

Paris Data Ladies au Trianon ! (NLP, GANs et Graphes)

Récemment, j’ai pu participer au meet up Paris Data Ladies du 19 juin 2019 qui se déroulait au Trianon. Paris Data Ladies est un meetup durant lequel des speakeuses présentent leurs expériences passées dans le domaine de la data. J’ai beaucoup apprécié les présentations proposées. En effet, les talks étaient de qualité et proposés par des personnes ayant des profils divers. Je voulais donc partager mon expérience sur ces talks portant sur du NLP, des GANs et de la théorie des graphes !
Le meet up se décomposait ainsi en trois présentations animées respectivement par :
- Ronin WU, Research Engineer chez Iris.AI
- Delphine GROLL, co-fondatrice et COO de Nabla
- Maria ROSSI, Data Scientist chez ProbaYes
Quels sont les problèmes rencontrés dans la recherche académique ? – Ronin WU @iris.ai
Ronin a travaillé pendant plusieurs années dans la recherche académique et a partagé les cinq principaux problèmes qu’elle a pu rencontrer durant cette expérience à savoir :
- Le surplus d’information
- Les choix biaisés d’articles selon les auteurs
- Les problèmes d’accessibilité aux articles
- La nécessité d’effectuer certaines recherches sans forcément être intéressé
- Les problèmes de reproduction des résultats
Iris.ai, société pour laquelle Ronin travaille, cherche à répondre à ces différentes problématiques. Pour ce faire, un premier projet de Natural Language Processing (NLP) est mis en place pour répondre aux deux premiers problèmes.
Une recherche d’articles facilitée !
Il permet de rechercher des articles en rapport avec une description donnée dans le domaine recherché. La recherche s’organise par concept afin de rendre la recherche plus facile. L’utilisateur pourra ainsi retirer les articles appartenant à des concepts ne l’intéressant pas forcément.
L’algorithme repose sur trois méthodes différentes afin de trouver les articles pertinents :
La première est une méthode reposant sur des mots-clefs. Un score de TF-IDF (Term Frequency – Inverse Document Frequency) afin de trouver des mots représentant le sujet de recherche.
La seconde consiste en un Word Embedding classique (Word2Vec) afin d’obtenir des synonymes des mots clefs obtenus précédemment.
Enfin la dernière méthode consiste en une modélisation de sujets (topic modelling) à travers un réseau de neurones (NTM et sNTM – respectivement Unsupervised et Supervised Neural Topic Model). En se servant de cette modélisation, des mots provenant de certains topics peuvent être ajoutés, une pratique souvent utilisée afin d’obtenir des contenus connexes à celui donné en entrée.
Le résultat de ce projet est accessible à travers le site d’iris.ai avec une version gratuite.
Ce projet a permis de répondre à deux des problèmes d’un chercheur à savoir le surplus d’informations et les choix biaisés par les auteurs.
Une validation des connaissances des différents théorèmes
D’autres projets ont aussi vu le jour, comme un module de validation de connaissance. En effet, un chercheur ignore souvent s’il existe déjà des preuves de certains théorèmes (avec les mêmes hypothèses, ou d’autres plus restrictives) dans des domaines différents de ceux qu’il étudie. L’objectif du module est donc de construire un modèle qui identifie les différentes parties d’un article de recherche à savoir :
- Le problème
- La solution
- L’évaluation
- Les résultats
En les extrayant à partir de mots-clefs, un graphe de correspondance entre les différentes hypothèses est généré pour pouvoir créer un arbre de connaissance où les nœuds sont différents articles qui ont prouvé (ou non) les hypothèses découlant de la problématique originale.
Spécificité pour la recherche en chimie !
Enfin, iris.ai s’est lancé sur un nouveau projet, cette fois-ci axé sur la recherche en chimie. Dans ce domaine, certaines molécules sont nommées d’après leur composante chimique (comme H2O pour l’eau) ce qui peut troubler la recherche sémantique.
Cela provient probablement d’un manque de données pour entraîner des Word Embedding spécifique à ce genre de domaine où la molécule peut être rarement cité.
Comment se servir de GANs pour faire du transfert de maquillage ? – Delphine GROLL @nabla
Delphine a co-fondé la société Nabla en 2017 avec deux partenaires. Pour leur premier projet, ils souhaitaient travailler sur un sujet à l’état de l’art et qui puisse être commercialisable. De ce fait, faire du transfert de maquillage serait une opportunité de satisfaire ces deux conditions.
La méthodologie des modèles
La présentation a débuté par une brève description conceptuelle des GANs (Generative Adversarial Networks) à savoir un entraînement antagoniste entre un discriminateur qui indique si une donnée est synthétique ou réelle et un générateur qui crée de la donnée.
Dans le cas d’usage, les GANs doivent faire un transfert de maquillage d’une personne vers une autre. Un grand point d’attention a porté autour de la capacité du modèle à être applicable sur tout type de visage indépendamment du sexe ou de la couleur. Le transfert de texture et de couleurs commençaient déjà à bien fonctionner avec les GANs. C’est pourquoi Nabla a décidé de retenir cette méthodologie.
Les pistes de recherche sur le cas d’usage
Pour se faire, ils se sont tournés vers un article de recherche paru en 2018 sur le PairedCycleGAN de Chang et al. [1], qui avait déjà abordé le problème en partant d’un dataset apparié. Cet article reposait lui-même sur l’article du CycleGAN de Zhu et Al [2].
Le cas d’usage de Nabla est ici de pouvoir utiliser la photo d’un certain type de maquillage avec la photo de quelqu’un (presque) sans maquillage et de voir le résultat. Dans les faits, le CycleGAN qui est entraîné pour affecter un certain type de style n’est pas adapté. En effet, il pourra être capable d’apprendre un maquillage précis durant l’entraînement et l’appliquer sur une personne non maquillée. Cependant, cela ne répond pas à la problématique puisque ce dernier exige de pouvoir transférer n’importe quel type de maquillage d’une personne à une autre. Les auteurs de l’article du PairedCycleGAN se sont donc penchés sur la question d’une variante du CycleGAN qui permettrait d’avoir deux données en entrée, l’une utilisée pour avoir le style à appliquer, l’autre pour avoir la personne à maquiller.
Ici, l’application se fait en plusieurs étapes.
- Générer un individu maquillé à partir des deux instances et d’un réseau G
- Démaquiller l’instance maquillée avec un réseau F
- Remaquiller l’instance démaquillée avec la génération de l’étape 1.
L’entraînement se fait sur la différence entre le démaquillage/re-maquillage et l’instance d’origine.
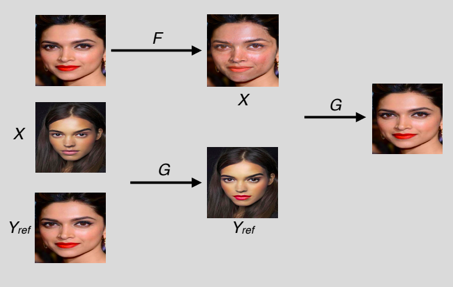
Par ailleurs, un discriminateur D est ajouté pour bien vérifier que le maquillage effectué sur l’instance non maquillée est bien identique à celui sur l’instance maquillée d’origine. L’entraînement du discriminateur est fait avec du face warping à savoir remplacer les yeux, l’image etc. d’une image par celle d’un autre portrait.
Les challenges et spécificités du projet
Les challenges que Delphine et son équipe ont rencontrés étaient multiples :
- L’absence de données appariées (maquillage/sans maquillage) qui a pu être résolue avec de la recherche d’image de youtubeuse beauté qui font souvent des « before/after make up »
- La non-reproductibilité des articles de recherche car beaucoup trop de calculs nécessaires. Cela fait écho avec la présentation de Ronin qui indiquait que c’était un des problème rencontré dans la recherche académique
- Vérifier que tous les types de visages étaient représentés (même ceux des hommes !)
Finalement, le résultat est obtenu avec un dataset de 20 000 images, ce qui représente une belle performance, surtout en comparaison avec l’article d’origine qui n’en avait que 2 000. L’implémentation a été effectuée sur PyTorch, avec un GPU et une semaine d’entraînement.
Delphine a fini avec une démonstration qui nous montrait un modèle remarquablement efficace sur tous type de profil, que ce soit une femme ou même un homme !
Comment maximiser la propagation dans un graphe à travers l’identification de nœuds influents avec l’algorithme K-truss ? – Maria ROSSI @probayes
Maria nous a présenté les résultats de sa thèse en théorie des graphes [3] [4]. La data science se porte récemment beaucoup sur des données tabulaires, des images, du texte ou du son mais les données de graphes ne sont pas en reste. La thèse de Maria portait sur la localisation des entités influentes dans un réseau, ce qui peut avoir de multiples intérêts selon les cas d’usage :
- rapidement faire connaître une offre marketing
- endiguer rapidement l’effet d’une épidémie
- optimiser la propagation d’une information
- etc.
Dans le cadre de sa thèse, Maria s’est spécifiquement intéressée au sujet des individus uniques influents. Une autre étude peut se porter sur les groupes d’individus maximisant la propagation.
Les méthodologies existantes
Une méthode classique pour définir un nœud influent est le calcul des degrés de centralité à savoir le nombre de liens vers d’autres nœuds. Un grand degré de centralité pourrait vouloir indiquer une bonne propagation. Cependant, des nœuds liés peuvent avoir un faible nombre de liens ce qui peut empêcher la propagation de l’information. Pour plus d’informations sur les différents indicateurs de centralité, je vous invite à lire l’article portant sur la théorie des graphes.
Une amélioration a été proposée à travers la décomposition k-core. Celle-ci consiste en la division du graphe en des groupes de nœuds denses en liens. C’est-à-dire que chaque sous-graphe k comprend des nœuds de degré de centralité supérieur à k dans le sous-graphe.
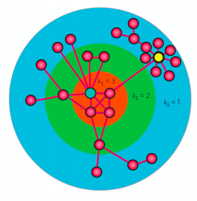
Dans cette image, tous les nœuds dans le sous graphe ks = 3 ont un degré de centralité supérieur à 3 (au sein même de ce sous-graphe).
Cependant, malgré le fait que ces nœuds ont en moyenne de bonnes capacités de propagation, ils sont très nombreux. Cela à orienter sa recherche vers une méthode pour affiner la recherche de nœuds au sein du sous graphe le plus dense de la décomposition k-core.
L’algorithme K-truss
L’algorithme K-truss a donc vu le jour, on recherche le sous-graphe comprenant uniquement des liens compris dans au moins k triangles (comprendre qu’il faut au moins k individus qui sont reliés aux nœuds formant l’arête d’origine).
Il est prouvable mathématiquement que le sous-graphe de K-truss maximal est compris dans le sous-graphe de k-core maximal.
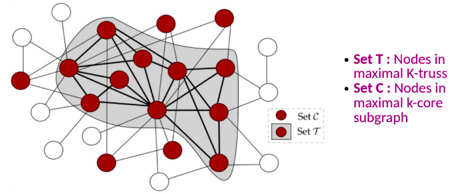
Enfin, les résultats ont été obtenus en comparant ces trois méthodes (degré de centralité, k-core, K-truss) dans différents datasets de graphes et où l’information propagée est simulée avec un modèle SIR (Susceptible-Infected-Recovered, chaque nœud à une probabilité 𝜷 de contaminer son voisin et 𝜸 de ne plus être infecté), étant la méthode la plus souvent utilisée dans ce genre de cas d’usage pour comparer des résultats. Les résultats sont étudiés après quelques étapes de propagation (2, 4, 6, 8 et 10) et quand l’épidémie est arrêtée.
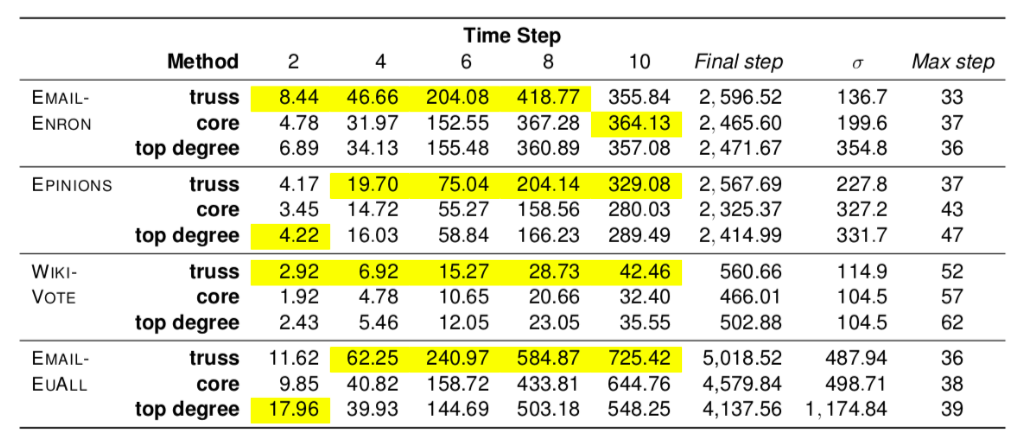
Dans la partie Time Step du tableau se situent le nombre moyen de nœuds infectés après un certains nombre d’étapes. En jaune sont les infections maximales (en moyenne), et nous remarquons que l’algorithme K-truss domine majoritairement les résultats tout le long du processus. C’est d’autant plus probant que les résultats restent vrais pour l’étape finale (Final Step) !
Il est apparent à travers les résultats que l’épidémie se fait à la fois plus rapidement et sur un plus grand périmètre !. Enfin, cela se fait avec beaucoup moins de nœuds que la méthode k-core.
Conclusion
Différentes méthodologies ont donc pu être présentées, que ce soit sur de la recherche de pertinence sur des données textuelles avec la présentation de Ronin, ou sur comment faire du transfert de style avec des méthodes particulièrement récentes (articles de recherches de 2017 et 2018) avec Delphine. Enfin, nous avons découvert un algorithme à l’état de l’art pour faire de la propagation au sein d’un graphe avec la thèse de Maria.
Les présentations de ce meet up étaient d’une très grande qualité avec des sujets variés (NLP, GANs et Théorie du Graphe) et dans un très beau cadre puisque ce Paris Data Ladies se déroulait au Trianon !
Je souhaite donc réitérer l’expérience sur les prochaines sessions du Paris Data Ladies, et j’espère assister à des talks d’aussi bonne qualité pour les fois suivantes !
Références
[1] PairedCycleGAN: Asymmetric Style Transfer for Applying and Removing Makeup, Chang et al. CVPR 2018
