

Nos recommandations pour réussir l'adoption d'Apache Spark en 2021

Cet article est rédigé conjointement avec :
Data Mechanics, une start-up soutenue par YCombinator et fondée par d’anciens ingénieurs de Databricks, commercialise une plateforme Spark de nouvelle génération déployée sur Kubernetes. Leur mission est de rendre Spark plus facile à utiliser et plus rentable, avec un focus sur les tâches de data engineering.
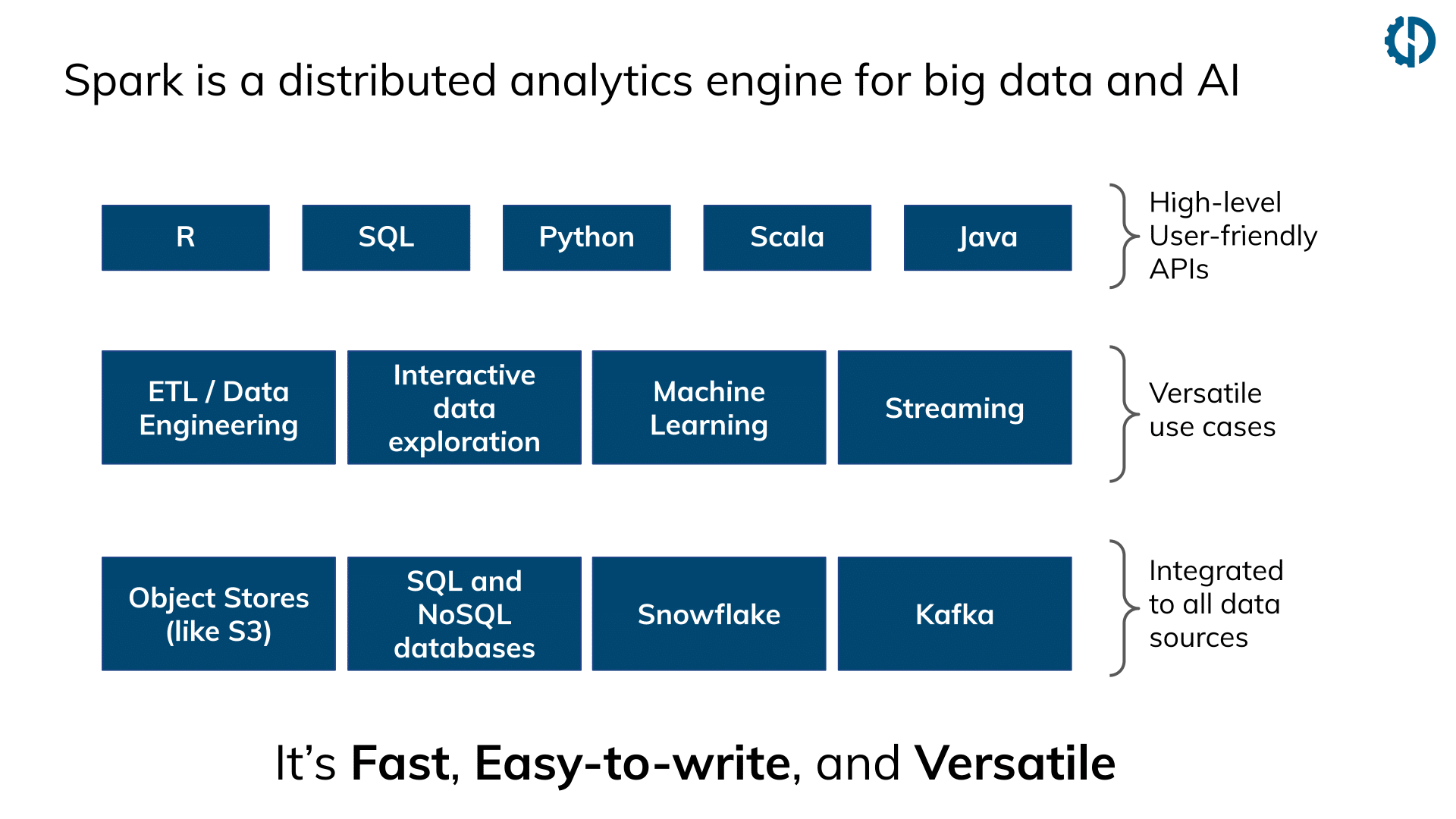
Qu’est-ce qui rend Apache Spark populaire ?
Dans le monde de la data science et du data engineering, Apache Spark est la technologie de pointe pour travailler avec de grands volumes de données. La communauté des développeurs Spark est florissante : la plupart des entreprises ont déjà adopté ou sont en train d’adopter Apache Spark. Sa popularité est due à 3 raisons principales :
- C’est rapide. Il peut traiter de grands volumes de données (à l’échelle du GB, TB ou PB) grâce à sa parallélisation native.
- Spark dispose d’API en Python (PySpark), Scala/Java, SQL et R. Ces API permettent une migration simple des charges de travail Python « mono-machine » (non distribuées) vers un fonctionnement à l’échelle avec Spark. Par exemple, la bibliothèque Koalas a récemment été publiée, ce qui permet aux développeurs Python de transformer facilement leur code Pandas en Spark. Le fait que du code Python/Scala puisse être exécuté donne également aux développeurs beaucoup plus de flexibilité que les cadres de travail uniquement SQL comme Redshift et BigQuery.
- Spark est très polyvalent. Apache Spark dispose de connecteurs pour pratiquement tous les stockages de données, et les clusters Spark peuvent être déployés dans n’importe quel plates-forme cloud ou on-premise.
Quels sont les principaux points douloureux d’Apache Spark ?
Adopter Spark, c’est aussi avoir à relever des challenges :
- Le premier défi est le fait qu’il est difficile pour les débutants de comprendre comment leur code est interprété et distribué par Spark. Vous devez apprendre les subtilités de Spark et atteindre un certain niveau d’expertise pour être capable de débugger votre application lorsqu’elle ne fonctionne pas comme prévu (par exemple, débugger une erreur de mémoire), et pour comprendre puis optimiser sa rapidité d’exécution. Spark présente de nombreuses configurations qui sont complexes à mettre en place pour les débutants. Par conséquent, la plupart des développeurs Spark ont tendance à s’en tenir aux paramètres par défaut, sans se rendre compte à quel point cela peut nuire à la stabilité et aux performances de leurs applications.
- Le deuxième défi est la gestion de l’infrastructure. Quelle devrait être la taille de notre cluster Spark ? Quel type de machines virtuelles et de stockage dois-je choisir ? Comment devrions-nous collecter et visualiser les logs et les métriques ? Ces défis se présentent sous deux formes différentes entre les déploiements on-premise (avec Hortonworks, Cloudera, MapR) et les déploiements dans le cloud (AWS : EMR, GCP : Dataproc, Azure : HDInsight).
- Pour les déploiements on-premise, le principal défi est le compromis coût/vitesse sur la taille du cluster. Si vous sur-dimensionnez votre cluster, vos coûts feront boule de neige et vous souffrirez la plupart du temps d’une faible utilisation et d’un sur-approvisionnement en ressources de votre cluster. Si vous sous-dimensionnez votre cluster, il ne pourra pas supporter les pics de charge de travail et vous devrez mettre en place des files d’attente prioritaires pour vous assurer que les charges de travail critiques pour votre mission ne sont pas retardées.
- Pour les déploiements cloud, l’élasticité du cloud provider résout ce problème car les ressources peuvent être ajoutées ou retirées à la volée. Cela signifie également que les coûts ne sont pas limités et qu’il appartient à chaque utilisateur de Spark de dimensionner et de configurer ses applications de manière appropriée et de s’assurer qu’elles sont stables et rentables. Bien que les services soient dits « gérés », le véritable fardeau de la gestion et de la configuration repose toujours sur les équipes data qui utilisent le cluster Spark.
Passons maintenant en revue les meilleures pratiques et les recommandations de Data Mechanics pour relever ces défis.
Simplifier la gestion de l’infrastructure Spark grâce à une approche serverless
Data Mechanics est une plate-forme Spark gérée, déployée sur un cluster Kubernetes, cluster qui est hébergé directement sur l’espace cloud des clients. Elle est disponible sur les 3 grands fournisseurs cloud (AWS, GCP et Azure) et constitue une alternative aux plateformes comme Databricks, Amazon EMR, Google Dataproc et Azure HDInsight. Jean-Yves, un ancien ingénieur de Databricks, maintenant co-fondateur de Data Mechanics, explique 3 caractéristiques principales qui permettent une approche serverless pour Apache Spark.
- C’est Dockerisé.
Kubernetes a un support natif pour les conteneurs Docker. Ces conteneurs vous permettent de créer vos dépendances en une fois (sur votre ordinateur local) et d’exécuter votre application partout de manière cohérente : sur votre ordinateur local, pour du développement et des tests ; ou dans le cloud sur des données de production.
En utilisant Docker plutôt que des scripts d’initialisation lents et des téléchargements de dépendance à l’exécution, vos applications Spark seront plus rentables et stables. Avec les optimisations appropriées, vous pouvez accélérer votre cycle de développement Spark avec Docker de sorte qu’il faut moins de 30 secondes entre le moment où vous apportez une modification à votre code et celui où il est déployé sur notre plate-forme.
![]()
- Il est en mode autopilote.
Nous pensons qu’une plateforme Spark « gérée » devrait faire plus que simplement démarrer des machines virtuelles lorsque vous en faites la demande. Elle devrait en fait décharger ses utilisateurs de la gestion de l’infrastructure. C’est pourquoi notre plateforme ajuste dynamiquement et automatiquement les paramètres d’infrastructure et les configurations Spark les plus importants : taille des clusters, type d’instance, types de stockage, niveau de parallélisme, gestion de la mémoire, configurations du shuffle, etc. Cela rend Spark 2x plus stable et plus rentable, comme cela a été illustré lors du Spark Summit 2019 via une success story.
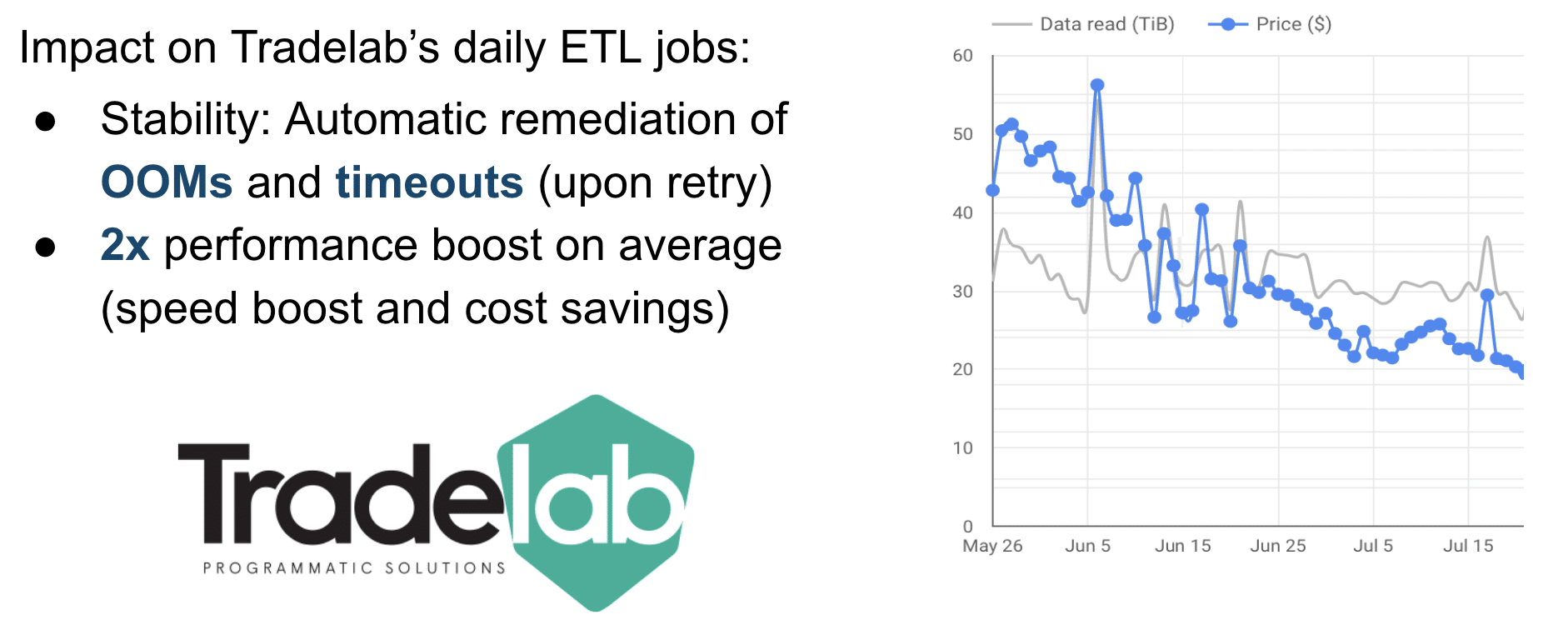
- Son prix est calculé en fonction du temps de calcul réel de Spark.
Les plateformes Spark concurrentes facturent des frais basés sur le temps de fonctionnement du serveur (« L’utilisation de ce type d’instance pendant une heure vous coûtera 0,40 $ »). Cette redevance est due que la machine soit effectivement utilisée par Spark, ou qu’elle soit juste allumée mais ne tourne pas parce que vous avez fait une erreur de configuration.
Chez Data Mechanics, nous ne gagnons de l’argent que lorsque vos machines sont utilisées pour effectuer des calculs Spark. Cela nous incite à gérer votre infrastructure plus efficacement et à supprimer les ressources de calcul gaspillées.
Le troisième point est spécifique à la plate-forme Data Mechanics, mais les deux premières recommandations — la dockérisation et certaines fonctions de pilotage automatique (au moins la mise à l’échelle automatique) peuvent être disponibles directement sur votre plate-forme Spark.
Rendre Spark plus accessible grâce à une nouvelle interface utilisateur de monitoring
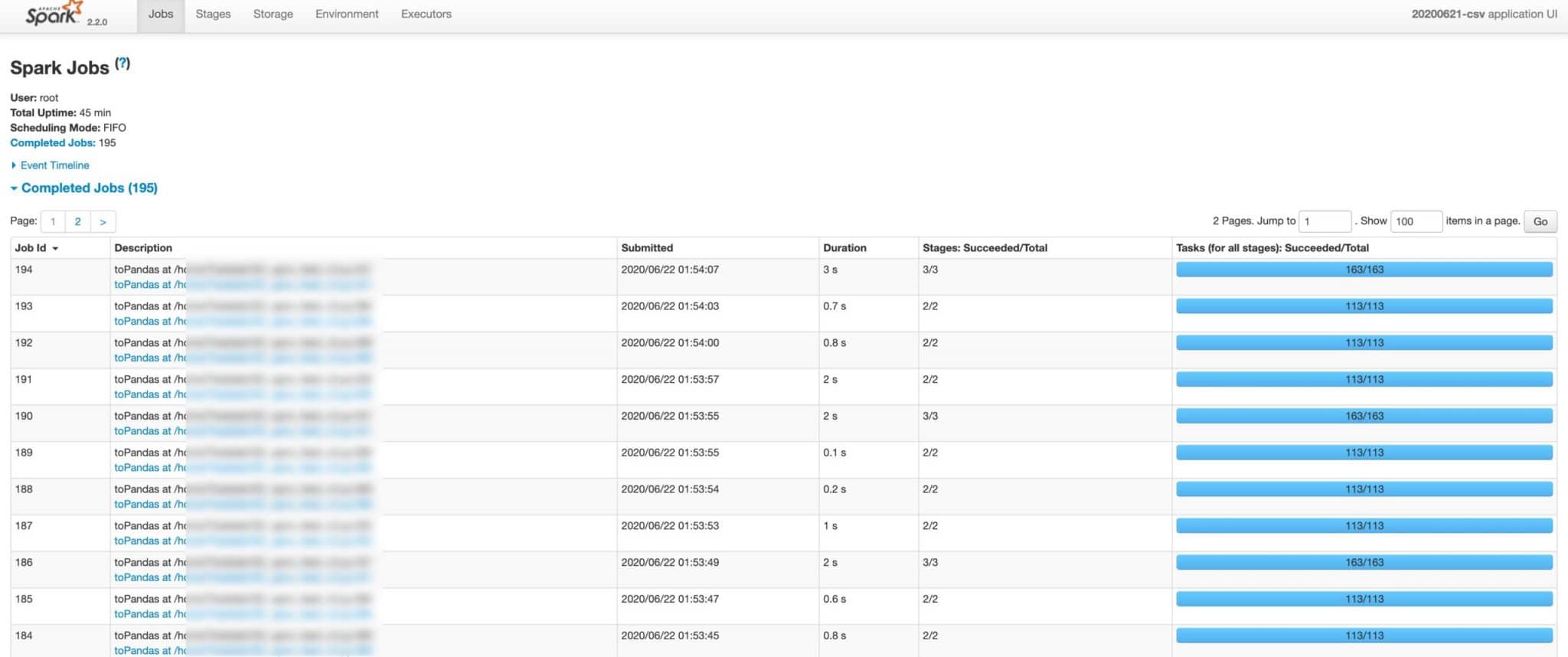
L’approche serverless peut accélérer votre cycle d’itération de 10x et diviser vos coûts par 3x. Mais si votre code Spark présente un bug ou si vos données ne sont pas partitionnées de la bonne manière, c’est toujours au développeur de résoudre ce problème. Aujourd’hui, le seul outil de suivi disponible pour résoudre ces problèmes est appelé la Spark UI (capture d’écran ci-dessous), mais elle est lourd et peu intuitif :
- Trop d’informations sont affichées. Il est difficile de repérer où l’application passe le plus de temps et quel est le goulot d’étranglement.
- Il manque des mesures importantes concernant l’utilisation de la mémoire, l’utilisation du processeur, les entrées/sorties.
- Le serveur d’archive de Spark (nécessaire pour accéder à l’interface utilisateur une fois l’application terminée) est difficile à mettre en place.
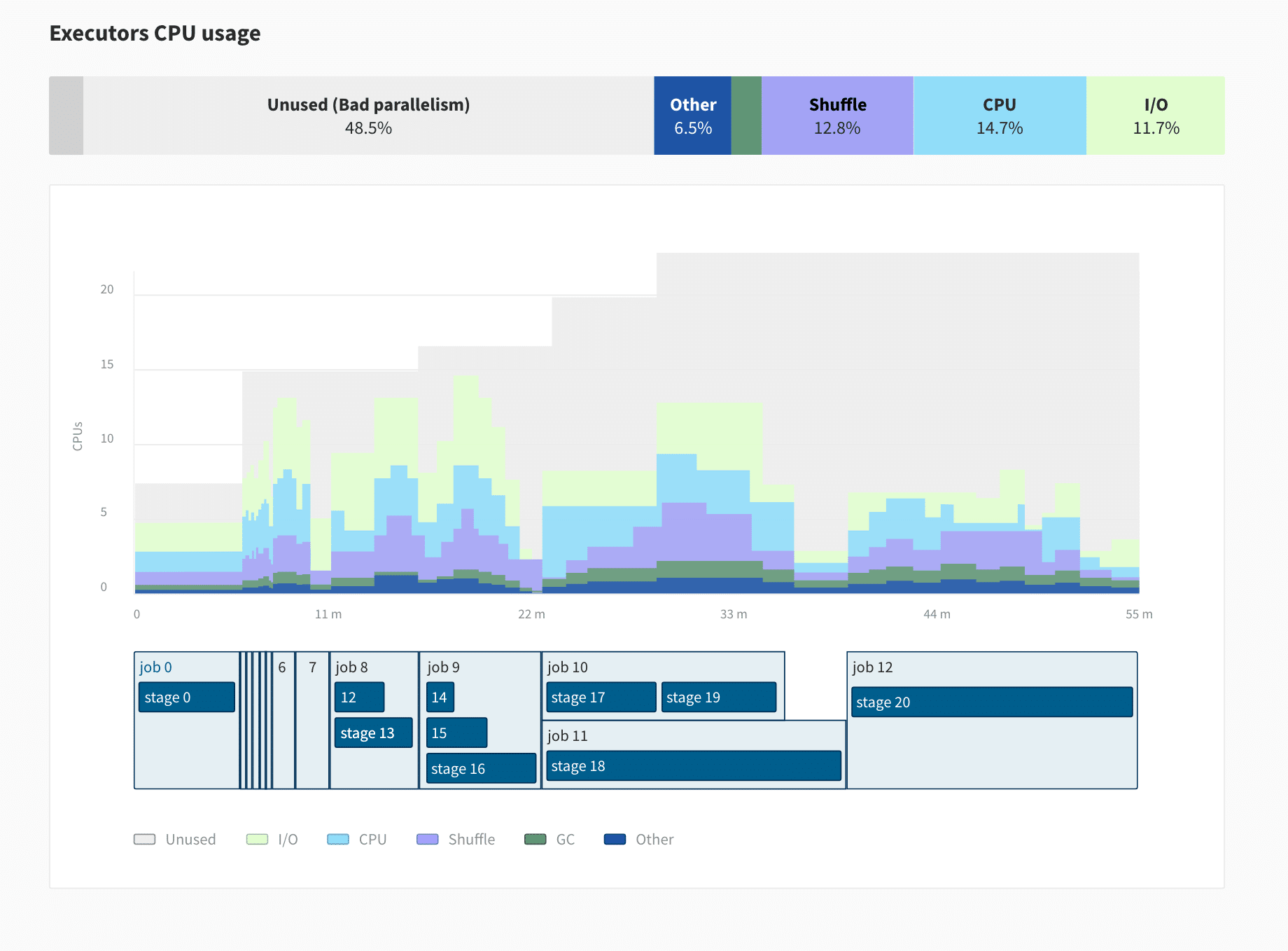
Pour résoudre ce problème et rendre Spark plus accessible aux débutants comme aux experts, l’équipe de Data Mechanics développe un nouvel outil de suivi pour remplacer l’interface utilisateur de Spark, le Data Mechanics Delight. Delight sera mis gratuitement à la disposition de l’ensemble de la communauté Spark (et pas seulement des clients de Data Mechanics). Vous pourrez l’installer sur n’importe quelle plateforme Spark (dans le cloud ou on-premise) en téléchargeant un agent open-source qui fonctionnera via le driver Spark et transmettra les mesures au backend de Data Mechanics.
Voici une capture d’écran de ce à quoi ressemble Delight. Il s’agit d’un écran d’aperçu qui permet aux développeurs d’avoir une vue d’ensemble de leur application, avec des mesures clés et des recommandations de haut niveau. De nouvelles mesures concernant l’utilisation du processeur et de la mémoire aideront les développeurs à comprendre le profil des ressources de leur application et le goulot d’étranglement.
Data Mechanics Delight UI est en cours de développement. En novembre, une première version sera lancé qui consistera simplement en une interface utilisateur amélioré de Spark hébergée gratuitement, et en janvier la nouvelle interface de monitoring sera publié avec de nouvelles métriques et une meilleure expérience utilisateur.
Conclusion : L’avenir d’Apache Spark
Nous espérons que cet article vous a donné des recommandations concrètes pour vous aider à mieux réussir avec Spark, ou des conseils pour vous aider à démarrer ! Quantmetry et Data Mechanics sont à votre disposition pour vous aider.
Pour conclure, passons en revue les activités passionnantes qui se déroulent actuellement au sein de la communauté Apache Spark.
- Spark 3.0 (juin 2020) a permis de multiplier par 2 en moyenne les gains de performance grâce à des optimisations de performance telles que l’exécution adaptative des requêtes et la taille des partitions. L’allocation dynamique (autoscaling) est maintenant disponible pour Spark sur Kubernetes. De nouvelles astuces de type Pandas UDF et Python facilitent également le développement en PySpark.
- Spark 3.1 (décembre 2020) déclarera Spark-on-Kubernetes comme officiellement disponible et prêt pour la production grâce à des correctifs de stabilité et de performance, accélérant ainsi la transition des plateformes basées sur YARN aux plateformes basées sur Kubernetes (comme Data Mechanics). D’autres optimisations sont également prévues, comme le filtrage des formats de fichiers JSON et Avro.
