

Pris en flagrant délit par une IA ! Comment détecter les attaques de guichets automatiques bancaires.

Il existe près de 55 000 guichets automatiques bancaires (GAB) en France [1]. Chaque guichet automatique peut contenir jusqu’à 150 000 euros en liquide [2]. De quoi largement attiser les convoitises…
Les attaques de GAB
Il y a plusieurs moyens pour extraire de l’argent d’une boîte en métal :
- La force brute, par insertion de pelleteuse ou de voiture brûlée dans le GAB afin de l’ouvrir [3] (voir Figure 1). Efficace et certaine, cette technique représente un coût pour l’attaquant, qui doit acheter, louer, ou tout simplement “obtenir” un véhicule. S’il s’agit d’un engin de chantier, sa location/usurpation est facilement traçable par les services de police.
- Les explosifs, notamment en remplissant le caisson par un mélange de gaz adéquat [4]. Peu coûteuse et facile à mettre en place, cette technique peut toutefois dégrader fortement le contenu du GAB.
- Le skimming, qui consiste à augmenter la fente carte d’un enregistreur d’empreinte magnétique [5]. Couplé à un système de caméra caché pour obtenir le code, le fraudeur peut récupérer l’empreinte sur son téléphone à distance, imprimer une toute nouvelle carte bleue, clone de l’originale, et l’utiliser normalement. Cette technique demande des compétences assez rares ainsi qu’un investissement dans le dispositif d’enregistrement.
- Le piratage informatique, qui consiste à prendre le contrôle du logiciel du GAB et à lui ordonner de se purger de son contenu [6]. C’est l’attaque qui nécessite le plus de savoir-faire, et une connaissance pointue de la structure physique et informatique du GAB.
- L’attaque de personnes, qui consiste souvent en une diversion, qui peut aller de la prestidigitation à l’attaque au rat mort [7], en passant par la violence physique. C’est de loin la méthode la moins coûteuse, mais aussi parmi les plus risquées car elle nécessite d’agir en plein jour devant témoins.

Figure 1 : un exemple d’attaque au chariot élévateur [8].
Les parades standards reposent principalement sur le renforcement physique du GAB ou la maculation automatique de billet suite à percussion. Là où la Data Science intervient, c’est sur le traitement automatisé de la vidéo-surveillance.
Vidéo-surveillance : des données sous contraintes
Les données de vidéo-surveillance sont une source directe d’informations qui permet de savoir ce qu’il se passe sur directement sur site. Ce sont donc les données de choix pour réussir à détecter les attaques de GAB. Toutefois, elles sont soumises à plusieurs contraintes :
- Diversité : tous les guichets automatiques sont équipés de caméra différentes (marques, résolution, angles de vues).
- Volume : une caméra filmant H24 génère environ 1 téraoctet de données par mois.
- Loi : le stockage de données vidéo filmant un lieu public ne peut dépasser un mois [9].
- Temps réel : du point de vue de la banque, seul le flagrant délit a de la valeur, pour épargner le vol de billets et/ou les réparations coûteuses qui en résultent. Ses leviers d’action sont par exemple le déclenchement d’alarmes, l’intervention de la police ou la télé-interpellation [10].
- Embarqué : pour des raisons de rapidité et de sécurité, les données doivent être traitées sur site. L’algorithme doit donc héberger directement sur le GAB, et pas sur un serveur distant.
- Absence de labels : en toute probabilité, un GAB n’a fait l’objet d’aucune attaque ces 30 derniers jours. Cette faible probabilité, combinée à la contrainte légale, rend impossible l’obtention d’extraits vidéo filmant une attaque (sur le périmètre restreint de GAB étudiés), et donc de labels. La détection doit donc être nécessairement non-supervisée.
Toutes ces contraintes conspirent pour éloigner du champ des possibles les méthodes standards de classification d’images sur la base de jeux de données labellisées.
Stratégie de détection : convertir les vidéos en séries temporelles et détecter les anomalies
Afin de proposer une solution de détection d’attaques qui obéisse à toutes ces contraintes, on peut envisager la stratégie suivante :
- Détecter des zones riches de sens (visage, mains, outils, véhicules etc.)
- Traquer en temps réel la position de ces différentes zones
- Enregistrer les données de détection uniquement sous forme de séries temporelles
- Détecter les séries temporelles anormales
Sur la Figure 2, on illustre le procédé de conversion de vidéo en série temporelle. Les avantages de cette méthode sont multiples.
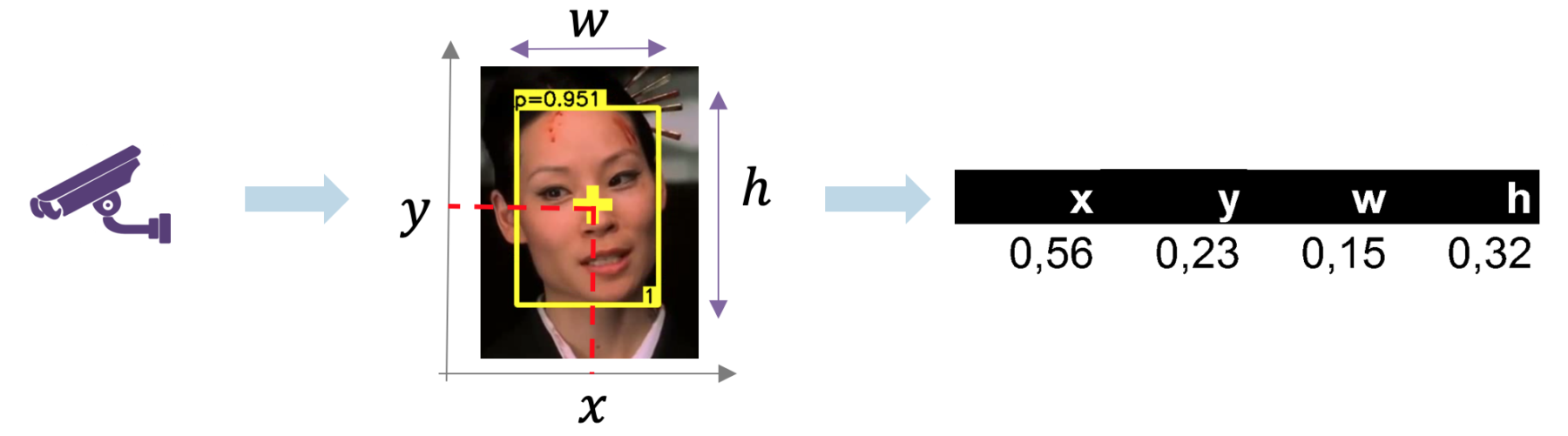
Figure 2 : conversion d’une vidéo (extrait du film Kill Bill) en séries temporelles. Sur chaque image, on peut identifier des zones d’intérêts (ici un visage) et n’enregistrer que les 4 nombres qui caractérisent le cadre de détection : positions, hauteur, largeur. En appliquant cette méthode à chaque image d’une vidéo, on obtient donc 4 séries temporelles par objet détecté.
Tout d’abord, c’est une compression et une anonymisation parfaite : impossible de reconnaître quelqu’un sur la base de quelques nombres.
Ensuite, l’information encodée est informative : on peut savoir si une personne (ou un objet) est seul, proche ou loin de la caméra, si une personne se baisse, si ses mains sont en train de visser quelque chose en hauteur, quel est le temps de présence devant la caméra etc.
Enfin, il existe une artillerie standard de détection d’anomalies sur des séries temporelles et de détection de séries temporelles anormales. L’avantage de l’utilisation de GAB est qu’elle est extrêmement normée par le logiciel : une interaction normale dure typiquement 90 secondes, le timing des gestes est dicté par les interactions logiciel et l’agencement physique du GAB (fente carte en bas à droite), la position des personnes est debout et immobile. L’information contenue dans les séries temporelles est donc suffisante pour établir un premier niveau de détection de comportements anormaux.
La conversion en séries temporelles permet donc de résoudre les contraintes légales et de volume. On peut donc extraire un historique très vaste de données. Quant à la brique détection d’anomalies, c’est celle qui répond le mieux à l’absence de labels. La question qui reste en suspens est : peut-on opérer cette solution en temps réel ?
Deep learning et temps réel, un mariage compliqué
Depuis la percée fulgurante du deep learning en 2012 [11], il est difficile de ne pas considérer les possibilités qu’offrent les réseaux de neurones en matière de détection sur des images. La Figure 3 illustre les possibilités offertes par le deep learning en matière de détection.

Figure 3 : possibilités offertes par les réseaux de neurones en terme de détection. De gauche à droite : la détection de visage, la détection de repères faciaux, la détection de poses corporelles, la détection de poses manuelles, la détection d’objets, et la détection de masques.
Toutefois, le deep learning coûte cher, en temps de calcul notamment. Par exemple, sur un Mac standard, il faut compter entre 1 et 5 secondes de temps de calcul pour traiter une image ! D’après les développeurs de l’algorithme de détection d’objets Yolo_v3 [12], il est possible de réduire le temps de calcul d’un facteur 5 à 6, pourvu qu’on se dote d’une carte graphique Pascal Titan X à 2000 euros sur la marché [13]… Dernière solution : louer des ressources sur le cloud, ce qui est complètement incompatible avec l’exigence d’algorithme embarqué mentionnée plus haut.
En réalité, ce problème fait couler beaucoup d’encre dans le monde de la recherche et nourrit depuis plusieurs années une littérature intensive sur la compression des réseaux de neurones (voir à ce propos notre article de blog [14]).
Le tracking, l’alternative temps réel au deep learning
Face à cette barrière scientifique, technologique et pécuniaire que représente le deep learning temps réel, une solution retient notre attention : c’est le tracking [15]. En effet, les données vidéo ne sont pas un flux d’images aléatoires, elles ont une auto-corrélation forte : deux images consécutives sont, la plupart du temps, très similaires. Le tracking est une famille d’algorithmes qui va justement prendre en compte cette structure particulière pour amoindrir le temps de calcul (voir Figure 4).
Figure 4 : différence entre la détection et le tracking de zone d’intérêt (ici un visage). La détection est renouvelée à l’identique pour chaque image, tandis que le tracking capitalise sur les images précédentes pour trouver la réponse plus rapidement.
Le principe du tracking est simple et on l’illustre ci-après pour la détection de visages pour fixer les idées. Sachant le visage sur l’image n, on veut déduire où se trouve le visage sur l’image n+1. Une manière simple de faire est d’utiliser un produit de convolution : le visage cible est testé sur toutes les positions possible de l’image source, et on retient la localisation pour laquelle le recouvrement du signal est le plus fort (voir Figure 5).
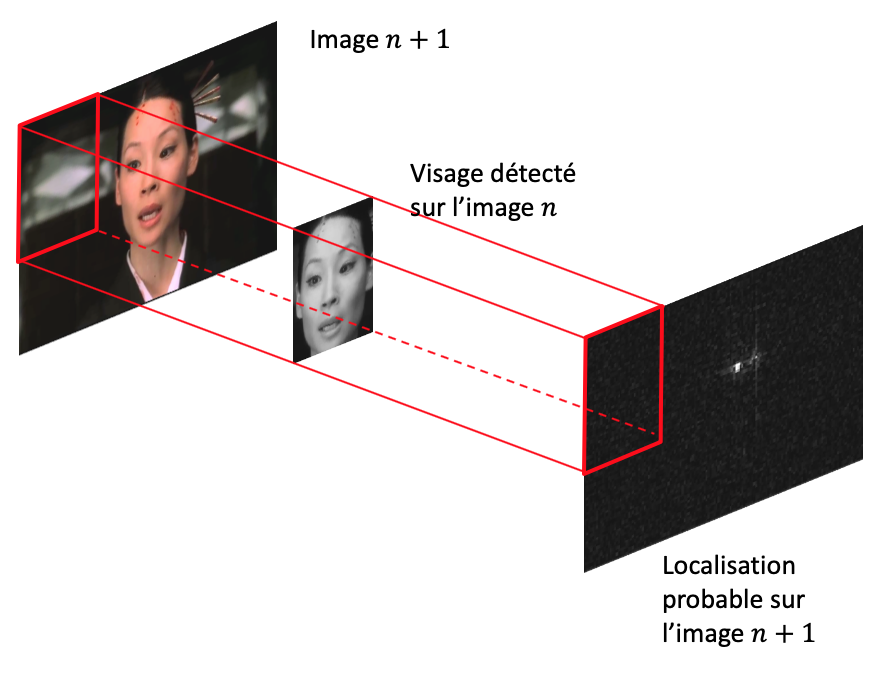
Figure 5 : principe du produit de convolution. On teste toutes les positions possibles et pour chacune on relève le recouvrement (somme du produit des pixels 2 à 2). La nouvelle position du visage est attribuée à la zone de recouvrement le plus fort.
En théorie, c’est une manière sûre de déduire la nouvelle position du visage. En pratique, le produit de convolution est très coûteux en temps de calcul, de par l’exhaustivité des produits effectués et des localisations testées. Cependant, grâce au théorème de convolution [16], on peut réduire le nombre d’opérations à une seule ! Le tour de passe-passe est accompli en passant dans l’espace de Fourier :
La transformée de Fourier d’un produit de convolution entre f et g est le produit des transformées de Fourier de f et de g.
On illustre son fonctionnement sur la Figure 6. La philosophie est identique au machine learning :
- Phase d’apprentissage : on part d’une image labellisée (comprendre : avec un visage identifié). On la sépare en des variables explicatives X (les pixels noir et blanc), et une variable cible Y (une image binaire indiquant là où se trouve le visage). L’astuce consiste à transformer X et Y dans l’espace de Fourier. Dans cet espace, le théorème de convolution nous donne d’un coup d’un seul le filtre F qui relie X à Y : c’est simplement le rapport des deux images transformées.
- Phase d’inférence : une nouvelle image non-labellisée arrive (comprendre : sans visage détecté pour l’instant). On la passe dans l’espace de Fourier. Par application du filtre, on trouve la transformée de Fourier de la réponse. En repassant dans l’espace réel, on obtient la prédiction
\hat{Y}de localisation.
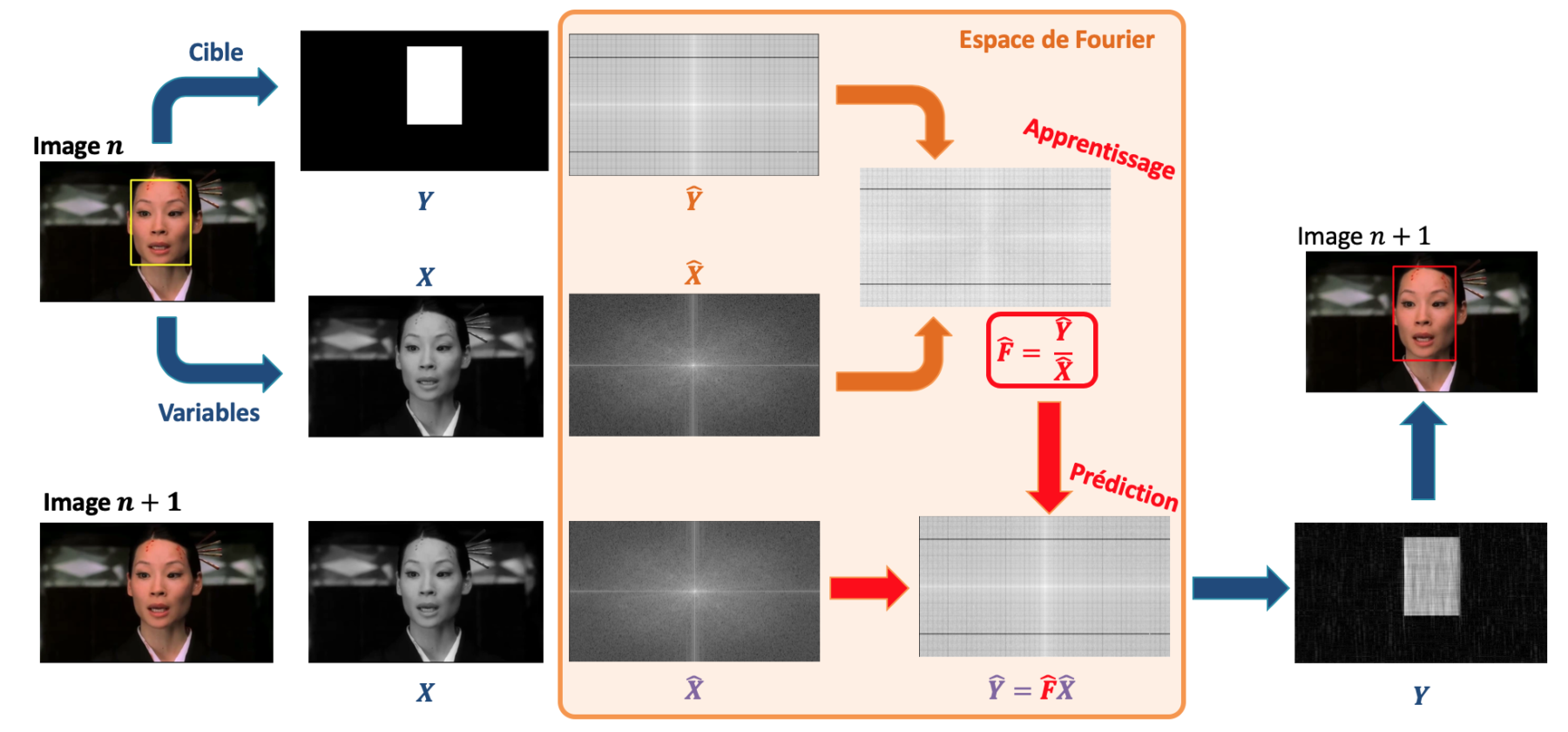
Figure 6 : application du théorème de convolution au tracking. C’est en réalité du machine learning. Plus précisément, il s’agit de construire un modèle linéaire dans l’espace de Fourier. L’apprentissage ne requiert qu’une image et est instantané.
En réalité, le tracking n’est rien d’autre qu’un modèle linéaire dans l’espace de Fourier, et dont le théorème de convolution fournit une solution analytique. L’absence de descente de gradient rend l’apprentissage instantané sur une jeu d’entraînement qui consiste en une seule image : l’image précédente (en réalité dans [15] c’est une poignée d’images qui est utilisée, à des fins de stabilisation).
Par rapport à un réseau convolutif à une couche, le temps de calcul est donc accéléré car :
- la phase d’entraînement est une simple division dans l’espace de Fourier,
- la phase d’inférence est une simple multiplication dans l’espace de Fourier,
- la transformée de Fourier numérique est une opération largement optimisée depuis les années 70 et est très rapide.
En pratique, nous avons pu observer que le tracking permettait de traiter une image en 15 millisecondes seulement sur un Mac standard, soit 10 fois plus rapidement qu’un réseau de neurones.
Tracking et deep learning, le mariage de raison
Oui, mais voilà : comment démarrer un algorithme de tracking sur la toute première image du flux vidéo ? Si l’algorithme est bien capable d’entretenir le feu de la détection tout au long du flux, encore faut-il allumer un signal sur la première image ! C’est là que le deep learning remonte sur scène. D’une précision sans égale par rapport aux méthodes classiques (les cascades de Haar sur OpenCV par exemple [17]), le deep learning (en l’occurrence un ResNet10 [18]) permet de générer le premier cadre de détection. Il s’agit donc d’investir un peu de temps de calcul au démarrage du traitement, puis de capitaliser ensuite grâce au tracking. Après une période transitoire de moins d’une seconde, on atteint le régime temps réel, comme illustré sur la Figure 7.
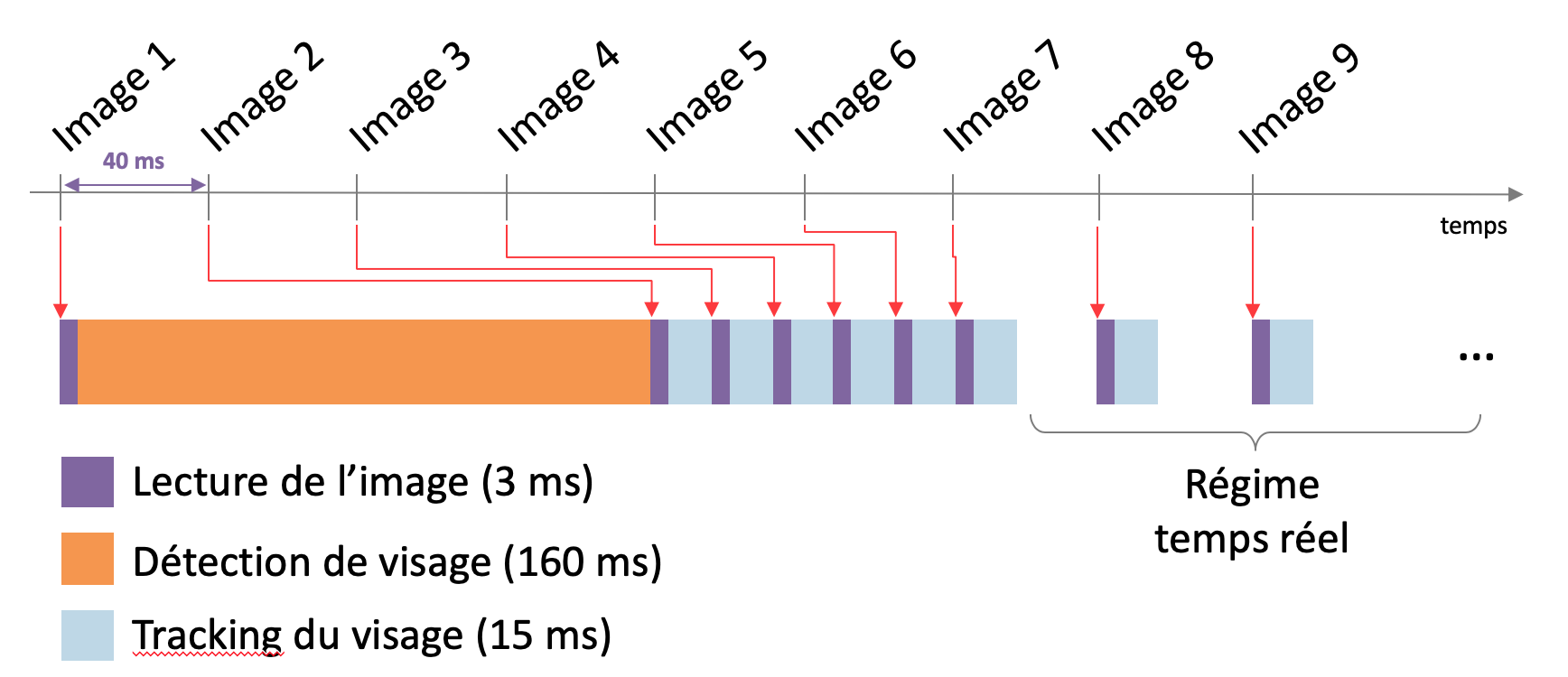
Figure 7 : détection en temps réel sur un flux vidéo. Un flux standard émet 24 images par secondes, soit une image toutes les 40 millisecondes. La première détection est à la charge d’un algorithme de deep learning. Le temps d’inférence est très long et le calcul prend du retard sur le flux d’image. Une fois la première détection effectuée, le tracking prend le relai et rattrape le retard en quelques images.
A titre d’illustration, nous mettons à disposition sur ce lien une exemple de vidéo traitée automatiquement en temps réel, en traquant le visage. Il s’agit d’une interview du footballeur Ngolo Kanté. A titre indicatif, nous avons mis le temps de calcul nécessaire pour chaque image. Le régime temps réel (inférence inférieure à 40 millisecondes) est bien atteint. Afin d’éviter les dérives du tracker, le feu de la détection est rallumé de manière périodique avec l’algorithme de deep learning.

Figure 8 : images extraites de la vidéo illustrative disponible sur ce lien.
Détection d’anomalies en temps réel
Une fois le processus de detection + tracking mis en place, on peut bien convertir notre vidéo en séries temporelles. Sur la Figure 9, on montre les 4 séries temporelles afférentes à la vidéo illustrative. Sur ce graphe, on voit distinctement que :
- Le début et la fin de la vidéo ne comportent pas de visage
- La vidéo est un plan fixe
- La personne interviewée oscille régulièrement de la tête avec une faible amplitude
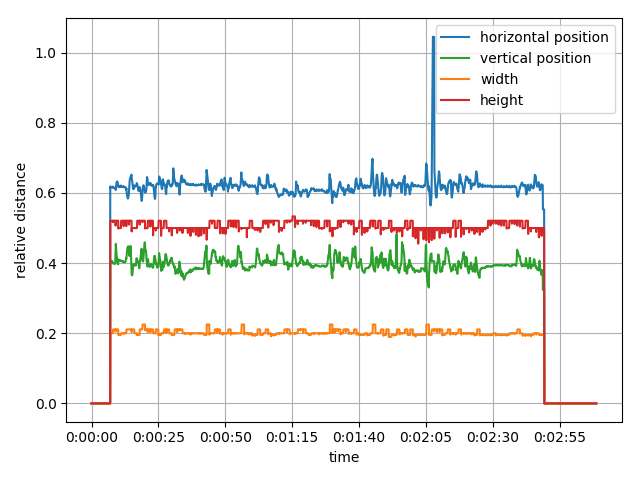
Figure 9 : séries temporelles extraites en temps réel de la vidéo illustrative. On y voit 4 séries temporelles : la position horizontale, la position verticale, la largeur et la hauteur du cadre de détection. Aux alentours de 02:05, on constate une anomalie dans la position horizontale.
Et… c’est tout ? Rien ne vous choque ?
Bien vu ! A l’œil nu, on est capable de distinguer une anomalie sur la courbe bleue. Essayez donc de comprendre la nature de l’anomalie en regardant directement la vidéo illustrative !
…
Alors, vous l’avez trouvée ? En effet, cette anomalie n’est pas un comportement anormal de la personne filmée, mais un comportement anormal de la vidéo : une bande de texte a défilé, est passée dans le cadre de détection, et a fourni un signal fort dans l’espace de Fourier (correspondant à la fréquence spatiale des motifs, autrement dit la taille de la police). Le tracker s’est donc attaché au texte plutôt qu’au visage. Pour corriger de telles dérives, on réinvestit de manière périodique dans une détection deep learning. La fréquence de rafraîchissement pilote le compromis entre temps de calcul et risque de dérive.
D’une manière générale, il faut bien comprendre qu’en l’absence de labels, un détecteur d’anomalies ne peut être spécifique à un comportement particulier : toutes les anomalies vont être capturées, même celles auxquelles on ne s’attend pas !
Limitations et perspectives
Dans cet article, nous avons abordé la conversion en temps réel de flux vidéos en séries temporelles, pour répondre à une contrainte légale et capturer les flagrants délits. Nous nous sommes focalisés sur la détection de visage à des fins illustratives, mais la méthode s’applique également aux mains et aux objets en toute genre (corps, véhicules, outils).
Nous n’avons pas discuté en détail la brique suivante qui est la détection d’anomalies en temps réel sur ces séries temporelles. Toutefois, on peut d’ores et déjà anticiper qu’un détecteur d’anomalies émettra de nombreuses fausses alarmes. On peut alors tenter de résoudre ce problème en ajoutant une brique supervisée de type active learning : en faisant analyser et labelliser certaines anomalies, on peut entraîner un algorithme de détection supervisée de fausses alarmes.
Plus généralement, l’ajout de règles métier semble indispensable pour consolider ce traitement : par exemple, un écran qui devient subitement noir peut signaler soit un dysfonctionnement soit une attaque de la caméra.
La tracking doit aussi être adapté lorsqu’il y a plusieurs objets de même nature sur l’image (par exemple deux mains). Si un objet passe devant l’autre, les positions des deux objets peuvent se confondre et s’échanger. On peut résoudre ce problème en s’appuyant sur la vitesse et l’estimation de trajectoires de chaque objet. Par ailleurs, le temps de calcul du tracking croît linéairement avec le nombre d’objets traqués, ce qui peut nécessiter de faire appel à du calcul parallèle sur plusieurs processeurs.
Enfin, il faut garder à l’esprit que tous les systèmes de détection sont faillibles, et qu’il est toujours possible de se rendre invisible pour un système de détection, via des techniques d’adversarial learning [19]. Comme toute guerre technologique, il ne s’agit pas d’obtenir une protection efficace à 100%, mais d’augmenter la difficulté et la pénibilité de l’activité frauduleuse, dans une logique dissuasive et de réduction des risques.
A retenir
Le traitement d’images et de vidéos est une science qui a précédé l’avènement du deep learning de plusieurs décennies. Malgré des progrès spectaculaires et fulgurants, le deep learning n’est pas une réponse universelle au traitement automatique d’images et de vidéos. Il est encore aujourd’hui largement handicapé par son coût en temps de calcul, que ce soit lors de l’apprentissage ou de la phase d’inférence. Le tracking apparaît alors comme une méthode simple, élégante et facile à mettre en œuvre, qui résout la contrainte temps réel en s’appuyant sur la structure de corrélation du flux vidéo. Cette technologie est implémentée en accès libre sur OpenCV [20], et est détaillée dans Bolme et al. [15].
[1] https://fr.statista.com/statistiques/489663/nombre-guichets-automatiques-bancaires-france/
[2] http://www.lefigaro.fr/conjoncture/2010/12/15/04016-20101215ARTFIG00643-les-distributeurs-automatique-de-billets-le-maillon-faible.php
[3] https://www.ledecodeur.ch/2014/01/16/comment-vider-un-distributeur-automatique-de-billets-avec-une-cle-usb/
[4] https://www.20minutes.fr/faits_divers/2237507-20180314-nord-parviennent-emparer-distributeur-billets-aide-gaz
[5] http://leparticulier.lefigaro.fr/jcms/p1_1695730/gare-au-skimming-une-technique-de-fraude-a-la-carte-bancaire
[6] http://www.leparisien.fr/seine-et-marne-77/bussy-saint-georges-tentative-de-jackpotting-d-un-distributeur-de-billets-26-11-2018-7953849.php
[7] https://mcetv.fr/mon-mag-politique-societe/societe/lycee-deux-jeunes-arretes-mis-feu-etablissement-de-07062019/
[8] http://www.hauteprovenceinfo.com/article-5563-un-distributeur-automatique-attaque-dans-la-nuit-a-chateau-arnoux.html
[9] https://www.cnil.fr/fr/cnil-direct/question/videoprotection-combien-de-temps-peuvent-etre-conservees-les-images
[10] https://www.youtube.com/watch?v=Q65KRImw3Xs&t=22s
[11] https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
[12] https://pjreddie.com/darknet/yolo/
[13] https://www.materiel.net/produit/201608010129.html
[14] https://www.quantmetry.com/neural-networks-embedded-systems/
[15] https://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf
[16] https://fr.wikipedia.org/wiki/Produit_de_convolution
[17] https://docs.opencv.org/3.4/db/d28/tutorial_cascade_classifier.html
[18] https://github.com/opencv/opencv/tree/master/samples/dnn/face_detector
[19] https://www.theverge.com/2019/4/23/18512472/fool-ai-surveillance-adversarial-example-yolov2-person-detection
[20] https://docs.opencv.org/3.4/d9/df8/group__tracking.html
