

Pourquoi faut-il modéliser les données ?

Cet article fait partie d’une série d’articles sur le sujet « Architecture – de la BI au Big Data ».
Quand on parle de Big Data, le data lake est un concept incontournable. Souvent, la démarche de mise en place d’un data lake s’arrête après la simple copie des données brutes dans ce dernier. La pensée commune considère que tout est résolu quand les données sont intégrées. Pourtant, au-delà de l’aspect « organisation du data lake », avoir seulement les données brutes n’est selon nous pas suffisant. Cet article se propose d’expliciter pourquoi. Nous détaillerons d’abord les différents types de structures de données qui peuvent se retrouver dans le data lake et les raisons pour lesquelles elles nécessitent un retraitement ; puis nous aborderons l’utilisation de ces mêmes données.
Les différents modèles rencontrés
Le data lake est le reflet du système d’information de l’entreprise et donc, de son histoire. Une entreprise établie depuis de nombreuses années n’aura pas du tout le même système qu’une start-up. Une application construite à l’ancienne en cycle en V ne stockera pas ses données de la même façon qu’une application construite en mode agile. Une application construite dans les années 90, pas le même type de stockage qu’une application récente …etc. En fonction de l’histoire et de l’architecture de l’entreprise, on retrouvera donc dans le data lake des données modélisées de différentes manières, avec différents niveaux de maturité et de cohérence.
Nous ne parlerons pas ici des données non structurées (de type image, voix ou « texte libre »). Le propos concerne donc les données structurées, quel que soit leur support de stockage.
La modélisation dans le monde traditionnel
Les données structurées peuvent être modélisées de différentes façons selon leur source.
Application Transactionnelle
Une application transactionnelle nécessite un modèle normalisé, qui est alors optimisé pour des opérations massives :
– insertion de données ;
– suppression ;
– mise à jour.
Dans l’idéal, il correspond à la 3ème forme normale (3NF). Les données sont normalisées et il n’y pas de redondance dans la base de données. Il y a donc de nombreuses tables et de nombreuses jointures entre ces tables. Lire les données est complexe et consommateur en temps. Tout le monde ne maintient pas à jour le modèle de données des bases. Il faut donc retrouver les jointures manuellement. Si des règles de nommage simplifiant cette tache ont été appliquées systématiquement, c’est envisageable, mais quoi qu’il en soit, cela prend du temps.
De plus, il y a toujours des subtilités non documentées et aucune base n’est parfaite (le « ah mais ça ne marchait pas alors on a appliqué une rustine »). En fonction du temps alloué aux équipes, les rustines perdurent et s’accumulent avec le temps complexifiant le processus de valorisation de la donnée.
Progiciel
Un progiciel est une application, paramétrable ou personnalisable. On en retrouve entre autres dans le monde du CRM ou de l’ERP. Le principe d’un progiciel est de pouvoir être personnalisé en fonction des besoins.
Les progiciels ont souvent un très grand nombre de tables. La base contiendra alors toutes les tables et pas seulement celles réellement utilisées. Un petit nombre de tables (comparé au nombre total de tables) contiendra des données signifiantes. Le CRM Siebel contient pas moins de 5000 tables par exemple, et seules quelques dizaines sont utilisées lors de l’implémentation, en fonction des fonctionnalités mises en œuvre.
De plus, le niveau d’abstraction peut être très élevé, et ne correspond pas à une approche « Merise ». Ce niveau d’abstraction est nécessaire pour permettre un paramétrage du progiciel. Parfois, on peut ainsi communément ajouter de nouvelles données métiers sans faire évoluer le modèle initial.
Souvent la lecture directe de la base de données n’est pas supportée par l’éditeur, autant pour des raisons de licence que de performance.
Les règles de gestion sont complexes et toutes ne sont pas formalisées par un champ de base de données. De nombreuses règles sont appliquées dans la couche de présentation, c’est-à-dire en temps réel sur l’écran de l’utilisateur.
Il est impossible de garantir la lecture correcte des données sans maîtriser le progiciel.
Modèle Dénormalisé
Si la base de données est un data warehouse ou une base destinée à du reporting, elle peut être dénormalisée.
Dans ce cas elle ne suit pas une 3ème forme normale, mais elle ne suit pas non plus un modèle en étoile ou en flocon de neige. Dans ce type de modèle, les redondances sont possibles. Cela limite le nombre de jointures. La base est en conséquence plus facile à lire.
Etoile ou flocon de neige
La modélisation en étoile ou en flocon de neige est une évolution de la modélisation dénormalisée. Ce type de modélisation consiste à représenter l’équivalent d’un cube dans une base de données relationnelle.
C’est une modélisation qui répond aux besoins du décisionnel et qui a été pensée pour répondre à des questions business. Nativement, elle permet de valoriser plus facilement la donnée métier.
Elle est constituée de dimensions (les axes d’analyse), et de faits (les données à analyser).
En fonction de l’importance du projet et de ses objectifs, la base contiendra une proportion plus ou moins importante de données métiers :
– si on a souhaité permettre du reporting ad-hoc, son champ sera assez large, puisque l’objectif est justement de permettre tout type de requêtes ;
– si on a construit le modèle pour répondre à du reporting ou du dashboarding uniquement, son champ d’application est plus restreint.
Nous reviendrons plus en détail sur ce type de modélisation dans l’article suivant.
Pour ceux qui veulent approfondir le concept, The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling de Ralph Kimball est un grand classique.
Toute information signifiante n’est pas stockée
Il est important de distinguer information signifiante et information stockée, quel que soit le type de modélisation.
Toute information signifiante n’est pas nécessairement stockée. Plusieurs raisons expliquent cela :
– pas d’intérêt à la stocker au moment de la conception de la base de données ;
– règle de gestion calculée dans la couche de présentation ;
– persistance d’un traitement manuel (« c’est Jean-Paul qui sait… ») ;
– persistance de référentiels « pirates » (fichiers Excel et bases de données Access personnelles).
L’étape de modélisation est indispensable mais longue et coûteuse. Elle permet alors de dégager de la valeur ajoutée métier, et idéalement d’améliorer et d’industrialiser les processus métier de production de la donnée.
La modélisation dans le monde du big data
Le datalake peut-il se passer de modélisation ?
Les capacités de stockage sans limite du big data ont rendu possible la collecte tout azimut de la donnée. Les supports de stockages proposés par Hadoop (HDFS) s’appuyant sur des systèmes de fichiers distribués, le travail préalable de structuration de l’information est devenu inutile. Ces supports de stockage (HFDS ou NOSQL) sont dits « schemaless ».
Les entreprises se sont donc empressées de construire d’innombrables data lakes et de les peupler d’innombrables données. Les jeunes data scientists regardaient alors les architectes et experts en base de données avec le regard que porte le nouveau monde sur l’ancien monde : « Plus besoin de modélisation, à la poubelle vos Modèles Physiques de Données, Modèles Conceptuels de Données, modèles de Kimball, UML ou autres SQL ! Nous on traite de la donnée brute ».
Très rapidement, nos data lakes sont devenus des « data swamps » et les data scientists se sont mis à passer énormément de temps en compréhension, préparation, nettoyage et agrégation de données. Cette charge sans grande valeur ajoutée représente plus de 50% de la charge totale d’un projet de data science. La part dévolue au machine learning est très faible, au point que les data scientists sont frustrés de faire si peu de vraie data science.
La modélisation au secours de la compréhension des données
En effet, s’il n’est plus nécessaire de modéliser pour stocker l’information, il est essentiel de modéliser pour comprendre l’information que l’on manipule. Qui plus est, la quantité d’information utile contenue dans la donnée devient de plus en plus infinitésimale. Pour comprendre et repérer l’information utile parmi les tera octets de données, il n’y a pas d’autre solution que de modéliser l’information. Pour faire une analogie littéraire, ce n’est pas en lisant le flux binaire persisté sur sa liseuse que l’on comprend la signification profonde de l’information présentée. Sans métamodèle, impossible d’en comprendre le sens.
Fort de ce constat, les architectes de données ont mis en place des structures d’information par étage, ont redécouvert les concepts de vue, d’objet ou de modèle en étoile. La gouvernance de la donnée est redevenue une priorité et tenir à jour un catalogue de données bien documenté, une prérogative des data labs. Les entreprises les plus avancées établissent des métamodèles et des ontologies pour comprendre, interpréter et naviguer dans les données. La théorie des graphes est ressortie de son placard et sert de support à toutes les analyses de données des réseaux sociaux.
Enfin, et ce sera l’objet du prochain article, les architectes et ingénieurs de données ont mis en place des data lakes en couche, à même de se substituer aux entrepôts décisionnels, et apportant le même niveau de lisibilité que les anciens systèmes.
La modélisation au service de l’efficacité
Le data lake va être utilisé par les data scientists. Or le travail d’un data scientist se répartit comme suit :
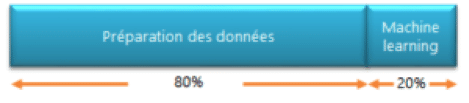
– 80% : préparation des données
– 20% : Machine learning
Quelles données utilisent-ils ? Beaucoup de données identiques à celles utilisées par les équipes Data Analytics.
Or comment se répartit le travail en Data Analytics :
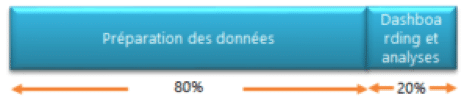
– 80% : préparation des données
– 20% : Dashboarding et analyses
Modéliser une base unique, permettant une lecture simple des données de l’entreprise, est donc indispensable :
– pour que les équipes de Data Science et de Data Analytics aient une même base d’analyse ;
– pour factoriser le travail et gagner en efficacité.
Conclusion
– Il est illusoire de penser que l’on peut exploiter les données brutes sans retravailler le modèle.
– La modélisation est réalisée a posteriori pour interpréter, analyser et produire une vue agrégée.
– La remodélisation des données dépend du cas d’usage ; il n’y a pas qu’une méthode. Il faut tendre à un modèle commun mais du point de vue de la technologie, on exploitera ce même modèle commun de manière différente.
