

Machine Learning à partir de données spatio-temporelles : prioriser les zones de contrôle des pollutions diffuses par la Police de l’Environnement

✍ Sophie Monnier, Rémi Rosenthal, François-Xavier Ferlande, Cyril Bécret, Aleksander Dabrowski (Quantmetry), Alexandre Liccardi (OFB) / Temps de lecture 20 minutes
Contexte
Les plans de contrôle Eau & Nature s’intéressent à 65 thématiques variées qui déclinent localement (1) les politiques de contrôle répondant à une stratégie nationale : qualité de l’eau, gestion de la ressource, préservation des milieux, pêche, chasse et lutte contre le braconnage, espèces protégées (…). En 2019, ces plans de contrôles représentaient plus de 20 000 contrôles annuels pour l’Agence Française pour la Biodiversité (AFB). Sur l’ensemble de la France, 11 % des contrôles réalisés par l’AFB ont donné lieu à des suites juridiques. Sur certains territoires, comme la Bretagne où les politiques de police de l’environnement sont prédominantes, ces taux sont de l’ordre de 30 %. Suite à la fusion de l’ONCFS et de l’AFB en janvier 2020, ce sont plus de 1 800 agents qui participeront à ces contrôles pour la nouvelle structure formée : l’Office Français de la Biodiversité.
Pour diverses raisons (sensibilisation, orientation des politiques locales, représentation sur le territoire…), les inspecteurs de l’environnement réalisent une part importante de contrôles conformes et n’optimisent pas la recherche des non-conformités. Il est possible de se demander, quel est le coût de cette sous-optimisation, et s’ils pourraient dégager du temps pour leur permettre de valoriser des activités à haute valeur ajoutée, telles que les processus judiciaires en aval du constat d’infraction, ou le contrôle de nouvelles zones à risque.
Dans ce contexte, le projet lauréat du premier appel à manifestation d’intérêt IA porté par le département Etalab au sein de la Direction interministérielle du numérique (DINUM) et la Direction interministérielle de la transformation publique (DITP) avec le soutien du Secrétariat général pour l’investissement (SGPI), porté par l’AFB (aujourd’hui Office Français de la Biodiversité), et appuyé de Quantmetry, vise à évaluer et mettre à disposition le pouvoir prédictif des données librement disponibles sur les plateformes gouvernementales et appuyer l’élaboration des plans de contrôles.
Les autres porteurs du projet sont le BRGM, sur les aspects les plus techniques et informatiques, et le Ministère de la Transition Ecologique et Solidaire (la Direction Eau et Biodiversité, le réseau scientifique et technique).
Ce projet a été réalisé dans le cadre du tout premier appel à manifestation d’intérêt intelligence artificielle, porté par la DINUM et la DITP pour le Programme d’investissement d’avenir (PIA). Cet appel à projet fait suite aux recommandations du rapport Villani en 2018. L’équipe projet a répondu à l’appel à projet en septembre 2018. Accompagné par les équipes Etalab, le projet a été lancé début 2019 et la phase de prototypage a duré jusqu’au mois d’octobre.
Le projet exploratoire, restreint au périmètre hydrographique du Bassin Versant Loire Bretagne, consiste à définir un indice de priorisation des contrôle de pollutions diffuses (essentiellement, pollution chimique des eaux) sur une maille 5x5km du territoire. Cet indicateur, assimilable à un risque, s’appuie sur des facteurs explicatifs parlants pour les inspecteurs de police afin de guider leur intervention sur le terrain : pressions anthropiques, état de l’environnement, sensibilité des milieux naturels et historiques des contrôles précédents.
Consolidation de données open sources hétérogènes
Sur les 35 sources de données identifiées comme potentiellement utilisables :
- On retrouve une forte dimension géographique : plus des ⅔ ont une composante géospatiale,
- 95% sont des données open sources (https://geo.data.gouv.fr/fr/, https://www.eaufrance.fr/ ), ce qui les rend accessible, mais pas forcément facile à harmoniser, car répondant à des référentiels différents (administratifs, agricoles, physiques, topographiques…)
- la composante temporelle est très variable : 70% sont des données fixes (informations départementales, référentiels géographiques), 15% ont une temporalité faible (fréquence pluri-annuelle, années manquantes), 15% une temporalité forte (annuelle ou sub-annuelle).
Les données sont hétérogènes sur leur granularité spatiale et sur la méthode de requêtage (cf tableau ci-dessous pour quelques exemples) :
| Data | Disponibilité | Temporalité | Maille géographique |
| Contrôles de police | Interne AFB | annuelle | Point |
| Ventes de pesticides | Interne AFB | annuelle | code postal |
| Etat physico-chimique des cours d’eau | API Hub’eau | mensuelle | station de mesure |
| Recueil de parcelles graphique | geo.data.gouv | annuelle (années manquantes) | parcelle agricole |
| Tendances agricoles | geo.data.gouv | annuelle | Canton |
| Rapportage DCE | eionet.europa.eu/ | 3 ans | Masse d’eau |
| Référentiel communal | IGN | annuelle | Commune |
Toutes ces données sont donc récoltées, nettoyées, et mises en base PostgreSQL, qui permet par son extension PostGIS la manipulation performante et reproductible de données géolocalisées en tant que geométries. Les volumes de données étant importants (plusieurs dizaines de milliers d’enregistrement), Quantmetry a dû mettre en place des ingénieries dédiées : modèles et index spécifiques, requêtes de jointures spatiales SQL et intégration GDAL optimisée. Les bibliothèques Python sqlAlchemy facilitent l’accès aux ressources et modèles de PostGreSQL, afin de reposer au maximum sur les capacité de traitement en base (mode ELT). Sur python, ces objets sont récupérés avec l’extension GeoPandas, qui ajoute aux fonctions de dataanlyse Pandas la gestion des géométries, les opérations spatiales (jointures, intersection, union, buffer, …) et l’affichage de cartes.
Feature Engineering géospatial : concilier des échelles différentes
Le modèle est construit sur un maillage 5×5 km du territoire Loire Bretagne. Or, aucune de nos sources de données brutes n’est définie sur cette maille. Le Feature Engineering doit donc comporter une logique de changement d’échelle spatiale et d’agrégation en plus d’une phase de processing classique. Nous détaillons ci-dessous quelques sources de données intéressantes parmi celles utilisées.
Donnée cible : contrôles de police
La donnée cœur de l’intervention technique est la donnée des contrôles de police. Il s’agit de données ponctuelles, où un point correspond à un contrôle daté effectué par un inspecteur de l’Environnement, sur un thème particulier. Pour cette étude, nous ne conservons que les thèmes “nitrates” et “pesticides”. Ces contrôles représentent un volume de 15 000 points de contrôles sur un historique de 10 ans avec une répartition plutôt équilibrée des classes (56% de non-conformes contre 44% de conformes). 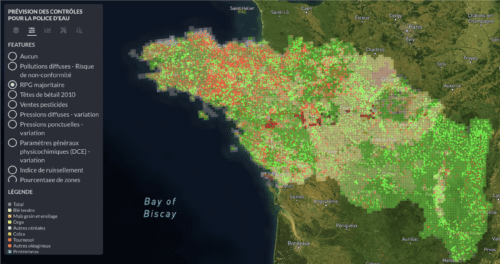
Bassin Loire-Bretagne.
La carte présente le type de parcelles agricoles majoritaires par découpage de 5km par 5km. Les points verts et rouges représentent les contrôles passés : conforme et non-conforme.
Ces données présentent plusieurs particularités à prendre en compte pour le feature engineering, notamment :
- 44% des mailles sont sans contrôle, et 49% des mailles ont au plus 2 contrôles sur les 10 ans
- Il y a une différence d’interprétation importante entre les contrôles conformes et non-conformes. Un contrôle non-conforme correspond à une infraction ponctuelle, relevée et identifiée à un endroit précis, alors que plusieurs contrôles conformes peuvent en réalité représenter une investigation sur le terrain plus longue et répartie sur plusieurs secteurs.
Le feature engineering consiste donc en la création d’un score de conformité, à l’échelle de la maille géographique choisie (5 x 5 km) et traduisant les points mentionnés ci-dessous.
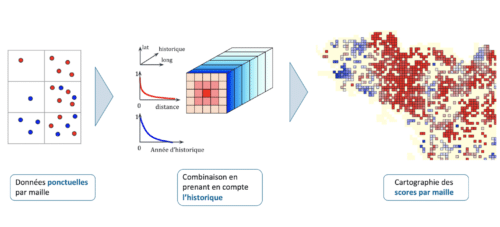
Schéma du processus de création de variable cible
- Le score doit refléter, pour chaque maille, la contribution et l’incertitude relative des contrôles conformes (points bleus) et non conformes (points rouges)
- Pour chaque maille, le score de pollution est construit à partir d’une contribution principale de la maille centrale, à laquelle s’ajoute les contributions des mailles voisines géographiquement et l’état de ces mailles dans le passé. La contribution est exponentiellement décroissante avec l’éloignement spatial ou temporel de la maille centrale
- Restitution du score (rouge : non conforme ; bleu : conforme) sur une carte
Etat physico-chimique des rivières
Pour cette variable, nous utilisons l’API REST Hub’eau d’Eau France, disponible en open data. Elle regroupe tous les relevés physico-chimiques (température de l’eau, taux de nitrates, …) qui ont été effectués pour les cours d’eau du territoire depuis plusieurs décennies par des stations dédiées, ainsi que 8 API supplémentaires non utilisées ici. Dans notre cas, nous sommes intéressés par les paramètres liés aux pollutions chimiques diffuses, en grande partie figurée par les engrais et les pesticides c’est-à-dire : potentiellement plusieurs dizaines parmi les quelques milliers relevés.
L’utilisation de cette base est complexe : les stations de mesure ne relèvent pas les mêmes paramètres, pas à la même fréquence et n’ont pas les mêmes périodes d’activité, car répondant aux préconisations scientifiques définies par l’arrêté surveillance du MTES. Par ailleurs, certains paramètres physico-chimiques sont difficilement interprétables sans expertise métier. En conséquence, avant de pouvoir calculer des indicateurs significatifs, un travail important de filtrage et d’harmonisation des données est nécessaire.
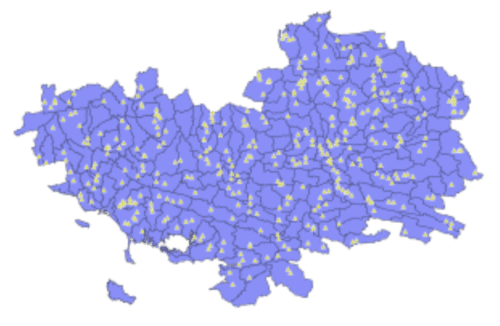
La carte présente les localisations des stations de mesure des paramètres physico-chimiques de la BD Naiade (triangles jaunes) et les secteurs hydrographiques (polygones blues).
Nous sélectionnons les stations et les paramètres chimiques utiles à notre cas d’usage avec deux critères, l’exhaustivité des données (suffisamment de mesures sur notre période d’étude) et la pertinence métier (nous sommes plus intéressés par le taux de nitrates que la température de l’eau). Nous disposons alors de séries temporelles propres pour un ensemble de stations et de paramètres chimiques.
À partir de ces séries temporelles, nous voulons quantifier leur variations au cours du temps avec l’idée que les activités polluantes à un temps T auront tendance à faire varier la chimie des rivières avoisinantes à un temps T + .
Nous avons calculé plusieurs indicateurs, par exemple, nous avons extrait la tendance du signal avec la méthode “Seasonal and Trend decomposition using Loess” (décomposition STL).
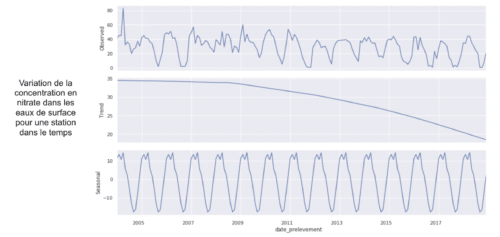
Le graphique ci-dessus présente l’exemple de résultats de la décomposition STL pour extraire une tendance. La décomposition STL est une méthode qui permet d’extraire les composantes de tendance, saisonnalité et résidus d’une série temporelle.
D’un point de vue métier, ces indicateurs n’ont de sens qu’au niveau de la zone hydrographique. Le référentiel géographique OFB/IGN BD Carthage a été utilisé pour agréger les données des stations par zone hydrographique (jointure spatiale entre le référentiel et les stations). L’imputation de valeurs manquantes prend aussi en compte cette composante géographique et se fait à travers les zones hydrographiques avoisinantes. Finalement, nous pouvons faire redescendre l’information à l’échelle de la maille en fonction de son appartenance à une zone hydrographique (intersection entre la maille et les zones hydrographiques).
Modélisation : changements apportés par la composante spatiale et gestion d’un nombre limité de points
Difficultés dans la constitution du jeu de test et impact des spécificités territoriales
Une fois le feature engineering réalisé, nous disposons d’une table d’entraînement où une ligne représente une maille et ses variables descriptives. À ce stade, il est possible d’utiliser les algorithmes et techniques de machine learning sur des données tabulaires classiques.
Cependant, la composante géographique des variables ajoute une dimension de variablilité supplémentaire et introduit une complexité supplémentaire : il est difficile de bien constituer des jeux d’entraînement et de test.
Usuellement, ces jeux sont construits de sorte à ce qu’ils ne se recoupent pas, pour éviter de fausser l’évaluation sur le jeu de test. En effet, les performances sur un point d’entraînement sont largement meilleures puisque l’algorithme s’est entraîné (a donc minimisé son erreur) sur celui-ci.
Dans notre cas, si nous prenons deux mailles adjacentes, certaines de leurs variables seront identiques car provenant d’une échelle plus large. Par exemple, si nous connaissons le nombre de tête de bétail à l’échelle du département, alors toutes les mailles de ce département auront la même valeur pour cette variable. En conséquence, si nous utilisons une maille dans le jeu d’entraînement et sa voisine dans le jeu de test, nous risquons de nous trouver dans le cas où ces mailles sont quasi identiques.
Par ailleurs, nous ne pouvons pas utiliser une région d’entraînement et une région de test car les propriétés propres à la région de test ne seront pas apprises par l’algorithme. Imaginons que nous utilisons la région de Bordeaux en échantillon de test, et la Bretagne pour l’entraînement. L’algorithme n’aura presque jamais rencontré les caractéristiques propres à la viticulture, structurantes du territoire et ne être précis sur le jeu de test.
Nous n’avons pas eu l’occasion d’établir une stratégie qui remédie aux deux problèmes contradictoires (l’idéal étant l’utilisation de mailles suffisamment proches pour suivre la variabilité des variables d’accompagnement, mais suffisamment distantes pour ne pas favoriser de redondance) et avons résolu uniquement le deuxième problème en prenant un sous ensemble de maille aléatoirement réparties sur le territoire pour l’ensemble de test, avec la contrainte que la distribution de la variable cible soit similaire pour les deux jeux formés. Une piste d’amélioration serait de considérer la variable avec l’échelle la plus grande et d’adapter la séparation par rapport à cette variable.
Travailler sur un périmètre limité
Lors de cette étude, nous avons tenté d’intégrer des données issues de l’imagerie satellite (images LANDSAT) qui ont été pré-traitées et labellisées par les experts de l’OFB, suivant une méthode développée par l’UMR Tetis. L’objectif de cette méthode est de classifier les parcelles agricoles, connues précisément grâce au référentiel parcellaire graphique, selon des classes de couverture végétale (sol nu, végétation rase, basse, haute, hétérogène). Les images satellites sont un outil très puissant car elles permettent d’analyser finement une grande partie des parcelles, avec un pixel représentatif de 10 m (programme européen Sentinel).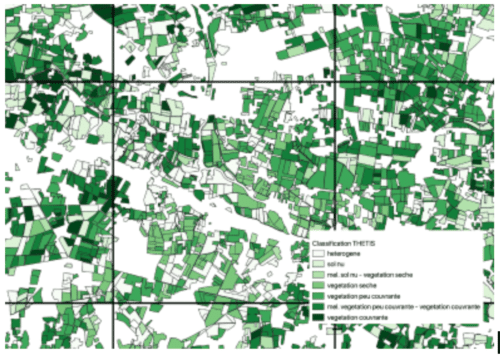
Malheureusement, la labellisation nécessitant l’intervention d’un expert et une vérification sur le terrain, le jeu de données résultant n’a pu être réalisé que sur un sous ensemble géographique et temporel. Le modèle d’optimisation n’intégre que les maille de 5x5km disposant à la fois d’une classification, à la fois de contrôles historiques, et ne laisse ainsi plus assez de points pour entraîner un modèle.
Pour résoudre ce problème, nous avons construit un algorithme en deux étapes : un algorithme semi-supervisé pour enrichir le jeu de données, suivi d’un algorithme supervisé qui réalise l’apprentissage à partir du jeu de données enrichi.
Le premier algorithme utilise KNN pour labelliser itérativement, sur la base de leur similarité, des points du jeu de données. A chaque passe, un algorithme de détection d’outliers (Isolation Forest) retire les points anormaux ajoutés par le KNN (artefacts induits par le système de vote).

Le résultat du deuxième algorithme est un simple arbre de décision. Ce choix est guidé par le manque de données qui ne nous permet pas de construire un jeu de test. Sans jeu de test, nous ne pouvons pas évaluer l’algorithme par une métrique. Toutefois, l’algorithme d’arbre de décision met en lumière les règles qui ont conduit l’algorithme à sa prédiction. Avec un support des métiers, il est donc possible d’évaluer la pertinence du résultat sur la base des règles induites par l’arbre.
DataViz : concilier une phase de développement POC avec de fortes attentes côté métier
La dernière étape de projet consistait à concevoir une interface web permettant de représenter visuellement les modèles calculés précédemment. Cette interface devra être ergonomique et compréhensible malgré un nombre important d’informations à afficher tout en restant ludique afin d’aider son adoption par ses utilisateurs, une amibition étant d’utiliser cet outil pour permettre aux inspecteurs de formuler leurs remarques sur les résultats des algorithmes précédemment développés. Malgré certaines contraintes techniques, nous sommes arrivés à notre objectif en termes de réalisation dans le temps imparti grâce à l’utilisation d’outils robustes qui répondaient parfaitement à nos besoins.
Le premier d’entre eux concerne la partie graphique de l’application. Il s’agit de Figma, un logiciel de design d’interface collaboratif en temps réel qui nous a permis de réaliser la 20e de maquettes d’écran du projet. La bonne conception de celles-ci est primordiale afin d’harmoniser les développements avec les souhaits du client. Elles permettent en outre de définir plus facilement une backlog détaillée qui sera par la suite très utile pour organiser la charge de travail.
Le second outil est une bibliothèque développée par Facebook et devenue très populaire : React. Celle-ci permet de créer des applications web « one-page » en JavaScript avec un système de composants qui réagissent aux changements d’état du système et aux interactions de l’utilisateur. Nous avons choisi d’implémenter cette bibliothèque avec une architecture de type Flux à l’aide de la bibliothèque Redux afin d’obtenir une interface stable et réactive. Cette dernière permet de facilement gérer un état global de l’application permettant ainsi de réduire certains temps de chargement et d’assurer une meilleure réactivité entre les différents composants de notre application.
Pour la partie visualisation des données géospatiale et des cartes, deux systèmes ont été utilisés afin de charger les données dans la bibliothèque Mapbox qui se chargera du rendu graphique. Le premier concerne les données de petit volume et de haute criticité, telles que les coordonnées GPS et résultats des anciens contrôle de pollution. Celles-ci sont chargés par une API web dédiée et sécurisée. Pour les données plus volumineuses mais de criticité moindre, nous les avons ajouté au service web de Mapbox qui permet d’héberger ces lourdes couches et de les charger dans l’interface du client en fonction des besoins de son affichage actuel (Haute résolution uniquement envoyée pour un grand niveau de zoom et donc pour une zone limitée). Ce chargement partiel des données a été crucial pour mettre en place la visualisation des cours d’eau et des exploitations agricoles du territoire puisque leurs fichiers sources pesaient plusieurs Go.
L’interface React permet ensuite de filtrer dans les différentes couches affichées par Mapbox afin d’avoir le rendu visuel souhaité. L’interface permet également de consulter la légende des différentes couches, tant pour les données de prédiction issues du modèle que pour les features d’origine. Enfin, l’importance de chacun de ces paramètres dans le calcul de prédiction a été représenté sous forme de graphique grâce aux SHAP values afin d’aider les opérateurs à comprendre le fonctionnement du modèle.
Finalement, pour faciliter le déploiement de l’application en production, nous avons confiné l’ensemble de la réalisation dans un conteneur Docker. Ainsi, les équipes du BRGM ont pu récupérer facilement le code source et le déployer très rapidement en production sans se confronter aux problèmes fréquents lors des changements d’environnement. Le transfert d’ingénierie et d’administration du service, objectif affiché de la mission Etalab au sein de la DINUM et la DITP à l’origine de l’appel à manifestation d’intérêt, a ainsi été servi par une collaboration technique facilité. Le transfert de compétence sur l’apport de l’intelligence artificielle repose quant à lui sur l’articulation entre data-analysts de Quantmetry et experts de l’OFB, servis par une solution lisible et ergonomique.
Conclusion
Dans ce projet de priorisation des contrôles des pollutions chimiques diffuses, l’introduction de données géolocalisées rend nécessaire l’utilisation de technologies supplémentaires à la stack de data science classique comme l’extension PostGIS ou la bibliothèque GeoPandas. Ces outils permettent d’exploiter pleinement l’information de position à travers des fonctions comme les intersections spatiales ou bien les buffers.
Par ailleurs, la diversité des éléments géographiques, autant au niveau de leur nature que de leur échelle, demande un important travail de conciliation et d’agrégation des données. Nous le voyons particulièrement lors de la phase de feature engineering, où chaque feature doit être calculée à la même maille mais est issue d’échelles géographiques différentes (zones hydrographiques pour les écoulements, villes pour les ventes, etc).
La méthodologie de modélisation et d’entraînement doit aussi s’adapter aux spécificités géographiques : pour évaluer la bonne généralisation spatiale d’un algorithme, il convient de s’assurer que les éléments du jeu de test et d’entraînement ne sont pas trop proches spatialement.
Une fois ces défis relevés, comme dans tout projet de data science, il faut rendre les résultats utilisables et compréhensibles par les utilisateurs finaux; par exemple, par un outil de visualisation. Un des challenges de la visualisation est d’être suffisamment claire et fluide, ce qui n’est pas aisé avec plusieurs millions de polygones (carte des parcelles agricoles). Le choix des technologies est crucial et le mix Mapbox et React-Redux a répondu à nos attentes.
Les cas d’usage à partir de données géolocalisées sont nombreux et le machine learning peut apporter une solution viable, à la condition d’adapter aussi bien les technologies utilisées que les méthodologies classiques aux spécificités de ces données, et de garantir la cohérence de leur utilisation tout au long des processus d’intégration et de modélisation.
(1) A l’échelle départementale, le processus d’élaboration du plan de contrôles est collégial et sous l’autorité du préfet, et réalisé par les missions interservices de l’eau et de la nature. Sont impliqués, en plus de l’OFB, les directions régionales et départementales, certaines fédérations, collectivités et établissements publics, sous coordination du Ministère de la Transition Ecologique et Solidaire. En considérant l’ensemble des contrôles de ces organisations, dont ceux des installations classées pour la protection de l’environnement, ce sont plusieurs milliers d’agents qui sont concernés.