

Q-Deep : une plateforme d’analyse d’image à la hauteur des défis de demain

Détection d’objets à partir d’images satellites ou de drones, classification d’environnement… nous vous proposons un petit aperçu des possibilités qu’offre notre socle technologique interne !
Introduction
Le Deep Learning appliqué à l’analyse d’image s’est largement démocratisé à partir de 2013 lorsque le concours ILSVRC (Imagenet Large Scale Recognition Challenge) a été remporté avec l’architecture de réseau de neurone AlexNet. Aujourd’hui les techniques d’analyse d’image s’appuyant sur du Deep Learning sont de plus en plus utilisées dans le milieu industriel avec par exemple des applications dans l’imagerie médicale et la sécurité. Les outils d’analyse d’image développés incluent notamment la détection, la reconnaissance, la reconstruction ou encore la colorisation d’image.
Pour adresser cette demande croissante, nous avons mis en place un socle technique, logiciel et matériel, permettant d’accélérer considérablement les projets d’analyse d’images utilisant les méthodes de Deep Learning :
-
Serveurs dotés de cartes vidéo de dernière génération
-
Environnement logiciel déployable rapidement pour ajouter des serveurs de calcul à la demande
-
Architecture de code modulaire, permettant de réutiliser le code d’un projet à l’autre.
Cela nous permet, dans un contexte donné, de nous focaliser sur la conception de l’architecture des réseaux de neurones et leur évaluation (accélérée par nos serveurs de calculs). Le challenge Kaggle d’analyse d’images satellite « Understanding the Amazon from Space » au cours du mois de juillet 2017 a été l’occasion pour nous de construire un test public de ce socle. La constitution de ce dernier répondait à trois objectifs, qui permettent de comprendre l’utilité d’un tel socle :
Comparer l’approche Deep Learning aux approches plus traditionnelles de traitement d’image ;
– Évaluer l’intérêt d’utiliser des réseaux de neurones pré-entraînés plutôt que de les faire apprendre « from scratch » ;
– Évaluer l’intérêt de réentraîner partiellement un réseau déjà pré-entraîné (fine tuning) ;
– Montrer la généricité de notre architecture logicielle adaptée aux sujets de deep learning. Cet article de blog présente dans un premier temps l’environnement mis en place et dans un second temps notre approche lors du concours Kaggle.
Quelle infrastructure pour l’analyse d’image ?
40 000 images d’entraînement et 80 000 images de test en couleur de 256×256 : c’est un beau volume à digérer pour un réseau de neurones.
Nous avons donc sorti l’artillerie lourde : notre QBox.
Carte vidéo NVIDIA TITAN XP :
3840 cores CUDA
Fréquence : 1.5GHz
Mémoire : 12GB
GDDR5X
• Intel socket 12 coeurs hyperthreadés @ 4GHz
• 128 Go RAM @ 2100 MHz Quad Channel
• 256Go SSD OS + Programmes
• 1-12To RAID10 6Gb/s ; 6 HDD 7200tr/min
Afin de pouvoir ajouter facilement des machine à la volée pour paralléliser les expériences nous avons « containerisé » notre environnement et notre application avec la technologie bien connue nommée Docker.
Petite remarque concernant la « containérisation » des applications tournant sur GPU :
Docker est fait pour rendre matériel et plateforme agnostiques les applications utilisant le CPU. La solution pour les cartes nvidia est d’installer le plugin nvidia-docker qui va se « brancher » sur les drivers GPU de la machine hôte, et d’installer le CUDA toolkit dans le container. Ainsi pour toute nouvelle machine installée il suffit d’installer les drivers GPU pour faire tourner le container.
Quelle architecture logicielle ?
L’architecture de notre plateforme se déclinait comme suit :
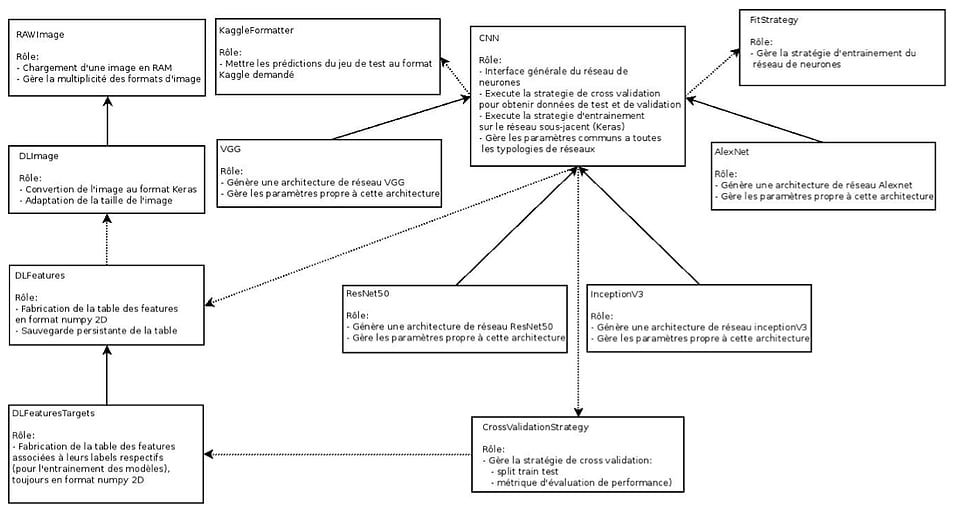
Ainsi, pour faire fonctionner le pipeline avec les spécificités du concours, nous avons uniquement modifié :
-
DLFeaturesTargets pour l’adapter à la classification multi labels en traitement d’image
-
KaggleFormater car il fallait mettre les résultats à un format précis pour les soumettre
-
CrossValidationStrategy pour implémenter la métrique d’erreur f2 multi-labels utilisée par le concours
Nos efforts durant la compétition se sont principalement concentrés sur FitStrategy (la stratégie d’entraînement) et les différentes architectures de réseaux de neurones (AlexNet, InceptionV3, …)
Le Challenge et son aspect multi classes
Dans le but d’étudier la localisation, les modes et les causes de déforestation en forêt amazonienne, Planet, distributeur de mosaïques d’images satellites a lancé au mois d’Avril un défi Kaggle de classification : « Understanding the Amazon from Space, use satellite data to track the human footprint in the Amazon rainforest ». Le challenge consistait à réaliser un modèle capable de labéliser les images en fonction de la présence d’éléments tels que des rivières, des nuages, des routes, des mines, des zones de déforestation, etc.
https://www.kaggle.com/c/planet-understanding-the-amazon-from-space
Contrairement à des problèmes de reconnaissances classiques où une seule classe peut être affectée à une image (« Cette image représente un chat. »), la principale particularité de ce challenge est l’aspect multi classes : « Cette image représente une forêt, une rivière et des habitations. ».
Le jeu de données et la métrique de performances de l’algorithme
Le jeu de donnée était constitué de 120 000 images en couleurs (rouge, vert, bleu) de 256 x 256 pixels au format JPG, pouvant contenir jusqu’à 17 labels différents (haze, cloudy, partly_cloudy, clear, primary agriculture, water, habitation, road, cultivation, slash_burn, conventional_mine, bare_ground, artisinal_mine, blooming, selective_logging, blow_down).
La métrique du projet, le score évaluant les performances de prédiction est le f2 score, moyenne harmonique pondérée de precision-recall et variante du f1 score, s’exprimant de la manière suivante :

Ce score met en valeur le recall c’est à dire qu’il favorise davantage la détection des labels peu fréquents que la précision des prédictions. Les modèles calculent des probabilités d’appartenir à une classe et non directement la classe, nous avons alors déterminé le seuil de probabilité pour décider si la classe est prédite ou non de manière à maximiser ce score sur le jeu d’entraînement.
Pour réaliser le test public de notre plateforme, nous avons suivi le plan suivant :
● Mise en place d’un modèle de classification classique (notre modèle benchmark) utilisant comme variables descriptives des images les distributions des couleurs,
● Mise en œuvre d’architectures types de réseaux de neurones à convolutions non pré-entraînés
● Utilisation de ces mêmes réseaux, cette fois pré-entraînés
● Entraînement partiel des réseaux pré-entraînés
Le modèle benchmark
Nous avons commencé par le construire à partir d’un algorithme Random Forest (modèle de classification ensembliste), qui a servi de « benchmark » pour la suite de nos travaux. Pour créer les variables explicatives de notre modèle nous avons remplacé chaque image par son histogramme des couleurs. Chaque image se voit attribuée 26 features représentant la distribution de la bande colorimétrique rouge, 26 features pour le bleu et 26 features pour le vert.
Partant de ces 26 + 26 + 26 features, nous avons entraîné un modèle de Random Forest pour chaque label à prédire (haze, cloudy, partly_cloudy, …).
Une fois soumis, ce modèle benchmark nous a permis d’obtenir des prédictions avec un score F2 de 0.86 sur le jeu de test du site Kaggle.
La performance de cette approche plutôt simplifiée est assez surprenant, certes nous n’étions pas dans les premiers du concours mais le score de 0.86 n’était pas si éloigné de la performance des meilleurs qui se situait autour de 0.93.
Cette méthode était particulièrement performante pour détecter les labels s’identifiant principalement par des signatures de couleurs spécifiques dans les images, par exemple pour détecter la présence de forêt vierge ou de terrain dénudé.
L’entraînement de réseaux de neurones à convolution « from scratch »
Première étape utilisant des réseaux de neurones à convolution dans notre approche, nous avons entraîné « from scratch » un modèle basé sur des architectures de réseaux de neurones tels qu’AlexNet ou VGG à partir de la bibliothèque Keras.
Les données d’entrée du réseau de neurones étaient les pixels bruts comme il est d’usage dans l’analyse d’image par Deep Learning
Remarque : pour obtenir une prédiction multi labels où plusieurs labels peuvent être présents à la fois sur une même image, il faut utiliser une fonction d’activation « sigmoïde » sur la dernière couche, et non la fonction d’activation « softmax » très utilisée dans les exemples Keras. En effet, la fonction d’activation sigmoïde renverra une probabilité entre 0 et 1 pour chacun des labels que l’on souhaite prédire alors qu’une fonction d’activation softmax nous aurait donné uniquement le label le plus probable.
Le résultat obtenu en entraînant ce réseau de neurones durant deux jours (convergence de la métrique d’erreur non atteinte) n’était pas satisfaisant quelle que soit l’architecture utilisée (AlexNet ou VGG). Avec un score f2 moyen de l’ordre de 0.78 sur le jeu de test Kaggle, sa performance était globalement bien en deçà du modèle benchmark de Random Forest entraînés sur les histogrammes de couleur… Mais pas pour toutes les classes :
Pour les classes avec une forte importance de l’information spatiale, le réseau de neurones à convolution était bien meilleur. Par exemple : des habitations auront une forme précise, une rivière également.
Ce faible résultat paraît surprenant, car dans d’autres projets avec des images de plus petite taille les réseaux non pré-entraînés avaient donné des performances plutôt satisfaisantes.
On constante ainsi que l’entraînement “from scratch” pour des images excédents une certaine taille n’est pas une solution optimale.
Utilisation de réseaux pré-entraînés
Les principales architectures de réseaux de neurones tel que InceptionV3 et ResNet50 sont disponibles dans la librairie Keras pour la classification d’images, pré-entraînés à partir du jeu ImageNet.
Il suffit alors de les adapter à notre problème en ajoutant des couches en sortie afin d’adapter le réseau. En effet, les réseaux d’origine permettent de prédire une probabilité pour les 1000 classes d’ImageNet, ce qui ne correspond pas aux 17 classes du concours Kaggle.
Les coefficients des couches ainsi rajoutés ont ensuite été entraînées, en gelant les poids des couches précédentes.
Avec le même temps d’entraînement que pour les réseaux non pré-entraînés nous avons obtenus des scores bien meilleurs : 0.9 (à la place de 0.78) pour InceptionV3 et ResNet50.
Ainsi, à partir d’une taille d’image 256×256, il est nettement plus avantageux d’utiliser des réseaux pré-entraînés que de les entraîner « from scratch ».
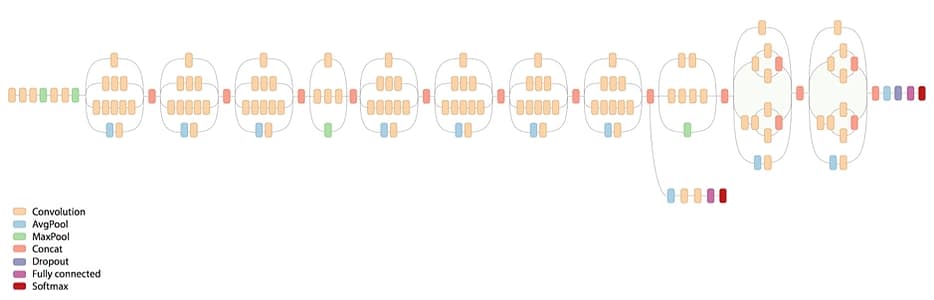
Typologie du réseau InceptionV3 :
Réentraînement partiel des réseaux de neurones pré-entraînés
Un réentraînement partiel des modèles consiste à ré-entraîner certaines couches supérieures du réseau de neurones pré-entraîné, et pas seulement les couches supérieures que nous avons ajouté.
Nous avons alors ré-entraîné spécifiquement les deux derniers blocs des architectures Inception V3 et ResNet50. Cette démarche a permis d’améliorer les résultats, nous sommes passés de 0.9 à 0.91 pour InceptionV3 et 0.92 pour ResNet50
Conclusion
Références :
Thibaud N., 2016, Abeille ou bourdon ? Activons les neurones (2/2), Article de blog – Quantmetry: https://www.quantmetry.com/single-post/2016/10/24/Abeille-ou-bourdon-Activons-les-neurones-22
Thibaud N., 2016, Abeille ou bourdon ? Activons les neurones, Article de blog – Quantmetry: https://www.quantmetry.com/single-post/2016/01/21/Abeille-ou-bourdon-Activons-les-neurones
