

Regard sur Strata + Hadoop World 2015

Les 5, 6 et 7 mai derniers, Londres accueillait data scientists, ingénieurs et décideurs métiers désireux d’échanger sur les dernières nouveautés du big data, lors de Strata + Hadoop World 2015. Présents à cet évènement, nous vous présentons à travers ce billet notre regard sur les technologies, produits et cas d’usages qui nous ont les plus marqués.
SESSION – THE INTERNET OF TRAINS – GERHARD KRESS (SIEMENS AG)
Le secteur de la maintenance ferroviaire connait actuellement d’importantes évolutions. L’expansion et la libéralisation du marché ont entraîné l’augmentation de la pression concurrentielle et conduit aujourd’hui les opérateurs à innover. Un axe d’innovation choisi par Siemens AG pour se différencier de ses concurrents est l’utilisation de données de capteurs embarqués et le développement de modèles prédictifs avancés, dans le but d’améliorer la gestion du risque : cibler les opérations de maintenance et anticiper incidents.
Siemens AG a créé un data lab, dans lequel des data scientists, des développeurs et des experts métiers réalisent des projets de data science qui apportent de la valeur à la totalité l’entreprise. Ce data lab a notamment permis la conception d’un modèle de détection de panne de portes, basé sur les données de capteurs de chacune des pièces du train qui, représentées en graphe, permettent de détecter des comportements anormaux. Un autre projet porté par le data lab est la réalisation d’un système de product information management, ou PIM, construit à partir des fiches techniques des pièces, qui permet aujourd’hui d’optimiser le remplacement des pièces défectueuses.

Siemens AG est un exemple d’entreprise mature vis-à-vis de la data science, capable de réaliser des projets innovants et de les mettre en production. Son adoption précoce des technologies et des compétences nécessaires en data science lui permettent aujourd’hui d’innover sur leur secteur et de consolider leur position dominante.
SESSION – IMPROVING FEATURE ENGINEERING IN THE LAB AND PRODUCTION WITH IVORY – BEN LEVER (AMBIATA)
Dans beaucoup de projets de data science, l’étape de feature engineering est la plus longue, la plus compliquée, mais c’est également celle qui apporte le plus de valeur. Souvent, l’objectif final du feature engineering est d’obtenir un feature vector, table représentant en ligne les individus, et en colonne les variables les plus riches possibles, à partir d’une base de données potentiellement complexe : évènements séquentiels, caractéristiques évoluant dans le temps, données en graphe, etc.
Ivory, projet open-source basé sur Hadoop, est un data store scalable et extensible, qui permet de simplifier la phase de feature engineering. Ivory stocke les données sous forme de « facts », un fact étant la donnée d’une entité, un attribut, une valeur et un timestamp, décrit dans un dictionnaire. L’exemple ci-après présente une base de données bancaires contenant des caractéristiques, gender et postcode, des évènements, cc.purchases, et des états, sav.balance, modélisée par Ivory en facts.
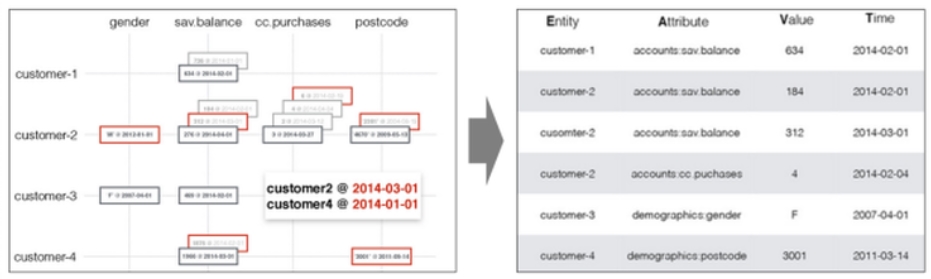
A partir de ces facts, il est facile de générer un feature vector exploitable, dans lequel toutes les entités sont observées soit à la même date, soit par rapport à un même évènement (par exemple churn, clic). Les features créés peuvent être des base features : la valeur de la variable est la dernière valeur observée (par exemple pour le genre ou l’adresse), ou bien des virtual features : la valeur de la variable est un compte, une moyenne ou une somme sur une fenêtre précédant l’instant observé (par exemple le nombre de purchases pendant les 4 semaines précèdent un évènement).
Ivory apparait comme un outil séduisant, car il simplifie et mécanise la phase de feature engineering qui peut être source d’erreur et de complexification du processus de data science. L’outil et plus de détails sont disponibles sur le github ambiata : https://github.com/ambiata/ivory
SESSION – AN INFORMATION ARCHITECTURE FOR HADOOP
De plus en plus d’entreprises adoptent Hadoop pour en faire un espace dédié pour le stockage et l’analyse de données massives dans le but de soulager le SI historique. Pour simplifier les questions d’interfaçages entre le monde Hadoop et le SI il est facile de s’abriter derrière le concept de « Data lake ». Ce concept doit être manipulé avec précaution car rapidement, sans travail de fond, l’image paisible et relaxante d’un Data Lake peut se transformer en une vision plus anxiogène de « Data Swamp ».
Conscient de cet écueil Cloudera nous propose dans cette présentation un framework macro pour l’organisation du stockage des données sur cluster. Ce Framework nommé « Lasagna Architecture » propose d’organiser et de stocker les différentes étapes du cycle de vie des données sous forme de couches distinctes. Cette organisation proposée peut être interprétée comme un demi-aveu que « Oui, la création d’un data lake demande beaucoup de travail lors des phases de conception de réalisation et d’exploitation d’un cluster».
Les différentes couches à alimenter dans l’ordre sont d’après ce Framework les suivantes :
-
Raw Layer: Capture des données brutes à l’image des sources
-
Discovery Layer: 1ers croisements et 1eres analyses
-
Shared Layer : Partage de toute la matière brute d’analyse au reste de l’organisation
-
Optimised Layer: Espace fruit des couches d’analyses, centralise les résultats ou pré-calculs d’analyses dans des zones qui optimisent l’exploitation de cas d’usages
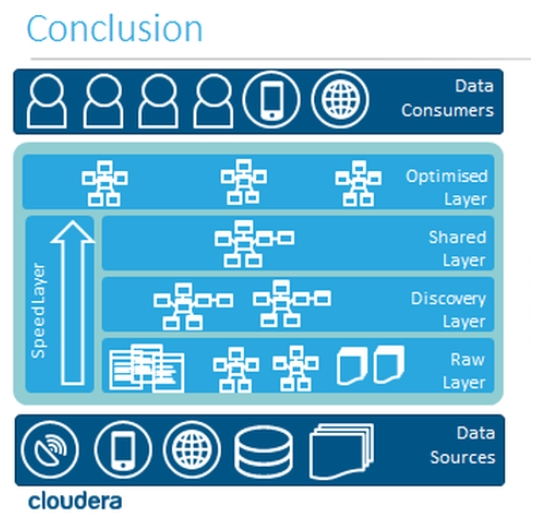
Finalement l’organisation proposée pourra sembler plutôt familière à tous ceux qui ont eu l’occasion de travailler sur des architectures décisionnelles organisées autour d’un entrepôt. Cette organisation qui a fait ses preuves lors de ces deux dernières décennies nous est présentée avec une belle rotation de 90° de ce que l’on pouvait avoir l’habitude de voir.
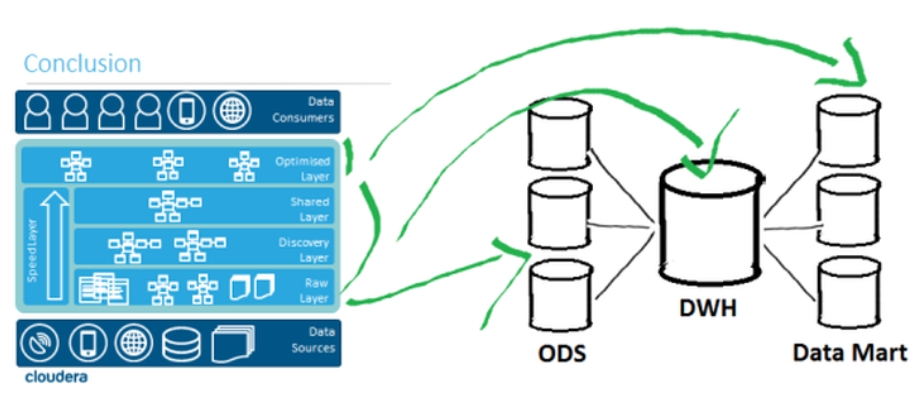
Ce macro framework est séduisant et parait solide pour beaucoup d’applications chez nos clients. Cloudera nous offre un talk clair et bien structuré qui mêle la théorie et l’expérience du terrain. Le support de présentation est disponible ici
SESSION – AUTOMATIQUE DATA ENCRYPTION ON HDFS
Un autre sujet légitime d’inquiétude remonté régulièrement par nos clients est l’exploitation d’un cluster et la sécurité des données qui s’y trouvent. Un peu plus tard à Strata un autre excellent talk nous est proposé par Cloudera sur une réponse efficace sur ce sujet : le cryptage des données directement sur HDFS.
Parmi les nombreux points qui peuvent être sécurisés, le cryptage direct des données au niveau HDFS permet de se mettre à l’abri de plusieurs types d’attaques (Accès physique aux disques, network sniffing, vols d’accès admin..). L’architecture repose sur un ensemble de clefs de cryptages gérées par un serveur dédié (Key Manager Server : KMS) capables de crypter des répertoires et leurs contenus pour un utilisateur complétement dé-corrélé d’HDFS.
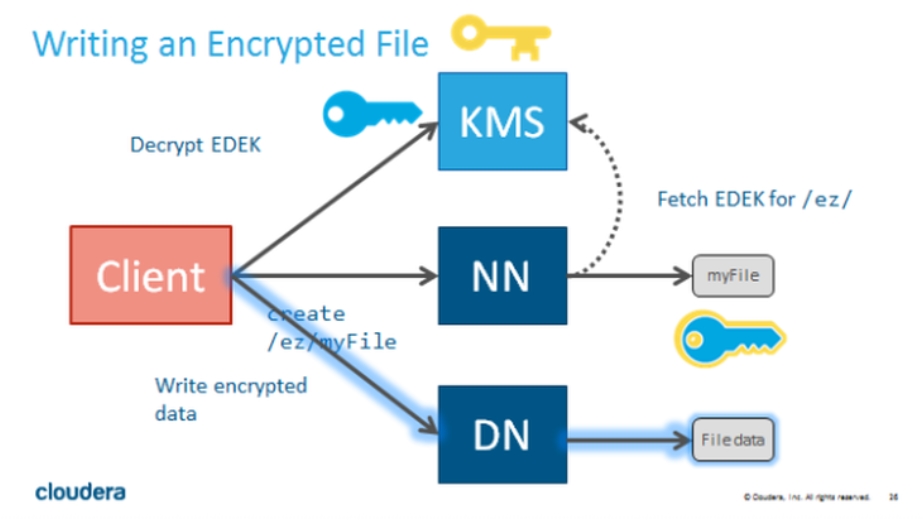
Après une présentation assez technique mais plutôt claire de l’architecture et des concepts du design, le talk s’est concentré sur les questions de performances de cette approche. Avec un hardware spécialisé pour ce genre de problèmes, le cryptage des données a un impact négligeable en write et une baisse de l’ordre de 7% en read.
Pour plus d’informations sur le talk, le support de la présentation est disponible ici.
SESSION – STEADY UX: BALANCING PERSONALISATION AND PRIVACY TO CREATE UNDERSTANDING AND TRUST – ANN WUYTS (SENTIANCE)
La gestion des données personnelles et le respect de la vie privée sont les enjeux centraux lorsqu’il s’agit de big data, car c’est un sujet de préoccupation pour les consommateurs. Le compromis entre personnalisation (recommandation, ciblage, etc.) et respect de la vie privée est une question que chaque entreprise désireuse d’entreprendre une démarche big data doit se poser, et dont la réponse doit prendre en compte des éléments juridiques et des éléments éthiques, à travers la relation de confiance que veut nouer une marque avec ses clients.
La principale inquiétude des consommateurs concernant le partage de leurs données personnelles est due à la sensation de « signer un chèque en blanc », c’est-à-dire de livrer leurs informations sans savoir à quelles fins elles seront utilisées ultérieurement.
Le conseil donné aux entreprises est d’être totalement transparent sur leur utilisation des données personnelles. Des moyens pour y parvenir sont par exemple le fait de préciser l’objectif de chaque demande de données personnelles, de limiter la collecte aux données réellement nécessaires et exploitées ou encore de permettre aux utilisateurs de consulter leurs données et de les supprimer.
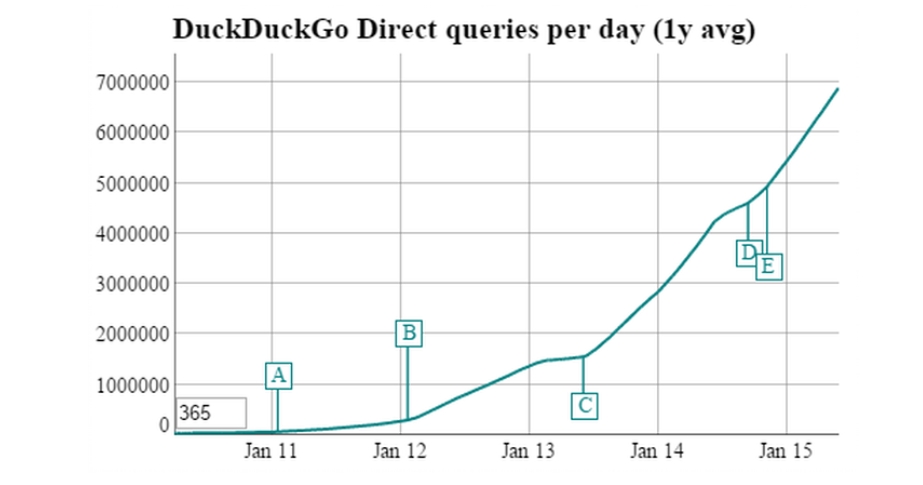
Le respect de la vie privée prend de l’importance et est en passe de devenir un avantage compétitif pour les entreprises qui s’en préoccupent. C’est notamment le cas de DuckDuckGo, moteur de recherche qui communique fortement sur le fait qu’il ne collecte pas de données personnelles, et dont le nombre d’utilisateurs augmente exponentiellement depuis sa création.
CONCLUSION GÉNÉRALE – PRINCIPALES ÉVOLUTIONS OBSERVÉES DANS L’ÉCOSYSTÈME BIG DATA
L’édition de cette année a donc été marquée par un gain en maturité des acteurs : des outils de plus en plus performants sont proposés aux data scientists, à la fois venant de start-ups (DataRobot, Dataiku) et de grands groupes (IBM, Teradata, Google). L’écosystème d’Hadoop évolue et des réponses aux problèmes classiques longtemps négligés commencent à être proposées, notamment concernant les organisations data lake et la securité des données. Les techniques de data science les plus traitées cette année et animant le plus la communauté restent l’online learning et le deep learning. L’innovation qui semble être la plus impactante sur l’écosystème cette année est sans doute l’internet des objets, qui génère de nouveaux types de données et de nouveaux usages. Enfin, les aspects de données personnelles et de respect de la vie privée prennent de plus en plus d’ampleur et deviennent des sujets à part entière qu’il faut prendre en compte en data science.
