

Model As Code : automatisation du déploiement de modèles R en production (2/2)
RETOUR D’EXPÉRIENCE SUR UNE IMPLÉMENTATION BIG DATA
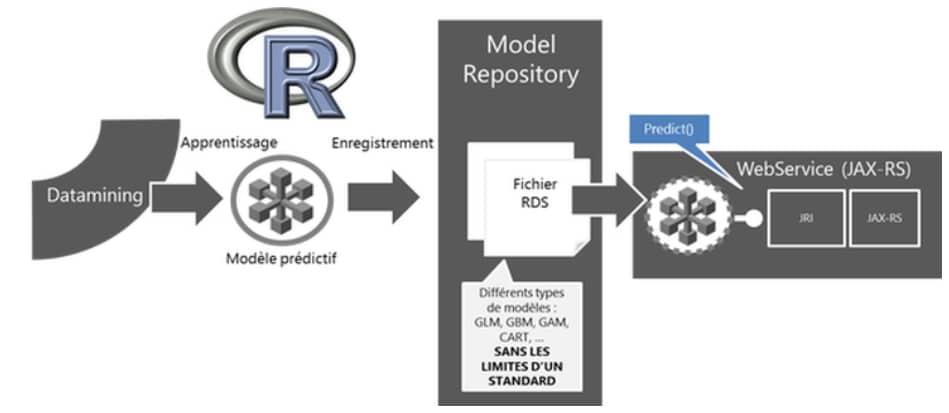
Dans l’article précédent – Model As Code 1/2 – les grands mécanismes de l’approche ont été couverts ainsi que son implémentation sous la forme d’un web service. Cette approche permet de déployer un modèle prédictif, développé et enregistré sur R comme un service web et d’activer des prédictions à la demande au travers d’une API Rest.
Figure 1 : Model as code – web service
Dans ce billet nous nous intéressons à notre retour d’expérience de son implémentation sur une plate-forme « Big Data » – Hadoop. L’objectif premier est là encore de diminuer voire d’annuler le temps de mise en production d’un modèle en exploitant la capacité de R à sérialiser n’importe quel objet sous la forme d’un fichier .rds pour le transférer d’une plate-forme de data mining (apprentissage) à celle de production (prédiction).
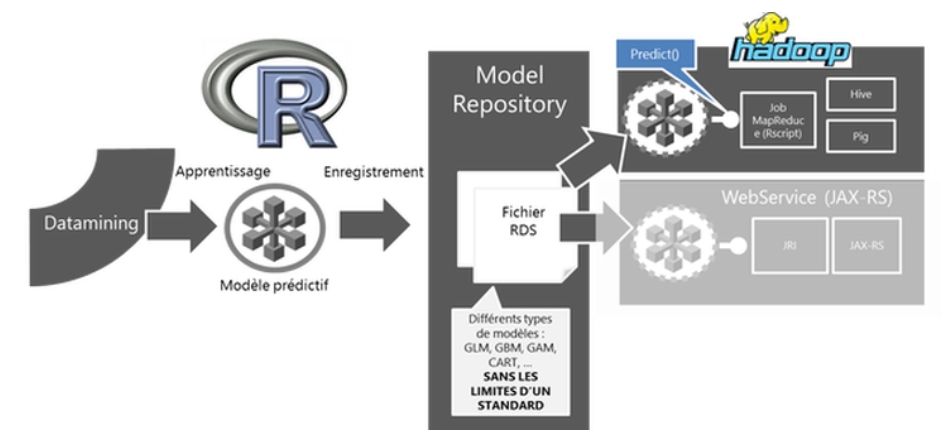
Figure 2 : Model as code – Hadoop
Les attentes et enjeux d’une exploitation d’un modèle prédictif sur une plate-forme Big Data sont complémentaires avec ceux attendus par une plate-forme Webservice. Contrairement au Webservice qui se doit d’être léger et réactif pour une utilisation en production, ce qu’on attend d’une plate-forme Big Data-Hadoop est de pouvoir scorer en batch de larges quantités (du Tera au Peta octet) de données en un temps prévisible et entièrement scalable.
REVUE DE DIFFÉRENTES IMPLÉMENTATIONS POSSIBLES
Si l’on part du principe que l’on dispose d’un cluster Hadoop de N machines avec R installé sur chacune d’entre elles, et que le fichier à scorer se trouve sur HDFS, voici les étapes que l’implémentation doit assurer pour exploiter un modèle R en format .rds :
-
Récupérer puis distribuer le modèle R (fichier .rds) sur toutes les machines ;
-
Lancer une session R sur chacun des nœuds et charger le modèle R ;
-
Récupérer les données à scorer ;
-
Effectuer la prédiction ;
-
Consolider et restituer les résultats de la prédiction – (rôle d’Hadoop)
L’étape 1 ne présente pas un enjeu technique particulier car Hadoop dispose de base d’une fonctionnalité appelée DistributedCache. Cette fonctionnalité permet de manière transparente de distribuer un fichier tiers, en read only, dans la mémoire de chacun des nœuds et donc de rendre le fichier accessible à n’importe quel Job MapReduce. Elle est par exemple activable par l’option –files lors du lancement d’un job MapReduce en ligne de commande ou par l’instruction add files dans Hive.
Pour le reste des étapes, Hadoop propose plusieurs mécanismes pouvant être actionnés. En voici une liste (très certainement loin d’être exhaustive) qu’il est possible de considérer:
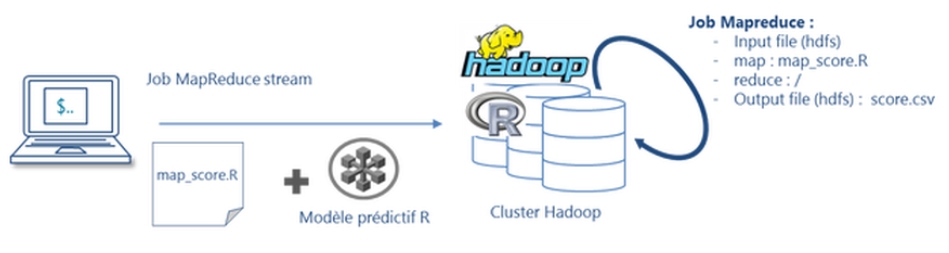
1. L’utilisation de la fonctionnalité Hadoop streaming
Hadoop streaming est une fonctionnalité puissante qui permet à Hadoop de générer ses jobs Map ou Reduce à partir de scripts écrits dans n’importe quel langage capables d’interagir avec l’entrée et la sortie (I/O) standard (soit virtuellement tous les langages imaginables).
Il est alors possible d’écrire un script R qui fera office de mappeur et qui se chargera des étapes de 2. à 4. Il suffit en effet de positionner ce script à l’écoute de l’entrée standard pour capturer les clefs/valeurs envoyées par hadoop via stdin ; charger le modèle rds ; faire appel à la fonction predict() du modèle ; renvoyer les résultats par la fonction cat().
2. L’utilisation de la fonctionnalité Hadoop streaming… par Hive ou Pig
La notion de streaming n’est pas limitée à une utilisation purement encadrée par MapReduce il est possible de l’exploiter avec Hive grâce à la fonction TRANSFORM() et avec Pig grâce à la fonction STREAMING(). L’intérêt le plus évident est qu’il devient alors possible d’exploiter des données directement accessible HCatalog et donc avec une structure et un schéma maîtrisés.
3. L’écriture d’UDF et leur exploitation par Hive ou Pig
Hive et Pig offrent la possibilité de rédiger et d’exploiter ses propres UDF (User Defined Function) écrites en Java. Leurs implémentations sont généralement plus complexes que l’écriture et l’exploitation de scripts map ou reduce par streaming. Mais elles ont pour principaux avantages :
-
s’affranchir des limitations d’échanges d’informations par l’IO standard. Ces limitations peuvent-être, un potentiel plafonnement de performances en read/write et surtout une exploitation de données sérialisées à priori plus complexe (fichiers .avro, .parquet souvent utilisés pour accélérer des traitements lourds en IO…)
-
proposer un framework solide capable d’offrir plus de contrôles sur la gestion des actions effectuées sur les données manipulées lors de l’exécution de jobs (exemple : s’assurer d’effectuer certaines tâches qu’une seule fois, comme le chargement du modèle et bibliothèque et une gestion « optimisée » du passage d’informations constantes…).
L’idée de cette approche est donc, comme dans le cadre de la mise en production par webservice, d’encapsuler des instructions R dans du code java grâce à la libraire rJava puis de faire exécuter ce code par les jobs MapReduce générés par les requêtes Hive ou Pig.
RETOUR SUR L’IMPLÉMENTATION
Pour l’intérêt technique et les avantages cités plus haut nous nous approfondissons dans cet article les étapes et les fonctionnements d’une implémentation par UDF Hive. Schématiquement cette approche doit respecter le cycle de vie suivant :
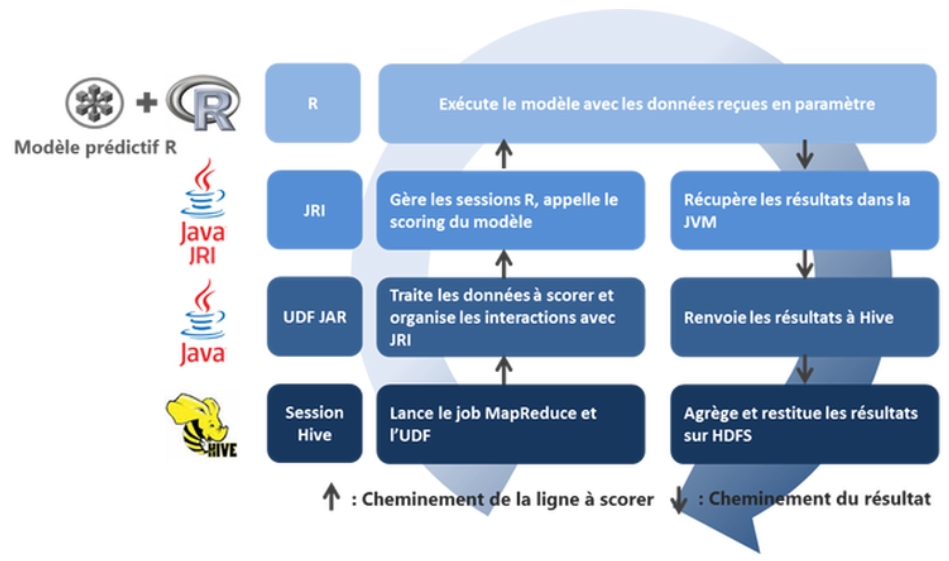
Figure 3 : Cycle de vie d’une requête de prédiction
Pour ce faire voici les différentes étapes ou briques à développer et à organiser.
-
Configuration des nœuds
L’étape préliminaire avant de commencer tout développement est de configurer tous les nœuds du cluster pour garantir un bon interfaçage entre Hadoop et R (Installations de R et de JRI ; mises à jour de variables d’environnement ; partage de fichiers binaires …).
-
L’écriture de l’UDF
C’est la partie centrale de l’approche, l’UDF organise et gère les flux de données entrants et elle orchestre les appels aux fonctionnalités R grâce à la librairie JRI. Pour plus d’informations sur l’écriture d’UDF Hive nous recommandons la lecture de l’excellent livre « Programming Hive ».
-
L’écriture de la requête Hive
C’est elle qui lance la procédure de scoring et transmet les données à scorer ainsi que les métadonnées ou constantes. Ces métadonnées sont par exemple : le nom du modèle R à appeler et une chaîne de correspondance des champs attendus par le modèle R avec les noms des colonnes de la table Hive passés en paramètre à l’UDF.
RÉSULTATS DE L’IMPLÉMENTATION
Cette approche permet là encore de pratiquement annuler le temps de mise en production des modèles R développés par les équipes Data Miner. Concrètement, une fois les briques et la « tuyauterie » développées, les seules actions incompressibles restent les suivantes :
-
sauvegarder le modèle R en fichier .rds dans un répertoire cible (une ligne de code à exécuter : saveRDS() )
-
mettre à jour la requête Hive, pour qu’elle pointe vers le nouveau modèle ;
-
s’installer confortablement et admirer les mappeurs se répartir et s’exécuter sur le cluster pendant que son voisin recode son modèle en C++…
RETOURS SUR PERFORMANCES
De manière prévisible, les tests effectués ont montré qu’en dessous d’une certaine volumétrie, l’approche avait peu d’intérêt à cause des temps incompressibles qu’imposent Hive et Map Reduce à l’initialisation des jobs.
Concrètement d’après nos tests, scorer entre 1 et 1 000 000 de lignes prenait un même temps moyen de 40s sur VM (fluctuant de manière arbitraire entre 30s et 50s). Au-delà, au-dessus du million de lignes, les fichiers deviennent suffisamment volumineux pour observer l’intérêt d’un traitement en parallèle par Hadoop. La montée en charge devient alors linéaire.
CONCLUSIONS DES RETOURS D’EXPÉRIENCE
Le développement de l’UDF Hive a dû se faire de manière itérative pour aligner correctement les informations à passer en paramètres avec celles nécessaires pour garantir que l’étape de scoring avec R se fasse de manière fiable et robuste aux erreurs.
Nous avons été surpris par les problèmes rencontrés sur les phases de configuration des nœuds et l’interfaçage entre Hadoop, JRI et R. En effet certaines parties nous ont paru relativement complexes et peu intuitives (la liste des variables d’environnement à mettre à jour, le déplacement de certains fichiers binaires dans des répertoires partagés d’Hadoop etc..).
Par contre une fois cette configuration initiale faite nous avons été agréablement surpris de constater que les fonctionnalités d’Hadoop tenaient leurs promesses sans problème. LeDistributedCache assure de manière transparente une accessibilité aux mappeurs aux fichiers distribués (le modèle R – rds, les .jar de librairies et d’UDF) et le côté linéaire et full scalable des résultats face à la montée en charge a pu être constaté sans aucun effet de bord.
CONCLUSION GÉNÉRALE DES RETOURS D’EXPÉRIENCE DE L’APPROCHE MODEL AS CODE
Les deux retours d’expériences d’implémentation de l’approche « model as code » ont su démontrer qu’il était possible d’intégrer R en environnement de production et qu’il est restrictif de le considérer «seulement » comme un outil de développement ou d’exploration.
Au-delà de l’approche en elle-même il est aussi intéressant de noter, qu’il est facile de mettre en place deux implémentations complémentaires niveau fonctionnalités. Une exploitation type Webservice capable de scorer à la volée des lignes soumises par API et une exploitation sur cluster Hadoop pour une exploitation batch (qui commence à être intéressante là où justement la partie webservice commence à rencontrer des limites).
Les possibilités d’implémentation de l’approche sont nombreuses et généralisables à beaucoup d’autres technologies et nous pensons notamment la tester sur Apache Spark ou Apache Storm très prochainement…
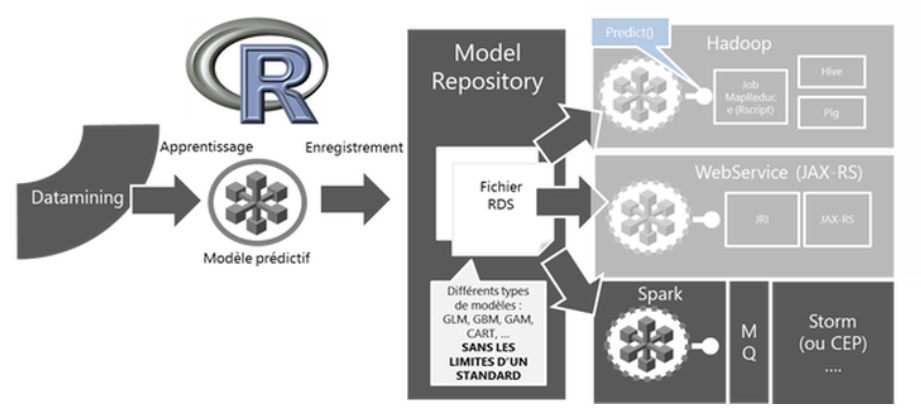
Figure 4 : Model as code – web service
