvent intégrer de nouveaux capteurs dans le datalake ou bien, remonter un historique de données de quelques mois voire années (backfill). L’aspect majeur de cette architecture Kappa est donc la mise à l’échelle pour absorber les pics de charge. L’architecture est hébergée sur le Cloud AWS.
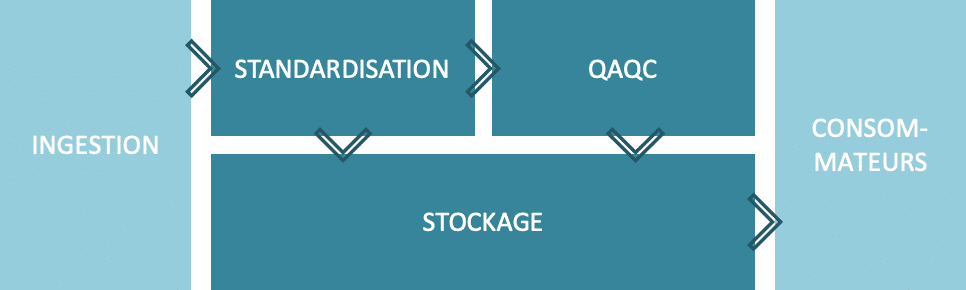
Architecture fonctionnelle
Standardisation
Les données proviennent de plusieurs constructeurs, via des composants d’acquisition (SCADA – qui tamponnent et agrègent les données, connecteur industriel PI, etc.), sur différents continents avec des unités et des formats distincts, etc. Dès leur ingestion, les datapoints doivent subir une série de transformations : mise en place d’un format commun en clé-valeur, passage sous la norme IEC, conversion des valeurs en unité du Système International, des timestamp en UTC, etc.
Chaque étape est responsable d’une tâche, agnostique à la source sous la forme d’un micro-service avec un format défini d’entrée et de sortie, sans se soucier de l’ordre d’exécution (sauf cas de dépendance) ni de la qualité des précédentes. Exemple : après le passage en IEC il n’est plus nécessaire de vérifier que la clé existe dans le référentiel, l’étape IEC étant responsable de rejeter une clé inconnue.
Une étape est implémentée en Python via une Lambda. Les applications sont découplées via des files SQS (Simple Queue Service), ce qui permet de stocker les données en attendant qu’elles soient traitées. Une Step Function permet d’orchestrer de manière élégante le déroulement de chaque étape, notamment en aiguillant le prochain état selon la sortie de la Lambda. Dès lors, si des messages sont toujours présents dans la file après exécution de la Lambda, celle-ci est invoquée de nouveau tant que la file n’est pas vide ; chaque minute une nouvelle Step Function est instanciée en « renfort » afin de paralléliser les calculs. Le résultat est qu’en cas de charge importante, chaque étape de la standardisation devient un groupe grandissant de Lambda qui « poll » les données à traiter.
Mise en qualité
La dernière étape de la standardisation partitionne les données par segment logique (une journée pour une variable de capteur et un site géographique) que l’on peut traiter comme « ensemble » avec les capacités qu’offre une Lambda. Les étapes de QA/QC vont assurer la mise en qualité des données, non plus par micro-batch ingéré mais par segment. Pour chacun d’entre eux, les datapoints sont dédoublonnés et complétés, et on s’assure que leur valeur est valide et cohérente.
Chaque segment standardisé est matérialisé par un « job » à traiter dans une base de données Aurora Serverless. En cas de charge importante, les « jobs » s’accumulent et sont priorisés selon les besoins des consommateurs des données (selon l’heure du jour ou de la nuit, les variables importantes, etc.), la capacité de la base s’adapte automatiquement (cf précédemment). Il est possible de paralléliser les étapes indépendantes les unes des autres. L’organe d’ordonnancement invoque les Lambda QA/QC selon l’ordre de priorité et en limitant le nombre d’exécutions parallèles (pour rester dans les quotas AWS). Comme pour la standardisation, l’utilisation de Step Function facilite le suivi des états et surtout la gestion des erreurs.
Stockage
S3 a été choisi comme système de stockage des séries temporelles mais aussi comme référentiel pour permettre les accès concurrents par un grand nombre d’applications en lecture comme en écriture. En effet, depuis juillet 2018, AWS a nettement augmenté les performances de S3 (5,5k GET et 3,5k PUT/COPY/POST/DELETE) ce qui rend possible la parallélisation mise en place. De plus, le partitionnement S3 nous permet de requêter les données via Athena de manière efficace, utile pour débugger ou simplement faire de l’exploration avec SQL.
Architecture
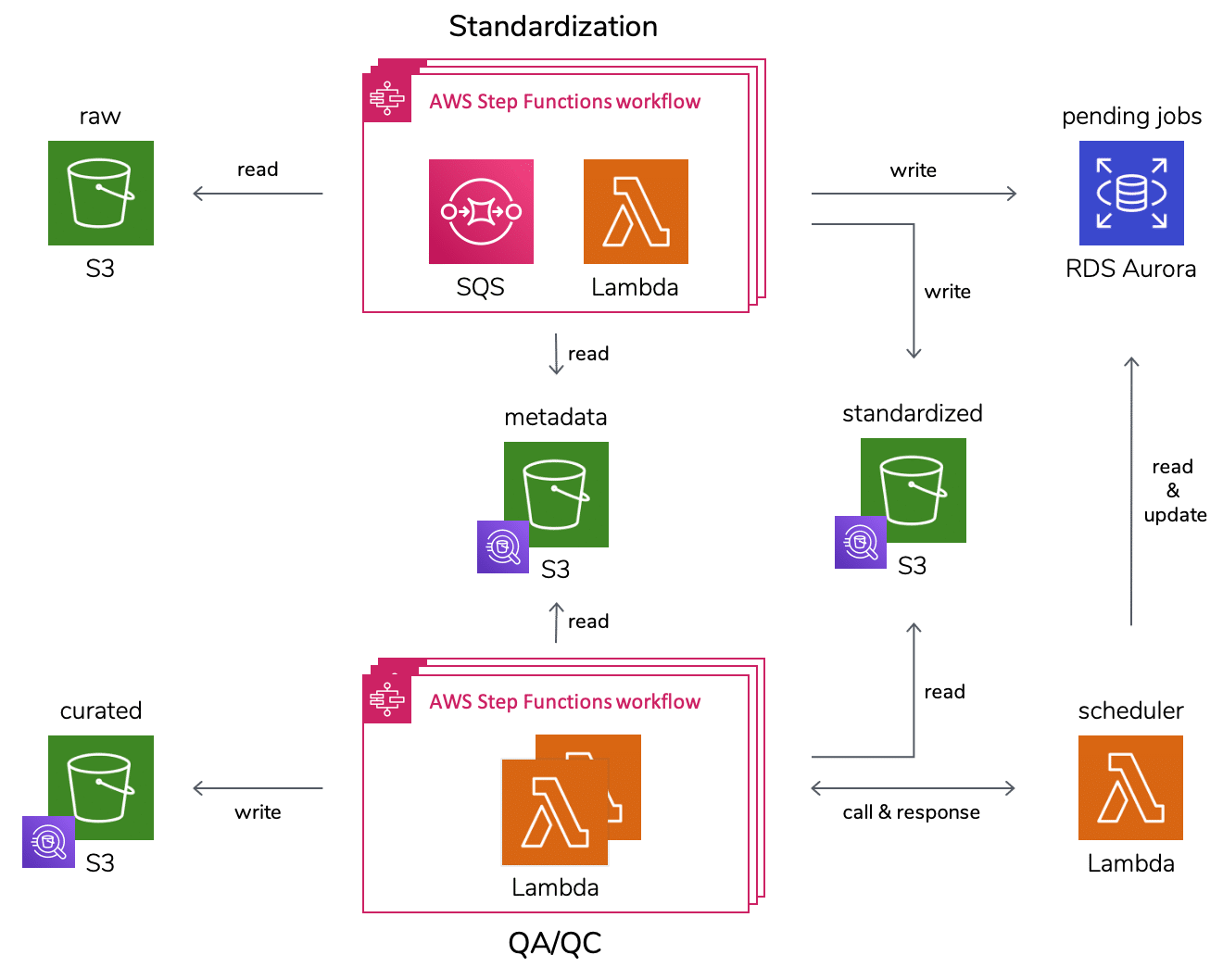
Architecture technique AWS
Conclusion
Chaque jour, plusieurs dizaines de millions de datapoints sont traitées par cette architecture, qui repose uniquement sur des composants Serverless managés par AWS. Cela a permis d’accélérer grandement son implémentation. La mise à l’échelle est réalisée grâce à des mécanismes de découplage (entre standardisation et QA/QC, mais également entre les micro-services) et de haute parallélisation. Ainsi, en cas de backfill, on n’observe pas moins d’une centaine de Lambda exécutées de concert pour écouler le flux de données entrant et traiter plusieurs mois de séries temporelles en quelques dizaines de minutes. Une approche monolithique qui traite l’ensemble des données (par batch quotidien par exemple) ne permet pas d’atteindre ce niveau de performance.
✍ Écrit par Olivier Denti et Jean Pasquier
