

Prédire l’intensité d’une tempête et exploiter les avantages du Deep Learning

Introduction
La R&D est au cœur de l’activité de Quantmetry et contribue à l’amélioration continue de ses connaissances scientifiques et techniques sur de nombreuses thématiques. En particulier sur le plan environnemental, Quantmetry a fait le choix depuis plusieurs années de développer des compétences autours de sujets favorables à la gestion de risques environnementaux et climatiques en particulier.
L’intérêt pour la prédiction de tempêtes
Dans un contexte d’urgence climatique, où les aléas climatiques sont de plus en plus au coeur des préoccupations, et présentent un risque conséquent de dommages (physiques et matériels), il est nécessaire de développer des techniques pour pouvoir mieux comprendre, mieux étudier et in fine mieux prévenir ces risques. En ce qui concerne les tempêtes tropicales, il peut être notamment utile de pouvoir prédire l’intensité de celles-ci, même à court terme, pour pouvoir prendre des mesures en conséquences. Nous avons donc cherché à développer un modèle de prédiction d’intensité pour de telles tempêtes. Cette volonté est née conjointement des suites de travaux de Quantmetry sur de la classification de tempêtes tropicales, et de la publication d’une compétition sur la plateforme RAMP [1, 2] dont l’objectif était précisément la prévision d’intensité de tempêtes (c’est donc de cette plateforme que nous avons récupéré le jeu de données dont traite cet article). D’un point de vue technique, c’est également un sujet à enjeu puisque l’analyse de données spatio-temporelles montre un intérêt croissant en Data Science, et l’objectif ici est d’y parvenir en utilisant des méthodes de Deep Learning, en cherchant à exploiter la nature temporelle des données.
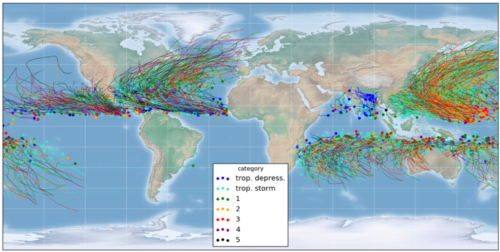
Cartographie des données disponibles
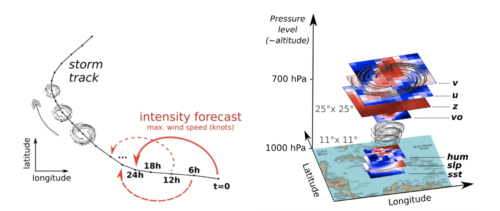
Schéma des données disponibles
Le problème posé est le suivant : établir une prédiction de la vitesse (exprimée en noeuds) à horizon 24h pour chaque point de donnée de tempêtes tropicales. Chaque tempête possède des données composées de données météo méso-échelle géoréférencées fournies sous formes d’imagettes, pour des variables telles que la température ou l’altitude, et de données scalaires telles que la position géographique ou la vitesse initiale par exemple.
Solution proposée
Dans le cadre de ce problème de régression, et étant donné les sources de données à disposition, deux approches sont intéressantes :
- Cible de prédiction : étant donné les importantes variations dans la variable cible, il est plus judicieux de prédire la différence par rapport à la vitesse courante, plutôt que la vitesse elle même : on donne ainsi à notre modèle une cible qui ne contient plus la vitesse déjà acquise (qui fait l’objet d’une variable à part entière) et qui est de plus centrée en zéro, mais surtout ce processus permet de rendre une bonne partie des séries temporelles étudiées stationnaires (ce qui facilite l’apprentissage).
- Analyse des images : les données scalaires ne nécessitent pas du tout le même traitement que les images. En l’occurrence nous avons privilégié les réseaux de neurones convolutifs (CNN) [6] pour ces dernières et donc séparé l’analyse de ces deux sources de données. Ces deux parties ont été optimisées séparément et ont été validées après concaténation.
Intégration de la temporalité
L’enjeu le plus important autour de ces données concerne la prise en compte de la temporalité, qui n’était selon nous pas suffisamment intégrée dans la solution de l’équipe gagnant de la compétition [2]. Ainsi, on pourrait considérer chacun des points à prédire comme indépendants et les traiter séparément, mais les points passés d’une série temporelle sont potentiellement porteurs d’information sur le futur de cette série et il convient donc de les intégrer comme variables explicatives. Nous transformons donc l’approche consistant à associer une combinaison de features à un point, en celle consistant à associer une série de features (i.e. les features des points précédents de la même tempête) à un point cible. Un point d’attention particulier sur cette méthode concerne la complétion des valeurs manquantes pour les points ayant moins d’historique que la longueur de séquence souhaitée. En fonction de la longueur choisie pour les séquences (3 dans l’exemple ci-dessus), les premières valeurs de la série ont des valeurs complétées par padding (# dans le tableau ci-dessus), ce qui pose un problème d’interprétation par notre modèle, puisque ces valeurs n’ont pas de sens concret.
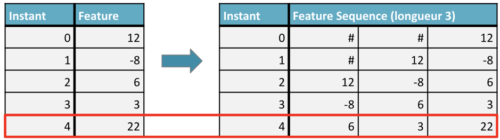
Exemple de création de feature temporel
Intégration de features spécifiques
En complément des variables explicatives déjà disponibles, nous prenons soin d’exploiter l’information de trajectoire, en calculant la variable explicative “bearing”, autrement dit l’azimut de la trajectoire de la tempête [11]. Cette variable circulaire, comprise entre 0° et 359°, peut être encodée depuis le système de coordonnées polaires en coordonnées cartésiennes (cosinus, sinus) afin de permettre au modèle de comprendre que la direction de 1° est très proche sur une cercle de la direction 359°.
Les méthodes clés implémentés
Les CNN
Pour l’analyse des images, nous nous dirigeons naturellement vers des réseaux à convolution (CNN), puisqu’ils fonctionnent particulièrement bien pour l’extraction de features à partir d’images. Une bonne pratique est de choisir une structure propice à cette extraction, c’est à dire avec un nombre réduit d’unités sur les premières couches, mais une taille de filtre assez grande (qui vont capturer les plus gros motifs). Mais avec la profondeur du réseau, le nombre d’unités va augmenter, et la taille des filtres va diminuer, favorisant l’extraction des détails.

Exemple de structure de CNN
ResNets
Avec les CNN, le sur-apprentissage peut arriver relativement rapidement avec le nombre de couches, et afin d’éviter cela, nous utilisons une structure très pratique, les ResNets[3], qui introduisent des sauts de connexion entre les couches afin d’apprendre les résidus ce qui sera plus facile pour le réseau.
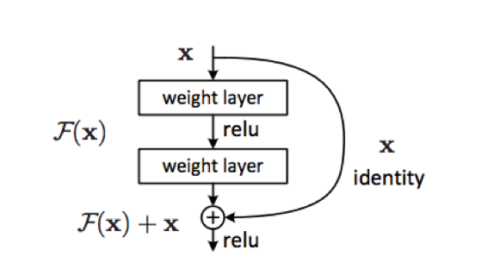
Fonctionnement des connexions ResNet
Lecture d’une série temporelle, CNN ou LSTM ?
Une séquence temporelle, c’est une séquence ordonnée, où l’on suppose que chaque point est dépendant des précédents. Les réseaux de neurones récurrents (RNN) sont donc appropriés pour traiter ce type de séquence, puisqu’ils prennent en entrée une séquence de points qui sont fournis un par un en entrée, et les cellules traitant l’entrée au temps t aura également en entrée la sortie du RNN au temps t-1. Plus particulièrement, les LSTM (Long Short Term Memory) [4, 5, 12] sont plus performant car ils permettent une meilleure persistance de l’information par rapport aux RNN classiques, grâce au “transport” de l’information au fil du temps par cet état caché que l’on appelle la “cell state”.
Mais les réseaux récurrents ne sont pas les seuls à être performants dans l’analyse de série temporelle, les réseaux à convolution sont aussi très efficaces puisque leurs filtres permettent une bonne reconnaissance de motifs spécifiques. On voit d’ailleurs de plus en plus de combinaisons de CNN et de LSTM [7, 8, 9] qui permettent de tirer parti de l’avantage des deux types de réseau (i.e. extraire des features avec les CNN et capturer les dépendances historiques dans les séquences avec les LSTM), ce que nous implémentons également, avec une approche en parallèle (l’approche en série est également envisageable).
Mécanismes d’attention
Dans une séquence temporelle, toutes les données passées n’ont pas forcément la même importance. A priori, le passé proche a une plus grande influence sur notre cible que le passé lointain, mais surtout, les valeurs de padding n’apportent absolument aucune information et il est important que notre réseau le comprenne. Nous mettons donc en place un mécanisme d’attention [10] pour apprendre cela. Ces mécanismes qui sont généralement plus utilisés pour le NLP (traitement du langage naturel), et permettent de comprendre l’importance des mots dans une phrase, peuvent très bien être utilisés dans notre cas pour permettre d’apprendre quelles sont les valeurs importantes.
Ceci nous permet de rallonger les séquences, mais pas de manière excessive. En l’occurrence, pour des tempêtes tropicales, avoir un historique de plusieurs dizaines de jours pour prédire l’évolution d’une tempête ne serait pas forcément pertinent.
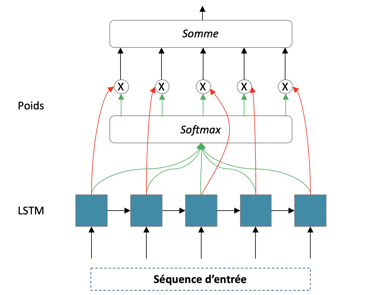
Structure du mécanisme d’attention
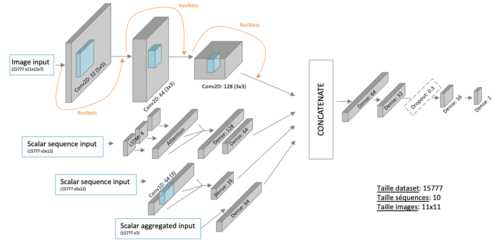
Schéma du modèle final
Analyse de performance
Les résultats obtenus sont encourageants puisque nous obtenons un RMSE (Root Mean Square Error) de 14,98 sur le jeu de test, et les différentes méthodes mises en place contribuent à une amélioration de 10% du RMSE. Ce résultat est d’ailleurs obtenu avec une complexité assez limitée puisque le temps d’entraînement est d’environ une quinzaine de minutes (sur GPU Tesla K80).
On remarque tout de même qu’il y a une différence nette de contribution entre les deux sous-modèles images et scalaires, ce qui justifie l’intérêt de l’étude séparée de ces deux modèles, mais surtout montre que les améliorations à prévoir pour la suite ne sont pas de même nature : améliorer la généralisation pour les images (la différence de performance entre le jeu d’entraînement et de test indique un problème de variance), et l’apprentissage pour les scalaires (on constate un biais plus important que sur le modèle image, mais une variance plus réduite). Le modèle global en revanche semble plutôt bien généraliser.
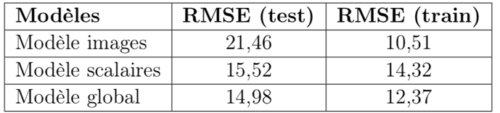
Tableau récapitulatif des scores
Remarque: La méthode de mesure d’erreur de prédiction actuelle (identique à la méthode principale utilisée lors du challenge RAMP) considère qu’un point donné a la même importance qu’un autre. Cette hypothèse est discutable, puisque si l’on cherche à juger la qualité de notre prédiction, mais aussi notre capacité à analyser une information temporelle, il paraît naturel d’être plus exigeant sur la prédiction d’un point ayant un long historique temporel de données, par rapport à un point en ayant peu. Ainsi, il conviendrait d’être plus critique sur les prédictions en début de tempête qu’en fin de tempête, et de sous-pondérer les erreurs faites sur les débuts de tempête.
Conclusion
La solution développée dans cette approche montre bien le potentiel du Deep Learning et d’une approche de traitement en série temporelle dans la prédiction d’intensité de tempêtes. Les capacités d’analyse temporelle sont notamment conséquentes, et peuvent sans doute être encore largement améliorées, pour fournir une solution plus robuste. Avec une analyse plus approfondie, on peut notamment probablement améliorer le feature engineering pour intégrer encore plus la spécificité du problème dans nos variables.
L’analyse de tempêtes tropicales, et de manière plus générale l’étude de phénomènes climatiques, est et restera un enjeu important des années à venir, et continuera de constituer pour nous un intérêt particulier. Ce projet constitue donc une étape supplémentaire dans l’accumulation de connaissances et d’expérience dans ce qui pourrait permettre le développement de modèles de risques bien plus élaborés, et potentiellement appliqués à des cas d’usages réels.
✍Article écrit par François-Xavier Ferlande et Guillaume Hochard
Annexes:
Détail des données disponibles
Jeu de donnée utilisé 739 séries temporelles, pour un total de 22 395 points d’observation espacés de 6h (source: RAMP).
Les informations à disposition pour chacun de ces points de donnée sont les suivantes :
- Position géographique : latitude, longitude
- La valeur courante de la vitesse
- L’hémisphère (sud=0, nord=1)
- Une donnée basée sur le pic de vitesse de la tempête :
\</span>exp{\frac{-(Jd-Pd)^{2}}{Rd}}<span style="font-weight: 400;">où Jd= jour julien du début de la tempête, Pd= jour julien du pic, et Rd=un timestep donné - La vitesse initiale de la vitesse
- La variation maximale de vitesse sur les 12 dernières heures
- Le basin
- La nature de la tempête
- La distance à la côte
Nous avions également à disposition des images (taille 11×11) centrées sur la localisation de la tempête, pour les paramètres suivants :
- L’altitude z
- u-wind : positif si le vent vient de l’ouest
- v-wind : positif si le vent vient du sud
- sst : la température à la surface (Sea Surface Temperature)
- slp : la pression à la surface (Sea Level Pressure)
- hum : l’humidité à 1000hPa
- vo700 : le vecteur tourbillon à 700hPa
Références
- Compétition: https://ramp.studio/problems/storm_forecast
- Sophie Giffard-Roisin, David Gagne, Alexandre Boucaud, Balázs Kégl, Mo Yang, Guillaume Charpiat, Claire Monteleoni, The 2018 Climate Informatics Hackathon: Hurricane Intensity Forecast, hal-01924336
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, Deep Residual Learning for Image Recognition, arXiv :1512.03385, 2015.
- S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- Hojjat Salehinejad, Sharan Sankar, Joseph Barfett, Errol Colak, Shahrokh Valaee, Recent Advances in Recurrent Neural Networks, arXiv :1801.01078, 2018.
- Jiuxiang Gu, Zhenhua Wang, Jason Kuen, Lianyang Ma, Amir Shahroudy, Bing Shuai, Ting Liu, Xingxing Wang, Li Wang, Gang Wang, Jianfei Cai, Tsuhan Chen, Recent Advances in Convolutional Neural Networks, arXiv :1512.07108, 2017.
- Wu Yuankai, Tan Huachun, Short-term traffic flow forecasting with spatial-temporal correlation in a hybrid deep learning framework, arXiv :1612.01022, 2016.
- Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-kin Wong, Wang-chun Woo, Convolutional LSTM Network : A Machine Learning Approach for Precipitation Nowcasting, arXiv :1506.04214, 2015.
- Tao Lin, Tian Guo, Karl Aberer, Hybrid neural networks over time series for trend forecasting, OpenReview, id :ByD6xlrFe, 2017.
- Harshall Lamba Intuitive understanding of attention mechanism in deep learning, https://towardsdatascience.com/intuitive-understanding-of-attention-mechanism-in-deep-learning-6c9482aecf4f
- Bearing, https://www.movable-type.co.uk/scripts/latlong.html
- Understanding LSTM Networks, https://colah.github.io/posts/2015-08-Understanding-LSTMs/