

En route vers le cycle de vie des modèles !

✍ Grégoire Martinon / Temps de lecture : 20 minutes.
IA en production [1], ce n’est pas une mince affaire. Les modèles d’intelligence artificielle ont ceci de particulier qu’ils sont probabilistes et qu’ils dépendent fortement des données qu’ils ingèrent. Les données elles-mêmes sont soumises aux aléas du monde qui les génère ! En conséquence, la plupart des modèles prédictifs voient leurs performances chuter dès la mise en production [2]. Il faut alors ré-entraîner le modèle pour espérer maintenir son niveau de fonctionnement : c’est ce qu’on appelle le cycle de vie.
Dessine-moi un cycle de vie
Les entreprises digitales ont déjà un cycle de vie à gérer, celui de la donnée (voir Figure 1). Il consiste principalement à ingérer la donnée à la source, à la valider et à la redistribuer auprès des acteurs ou des solutions métier. Le cycle de vie de la donnée est déjà quelque chose de complexe et technique à gérer, mais qui s’accompagne via des méthodes de gouvernance [3].
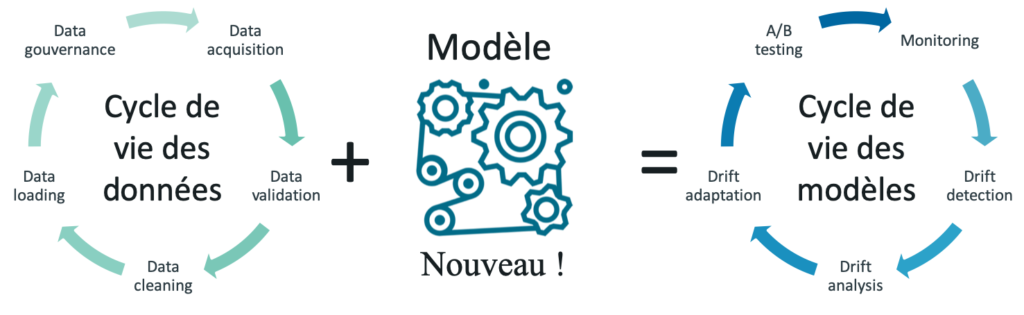
Figure 1 : le cycle de vie des modèles est une conséquence du cycle de vie des données. D’abord pour prédire, le modèle doit être branché sur des données émises au jour le jour. Ensuite pour le ré-entraînement, le modèle doit avoir la possibilité de s’adapter sur des données fraîches et labellisées pour maintenir sa performance.
Arrive alors un nouvel élément : le modèle prédictif. Cela peut être une moyenne, une règle métier ou un modèle de machine learning, il s’agit dans tous les cas d’un mécanisme qui se nourrit de données passées pour propager une information vers le futur. Le modèle va donc devoir se brancher sur le cycle de vie des données de deux manières différentes : pour s’entraîner d’une part et pour prédire d’autre part.
Or, un modèle figé est un risque.
Pensez par exemple à un système de détection de fraude [4], où l’adaptation des fraudeurs rend caduque tout modèle statique. En réalité, la donnée n’est autre qu’un signal émis par le monde extérieur, et ce monde est en constante évolution. En termes plus techniques, l’hypothèse selon laquelle “les données sont indépendantes et identiquement distribuées”, omniprésente en intelligence artificielle, est violée dans la réalité.
D’ailleurs, quand la performance du modèle chute, un abus de langage courant affirme que “le modèle a dérivé”. Or c’est complètement faux : ce sont les données qui ont évolué, pas le modèle, et c’est justement là tout le problème.
Le cycle de vie est la science qui va permettre de résoudre les problèmes suivants : comment surveiller un modèle ? comment détecter une baisse de performance ? comment s’adapter à l’évolution de la donnée ?
Bien conduire son cycle de vie
Bien gérer son cycle de vie, c’est faire preuve de bon sens. Et ce bon sens est déjà acquis dans d’autres domaines de la vie courante. On peut par exemple filer la métaphore de la voiture (voir Figure 2 et Table 1). On distingue alors deux phases : la mise en production du modèle et son cycle de vie.
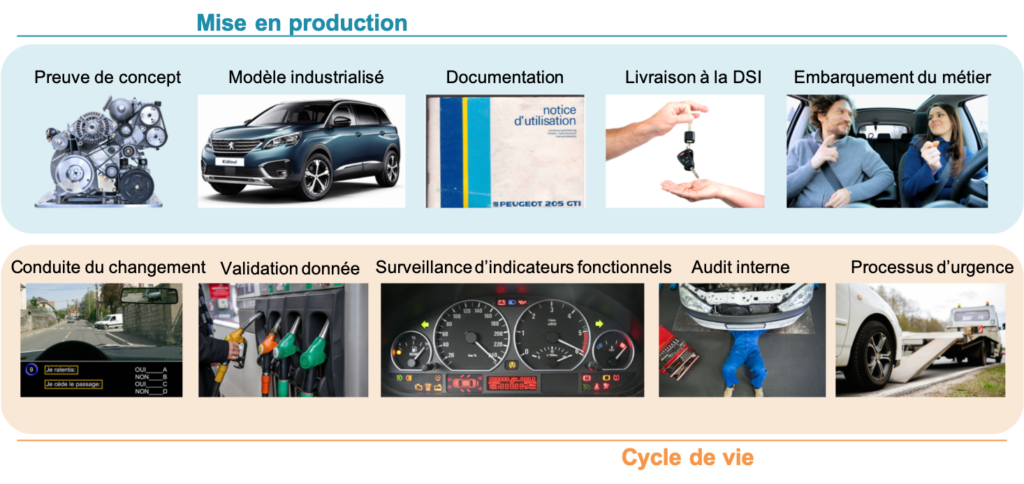
Figure 2 : Le cycle de vie des modèles repose sur du bon sens, et peut être comparé au cycle de vie d’une voiture. Le modèle est le moteur, et le système d’information (SI) la voiture. La direction du SI (DSI) est en charge de conduire le modèle et le métier est en charge de donner les directions à suivre. Comme pour une voiture, le cycle de vie des modèles va devoir anticiper les pannes et apporter des solutions à tous les niveaux.
Mise en production
C’est le processus de développement de l’intelligence artificielle jusqu’à son utilisation.
Le data scientist (l’ingénieur automobile) crée un modèle (un moteur).
Or un modèle isolé n’a aucune valeur en soi. Il ne prend sa valeur qu’un fois inséré dans un code de qualité (le châssis) qui doit gérer l’interaction du modèle avec le monde extérieur. C’est ce code et ce modèle qui sont livrés à la DSI (le conducteur). La DSI ne sait pas créer un modèle, mais elle sait le déployer (elle sait conduire).
Un troisième acteur prend place, c’est le métier (le copilote). Il ne sait ni créer ni déployer un modèle, mais il détermine son cas d’usage métier (il donne l’itinéraire du trajet et tient le budget).
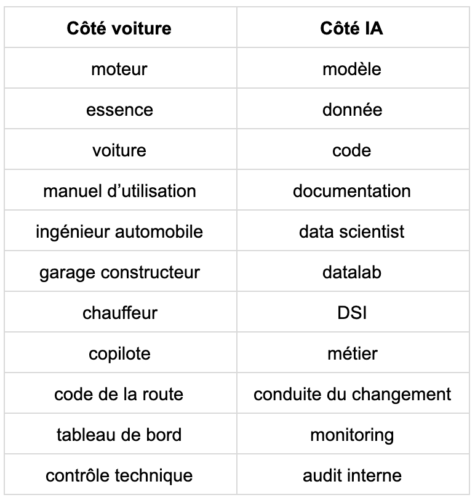
Table 1 : dictionnaire d’analogies entre le déploiement d’un service automobile et le déploiement d’un service d’intelligence artificielle.
Cycle de vie
C’est tout ce qui advient au cours de l’existence du modèle une fois mis en service.
La conduite du changement (le code de la route) permet d’insérer le modèle dans le processus de l’entreprise, en définissant des droits d’accès, d’utilisation et en permettant l’adhésion du plus grand nombre.
Ensuite, pour prédire correctement, les données servies au modèle (l’essence) doivent obéir à des standards de qualité (Diesel, SP 98), sous peine de fournir des valeurs aberrantes, voire inexistantes.
Le monitoring de modèle permet de surveiller son bon fonctionnement, sa performance et les retours terrains (de même qu’il est impensable de vendre une voiture sans tableau de bord).
L’anticipation des problèmes en production passe par une phase d’audit, ou de validation interne (c’est le contrôle technique).
Enfin, en cas de problème, il s’agit de déterminer le degré d’autonomie de l’utilisateur : peut-il se contenter de réparer un bug mineur (remettre du liquide de refroidissement), ou doit-il ré-entraîner le modèle sur un nouveau jeu d’entraînement rafraîchi (dépanneuse puis garage constructeur) ?
Ces grandes étapes du cycle de vie des modèles relèvent donc essentiellement du bon sens qui s’applique au déploiement de toute solution à l’échelle.
Objectifs du cycle de vie
Pour résumer le cycle de vie va devoir anticiper tous les aléas qui surviennent dans la vie d’un modèle en production et fournir des solutions idoines. Les trois principaux objectifs du cycle de vie sont (voir Figure 3) :
- mesurer le retour sur investissement (ROI) : le modèle étant en production, il est primordial de mesurer son impact métier et son retour sur investissement, si possible en euros. Comme toute mesure, elle doit s’accompagner d’incertitudes.
- évaluer le risque : il s’agit de construire un modèle robuste aux changements, en tenant compte non seulement du bénéfice de la performance mais aussi du coût de maintenance (acquisition de données labellisées, ré-entraînement, redéploiement).
- assurer la non-régression : au-delà des dérives de données, il faut aussi se prémunir des dérives proactives de modèle (autrement dit les bugs). C’est toute la méthodologie DevOps appliquée à l’intelligence artificielle qui entre en jeu, on parle même de DataOps ou MLOps [5].

Figure 3 : Objectifs du cycle de vie. Étant la science des modèles en production, le cycle de vie est naturellement la science de la mesure du retour sur investissement (ROI). C’est aussi la science de la mesure du risque et des incertitudes, qui ont autant si ce n’est plus de valeur en production que la performance. Enfin, il s’agit d’assurer la non-régression du service d’intelligence artificielle en renforçant les flux de traitements pour les rendre plus robustes.
Les questions que posent le cycle de vie
L’organisation, ou plutôt l’absence d’organisation, est le premier frein à la mise en place d’un cycle de vie des modèles.
Dans un projet de machine learning de bout en bout, on peut distinguer trois niveaux de réalisation (voir Figure 4) :
- organisationnel : c’est le volet qui va s’intéresser aux responsables, aux compétences et à l’impact métier. L’organisation, ou plutôt l’absence d’organisation, est le premier frein à la mise en place d’un cycle de vie des modèles.
- scientifique : c’est le volet qui va s’intéresser à la robustesse des modèles, à l’efficacité d’un système de détection de dérive, et aux solutions de redressement de la performance.
- technologique : c’est le volet qui assure le branchement du modèle au cycle de vie de la donnée. Il va s’intéresser à la qualité de la donnée, à la gestion d’un historique (ou d’une banque) de modèles, ainsi qu’au déploiement rapide et sûr de la solution préconisée par le volet scientifique.
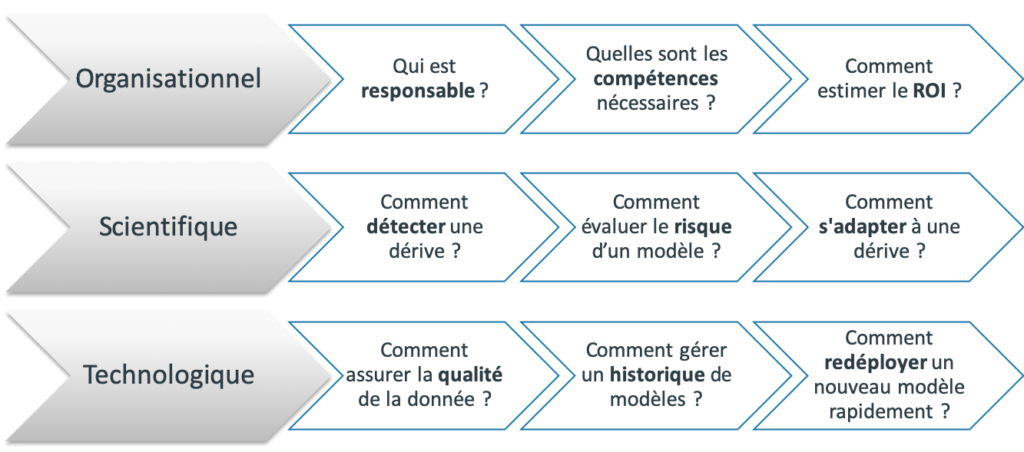
Figure 4 : les questions que pose le cycle de vie des modèles, d’un point de vue organisationnel, scientifique et technologique.
Le cycle de vie pas à pas
Aujourd’hui, les problèmes et les questions que posent le cycle de vie sont bien identifiés par le marché. C’est plutôt l’aspect mise en oeuvre des solutions qui fait défaut. Dans cette partie, on propose donc une feuille de route cycle de vie des modèles (voir Figure 5), qui répond à la question suivante :
“Je m’apprête à mettre un modèle en production, que dois-je faire et par où commencer ?”
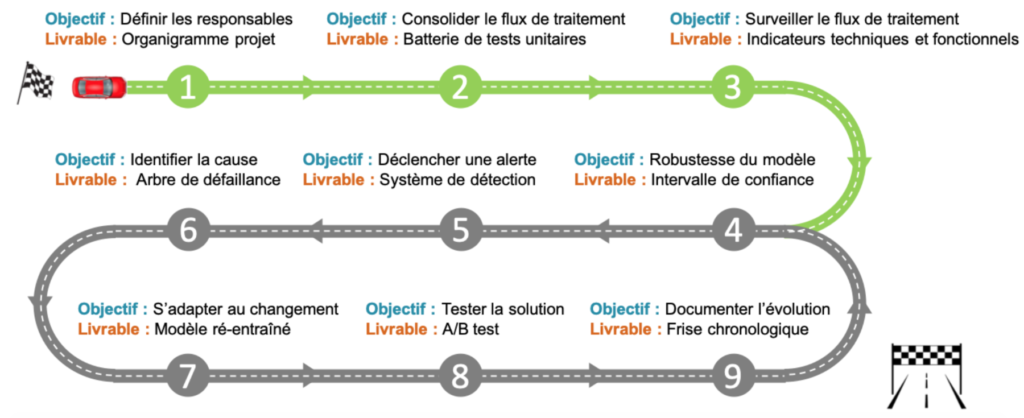
Figure 5 : feuille de route cycle de vie des modèles. Avant d’entrer sur l’autoroute, il faut emprunter une voie d’accélération avec trois étapes obligatoires (en vert) : définir le projet cycle de vie et les ressources à y allouer (1), consolider une chaîne de traitements robuste (2), et installer un système de monitoring (3). Une fois ces pré-requis mis en place, on peut alors aborder le cycle de vie des modèles proprement dit, en s’attaquant à la robustesse du modèle (4), au système de détection de dérive (5), à l’intelligibilité de la dérive (6), à l’adaptation du modèle (7), aux tests en conditions réelles (8) et à la documentation continue (9).
Etape 1 : définir les responsables
Le profil de product owner est le plus rare et le plus difficile à trouver.
Il s’agit de définir qui construit le moteur, qui conduit, et qui fait le plein. Le cycle de vie des modèles ne peut pas exister s’il n’est mis entre les mains d’un responsable (product owner), avec une bonne compréhension métier, dont la mission est de construire et de maintenir le modèle en production. C’est le profil le plus rare et le plus difficile à trouver. Il doit gérer une équipe comprenant au minimum (voir Figure 6) :
- un responsable qualité de donnée : souvent un (ou plusieurs) data engineer, il doit construire et assurer la qualité de la donnée d’entrée, en consolidant un référentiel de donnée. Il doit agir côté DSI et côté DataLab.
- un responsable robustesse du modèle : souvent un data scientist, il doit non seulement assurer la performance du modèle mais également quantifier sa robustesse et donc son incertitude. Il doit agir côté DataLab et côté métier.
- un responsable mise en production : c’est le profil ML engineer, qui doit savoir orchestrer et mettre en oeuvre la chaîne de traitement sur la plateforme de production. Il doit agir sur tous les fronts DSI, DataLab et métier.
- un responsable surveillance et alerte : souvent un data analyst orienté métier ou data science, il est en charge de surveiller les indicateurs de performance du modèle et d’alerter les bons éléments en cas de problème.
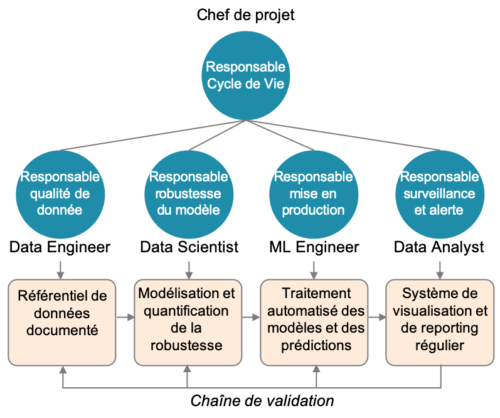
Figure 6 : exemple d’une organisation projet cycle de vie qui a fait ses preuves. Le point clef est de définir un responsable côté métier (product owner), qui ait à la fois une sensibilité sur les enjeux techniques et sur les enjeux business. Sa mission est d’orchestrer toutes les compétences nécessaires au cycle de vie.
C’est la mixité et la proximité des compétences qui assure la réactivité et la fluidité du système. Par ailleurs, il faut réussir à octroyer une certaine autonomie à chaque pôle de responsabilité, en rédigeant un document d’exploitation qui permet de gérer rapidement les problèmes connus les plus courants.
Etape 2 : consolider les flux de traitements
Il y a globalement quatre points faillibles dans une chaîne de traitements : les données, le code, le modèle et l’infrastructure.
C’est le contrôle technique de la voiture. Il y a globalement quatre points faillibles dans une chaîne de traitements : les données, le code, le modèle et l’infrastructure. Chacun de ces points doit faire l’objet de tests unitaires exhaustifs [6].
Pour les données, la notion de test unitaire est bien capturée par ce qu’on appelles les schémas de contraintes (ex : une donnée “âge” doit être entière et comprise entre 0 et 150). Plusieurs technologies permettent d’automatiser la découverte et la mise en place de ces contraintes. On peut citer par exemple TensorFlow Data Validation [7] (Google), Deequ [8] (Amazon), Delta Lake [9](Databricks) ou encore TDDA [10] (Stochastic Solutions). D’une manière générale, le schéma de contraintes va se construire de manière itérative et va incarner le processus de capitalisation et de définition de la qualité de donnée.
Pour le code, c’est toute la méthodologie DevOps qui est à mettre en oeuvre, c’est le MLOps [11].
Pour le modèle, c’est avant tout la reproductibilité des résultats qui garantit la maîtrise de tous les processus aléatoires du modèles. C’est le fer de lance de la technologie MLflow [12]. Il existe aussi des particularités propres aux modèles de deep learning [13].
Enfin pour l’infrastructure, c’est l’équipe production de la DSI qui doit fournir la disponibilité du serveur de production (temps de calcul, RAM, espace disque, temps de réponse).
Etape 3 : surveiller les flux de traitements
Le monitoring est la colonne vertébrale du cycle de vie des modèles.
C’est le tableau de bord de la voiture. C’est la colonne vertébrale du cycle de vie des modèles. La point difficile est : “quels indicateurs surveiller ?”.
A minima, ce sont les indicateurs métiers et financiers qui doivent être mis en place, et ce dans une optique d’estimation de ROI. Le problème est que souvent, ces indicateurs nécessitent des données labellisées (ex: fraude / pas fraude [4]), qui arrivent avec un certain retard sur les événements. Lorsqu’un indicateur financier baisse, il est souvent déjà trop tard et l’inertie du changement peut être de plusieurs mois.
De plus dans certains cas, certains indicateurs sont tout simplement indisponibles (ex: est-ce qu’une demande de crédit refusée était finalement solvable ?), et la notion même de faux positifs ou de vrais positifs peut tout simplement disparaître en production.
Il est donc important de se focaliser :
- d’une part sur des métriques non-supervisées, qui vont permettre d’anticiper les évolutions de distribution de données sans attendre l’arrivée des labels,
- d’autre part sur des métriques fonctionnelles, qui vont mesurer l’impact immédiat du modèle sur les processus de l’entreprise.
Par exemple, dans une chaîne de validation modèle + expert, toutes les détections de “positifs” (vrais ou faux) peuvent déclencher une validation experte, et donc requérir du temps de traitement. On peut alors surveiller une éventuelle sur-sollicitation (ou sous-sollicitation) des experts métier par le modèle.
Etape 4 : évaluer la robustesse du modèle
C’est l’incertitude du modèle qui sert de gage de qualité, plus encore que sa performance.
On ne dit pas “il faut 1h30” pour faire le trajet Rouen-Paris en voiture, mais plutôt “il faut entre 1h20 et 2h30 selon la météo et la circulation”. Ce bon sens doit se propager aux modèles prédictifs et à l’évaluation d’incertitudes. C’est d’ailleurs cette incertitude qui va servir de gage de qualité du modèle, au même titre que sa performance. C’est aussi cette incertitude qui va permettre d’évaluer le risque d’un modèle. D’un manière générale, on dit d’un modèle qu’il est robuste si sa performance est stable (comprendre faible incertitude ou écart-type) quand on le perturbe.
Comment évaluer l’incertitude d’un modèle prédictif ? Soit le modèle émerge d’un cadre mathématique qui donne gratuitement l’incertitude (c’est le cas des modèles linéaires généralisés [14]), soit il faut considérer l’apprentissage comme un processus aléatoire et relancer les dés plusieurs fois (voir Figure 7).
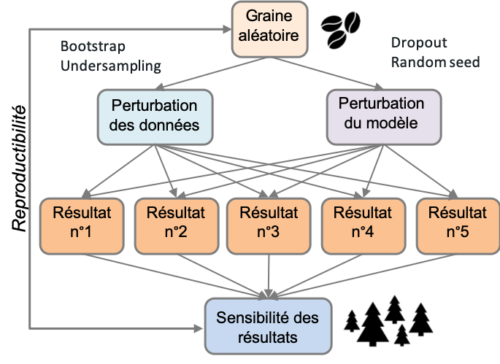
Figure 7 : comment obtenir des incertitudes sur un modèle prédictif ? Une manière simple consiste à répéter l’expérience aléatoire que constitue l’apprentissage en perturbant les conditions initiales, à savoir : le jeu de données et l’algorithme. Chaque perturbation va donner lieu à des prédictions légèrement différentes, sur lesquelles on peut calculer une dispersion de résultats. Et ça ne coûte pas plus cher qu’une recherche d’hyper-paramètres !
Cela signifie qu’il faut perturber les données et le modèle [15]. Perturber les données est quelque chose de bien maîtrisé en statistiques, et il existe des méthodes comme le bootstrap [16] qui sont très populaires. En cas de classes déséquilibrées, le sous-échantillonnage est également un processus aléatoire, qui a une variance propre. Pour ce qui est du modèle, il suffit de modifier sa graine aléatoire (la plupart des modèles reposent sur de l’aléatoire, des arbres de décisions aux réseaux de neurones). On peut même aller plus loin et utiliser des méthodes de Monte-Carlo dropout [17], aussi bien sur les neurones d’un réseau que sur les arbres d’une forêt aléatoire.
Le résultat de ces perturbations est qu’on obtient non seulement une dispersion de résultats [18] à la maille globale (métrique de performance) mais également à la maille locale (sur les prédictions de chaque observation). Cela permet d’identifier des prédictions dont l’incertitude dépend de l’observation, et de poser une question cruciale : “est-ce que ça ne coûte pas plus cher de donner une prédiction totalement incertaine plutôt que de ne pas prédire du tout ?”. Dans certains cas d’usage, il fait sens de laisser la main à un opérateur humain quand l’incertitude est trop élevée.
Etape 5 : déclencher une alerte
Mesurer la stabilité d’un indicateur ou d’un jeu de données est une science à part entière.
Déclencher une alerte est la suite logique du monitoring. Il s’agit de définir les systèmes d’alerte, que ce soit sur les indicateurs de suivi ou sur les batchs de données. La grande majorité des problèmes peut se détecter avec des systèmes simples comme la détection d’anomalies ou les tests statistiques.
Il existe des méthodes plus sophistiquées de déclenchement d’alerte, qui sont des sciences à part entière (voir Figure 8 gauche) :
- la maîtrise statistique des procédés [19], qui construit des tests statistiques online sur des séries temporelles d’indicateurs. On en trouve certaines implémentations dans la librairie scikit-multiflow [20]. La détection de ruptures [21] opère sur des séries temporelles offline et est implémentée dans la libraires ruptures [22].
- la mesure de distance entre jeux de données multidimensionnels [23], qui permet de mesurer à quel point un jeu de prédiction s’éloigne du jeu d’entraînement, notamment via des tests de permutation. On en trouve une implémentation intéressante dans la librairie dcor [24], qui s’appuie sur la distance énergétique [25], une distance invariante d’échelle et invariante par rotation. En particulier, deux échantillons de données distribuées de manière identiques ont une distance énergétique qui tend vers 0 comme O(1/n), n étant la taille des échantillons.
Le point commun à toutes ces méthodes est qu’elles dépendent de paramètres qui vont contrôler le taux de fausses alarmes (ex: seuil, p-value etc.), et l’ajustement de ces paramètres doit être réalisé de manière itérative au début du cycle de vie.
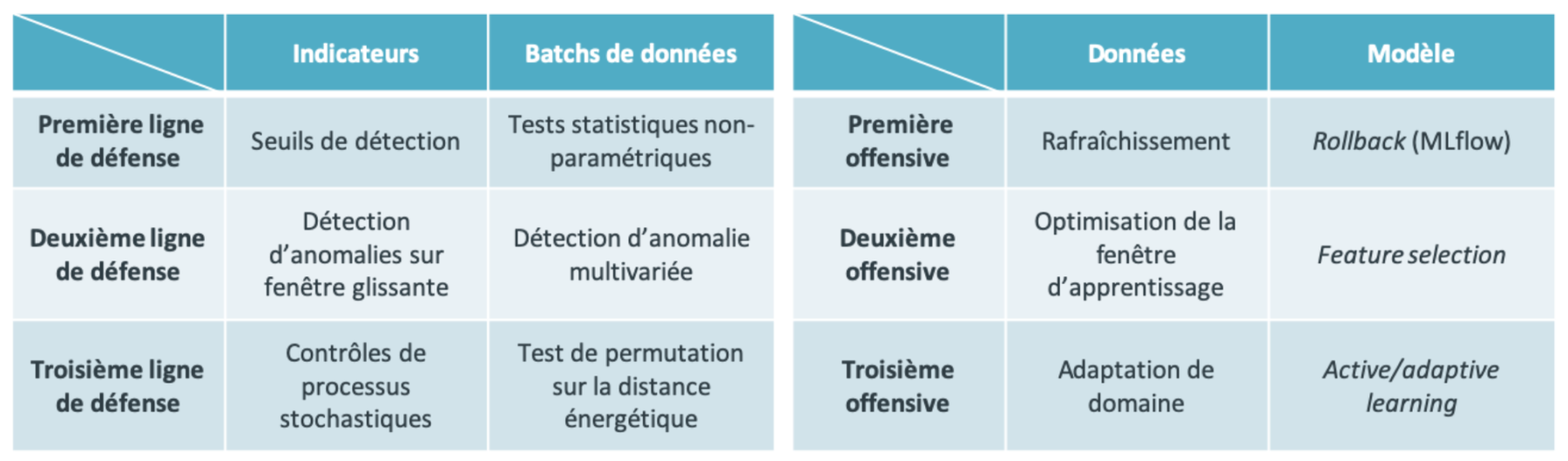
Figure 8 : (Gauche) Trois lignes de défense statistiques pour la détection de dérive de données. On peut agir soit sur les indicateurs de suivi soit directement sur les batchs de prédiction. (Droite) Trois offensives d’adaptation statistiques en cas de dérive de données. On peut agir soit sur le jeu d’entraînement sur directement sur le processus de modélisation.
Etape 6 : identifier la cause
L’objectif est de résoudre les problèmes le plus rapidement possible pour faire tendre le coût de maintenance vers zéro.
Quand un voyant rouge s’allume, il est temps de se ranger sur le bas-côté et d’ouvrir le capot pour comprendre la panne. Dans le cycle de vie des modèles, l’objectif est de résoudre le problème le plus rapidement possible pour faire tendre le coût de maintenance vers zéro.
Une méthode qui a fait ses preuves dans l’industrie du Web et dans le DevOps en général est l’arbre de défaillance [26] (voir Figure 9 gauche). Concrètement, il s’agit d’interroger le problème avec des questions binaires, et de cheminer dans un arbre des problèmes possibles rencontrés dans le passé. L’arbre peut même être imprimé sur un poster et affiché dans un DataLab ou une DSI. Au terme du cheminement, on tombe dans une typologie de problèmes déjà rencontrés, pour lesquels un(e) collègue a effectué des analyses (par exemple un jupyter notebook). Lorsqu’un problème survient, on peut alors capitaliser sur tout l’historique de panne en quelques secondes. Globalement, c’est tout le cycle de vie qui peut être vu comme un processus de capitalisation ordonné, où chaque problème rencontré une fois est détecté et résolu de manière quasi-automatique à l’avenir.
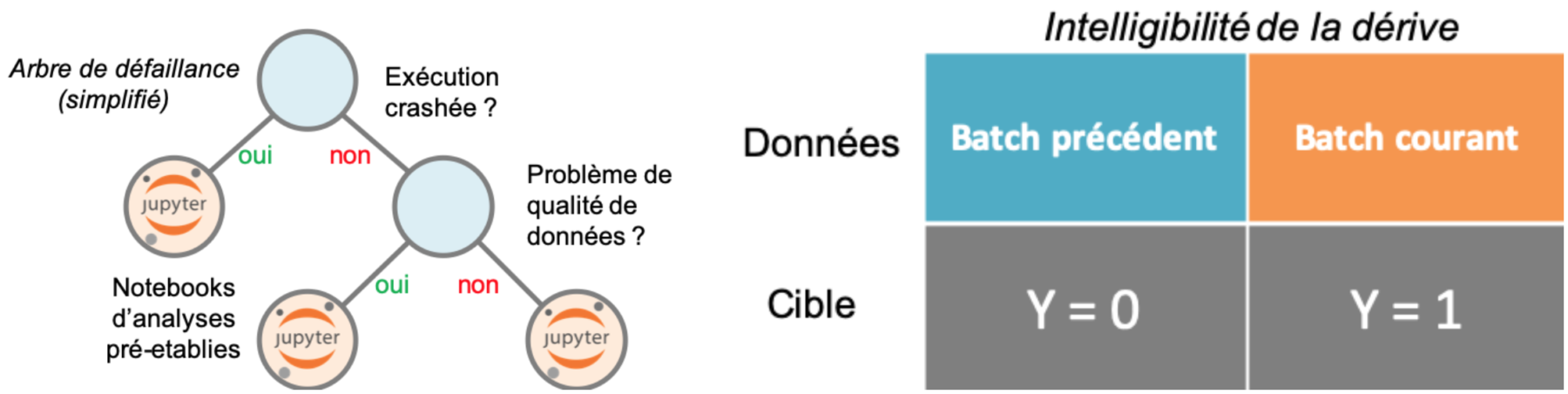
Figure 9 : (Gauche) Un exemple d’arbre de défaillance. Il s’agit d’interroger le problème avec des questions binaires jusqu’à ce que l’on tombe dans une typologie de problèmes similaires déjà résolus dans le passé. (Droite) Intelligibilité de la dérive. Du moment qu’on est capable de dater un problème à la maille batch, on peut très bien créer un label qui va capturer le signal de la dérive. Un modèle de machine learning simple et interprétable (par exemple linéaire) va être capable de s’appuyer sur les variables dont la distribution a changé entre les deux batchs pour identifier un problème.
L’arbre de défaillance va détecter en priorité les bugs de code, d’infrastructure ou de qualité de donnée. Mais lorsqu’on a affaire à une véritable dérive du signal, d’autres méthodes doivent être considérées. Imaginons par exemple que l’on doive réaliser des prédictions batch par batch, un batch pouvant représenter une journée, une semaine ou un mois d’acquisition de données. S’il apparaît (voir étape 6) que le dernier batch est problématique, c’est qu’il y a sûrement eu une dérive de la distribution de la donnée. Nommons cette dérive un signal… et le tour est joué [27] ! Un modèle de machine learning va pouvoir le détecter sans problème. Il suffit pour cela de “nommer” la dérive, avec des labels (voir Figure 9 droite). On peut alors s’appuyer sur des techniques d’intelligibilité globale [28] comme skope-rules [29] pour comprendre quelles variables sont les plus sujettes à la dérive, et si l’on peut les supprimer. On peut alors opérer une feature selection orientée robustesse, et non plus performance, pour s’adapter au changement.
Etape 7 : s’adapter au changement
Si le jeu de prédiction a dérivé par rapport au jeu d’entraînement, le modèle est illégitime pour prédire. L’adaptation de domaine est la science qui va résoudre ce problème.
Une fois le problème identifié, il est la plupart du temps trivial de le régler. La neige vous bloque la route ? Installez des pneus-neiges. Dans le cycle de vie aussi, certaines solutions coulent de source. Cela peut être la résolution d’un bug, le rétro-pédalage sur un modèle non-buggé (rollback), le ré-entraînement sur un jeu de donnée rafraîchi ou la mise à jour du schéma de contraintes (voir étape 2).
Toutefois, dans certains cas difficiles, cela ne suffit pas, par exemple si la dérive des données est trop rapide ou trop complexe. Il faut alors employer des méthodes plus sophistiquées (voir Figure 8 droite), qui sont des domaines de recherche actuels et dynamiques :
- l’apprentissage adaptatif [4] est une méthodologie d’apprentissage en continu sur des flux de données. Il va intégrer une boucle de rétroaction entre la performance et le ré-entraînement automatique du modèle. Il va également se baser sur des comités d’expert, un expert étant un modèle spécialiste d’une période donnée et capable de simuler un mécanisme de mémoire sélective. On peut en trouver des implémentations dans la librairie scikit-multiflow [20].
- l’adaptation de domaine [30] est une méthodologie d’apprentissage par batchs. Soit (X, y) un jeu de données labellisé, typiquement le jeu d’entraînement. Arrive alors un jeu de données Z non-labellisé, c’est le jeu de prédiction. Si Z n’est pas distribué selon la même loi statistique que X (c’est une dérive), le modèle entraîné sur (X, y) est illégitime pour prédire. L’adaptation de domaine est la science qui va trouver la transformation qui relie X à Z (un transport) qui va permettre de réentraîner le modèle sur une distribution semblable au jeu de prédiction. La librairie TLDA [31] implémente plusieurs algorithmes d’adaptation de domaine.
Le cycle de vie n’est donc pas seulement un problème opérationnel, technologique ou organisationnel, c’est aussi un véritable champ de recherche scientifique de plus en plus actif.
Etape 8 : tester la solution
L’A/B testing minimise le risque encouru par la mise en production d’un nouveau modèle en conditions réelles.
Une fois la roue de secours changée, il est sage de rouler quelques mètres et de s’assurer que tout va pour le mieux. C’est pareil pour les modèles en production. Une fois un modèle candidat désigné pour remplacer son prédécesseur, il faut le tester en conditions réelles, c’est ce qu’on appelle l’A/B testing [32]. On en distingue plusieurs types [33], essentiellement (voir Figure 10) :
- le shadow deployment : il s’agit de déployer le modèle candidat en même temps que le modèle en place, mais sans en tenir compte pour la prise de décision. Les prédictions du second modèle servent uniquement de point de comparaison pour chiffrer les potentiels bénéfices. Par exemple en prévision de séries temporelles, on peut très vite comparer la réalité aux deux prédictions concourantes, pour choisir la meilleure.
- le modèle canari : il s’agit cette fois de déployer les deux modèles (actuel et candidat) sur deux sous-populations différentes choisies au hasard. On attend alors de voir comment les deux sous-populations réagissent à chacun des modèles, et dès qu’on a acquis suffisamment de données pour trancher, on peut déployer le meilleur sur l’ensemble de la population. C’est une technique très populaire en web marketing, où la séparation se fait selon les adresses IP.
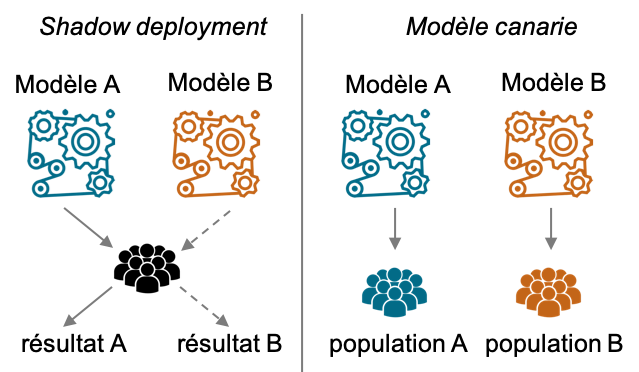
Figure 10 : deux exemples d’A/B testing. Le shadow deployment déploie deux modèles sur la même population mais un seul des deux participe à la prise de décision, l’autre servant de comparateur. Le modèle canari déploie complètement deux modèles sur deux sous-populations différentes et compare les deux influences.
Dans tous les cas, l’A/B testing va chercher à minimiser le risque encouru par la mise en production d’un nouveau modèle en accumulant de l’information sur sa performance en conditions réelles. Une séquence d’A/B testing prend nécessairement un certain temps avant de fournir un pouvoir de décision statistique satisfaisant. Les entreprises du web y consacrent typiquement plusieurs semaines. C’est même un domaine de recherche statistique en soi que de développer des techniques pour raccourcir la durée des A/B testing. On peut citer par exemple les méthodes par stratification ou par variable de contrôle [34].
Etape 9 : documenter l’évolution
Le risque d’évaporation des compétences fait parti du cycle de vie des projets, de l’entreprise et donc du modèle.
Quand un modèle de voiture rencontre un problème grave, on publie les numéros de séries concernés pour informer les usagers. De même pour les modèles : toute mise à jour va nécessairement changer le comportement du modèle. Et les utilisateurs habitués à certaines décisions pourraient abandonner l’outil s’ils ne comprennent pas ses changements ou s’ils trouvent le modèle instable. Il est donc vital, pour l’adhésion des utilisateurs, de notifier a minima les mises à jours du modèle. Qui plus est, plus un modèle est robuste, et plus ses mises à jour seront transparentes pour l’utilisateur (voir étape 4).
D’un point de vue gestion de projet, il est très utile de marquer sur une frise chronologique les changements majeurs de modélisation ou de traitement, avec quelques indicateurs de performances. Cela permet de relativiser une éventuelle baisse ou hausse de performance au regard de tout l’historique du modèle. Idéalement, un service d’intelligence artificielle doit obéir à la même rigueur et à la même dynamique que les logiciels professionnels dans leur gestion de montée de version.
Enfin, le cycle de vie des modèles est intrinsèquement lié au cycle de vie de l’entreprise qui l’héberge, à commencer par le cycle de vie de ses compétences. Pour prévenir le risque d’évaporation des compétences de maintenance en cas de départ d’un collaborateur, il est vital de maintenir une documentation technique et fonctionnelle du projet au fur et à mesure.
Les solutions du cycle de vie
Le cycle de vie des modèles fait la part belle aux méthodes statistiques.
Quelles sont les réponses apportées par le cycle de vie ? Au début de cet article, nous avons posé 9 questions pratiques réparties sur trois volets : organisationnel, scientifique et technologique. On peut alors résumer les solutions discutées dans cet article (voir Figure 11) :
- organisationnel : la clef du succès réside dans la proximité des compétences entre ceux qui développent les modèles et ceux qui les mettent en production (you build it, you run it). Pour clore l’analogie automobile, est-ce que pour conduire une voiture qui tombe tout le temps en panne, il ne faut pas être garagiste ? Ou a minima faire des allers-retours au garage constructeur ? Si ce n’est pas la seule organisation possible, c’est en tout cas celle qui a fait ses preuves jusqu’à présent. Par ailleurs, certaines organisations ne font même pas la distinction entre data scientist et data engineer, c’est le fameux profil hybride machine learning engineer. Enfin, on a vu que la phase monitoring était subtile, et devait être orientée ROI/impact fonctionnel du modèle plutôt que technique. A la maille entreprise, c’est tout l’aspect gouvernance des modèles qui doit être abordé.
- scientifique : le cycle de vie des modèles fait la part belle aux méthodes statistiques, que ce soit pour la détection de dérive (lignes de défense statistiques) ou la production d’incertitudes. Enfin, plusieurs champs de recherche semblent prometteur pour répondre à une dérive de performance (offensives d’apprentissage adaptatif) : l’intelligibilité et l’adaptation de domaine.
- technologique : la qualité de donnée est la passerelle entre cycle de vie des modèles et cycle de vie des données. En ce sens, elle devient naturellement le point d’attention principal dans la maintenance d’un modèle en production. Qui plus est, certaines technologies émergentes comme MLflow [12] et Metaflow [35] s’attaquent au problème de versioning et de reproductibilité des expériences, la base du raisonnement scientifique. Enfin, le redéploiement d’un modèle doit aussi minimiser les risques : c’est la phase d’A/B testing, qui assure une mise en production robuste.
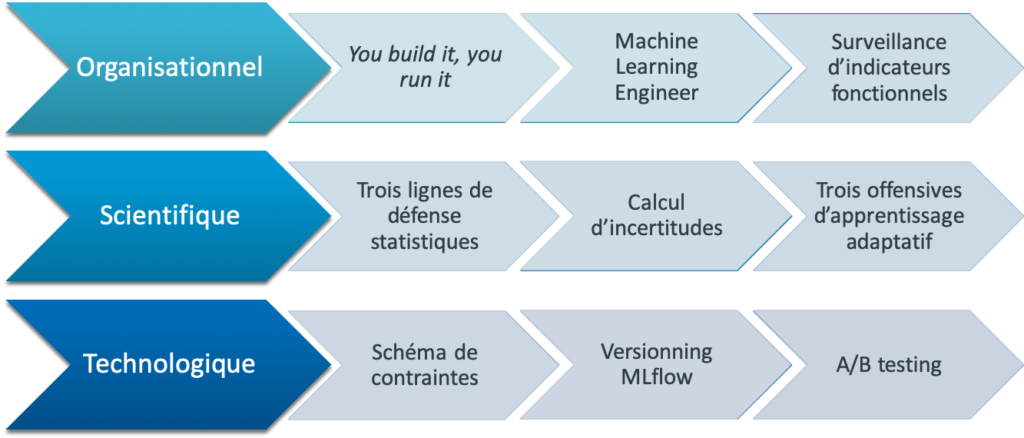
Figure 11 : les réponses apportées par le cycle de vie des modèles. Au niveau organisationnel, c’est la proximité des compétences et des intérêts techniques et métiers qui installe une dynamique efficace. Côté scientifique, plusieurs champs d’application s’ouvrent, que ce soit en terme de détection de dérive, robustesse des modèles ou adaptation de domaine. Enfin, au niveau technologique, c’est la robustesse de la qualité de donnée, la reproductibilité des modèles et le test en conditions réelles qui s’imposent.
Conclusion
Le cycle de vie peut être vu comme un immense processus de capitalisation ordonné.
Pour conclure, on peut voir le cycle de vie comme un immense processus de capitalisation ordonné : dès qu’un problème est rencontré, sa détection et sa résolution peuvent être automatisés dans un schéma de contraintes (étape 2) ou un arbre de défaillance (étape 6). C’est cette mécanique de capitalisation qui, après un investissement initial de construction de la chaîne, permet de faire tendre le coût de maintenance vers zéro.
Qu’est-ce qui coûte le moins cher et est le plus efficace ? La réponse est simple : c’est le monitoring (étape 3). C’est la colonne vertébrale du cycle de vie, celle qui permet de détecter les problèmes et donc de commencer à les résoudre. Dans un premier temps à la main, puis de manière de plus en plus automatisée et robuste. L’expérience montre que 80% des problèmes sont résolus par des tests unitaires qui relèvent du bon sens. Ce serait dommage de s’en priver ;-).
Quantmetry sort son nouveau livre blanc, IA en production [1], disponible gratuitement.
Références
[1] Livre blanc IA en production, par Quantmetry
[2] Why Machine Learning Models Crash And Burn In Production
[3] La gouvernance de la data, cette aventure humaine
[4] Comment s’adapter à l’évolution de la fraude ?
[5] Lessons learned turning machine learning models into real products and services
[6] The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction
[7] TensorFlow Data Validation
[10] TDDA (Test Driven Data Analysis)
[11] Continuous Delivery for Machine Learning
[13] A Recipe for Training Neural Networks
[14] Generalized Linear Models
[17] Bayesian Deep Learning : Soyez sûr de vos incertitudes
[18] Embrace Randomness in Machine Learning
[19] A survey on concept drift adaptation
[21] Selective review of offline change point detection methods
[25] Energy statistics: A class of statistics based on distances
[30] An introduction to domain adaptation and transfer learning
[33] Six Strategies for Application Deployment
[34] Improving the Sensitivity of Online Controlled Experiments by Utilizing Pre-Experiment Data