

Comment mieux modéliser, analyser et décider pour vos cas d’usage en prévision ?

Introduction
Pourquoi l’initiative d’un démonstrateur ?
La prévision est aujourd’hui une problématique business que l’on retrouve dans toutes les industries. De la prévision de la demande à celle d’indicateurs financiers en passant par la consommation énergétique, tous les domaines se confrontent à des enjeux de prévisions. Les défis techniques liés à ce domaine ne sont quant à eux pas nouveaux. Il existe d’ailleurs dans la littérature une grande variété de méthodes pour prévoir l’évolution d’une série dans le temps, dont certaines ne datent pas d’hier.
Récemment, à l’ère des « open data », les techniques de prévision ont de nouveau évolué afin de prendre en compte des données externes et ainsi améliorer les prévisions effectuées.
Face à toutes ces avancées, il est légitime de se demander quel est l’apport de chaque méthode et comment les combiner pour décupler leur potentiel. La question des variables à intégrer pour obtenir de meilleures performances tout en se basant sur des observations pertinentes peut elle aussi se poser.
Chez Quantmetry, nous disposons d’un pôle composé d’experts en prévisions dont le rôle est justement de répondre au mieux à l’ensemble de ces questions.
C’est dans ce contexte que, fin 2019, l’ASHRAE (American Society of Heating, Refrigerating and Air‑Conditioning) a lancé un challenge sur la célèbre plateforme Kaggle (https://www.kaggle.com) : prévoir la consommation électrique de son parc de bâtiments.
L’objectif ? Comparer les consommations prévues aux consommations observées après des travaux de rénovation et ainsi mesurer les économies d’énergie réalisées.
Notre équipe d’experts a décidé de répondre à ce défi en proposant une application permettant notamment de benchmarker un ensemble de modèles de prévision afin de pouvoir sélectionner le meilleur sur le jeu de données considéré.
De la création de cette application est née l’envie de condenser le savoir-faire de Quantmetry au sein d’un démonstrateur dont le rôle est d’offrir le panel le plus complet possible de nos différenciants en matière de prévision, le tout en trois onglets : Modéliser, Analyser, et Décider.
Dans cet article, nous présenterons notre vision d’un projet de prévision au travers de la présentation du démonstrateur, dont nous détaillerons par la même occasion les différentes fonctionnalités techniques.
Notre vision d’un projet de prévision
Utiliser les meilleurs outils pour prédire finement, à la fois localement et globalement, est aujourd’hui un enjeu important pour le domaine, et le Machine Learning et l’Intelligence Artificielle sont alors sans conteste de grands atouts pour y parvenir.
Bien que la recherche de performance soit un enjeu clé, nous pensons aussi que d’autres éléments doivent être pris en compte pour construire une prévision optimale. Nous jugeons qu’il est important de pouvoir :
- Évaluer l’impact de l’intégration de variables externes comme les données météorologiques, qui peuvent jouer un rôle non négligeable dans l’amélioration des performances de la prévision.
- Fournir des leviers d’explicabilité des prédictions faites afin de quantifier l’influence de chaque variable ou comportement dans une décision prise par un modèle.
- Intégrer des degrés de certitude liés à chaque estimation. En effet, dans de nombreux cas et du fait de l’incertitude liée à chaque prévision, les méthodes classiques de prévision ne sont pas suffisantes pour répondre à une problématique donnée. Les méthodes probabilistes (qui permettent d’intégrer des intervalles de confiance aux prévisions classiques) sont alors plus adaptées pour prédire une fourchette acceptable dans laquelle la valeur réelle sera incluse. Pour aller plus loin dans l’analyse des méthodes probabilistes, on pourra se référer à un autre article de notre blog : les prévisions probabilistes avec DeepAR.
Conscients de tous ces besoins, nous avons l’ambition d’apporter une réponse à l’ensemble des enjeux cités grâce à des méthodes et outils performants et sur mesure pour s’adapter à chaque problématique individuelle et ainsi augmenter significativement la valeur ajoutée des projets de prévision de nos clients.
Pour les accompagner et être un facteur clé de succès de leurs projets de prévision, nous nous appuyons sur 4 accélérateurs :
Un pôle d’expertise dédié à la prévision parmi l’ensemble de nos Quanters.
Une Quant Approach définie par un accompagnement de bout en bout des projets, depuis la phase d’exploration des données jusqu’à la phase de mise en production.
Une approche algorithmique à l’état de l’art, adaptée à chaque cas d’usage, et que nous perfectionnons toujours plus au sein de notre Quant Lab.
Des Quant Stories multi-sectorielles, acquises auprès de dizaines de références.
1. Contexte
Les données utilisées
En nous basant sur les données issues du challenge Kaggle que nous avons relevé, nous prenons l’exemple d’une administration qui souhaite effectuer des travaux sur ses bâtiments afin de réduire son empreinte environnementale.
Pour mesurer l’impact des rénovations, celle-ci souhaite prévoir la consommation électrique de ses différents bâtiments avant les travaux pour la comparer à la consommation effective après les travaux.
Nous prenons alors le rôle d’un prévisionniste dont le but serait de modéliser la consommation énergétique du parc de bâtiments pour obtenir les prévisions avant le début des travaux.
Parmi les bâtiments que nous souhaitons rénover, nous disposons de 4 typologies très différentes dans leur comportement selon le jour de la semaine et l’heure de la journée : une école, une résidence, un parking, et des bureaux.
Les bases de la prévision de séries temporelles
Lorsque l’on souhaite effectuer la prévision d’une série temporelle, les principales étapes à suivre sont :
- La séparation de la série en deux : un jeu d’entraînement sur lequel nous entraînons notre modèle à reconnaître les différents comportements de la série, et un jeu de test sur lequel nous effectuons des mesures de la cohérence de nos prévisions. La date charnière sera appelée la « date de cutoff ». Il est très simple de la faire varier sur notre démonstrateur.
- L’analyse du jeu d’entraînement afin d’identifier ses différents comportements notables : la série possède-t-elle des motifs saisonniers ? Une tendance ? Est-ce que des valeurs aberrantes sont présentes et risquent de fausser les prévisions ?
- Dans le cas où le jeu d’entraînement comporte des valeurs manquantes ou aberrantes, il est nécessaire d’effectuer un traitement préalable sur les données en appliquant des méthodes d’imputation notamment.
- Vient ensuite la phase de modélisation, lors de laquelle nous comparons un ensemble de modèles selon différents critères de performance. Une fois le modèle le plus adéquat élu, nous effectuons des tests sur sa robustesse en faisant varier la date de cutoff.
- Enfin, une fois les modélisations effectuées, nous étudions l’influence des différentes variables sur le comportement du modèle pour identifier les plus influentes. Nous vérifions aussi l’incertitude liée aux prévisions en analysant l’intervalle de confiance à 95% associé à chaque mesure.
Voilà, maintenant que nous avons défini les principales étapes à suivre, nous pouvons nous lancer dans leur réalisation avec notre démonstrateur !
2. Préparation des données
Premiers pas dans le démonstrateur
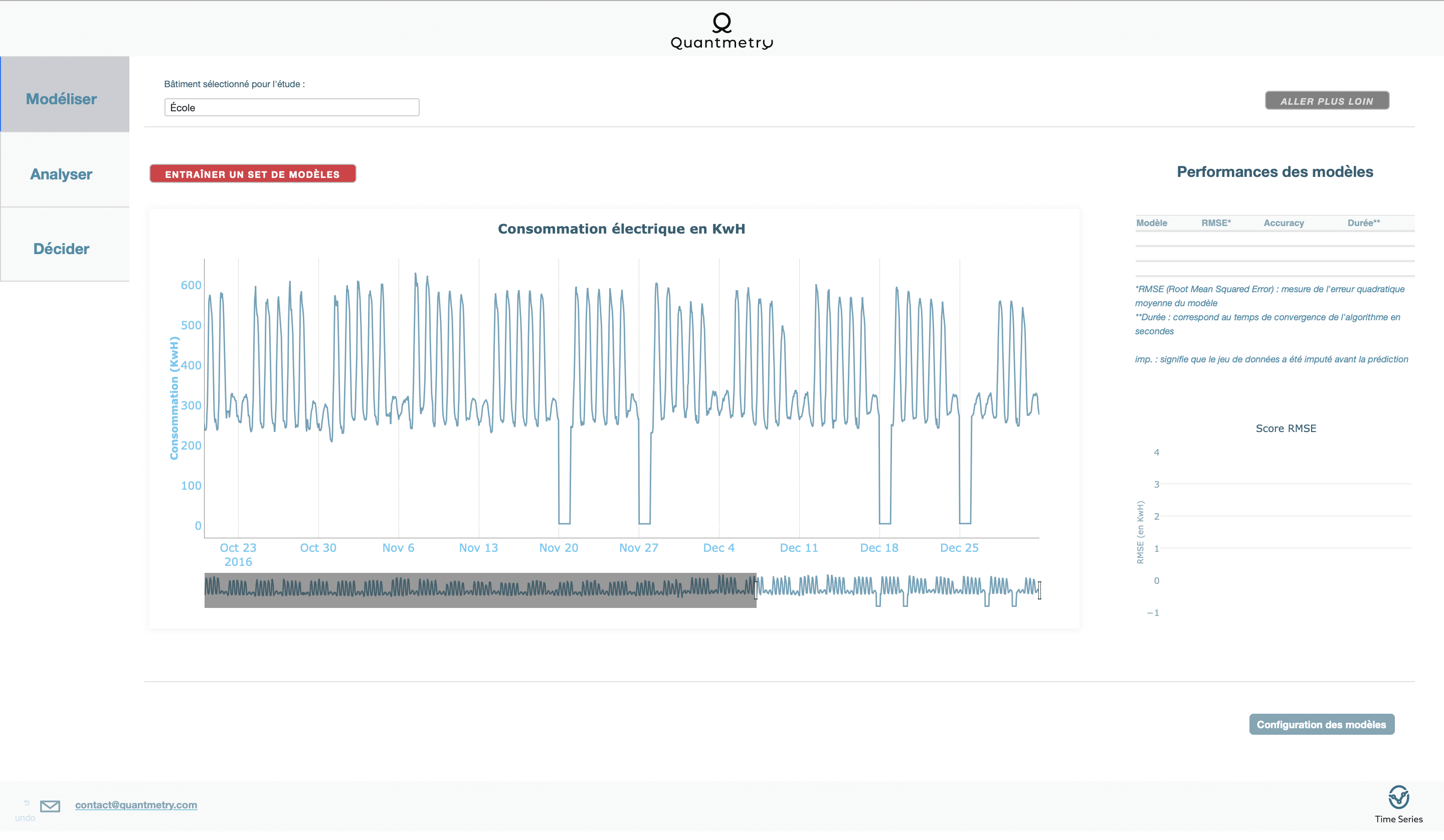
Une fois le démonstrateur lancé, la première chose à faire est de choisir le bâtiment à modéliser. Nous illustrerons cet article avec les données issues de l’école.
En observant la courbe de consommation électrique au cours du temps, nous notons la présence de différents motifs de consommation, notamment un motif quotidien, couplé à un motif hebdomadaire.
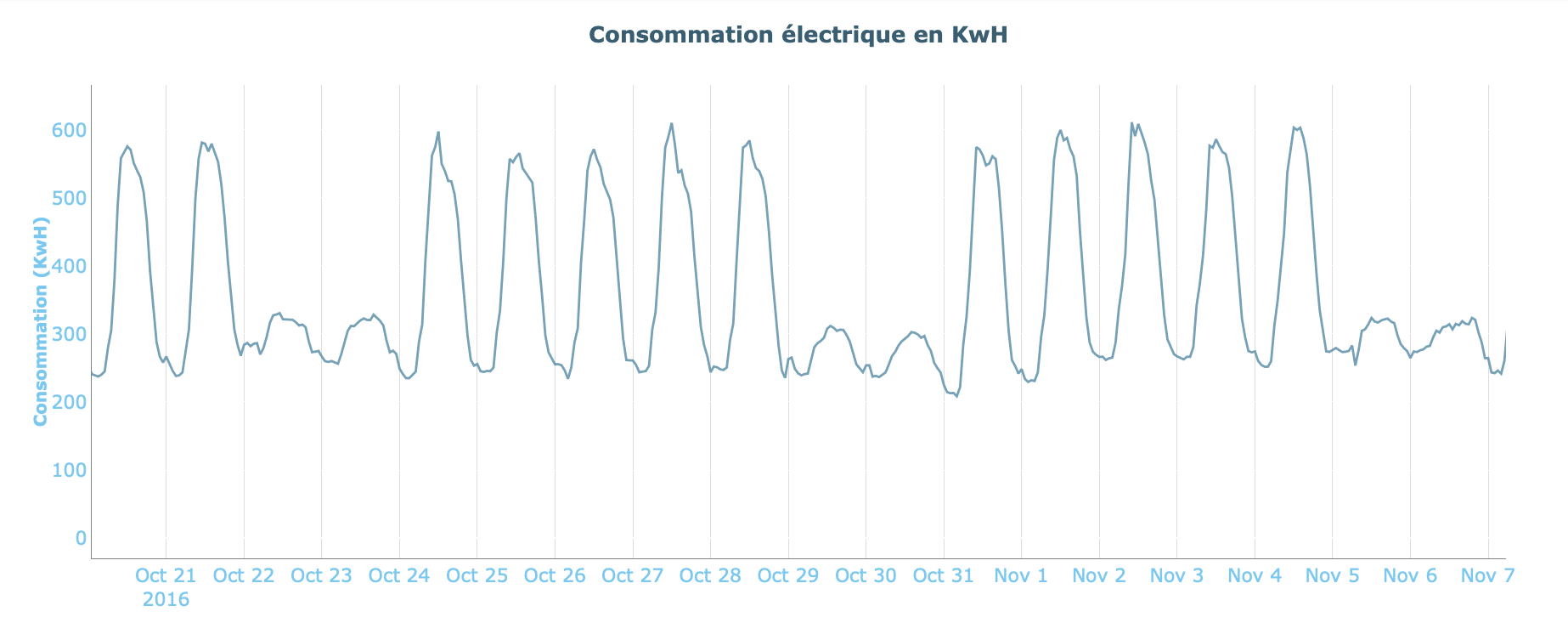
Nous notons aussi la présence de valeurs aberrantes (valeurs proches de 0) dont nous ne connaissons pas l’origine.
Traitement des valeurs manquantes
Comme nous l’avons remarqué précédemment, le jeu de données présente un certain nombre de valeurs proches de zéro. Étant donné l’ordre de grandeur des valeurs prises par la consommation électrique sur les autres intervalles de temps, nous pouvons considérer que ces données proviennent d’erreurs.
Ce phénomène arrive très fréquemment en pratique et peut s’expliquer par diverses raisons, allant de la panne de capteurs à la mauvaise remontée des mesures (et même parfois pour des raisons inexpliquées).
Cependant, lorsque nous étudions des séries temporelles comme c’est le cas ici, laisser des mesures aberrantes ou manquantes dans le jeu d’entraînement peut avoir des répercussions néfastes sur les résultats obtenus par les prévisions qui s’en suivent.
C’est pourquoi il est important d’avoir la possibilité de remplacer ces valeurs par des valeurs plus vraisemblables. On appelle cela l’imputation. C’est un sujet prépondérant dans le domaine de la prévision et nous considérons donc qu’il est nécessaire que notre démonstrateur dispose d’une telle fonctionnalité.
L’imputation sur le démonstrateur
Nous offrons la possibilité d’imputer les valeurs manquantes ou aberrantes de trois façons différentes :
- La première méthode que nous proposons est une méthode assez simple qui consiste à remplacer les valeurs manquantes par la moyenne sur le jeu d’entraînement. Cette méthode permet d’éviter d’induire en erreur les modèles de prédiction en supprimant les valeurs éloignées du jeu de données. Elle convient uniquement lorsque la série ne contient qu’un faible taux de valeurs manquantes.
- La seconde méthode que nous proposons d’appliquer est la méthode dite d’ajustement saisonnal et d’interpolation linéaire. Son principe est de remplacer les valeurs manquantes par une valeur calculée par la désaisonnalisation de la série, suivie d’une interpolation linéaire et d’une “resaisonnalisation” de cette même série. L’objectif de cette méthode plus avancée est de prendre en compte la saisonnalité et la tendance de la série que nous souhaitons imputer.
- Enfin, la dernière méthode que nous avons mise en place est une méthode issue d’un algorithme de Machine Learning : le Gradient Boosting. Ce modèle sera aussi proposé en tant que modèle pour la prévision et il possède la particularité de s’appuyer sur les variables externes de la série et non sur ses comportements temporels comme c’était le cas pour les méthodes précédentes.
Les deux dernières méthodes ont l’avantage d’être plus robustes, ce qui se ressentira notamment lorsque le taux de valeurs manquantes augmentera.
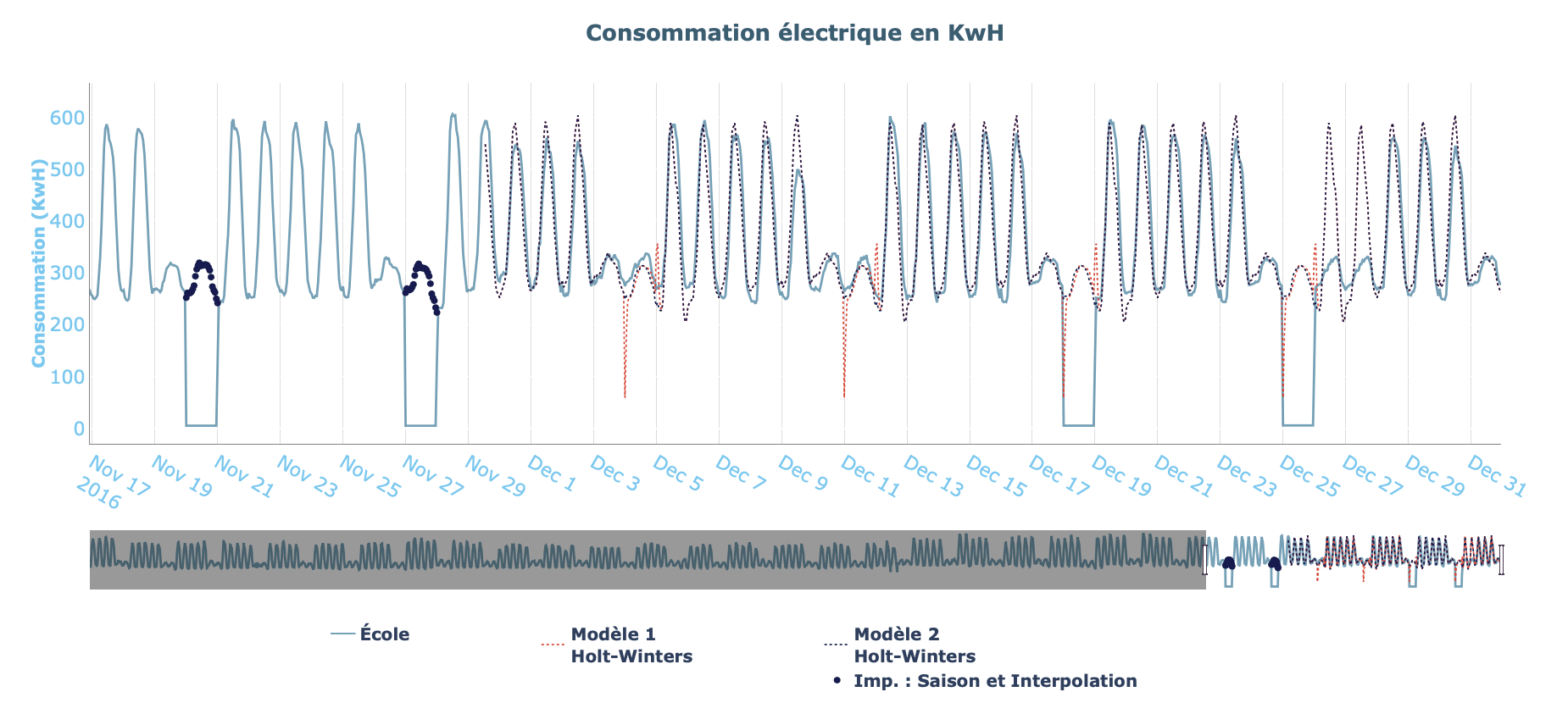
Nous donnons à titre d’exemple les prévisions effectuées par un même modèle mais avec une imputation par ajustement saisonnal et interpolation linéaire dans un cas (Modèle 2) et sans imputation dans l’autre (Modèle 1). Nous voyons clairement que le comportement adopté par la courbe rouge (creux soudains de consommation) n’est pas un comportement attendu et a été causé par la présence de valeurs anormales. Le second modèle a pu corriger ces erreurs grâce à l’imputation.
3. Benchmark des modèles
Choix des modèles utilisés
Afin de répondre à la majorité des problématiques tout en restant rapide et facile à « benchmarker », nous avons fait le choix de proposer trois modèles différents pour la phase de modélisation.
- Le premier modèle dont nous disposons est un modèle de Holt-Winters. C’est un modèle statistique basé sur la décomposition additive d’une série temporelle (tendance, saisonnalité, et résidus). Ce modèle reste assez simple dans son fonctionnement, bien que très performant dans certaines situations. Sa principale limitation se situe dans le fait qu’il ne possède pas la capacité d’inclure des variables exogènes à la modélisation, comme les données météorologiques qui peuvent avoir des conséquences importantes sur la consommation électrique d’un bâtiment.
- Ensuite, le second modèle que nous proposons est un modèle dit de Prophet. Il a été développé et mis en Open Source par Facebook qui l’utilise notamment en interne pour ses routines quotidiennes de prédiction. Tout comme Holt-Winters, il permet la décomposition additive d’une série temporelle, mais en incorporant des cycles saisonniers de façon plus avancée (cycles annuels, hebdomadaires, quotidiens, mais aussi des effets vacances par exemple), ainsi qu’en offrant la possibilité de prendre en compte des variables exogènes dans la modélisation.
- Pour finir, le dernier modèle que nous avons intégré est un modèle de Machine Learning, le modèle de Gradient Boosting. Très différent des modèles statistiques précédents dans sa composition, le Gradient Boosting est un algorithme d’apprentissage supervisé de type ensembliste dont le principe est de combiner les résultats d’un ensemble de modèles plus simples et plus faibles afin de fournir une prédiction globale très fiable. Contrairement aux modèles précédents, ce modèle n’est pas intrinsèquement conçu pour extrapoler les valeurs d’une série temporelle. Toutefois, en lui fournissant des variables porteuses d’information sur la tendance ou la saisonnalité de la série par exemple, il est capable de capturer des corrélations avancées permettant de prédire les valeurs de la série.
Premier entraînement et performances obtenues
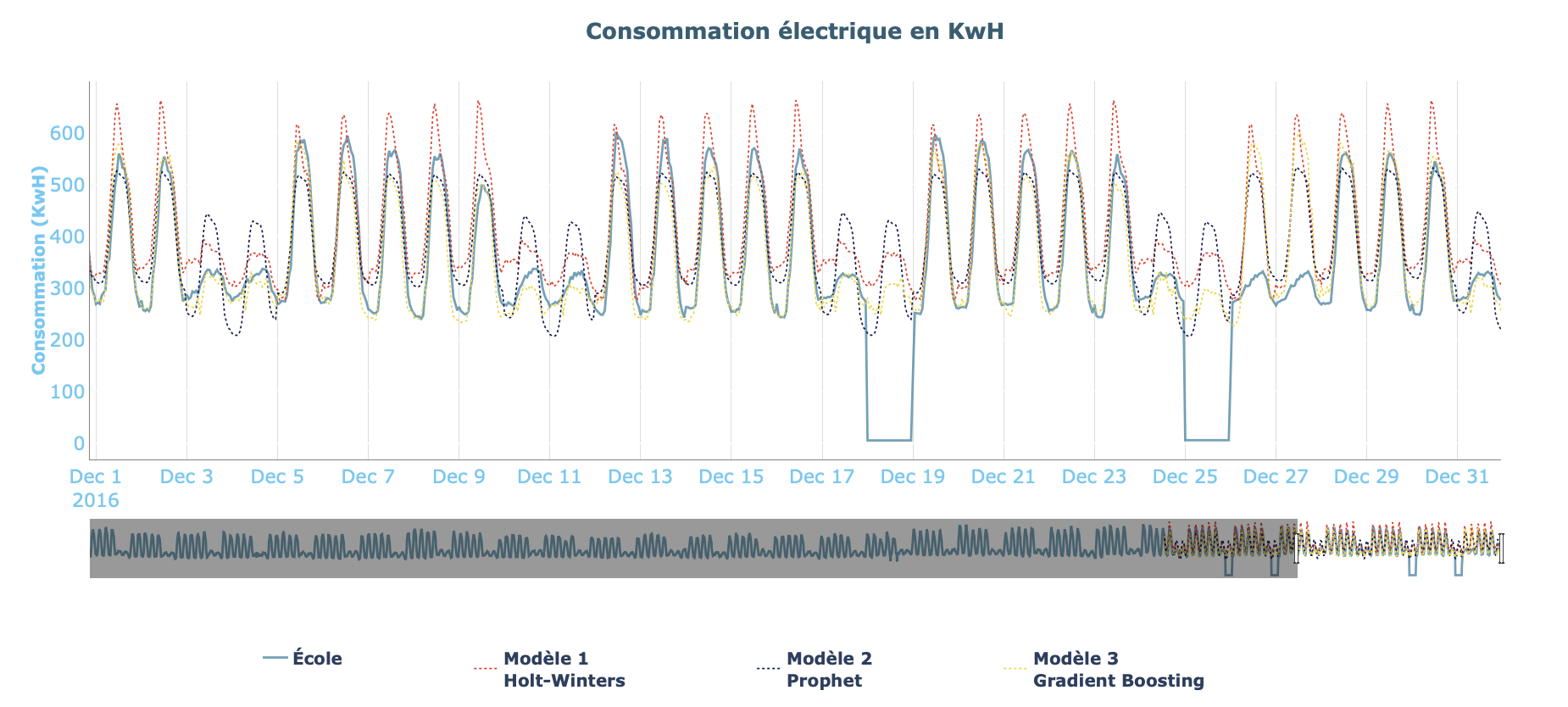
Maintenant que nos trois modèles ont été définis, nous pouvons effectuer un premier entraînement sur nos données. Pour cela, l’application dispose d’un bouton permettant l’entraînement simultané de trois modèles déjà paramétrés avec des réglages de base.
Pour aller plus en détail dans la configuration, il est toujours possible de configurer les paramètres séparément en jouant sur les méthodes d’imputation (si nécessaire), les paramètres propres à chaque modèle (hyperparamètres) ainsi que les variables externes à prendre en compte.
Les résultats obtenus par notre benchmark sont les suivants :
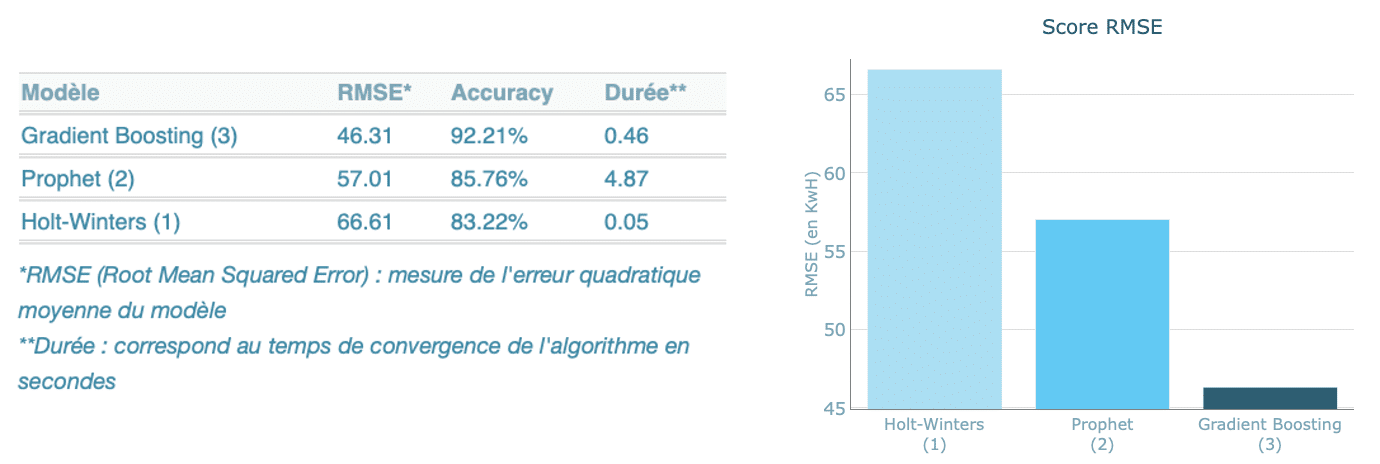
Grâce aux données condensées dans le tableau ainsi qu’au diagramme qui leur est rattaché, nous pouvons très facilement comparer les résultats obtenus.
Nous constatons ainsi que le modèle obtenant les meilleures performances dans notre cas est le modèle de Gradient Boosting.
4. Analyser et décider
Explicabilité
On constate qu’il est possible de benchmarker rapidement une série de modèles pour en trouver le plus performant grâce à l’interface de notre démonstrateur. Cependant, comme nous l’avons évoqué plus tôt, la recherche de performance seule ne suffit pas pour définir un bon outil de prévision. Il est aussi important que le modèle choisi soit explicatif.
L’application est ainsi dotée d’une section “Analyser” dans laquelle il est possible d’obtenir des informations sur l’explicabilité globale et locale pour chacun des modèles.
Bien sûr, cette explicabilité ne prendra pas le même format selon la nature du modèle (statistique ou de Machine Learning).
- Cas 1, modèle statistique :
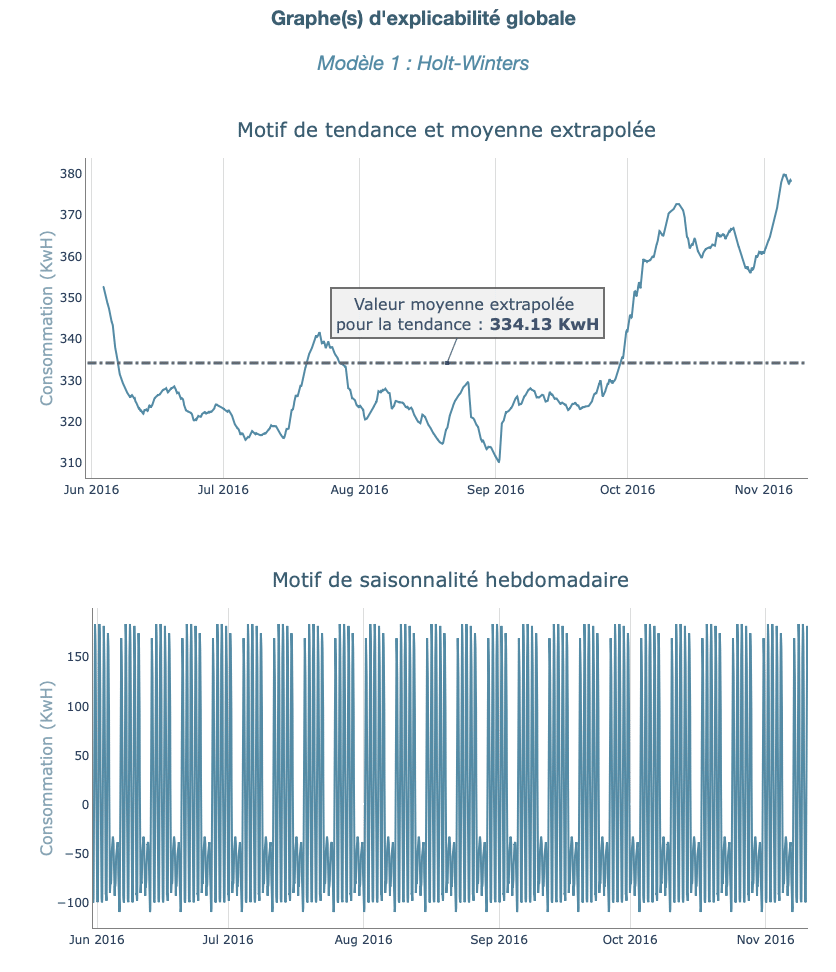
Un modèle statistique se base sur une décomposition du modèle en plusieurs composants. Parmi ceux-ci, on compte la tendance, une ou plusieurs saisonnalités, ainsi que des résidus.
L’explicabilité globale d’un tel modèle consiste alors en la décomposition de celui-ci en chacun de ses composants. Dans le cas de Holt-Winters, cette décomposition est simple car elle ne fait apparaître qu’une tendance et un cycle quotidien, comme nous le voyons sur l’image ci-dessous.
En revanche, la décomposition du modèle Prophet est plus avancée et fait apparaître plusieurs termes saisonniers (horaire, quotidien, hebdomadaire, mensuel, ainsi qu’un motif composé des variables exogènes sélectionnées).
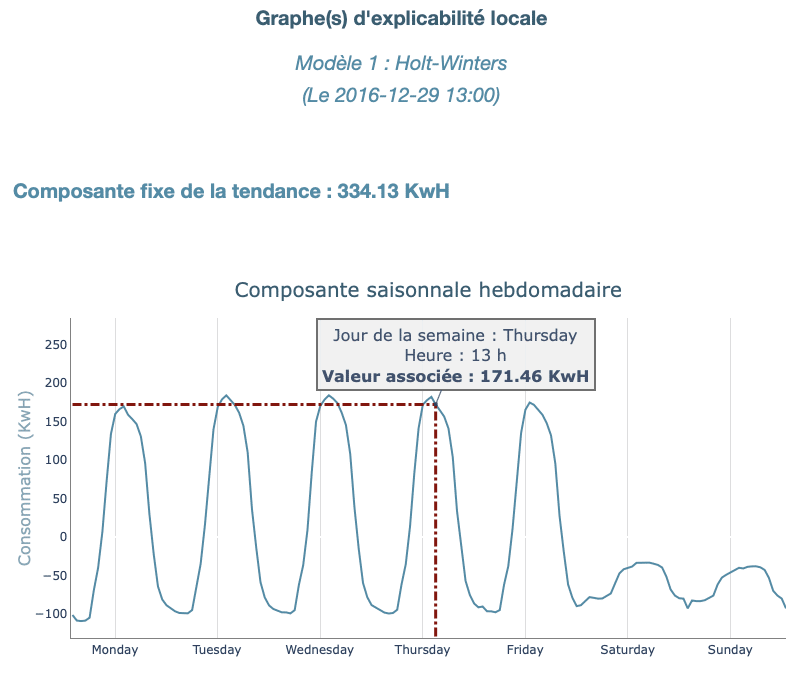
Concernant l’explicabilité locale, celle-ci dérive directement de l’explicabilité globale et consiste en l’extrapolation des différentes valeurs des composants pour un point donné. Nous affichons ici l’explicabilité locale pour un point aléatoire des prévisions effectuées par un modèle Holt-Winters.
- Cas 2, modèle de Machine Learning :
Pour ce qui est des modèles de Machine Learning (Gradient Boosting dans notre cas), la décomposition est différente puisqu’elle ne fait pas apparaître de cycles mais plutôt l’influence de chaque variable sur les décisions. Cette influence sera affichée à la fois globalement (poids de chaque variable sur l’ensemble des prévisions de l’algorithme), et localement (poids de chaque variable pour une décision donnée).
Voici ci-dessous un exemple de décomposition pour un modèle Gradient Boosting.
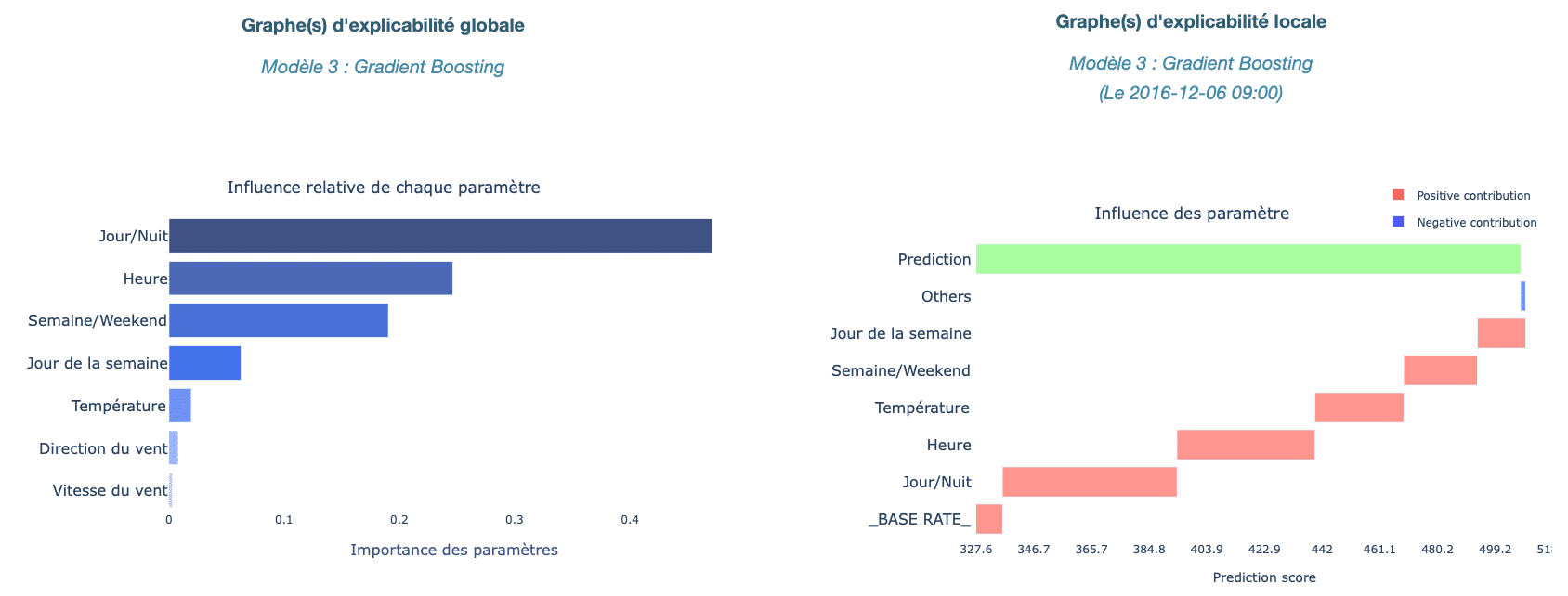
Cette décomposition s’appuie sur les valeurs de Shapley qui correspondent à une décomposition additive de l’influence de chaque variable sur la prédiction. Si vous souhaitez aller plus loin sur le sujet, les travaux de Shapley sont repris dans cet article : The Shapley Value.
Grâce à ce module, l’utilisateur pourra facilement comprendre les décisions prises par l’algorithme (notamment les raisons de certains pics ou creux de consommation), mais aussi étudier l’influence des différents paramètres sur la consommation énergétique du bâtiment.
Intervalles de confiance
Parce qu’une prévision ponctuelle n’est pas suffisante pour prendre une décision, le démonstrateur arbore une dernière section nommée “Décider” qui permet d’intégrer pour chaque prévision effectuée les intervalles de confiance à 95% associés au modèle utilisé. Cela permettra de conforter l’utilisateur dans ses choix ou de l’avertir de la volatilité des prévisions dans le cas opposé.
Selon la nature du modèle, l’aspect de cet intervalle peut changer. En effet, les intervalles de confiance liés aux modèles statistiques auront tendance à s’élargir fortement avec l’horizon sur lequel sont effectuées les prévisions. Les hypothèses prises sur la tendance et les différents motifs auront tendance à être de moins en moins fiables avec le temps, ce qui se ressentira au niveau de la taille de l’intervalle de confiance. Nous voyons par exemple ici les prédictions faites par un modèle Prophet ainsi que l’intervalle de confiance associé.
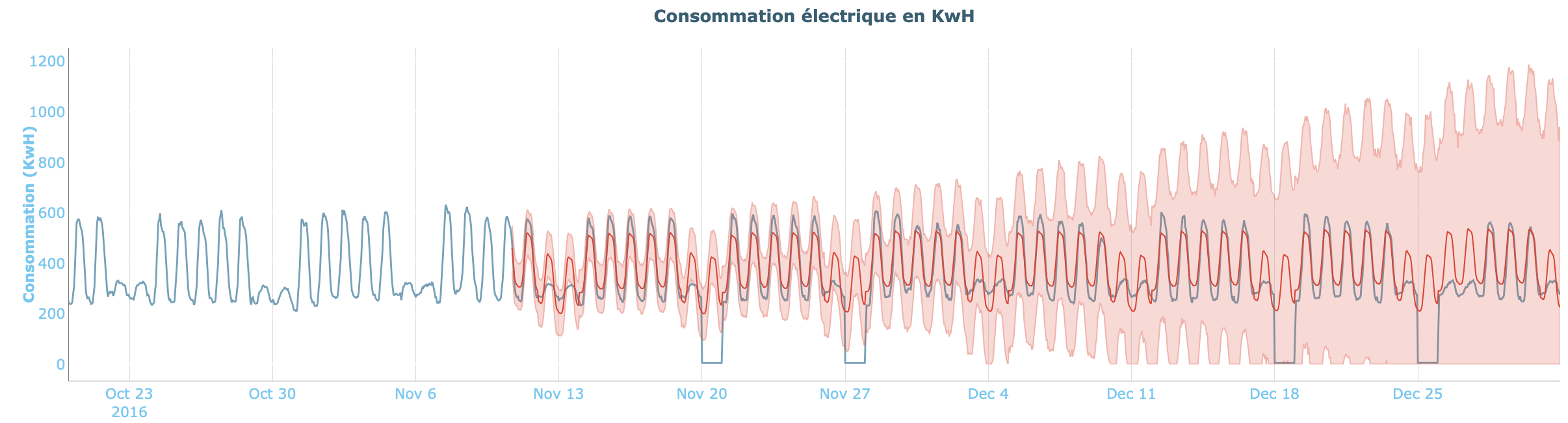
Pour ce qui est des modèles de Machine Learning, les hypothèses faites par l’algorithme ne sont pas basées sur les mêmes principes et l’intervalle de confiance résultant sera beaucoup plus stable dans le temps. Cette précision permettra de définir une fourchette plus précise dans laquelle seront contenues les données, comme en témoigne l’intervalle ci-dessous, obtenu pour un modèle de Gradient Boosting.
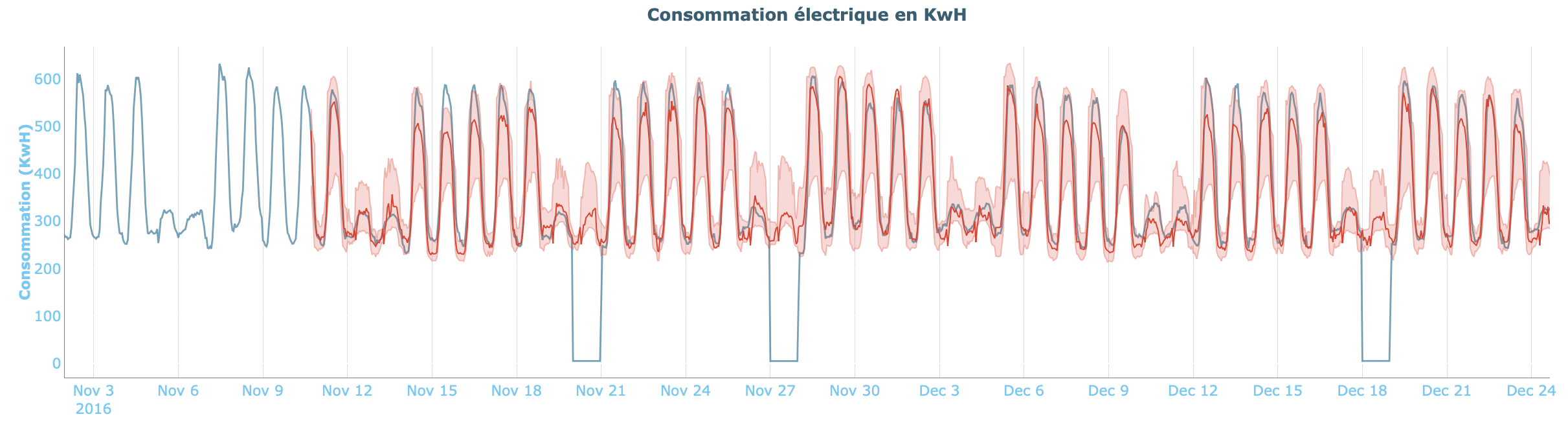
5. Pour aller plus loin
L’un des enseignements clés que nous devons retenir est qu’aucun modèle n’est parfait. Nous constatons qu’il est parfois plus judicieux de passer du temps à identifier les forces et les faiblesses de chaque modèle pour en combiner les points forts et en atténuer les points faibles plutôt que de rechercher LE modèle idéal.
C’est dans cette démarche que le démonstrateur est doté d’un module « aller plus loin » comportant un modèle hybride. Ce dernier combine (via du stacking) un modèle statistique Prophet à un modèle de Machine Learning : Gradient Boosting. Bien qu’ayant des résultats proches de ceux obtenus avec un modèle Gradient Boosting simple, ce modèle permet d’obtenir des prévisions plus robustes en associant deux types de modèles différents.
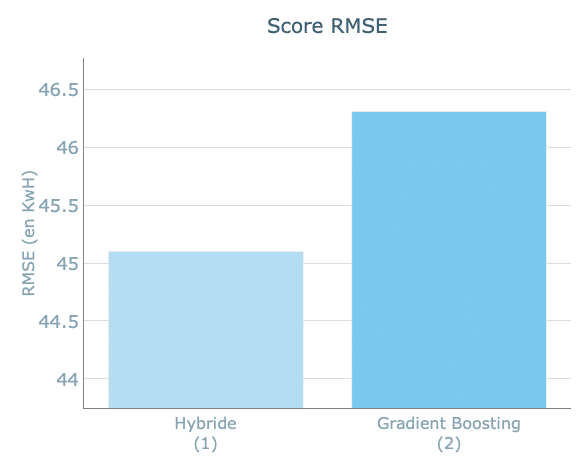
Il possède aussi l’avantage de pouvoir s’accommoder à un modèle déjà existant. Prenons par exemple, une entreprise ayant utilisé Prophet depuis toujours et souhaitant aller plus loin dans ses performances, tout en conservant les avantages qu’elle trouvait à utiliser son ancien modèle.
Alors, l’utilisation d’un modèle hybride permet d’inclure les avantages du modèle Prophet tout en incorporant les bénéfices apportés par le modèle Gradient Boosting au niveau de la robustesse des performances atteintes et de sa capacité d’adaptation.
Conclusion
En résumé, le démonstrateur permet de mettre sur un banc de test un ensemble de modèles pour en benchmarker les performances. Grâce à la section explicabilité, il est possible de décomposer chaque prévision en contribution des variables explicatives, afin de comprendre et de quantifier quel impact a, par exemple, la température extérieure sur la consommation d’électricité. Cela permettra d’expliquer certains pics et creux de consommation. Enfin, associer des intervalles de confiance aux prévisions permet de mieux qualifier le niveau de risque pour prendre des décisions plus éclairées.
Avec cet outil, notre administration disposera de toutes les fonctionnalités nécessaires pour prévoir au mieux la consommation énergétique de ses bâtiments, et en déduire les économies réalisées grâce aux travaux.
Elle pourra aussi comprendre en détail l’origine du comportement de la consommation électrique selon les divers facteurs pris en compte.
Nous serions ravis d’échanger avec vous plus en détail sur vos besoins pour construire un projet adapté à votre problématique. N’hésitez pas à nous écrire à contact@quantmetry.com.
Nous pourrons également vous faire une démonstration de l’ensemble des capacités de notre démonstrateur.
