

Les ordinateurs ont appris à bluffer. Et ça va tout changer. (2/2)

Dans le premier volet de cette série, nous avons présenté les principes de la théorie des jeux, ainsi que ses points de contact avec le machine learning et l’intelligence artificielle. Nous allons à présent vous parler du challenge d’apprendre aux machines à jouer ainsi que des toutes récentes avancées dans ce domaine, et pour finir les possibles champs d’applications. Suivez nous dans ce voyage !
Libratus : une avancée majeure pour la convergence entre théorie des jeux et machine learning
Des jeux de dames à Libratus…
Depuis 20 ans, d’importants progrès ont été réalisés dans la confrontation entre humains et IA sur des jeux donnés. En effet, un jeu tel que le jeu de dames ou les échecs peut être transformé en problème d’optimisation, sachant un nombre donné de combinaisons possibles. A titre de référence, il y a environ 10^80 atomes dans l’univers.
Complexité des différents jeux
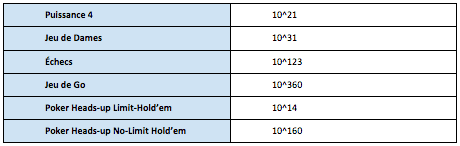
Les premières victoires
1994 : Le logiciel Chinook bats au jeu de dames Marion Tinsley, considéré comme le meilleur joueur de tous les temps. Cette victoire est cependant en demi-teinte, car elle intervient après 6 parties nulles et un abandon de Tinsley. En effet, il est établi qu’aux dames, en cas de 2 joueurs parfaitement rationnels, l’issue attendue est un match nul. Depuis 2007, on connaît l’ensemble des coups à jouer, le jeu de dames est donc officiellement “résolu”.
1997 : DeepBlue bat Gary Kasparov aux échecs, et ce, sans match nul ; malgré une complexité de jeu bien supérieure au jeu de dames.Contrairement aux dames, les échecs n’ont pas encore été résolus par les programmes, bien que le champion du monde ait pu être battu.
Les premiers pas de mise en oeuvre de la théorie des jeux
2015 : Des chercheurs de l’université d’Alberta développent Cepheus, qui bats des joueurs professionnels au Texas Hold’Em avec limite. Ils ont résolu ce jeu, qui a cependant un nombre de combinaisons limité, en calculant un équilibre de Nash à chaque étape du jeu, ce qui le rend “imbattable”. Ils ont par la suite développé DeepStack pour le Texas Hold’Em No Limit. On peut noter que Cepheus nécessite 16 To de RAM et ne peut jouer que contre un seul joueur…
La même année, l’université Carnegie Mellon développe Claudico, qui a le même objectif que Cepheus, mais ne parvient pas à battre les joueurs professionnels. Par la suite, ils améliorent leur programme pour créer Libratus.
AlphaGo : une victoire attendue de la machine sur l’homme *
Mars 2016 : AlphaGo, le programme développé par DeepMind (Google) bat le Sud-Coréen Lee Sedol, champion du monde du jeu de Go. On monte encore d’un cran dans la complexité, le nombre de combinaisons étant abyssal. La machine, qui se basait sur des techniques connues et éprouvées, à savoir l’algorithme Monte Carlo tree search, le Deep Learning et le Reinforcement learning, a appris en deux phases. Dans un premier temps, elle a appris du maximum de parties jouées par l’homme, puis elle a affronté une autre machine afin d’améliorer seule son réseau neuronal, et pouvoir se confronter à Lee Sedol. Il est important de préciser que cette victoire de la machine sur l’homme au jeu de Go était attendue, puisqu’il ne s’agit “que” de stratégie combinatoire, mais qu’elle est arrivée plus tôt que prévu, ce qui est de bon augure pour l’IA. On peut également préciser qu’AlphaGo ne sait faire que du Go, et qu’en ce sens on est loin d’une vraie IA générale, qui n’existe pas encore et nécessite d’introduire des représentations générales du monde.
*Le 18 octobre 2017, Nature a publié “Mastering the game of Go without human knowledge” où AlphaGo Zero est présenté. DeepMind a en effet développé une nouvelle version d’AlphaGo qui ne nécessite plus de jouer contre un humain pour apprendre, mais où l’algorithme joue contre lui même. En jouant contre AlphaGo, AlphaGo Zero gagne 100-0, ce qui est plutôt significatif…

Libratus
Janvier 2017 : Libratus, développé par l’université de Carnegie Mellon, affronte en face à face 4 des meilleurs joueurs professionnels de poker Hold’Em “No limit” (Daniel McAulay, Jimmy Chou, Dong Kim et Jason Les). Cette variante du poker permet des relances infinies ainsi que toutes les formes de bluff. Les joueurs ont enchaîné pendant 20 jours plus de 120.000 mains différentes avec la machine. Le résultat des courses est sans appel : à la fin de l’expérience, Libratus avait ainsi pu récupérer plus de 1,5 million de dollars en jetons, les autres perdant chacun entre 84 054 .
.
Pendant le jeu, Libratus a nécessité 2.6PB de stockage et environ 800 noeuds, chacun ayant entre 128Go et 12 To de RAM.

Fonctionnement et hypothèses de Libratus
Contrairement aux échecs et au Go, le Poker est un jeu qui n’est pas « à information complète », ce qui signifie que les participants ne peuvent avoir accès à l’ensemble des informations relatives au jeu. Il y a de multiples inconnues, et le facteur chance, ainsi que l’élément psychologique priment.
Cette situation peut être conceptualisée grâce à la théorie des jeux par :
– un jeu à deux agents (ou plus)
– chacun souhaite maximiser ses gains et par conséquent battre son adversaire
– chaque agent élabore des stratégies et fait des hypothèses sur la stratégie de l’adversaire, en se basant sur une information publique (les cartes déjà jouées) et une information privée (on connaît son propre jeu, pas celui de l’adversaire).
Ainsi, on est dans une situation de jeu répété, avec une asymétrie d’information, et une rationalité limitée des individus. En effet, personne n’est parfaitement rationnel.
On va alors essayer de « résoudre le jeu », et bluffer au besoin, ce qui revient à calculer un équilibre de Nash à chaque étape. On adopte alors la meilleure stratégie à chaque étape, ce qui revient à un problème d’optimisation sous contrainte d’information publique et de cartes à disposition.
De manière générale, cela illustre la capacité de Libratus à faire des raisonnements stratégiques en ayant une information imparfaite, et qui a surpassé celle des meilleurs joueurs humains. Or, c’est dans les prises de décisions du monde réel qu’une IA deviendra vraiment intéressante.
Grâce au Deep Learning et doté d’une énorme puissance de calcul, Libratus est capable, d’une partie à l’autre, d’apprendre comment jouent ses adversaires, y compris quand et comment ils bluffent.
Son algorithme se base sur l’équilibre de Nash afin d’optimiser ses gains. Pour finir, il joue de manière totalement imprévisible. «Chaque fois qu’on a trouvé la faille, le lendemain, elle avait disparu», confesse un des joueurs.
Au final, il est composé de trois blocs d’algorithmes : le premier apprend le comportement du joueur au fur et à mesure de la partie, le deuxième élabore des stratégies pour jouer, le troisième analyse les propres stratégies de Libratus pour les supprimer au fur et à mesure et garder un effet de surprise. Il peut par exemple être efficace de varier la fréquence des bluffs au long de la partie.
Le papier de recherche détaillant le fonctionnement de Libratus n’a pas encore été publié.
En revanche, des chercheurs d’Alberta ont développé un algorithme similaire, DeepStack, qui a également battu des professionnels au Texas Hold’em No Limit, bien que d’un peu moins haut niveau, et publié sur le sujet. Le débat fait rage sur qui de DeepStack ou Libratus affiche les meilleures performances.
Chaque décision de DeepStack est basée sur l’information privée du joueur (notre jeu) et une connaissance publique (l’état du jeu à un moment M, à partir duquel on peut inférer une distribution de probabilité sur la main des autres joueurs). Deepstack ne calcule/stocke pas de stratégie complète avant de jouer, et n’a donc pas besoin d’une abstraction explicite.
Il considère plutôt chaque situation particulière au fur et à mesure qu’elle apparaît dans le jeu. Deepstack estime la stratégie de meilleure réponse jusqu’à une certaine profondeur, comme maximisant son utilité espérée, face à la stratégie de l’adversaire, ce que fait un équilibre de Nash. L’algorithme Deepstack résout ainsi un équilibre de Nash approximé.
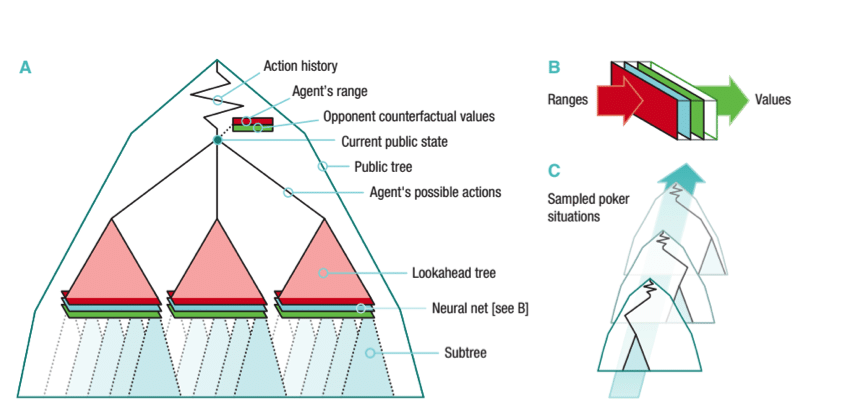
Fonctionnement de DeepStack
Quels résultats ? Quelles limitations?
Il n’est pas aisé d’évaluer l’efficacité d’un algorithme dans ce type de jeux, i.e est-ce que ses performances sont significativement meilleures qu’un certain benchmark. Ceci est dû à la large variance du résultat des jeux, liée à la dimension aléatoire de la distribution des cartes et les choix stochastiques faits par les joueurs.
Libratus a battu les 4 joueurs professionnels, tandis que Deepstack a été évalué contre 33 joueurs professionnels de 17 pays choisis par la fédération internationale de Poker. Chacun a dû réaliser un match de 3000 jeux sur une période de 4 semaines fin 2016. L’évaluation de performance est faite avec AIVAT (Moravcil et al. 2017) qui est une technique d’évaluation de performance non biaisée et tenant compte de la variance dans le cadre de jeux.
Cette métrique a permis de prouver que Deepstack était meilleur de façon statistiquement significative. Sur l’ensemble des jeux joués, Deepstack a gagné 492 mbb/g, sachant que les pros du poker considèrent que 50 mbb/g est une marge déjà significative. Deepstack était un peu chanceux, et on serait plutôt en réalité à 486mbb/g. Cependant, les auteurs sont certains de surperformer le pool de joueurs professionnels.
Libratus et Deepstack ne prennent en compte jusque là que des situations en poker face à face. L’étape suivante la plus naturelle serait d’intégrer du multi joueur, mais cela augmente exponentiellement le nombre d’interactions à prendre en compte, et par conséquent demande encore plus de ressources.
Cas d’usage
La possibilité d’utiliser les potentialités du machine learning dans des situations caractérisées par une information incomplète et/ou asymétrique ainsi que par des comportements irrationnels ouvre à ce domaine énormément de possibilités et permettra de poser les jalons d’une IA “générale”.
Le yield management, est depuis longtemps un terrain de prédilection pour l’application de méthodes de la théorie des jeux, et en particulier de la théorie des enchères. Les notions d’équilibre et de réponse optimale aux stratégies des concurrents sont au coeur même des outils nécessaires pour déterminer le meilleur prix pour une chambre d’hôtel ou vendre des espaces de publicité en ligne. Combiner théorie des jeux et machine learning permets donc d’optimiser les prix, en considérant les stratégies des différents agents.
La conduite autonome est également un champs d’application intéressant. En effet, il est crucial de ne pas considérer les autres conducteurs comme parfaitement rationnels, et notamment pendant la période où conduite humaine et autonome coexisteront. Il en va de même pour les piétons et l’ensemble des individus sur la voie publique. On peut alors modéliser et généraliser les comportements des autres conducteurs, en information incomplète, ce que ne peut pas faire le machine learning purement prédictif de façon naturelle.
En 2013, l’économiste Ariel Rubinstein défendait l’idée que “la théorie des jeux ne permet pas de prédire le réel mais propose un cadre de pensée qui, au même titre que les fables et les proverbes, permet de penser et d’analyser des situations réelles”.
Avec le succès de Libratus, il semble cependant que, grâce au deep learning, cette assertion ne sera plus vérifiée. On pourra ainsi trouver les équilibres de Nash en situation réelle, nous permettant de progresser vers l’IA générale.
Références
– Radford, A., Metz, L., & Chintala, S. (2015). Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434.
– Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680), arXiv preprint arXiv:1406.2661
– Hartford, J. S., Wright, J. R., & Leyton-Brown, K. (2016). Deep learning for predicting human strategic behavior, Advances in Neural Information Processing Systems (pp. 2424-2432)
– Elpern-Waxman, J. (2017). Autonomous vehicles need to learn empathy and game theory
– Moravčík, M., Schmid, M., Burch, N., Lisý, V., Morrill, D., Bard, N., … & Bowling, M. (2017). DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science, 356(6337), 508-513, arXiv preprint arXiv:1701.01724
– Zhao, J., Mathieu, M., & LeCun, Y. (2016). Energy-based generative adversarial network. arXiv preprint arXiv:1609.03126
– Garcia, V. (2016). La victoire d’un ordinateur sur un joueur de go n’est pas si revolutionnaire, L’express
– Gavois, S. (2016). Des échecs au jeu de Go : quand l’intelligence artificielle dépasse l’homme, NextInpact
– Moravčík, M., Schmid, M., Burch, N., Lisý, V., Morrill, D., Bard, N., … & Bowling, M. (2017). Deepstack: Expert-level artificial intelligence in no-limit poker. arXiv preprint arXiv:1701.01724.
– Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., … & Chen, Y. (2017). Mastering the game of Go without human knowledge. Nature, 550(7676), 354-359.
– Bowling, M., Burch, N., Johanson, M., & Tammelin, O. (2015). Heads-up limit hold’em poker is solved. Science, 347(6218), 145-149.
