

Les notes de Quantmetry au salon Big Data Paris 2019

Les 11 et 12 mars derniers au Palais des Congrès de Paris s’est déroulé la 8ème édition de l’évènement annuel tant attendu LE salon Big Data Paris. Objectif des deux jours : sortir de ces lieux en ayant eu un panorama complet des opportunités, perspectives et technologies du big data.

C’est dans une ambiance électrique que le salon s’est ouvert : plus de 16 000 participants, 250 exposants, 5 zones dédiées aux ateliers et 2 amphithéâtres ! Cette année encore, le salon occupe une surface encore plus importante que pour l’édition précédente !
9 heures : nous étions fins prêts à enchaîner les rencontres et les conférences bien décidés à nous imprégner des nouvelles tendances 2019 et à vous les partager.
Apache Kafka sur le devant de la scène
La première grande tendance 2019 est la généralisation des architectures temps réel.
Dans bon nombre de RETEX clients, la technologie Apache Kafka est au cœur de l’architecture applicative. C’est notamment le cas de la nouvelle plateforme Analytics / Datalake G2 d’Orange.

Apache Kafka est une technologie éprouvée d’une dizaine d’années. Initialement développé par la société LinkedIn, le code source a été Opensourcé en 2011. Depuis, il a intégré le cercle restreint des Top Level Projets (TLP) de la fondation Apache. Il s’agit d’une technologie nativement distribuée orientée pour le streaming. Il s’agit d’un composant de premier choix dans les projets big data. Celui-ci s’interface facilement avec d’autres technologies de référence de l’écosystème big data tel Apache Cassandra ou Apache Spark. Eux aussi sont des TLP de la fondation Apache et bénéficient d’une très grande communauté. Sur le plan technique, c’est la gestion des partitions qui est conservée d’un système à l’autre.
La conférence « IoT Sensor Analytics with Apache Kafka, KSQL and Tensor Flow » a mis en lumière les capacités de prédictions temps réel d’Apache Kafka appliqué à un cas d’usage de Data Science. Ci-dessous, l’architecture IoT basée sur KSQL & Kafka Connect présentée par Kai Waehner, Technology Evangelist chez Confluent.
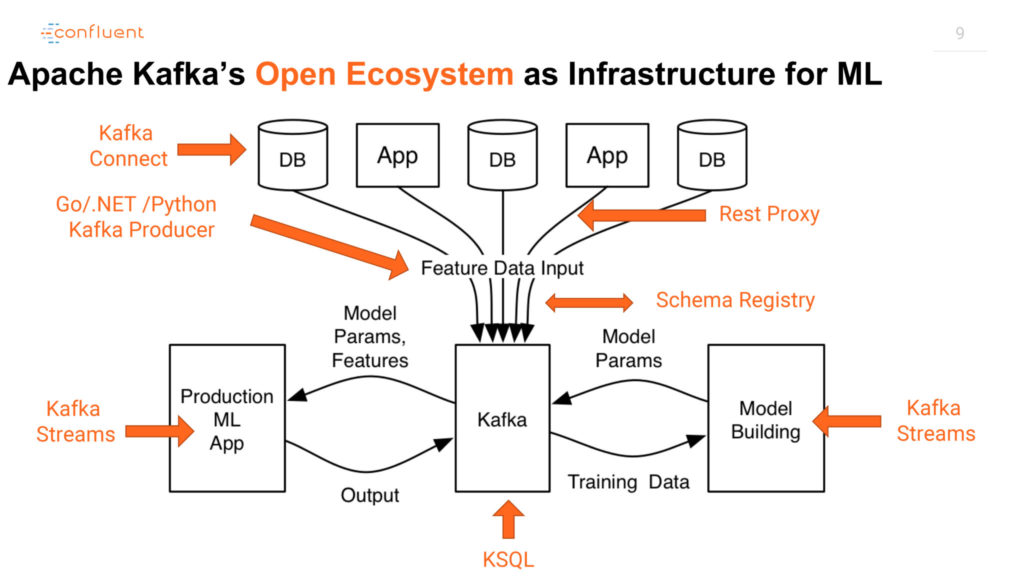
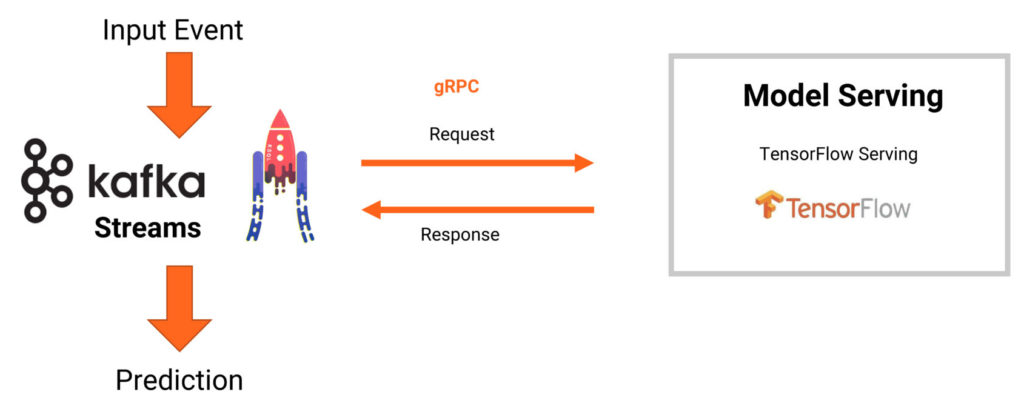
Une fois le modèle entrainé, les prédictions du modèles TensorFlow sont réalisées en temps réel par l’intermédiaire de Kafka Streams / KSQL. Dans l’exemple ci-dessous, l’application communique avec le modèle via le protocole RPC. Au besoin, il est possible de réaliser les prédictions directement depuis l’application.
Le déploiement de ce type d’architecture est facilité par l’utilisation d’une architecture construite avec les solutions cloud proposées par AWS, GCP ou Azure. Dans la conférence « Panorama des solutions Big Data & Machine Learning à utiliser (et celles à oublier) », Cédric Carbone, CTO d’Ogury, utilise la phrase choc « OnPrem is dead » !
Le concept de « Fonction as a service » – la nouvelle coqueluche du Serverless computing
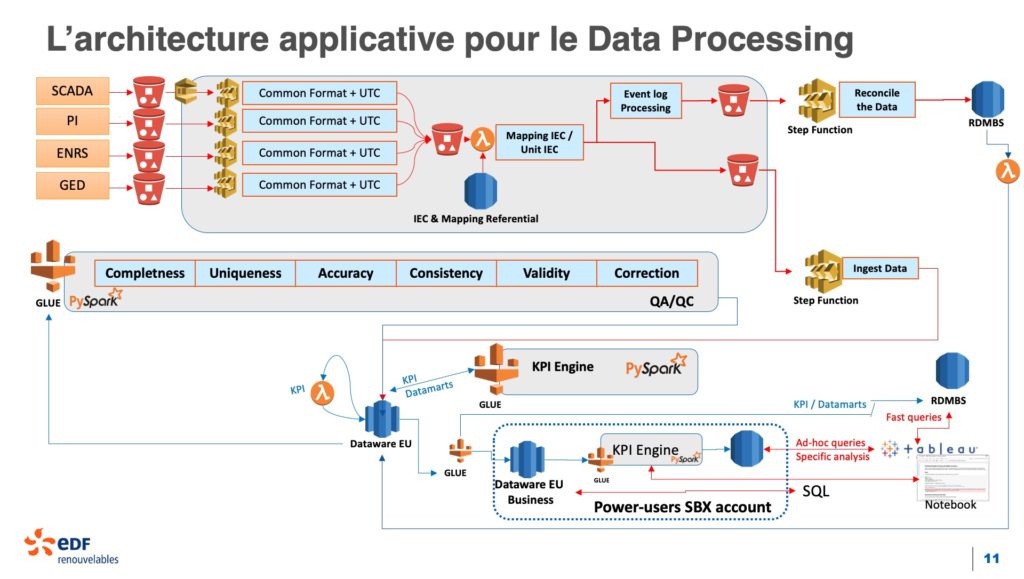
L’avènement du cloud computing à fait émerger le paradigme « Function as a Service » (FaaS). Le service AWS Lambda lancé en 2014 a fortement contribué à populariser ce type d’architecture. Dans l’atelier « Plateforme cloud : agrégation et valorisation de données – nouveaux usages », EDF Renouvelables nous détail la plateforme IoT en charge de la gestion mondiale du parc d’éolien. Ci-dessous, le schéma d’architecture soutenu par notre Data Architect Olivier Denti.
Généralisation des plateformes de data science as a Service
Une tendance se dégage du marché de la data : les POC, pensés pour l’industrialisation, disparaissent au profit de projets « at-scale. » Plusieurs raisons expliquent ce constat. Tout d’abord les technologies data sont de plus en plus matures, permettant ainsi de passer d’une approche « technology-driven » à une approche « use-case driven » où les initiatives sont pilotées par les cas d’usage et les problématiques fonctionnelles. Ensuite, les phases d’expérimentation sont souvent consommatrices de temps et d’argent. La finalité étant de prouver un concept ou une méthodologie qui en pratique a déjà souvent été prouvée. Enfin, le dernier point est l’adoption souvent timide par les métiers de ces solutions.
Cela s’explique par plusieurs raisons. D’une part les solutions développées à l’issu d’un POC manquent parfois d’actionnabilité et d’utilisabilité car la démarche d’expérimentation n’a souvent pas vocation à permettre aux métiers d’interagir avec la solution développée. D’autre part, l’implication des métiers à la phase d’expérimentation peut être faible ce qui limite la compréhension des données et de la modélisation utilisée et donc à terme, de son adoption.
Un des « takeaway » de ce Big Data Paris 2019 est la généralisation des plateformes « Data Science as a Service » qui font la promesse de lever ces freins en simplifiant les expérimentations data et en accélérant leur mise en production. Quantmetry a assisté à deux retours d’expérience dans le domaine de la banque : Une présentation de Florian Caringi, Mickael Le Bars et Nicolas Korchia sur l’utilisation de la Data Science pour optimiser les opérations de Back Office chez Natixis et un talk de Bertrand Ring et François Simeonidis de la BRED sur la maintenance prédictive des guichets automatiques de banque.
La présentation de Natixis se voulait être un retour d’expérience sur la gestion des prêts à destination des grands comptes. De par la variété des devises, des risques, des conditions et des acteurs, les opérations de financement qui mènent à terme un contrat entre différents partis rendent la gestion et le monitoring de cette activité complexe. Côté Natixis, le suivi de cette activité se faisait historiquement via des tableaux Excel avec toute la complexité et la fastidiosité qui en découle. Une des solutions a été d’hébergée avec l’aide du 89C3R la Digital Factory de Natixis, cette activité dans le datalake en ajoutant à l’aspect BI du monitoring, des mécanismes de data science permettant de mieux comprendre et mieux anticiper certains éléments complexifiant les tâches des gestionnaires Back Office. Un des « pain point » de ce projet est la complexité des extractions de données, de leur préparation et de la diversité des environnements techniques nécessaires au déploiement du projet sur l’environnement de production. Une des solutions apportées par Natixis à ces freins est l’utilisation de la solution de Data Hub d’Indexima, une plateforme d’exécution centralisée se positionnant entre les data sources et les applications de restitution. Elle leur a permis entre autres d’unifier les environnements de développement et de production et d’interagir avec les modèles de data science via un langage unifié : Le SQL.
Le retour d’expérience de la BRED s’articulait quant à lui autour de la mise en place d’un cas d’usage de maintenance prédictive de ses GAB. Le projet a été porté par la Data Factory de la BRED pour qui son premier cas d’usage data remonte à 2016 avec la mise en place d’un score d’appétence au crédit conso. Un des challenges technique à relever afin de modéliser le problème a été de gérer l’hétérogénéité des typologies de panne (Claviers hors service, lecteurs de carte en panne, problèmes réseaux, etc) et l’asymétrie des durées d’indisponibilité (20% des pannes sont des indisponibilités de moins d’une minute). Une des solutions apportée dans la modélisation proposée est l’utilisation d’une approche hybride faisant appel à la fois à des modèles de classification via des méthodes ensemblistes et de techniques d’analyse de survie sur des clusters de GAB ayant un comportement similaire. L’implémentation du cas d’usage s’est faite via l’utilisation de la plateforme logicielle collaborative de data science : Dataiku DSS. Elle a permis d’une part aux équipes data de travailler plus sereinement de manière collaborative et d’autre part d’accélérer la mise en place de pipelines de data extraction et de data preparation.
En conclusion bien que les outils diffèrent d’un acteur à l’autre, force est de constater que la généralisation des plateformes Data Science as a Service se confirme. Elles permettent en effet d’accélérer la mise en place d’expérimentation data via la centralisation des environnements techniques, la mise en place de pipeline d’extraction et de préparation de données ainsi que de modèles de machine learning facilement requêtables. Toutefois chez Quantmetry notre conviction est que leur mise en place n’est pas nécessairement la réponse à toutes les initiatives data, elles ont en effet un certain coût et doivent pouvoir être dimensionnée en fonction du besoin, de la taille et de la maturité data de l’organisation. Les technologies temps réel ont gagné en maturité sous l’influence des GAFAM et du Cloud computing faisant de ce besoin un état de fait dans de nombreuses industries.
Rendez-vous dans un an à Big Data Paris 2020 pour vous partager les nouveautés et les tendances du marché de la data !