

Smart Cities et data science – Partie 2

Chez Quantmetry, nous avons décidé d’y voir plus clair sur le sujet Smart Cities, très à la mode depuis quelques années déjà. En particulier, nous avons décidé de considérer une dizaine de cas d’usage spécifiques, de les détailler et d’en évaluer l’intérêt pour une entreprise comme la nôtre, spécialiste dans le domaine de la Data Science. Dans la première partie de ce travail, sortie il y a quelques semaines sur notre blog, des cas d’utilisation tels que la réalisation d’un système d’éclairage adaptatif, d’une offre de stationnement dynamique ou encore d’une plateforme de marketing digital touristique ont été analysés.
6. SMART GRID ENERGIE
L’introduction de capteurs dans le réseau électrique et chez les compteurs des usagers permet une compréhension plus fine des usages. Cette connaissance autorise la mise en œuvre de deux modes d’actions. En premier lieu, les smart grids étant un type particulier de réseau, nous pouvons mettre en œuvre toutes les améliorations propres aux systèmes de réseaux distribués vus précédemment (maintenance au plus juste, équilibrage dynamique …). D’autre part, des actions plus spécifiques au secteur de l’énergie peuvent être entreprises comme la proposition d’une tarification dynamique pour encourager les comportements vertueux (par exemple, les usages hors pics). Enfin, le déploiement de smart grids peut faciliter la création de communautés autosuffisantes et l’avènement du producteur consommateur (un client particulier peut être à la fois producteur d’énergie et consommateur grâce à des unités locales de production d’énergie).
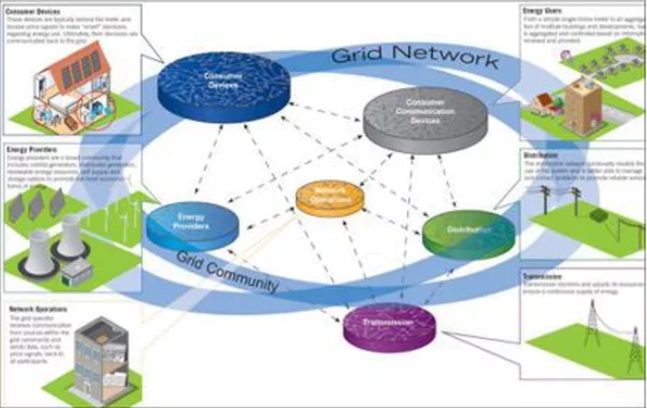
En termes de Data Science, nous trouvons deux sujets à traiter. Comme toujours dans la gestion des réseaux, d’importantes améliorations peuvent être produites du point de vue de la maintenance prédictive et de la priorisation des interventions, de manière à fournir aux équipes techniques une information plus détaillée sur les situations qui sont les plus risquées pour l’ensemble du réseau, et qui seront donc à traiter en priorité. Sur le moyen terme, on pourra utiliser les aperçus en tant qu’aide à la prise de décision : les modifications du réseau pourront en fait être réalisées de manière à adresser les criticités structurelles ou récurrentes détectées par les algorithmes.
Le bénéfice attendu le plus immédiat sera l’amélioration des interventions de maintenance sur le réseau. La tarification dynamique encourageant les usages hors pics pourra donner lieu à une meilleure et plus homogène exploitation des ressources. Les données récoltées, enfin, vont aider les décisions sur les modifications structurelles à apporter au réseau pour résoudre les problèmes détectés, en simulant par exemple les effets que ces interventions auront sur le système.
RÉFÉRENCES D’EXPÉRIMENTATIONS
Des expérimentations concernant les réseaux d’auto-production et de consommation locale d’énergie ont déjà été menées, comme par exemple le projet RennesGrid. Remarquons que sur ce sujet l’approche pragmatique qui met le réseau de producteurs-consommateurs en lien avec le reste du réseau est à considérer nécessaire, au moins pour la phase initiale de chaque projet, quand le risque serait de ne pas avoir encore une masse critique assez élevée pour garantir aux participants un apport suffisant en énergie.
A remarquer que, même si ce projet vient de remporter des prix pour sa qualité et sa capacité d’innovation, les premiers KWh ne seront pas produits par RennesGrid avant 2017. Une description quantitative et objective de résultats et retombées pratiques générés par cette nouvelle typologie d’infrastructure n’est donc pas encore directement faisable.
7. OFFRE DE SANTÉ CONNECTÉE
Plusieurs typologies d’interventions peuvent être imaginées dans le secteur de la santé. L’une des plus simples est de mettre en place une plateforme unifiée des ressources à disposition dans la ville (médecins généralistes, spécialistes, pharmacies, urgences) et de leurs disponibilités pour RDV et interventions de différents types. Cette plateforme pourra même être utilisée d’une façon plus proactive, par exemple en suggérant aux patients l’hôpital dans lequel le temps d’attente pour l’examen à réaliser est le plus court. On peut viser de cette manière un usage plus équilibré des ressources et une coordination des parcours de soins entre les différentes structures ; les données recueillies pourront être aussi analysées a posteriori, avec l’objectif de choisir de manière optimale les modifications à faire sur le système (par exemple, quels hôpitaux renforcer en connaissant la demande et l’offre à un niveau beaucoup plus fin que aujourd’hui). Dans l’analyse de ce cas d’usage, il faut bien considérer l’importance du traitement des données personnelles qui est centrale pour les sujets liés à la santé.
Du point de vue de la Data Science, la partie la plus intéressante est l’aide relative à l’analyse de données sur le court terme (exploitation optimale des ressources actuellement existants via un système de réservations qui prend en compte l’utilisation globale des ressources) et sur le moyen terme (en comprenant les modifications sur le système qui l’amélioreront le plus et qui seront les plus adaptées pour adresser les criticités détectées dans la première phase).
Pour ce qui concerne les bénéfices attendus, des améliorations sont d’abord à prévoir en termes de services offerts aux patients une fois que toutes les informations seront groupées sur une même plateforme. Une telle plateforme permettra par exemple aux citoyens de facilement repérer la structure hospitalière avec le temps d’attente le plus court pour les examens cliniques qu’ils devront subir. Les structures hospitalières, de l’autre côté, pourront optimiser leur utilisation des ressources ; en diminuant l’impact de pics d’usage, elles pourront par exemple mieux programmer le staff de chaque hôpital. Pour les décideurs et les pouvoirs publics enfin, les analyses réalisées fourniront une aide précieuse dans les choix des modifications à faire sur le système pour résoudre les problèmes détectées et pour l’améliorer ultérieurement.
RÉFÉRENCE D’EXPÉRIMENTATIONS
Les expérimentations mises en place jusqu’ici sont pour la plupart partiels, et ne traitent pas encore du problème dans sa complexité globale.
Dans cette référence, par exemple, le projet crée par la ville de Barcelone dans le contexte du suivi à distance des personnes plus âgées est présenté. La possibilité, que la connexion en temps réel va offrir, de traiter de manière plus efficace les urgences suffit déjà à expliquer l’intérêt de ces projets pour la collectivité.
D’autres études, plus générales mais moins directement appliqués, ont aussi bien été menées. Dans cet article, les auteurs analysent les optimisations qui seraient possibles en utilisant, dans le système sanitaire, les mêmes principes et technologies déjà mises en œuvre dans l’industrie, et en particulier dans le e-business.
8. CARTE DES CONDITIONS DE VIE
Mieux comprendre les conditions de vie dans les différents quartiers, identifier les situations les plus défavorables pour les pouvoir adresser, prioriser au sein de la ville les interventions dans le contexte de la politique sociale, de l’instruction, de la santé puis évaluer l’effet des mesures prises. Voici quelques thématiques à aborder pour la prochaine génération d’hommes politiques. Comment comprendre d’une façon plus quantitative les hétérogénéités au sein d’une ville ?
Et, une fois ces caractéristiques établies, comment évaluer si les actions mises en œuvre sont effectives ? Sur ces sujets, la Data Science peut fournir une aide significative. La première étape, plus simple à réaliser en termes d’infrastructures requises, est le regroupement sur une seule plateforme des informations plus facilement quantifiables sur les conditions de vie dans les différents quartiers telles que le salaire moyen, les données statistiques recueillies par l’INSEE, les indications venant des capteurs installés pour suivre pollution lumineuse, atmosphérique ou sonore. Dans une phase plus avancée, et après un travail de Data Science plus poussé, la même plateforme pourra accueillir des informations moins directement quantifiables telles que le niveau de sécurité perçu en utilisant les données venant par exemple des messages échangés sur les réseaux sociaux.
L’apport Data Science sera fondamental dans la modélisation des données brutes, recueillies dans une variété de formats, et obtenues à travers plusieurs outils (caméras, capteurs, informations obtenues lors d’enquêtes menées dans la population, données présents dans les différents archives de la ville). D’un point de vue technique, on aura à adresser un certain nombre de problèmes d’optimisation sous contraintes (comment choisir le quartier où chercher son appartement en connaissant les caractéristiques de l’usager). Un rôle important va aussi être joué par le traitement de données non structurées, et en particulier des applications en termes de natural language processing pour ce qui concerne le traitement statistique des messages échangés sur les réseaux sociaux. Une partie de modélisation très poussée sera nécessaire au moment où un nombre élevé de paramètres (features) sera fusionné de manière à permettre d’augmenter l’interprétabilité des résultats pour le citoyen, cette dernière n’étant pas forcément garantie par les données brutes.
Le premier résultat attendu de ce cas d’usage sera de fournir aux citoyens les informations sur les conditions de vie dans les différents quartiers et leur donner le moyen d’agir. Dans une démarche de type open government, il y aura une réappropriation de données publiques par la population, et une transparence majeure sur les motivations derrière les choix effectués par la mairie ou par les arrondissements. De plus, l’ouverture des données permettra aux citoyens de proposer des solutions innovantes aux problématiques détectées (cet intérêt étant peut-être même à exploiter plus en profondeur, en utilisant des formats du type Hackathon sur ces typologies de données). Une telle plateforme donnera aussi aux citoyens la possibilité de se mettre en contact plus facilement et de façon moins formelle avec décideurs et autorités locales, afin de signaler les services nécessaires et pas encore fournis, les structures nécessitant une mise à jour, les quartiers et bâtiments dégradés. Dans ce contexte, il faut s’attendre que de plus en plus de cas d’usages (parfois inattendus) soient proposés après la mise à disposition d’une telle infrastructure.
RÉFÉRENCES D’EXPÉRIMENTATIONS
Dans ce lien, un reportage sur la façon dont une application de ce genre a permis aux habitants de Detroit à se rapprocher au renouveau de la ville.
9. PLANIFICATION URBAINE
Dans la section précédente, les jeux de données permettant de mieux comprendre les conditions de vie dans les différents quartiers. Le même jeu d’informations peut être utilisé par les décideurs publics en vue d’aménager la ville. La partie prédictive des modèles (et, en conséquent, la nécessité d’utiliser des méthodes de machine learning plus adaptés) est centrale dans ce cas d’usage, car la valeur ajoutée sera principalement la possibilité de prévoir à l’avance l’effet des interventions programmées ; ça, en vue de limiter au maximum la gêne procurée et d’effectuer lesdites interventions de la manière la plus efficace. L’évaluation à l’avance de l’impact des travaux sur la circulation urbaine (par rapport, par exemple, à la création de bouchons) sera une information précieuse pour pouvoir décider la date la plus adaptée pour le démarrage des travaux. Dans le transport public, les décideurs vont connaitre à l’avance les changements dans les temps de déplacement dû à l’ajout au réseau urbain des lignes de transport public ou à leur prolongement. Cette information les aidera à bien choisir quels axes de transport public renforcer prioritairement. De la même manière, pour chaque situation critique détectée en suivant la logique expliquée dans la section précédente on pourra simuler différentes approches, pour finalement mettre en œuvre la plus prometteuse. A posteriori, on pourra vérifier l’impact réel des actions prises, de manière à rendre les algorithmes utilisés de plus en plus fiables.

Dans ce contexte, la Data Science a sans doute un rôle central : en plus de ce qui a été dit pour le cas d’usage précédent et qui reste en bonne partie valable, il y aura ici une composante plus poussée du point de vue de la modélisation, le focus étant plutôt sur la prédiction que sur l’observation des conditions existantes.
La connaissance quantitative améliorée des problématiques abordée, obtenue à travers la mise en œuvre de ce genre de projet, apportera de la valeur dans plusieurs phases du processus de la prise de décision. D’abord, elle permettra une identification plus rapide et ponctuelle des criticités existantes au sein de la ville. Ensuite, elle sera utile pour choisir la manière la plus adaptée d’aborder le problème identifié (en considérant des différentes possibilités et en simulant leur impact). Enfin, elle permettra un suivi des effets vraiment obtenus, pour détecter difficultés ou erreurs dans la mise en œuvre, et même pour améliorer à fur et à mesure les algorithmes utilisés pour rendre les prévisions de plus en plus en ligne avec les effets réels de chaque typologie d’intervention.
10. SÉCURITÉ PUBLIQUE
Les comportements de délinquance sont-ils prévisibles ? Sur la base de cette hypothèse raisonnable et vérifiée dans un grand nombre de cas, il est ainsi possible d’anticiper les lieux et les périodes de temps les plus favorables à un passage à l’acte et guider ainsi la police.
Les modèles de Data Science utilisés ici sont des modèles de prédiction (identification de features) et des modèles de calcul de risque s’appuyant sur des historiques. Les données utilisées seront différentes, entre les messages échangés sur les réseaux sociaux, les bases de données des forces de l’ordre (même s’il faut considérer que le partage d’information sur le thème de la sécurité n’est pas toujours évident …), les données recueillies par les capteurs présents dans la ville et concernant plusieurs paramètres.
Les bénéfices attendus sont une amélioration dans le sentiment de sécurité des citoyens d’un côté, et une optimisation des ressources de la police (par exemple en ciblant les parcours des patrouilles). Les mêmes analyses et données seront utilisables aussi au moment de la décision sur comment répartir les forces de l’ordre sur le terroir d’une ville, la façon optimale de gérer une urgence (telle qu’une acte de terrorisme ou un désastre naturel).
Une bonne dose de pragmatisme, toujours utile dans l’analyse du sujet Smart City, s’avère être particulièrement nécessaire à l’égard de cette application. Il faut bien considérer, en fait, que les modèles exploitant la répétabilité des évènements sont aptes à en capter seulement une partie. Un délinquant astucieux peut mettre en place des stratégies d’évitement en accomplissant ses forfaits dans des zones à chaque fois différente. Nous pouvons constater que les délinquants les plus dangereux ont depuis longtemps arrêté d’utiliser les moyens modernes de communication, ce qui leur permet de naviguer sous la surface. Attention à la surenchère technologiste en matière de renseignement.
Un autre risque (mais finalement moins probable que le premier car faisant l’hypothèse de modèles parfaits), serait de permettre aux forces policières et judiciaires de prendre des actions sur la base des prédictions statistiques obtenues via les algorithmes : cette utilisation à laMinority Report des méthodes de la Data Science serait extrêmement dangereuse si appliquée au niveau des individus, car elle constituerait une violation au principe du libre arbitre de chaque personne.
RÉFÉRENCES D’EXPÉRIMENTATIONS
Le logiciel PredPol aurait dans certaines villes des Etats-Unis amélioré le taux d’élucidation des policiers et conduit à une diminution de l’ordre de 30% des faits constatés.
La mairie de Paris a récemment organisé l’Hackathon Nec Mergitur ayant comme but le rassemblement de l’écosystème parisien de l’innovation afin de proposer de nouvelles approches au thème de la sécurité en ville ; plusieurs parmi les projets proposés ont, au moins potentiellement, une forte composante sur l’axe Data Science – Big Data – Machine Learning.
11. PRÉVENTION ET GESTION DES RISQUES
Un certain nombre de phénomènes, difficiles à prévoir, peuvent avoir des effets potentiellement catastrophiques sur la vie d’une ville. Cette dernière, en fait, est constamment exposée à risques de différente nature :
-
sociale (voir les émeutes violentes dans les banlieues françaises en 2005) ;
-
économique (avec l’appauvrissement, et la conséquente détérioration des conditions de vie dans certains quartiers) ;
-
sanitaire (déclenchement d’épidémies) ;
-
hydrogéologique (quartiers qui peuvent être endommagés à la suite d’événements naturels tels qu’inondations, éboulements, tremblements de terre …).
Les possibles bénéfices dans ce domaine sont très variés, et bien visibles par l’ensemble de la population. L’objectif de mieux identifier (en temps réel, ou même à l’avance) les situations les plus risquées, enchainera ainsi sur un augmenté sentiment de sécurité des citoyens et pourra rendre les efforts des forces de l’ordre plus efficaces. La capacité de correctement et rapidement localiser les endroits où un certain événement aura produit les dommages les plus significatifs, permettra aussi de focaliser les aides sur ces quartiers, et de gagner du temps potentiellement vital dans des situations critiques.
On voit bien comment, sous certains points de vue, ce genre de problème n’est pas trop loin d’autres cas déjà adressés avec succès avec des méthodes de Data Science, tels que la maintenance prédictive dans l’industrie où la priorisation des interventions sur un réseau d’énergie. La variété des sources de données d’intérêt (capteurs, open data, mais aussi messages transmis via les réseaux sociaux) ainsi que leur volume va être un vrai challenge, à adresser forcément avec les méthodes Big Data les plus avancés. D’autre côté, les atouts de la Data Science (capacité de modéliser des événements rares, étude de séries temporelles, construction de modèles caractérisés par un énorme nombre de facteurs explicatifs) vont être nécessaire pour arriver à des résultats de haut niveau.
CONCLUSION
CONSTRUCTION DE CAS D’USAGE PRATIQUES
Le sujet Smart City contient un grand nombre de cas d’usage apparemment indépendants, mais qui révèlent néanmoins avoir plusieurs points en commun. Ne retrouverait on pas quelques design patterns ?
Entre les problèmes typiquement adressés, nous trouvons :
-
la mise en place d’une tarification dynamique, pour homogénéiser l’utilisation des ressources ainsi que pour encourager les comportements vertueux ;
-
l’usage de systèmes de maintenance prédictive ;
-
l’aide donnée aux décideurs afin de créer nouveaux services, ainsi que des modifier ceux déjà existants, en suivant une approche data driven;
-
une optimisation des ressources, ainsi qu’une amélioré correspondance entre demande et offre dans les services offerts.
L’ensemble de secteurs dans lesquels ces thématiques sont de grand intérêt est ainsi très varié, et comprend l’urbanisme, la santé, le tourisme, les services publics, l’énergie parmi bien d’autres.
De quelque manière, chaque combinaison secteur visé – problème adressé peut générer un (ou plusieurs !) cas d’usage dans le contexte Smart City. La meilleure mise en relation de la demande et de l’offre pour ce qui concerne les ressources énergétiques nous conduit aux smart grids ; en cherchant d’offrir des offres ciblées dans le secteur touristique on peut imaginer la création d’une plateforme de marketing digital touristique ; l’optimisation dans l’utilisation des ressources dans la santé nous ramène à la perspective de mettre en ligne les ressources existants et leurs disponibilités.
A ce cadre, il ne faut pas oublier de rajouter l’élément fondateur de tout ce sujet de recherche : la donnée ! Aussi dans ce cas-là, le choix est plutôt libre, comme plusieurs sources de données peuvent être choisies pour un cas d’usage, ainsi que la même typologie de data peut avoir des rôles complétement différents selon le sujet abordé. Pour mieux clarifier ce point, il suffira de penser à la location GPS, que dans la perspective d’un amélioré service de sécurité publique peut être utilisée pour détecter les mouvements de foule, et qui pourra aussi bien être d’importance centrale dans une plateforme touristique afin de conseiller les musées les plus proches à chaque usager.
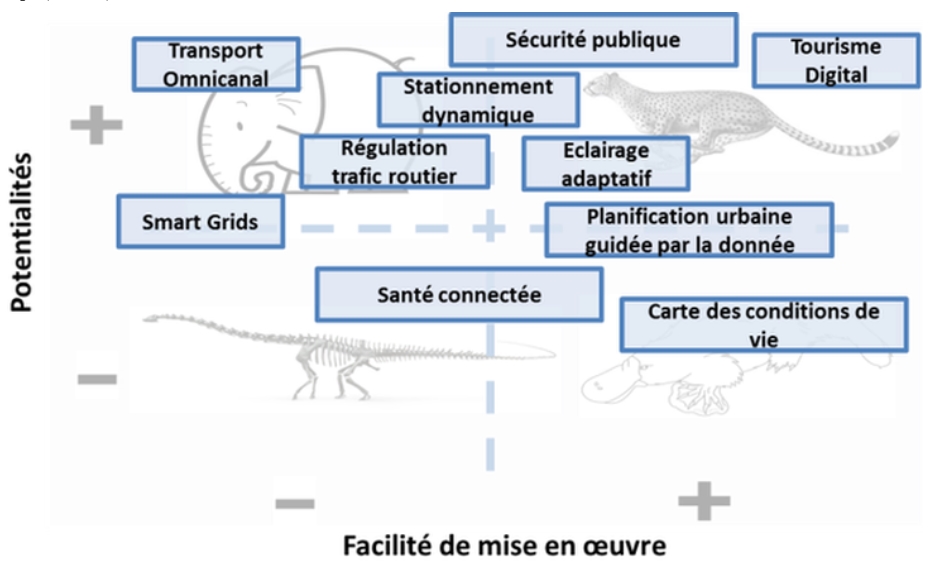
UNE CARTE POUR ÉVALUER L’INTÉRÊT DE CHAQUE CAS D’USAGE
Mais parmi cet énorme nombre de cas d’usage, comment choisir les pistes à suivre ? Dans notre contribution au blog du salon BigDataParis nous avons adressé ce problème d’une façon pragmatique, en analysant comment chaque cas d’usage se pose par rapport à deux axes d’évaluation complémentaires.
En premier lieu, il faut tenir compte de la complexité du projet. Ce terme, expressément générique, comprend des éléments variés qui sont centrales même si pour des raisons différents : entre eux, les investissements nécessaires pour arriver aux premiers résultats, les difficultés techniques prévues, la complexité organisationnelle (si par exemple des collaborations strictes entre plusieurs entités publiques et privées sont nécessaires au bon déroulement du projet), la difficulté d’accès aux données…
Cet axe ne suffit quand-même pas, tout seul, à évaluer correctement l’intérêt d’un cas d’usage : il faut en fait aussi analyser ses potentialités en termes de plus-values immédiates pour la société, de liens avec des enjeux sociaux et politiques de première importance, ou encore de son alignement avec des tendances déjà amorcées dans d’autres secteurs.
En suivant ce cadrage nous sommes arrivés à déterminer quatre régions. Si deux entre elles sont plus faciles à lire (car les projets simples et avec des grandes potentialités sont toujours à développer, tant que ceux peu intéressants et difficiles à mettre en œuvre sont plutôt à stopper), pour les autres la classification est plus flou, et doit prendre en compte plus de paramètres spécifiques. Une solution Smart City difficile à mettre en œuvre mais avec des impacts potentiels majeurs, pourra être par exemple suivie par les grandes structures publiques et privés, capables d’investissements importants sur le moyen terme. D’autre côté, les projets simples à réaliser mais dont l’impact n’est pas encore garanti pourront être soumis à la citoyenneté pendant des hackathons ou d’autres événements similaires, afin de stimuler la fantaisie de la communauté et voir si des applications de valeur peuvent être trouvées. En plus, l’axe des potentialités doit être réévalué périodiquement, car les éléments qui le définissent sont destinés à changer plutôt rapidement.
QUE RETENIR DANS TOUT ÇA ?
Les use cases sont destinés à évoluer, les technologies aussi, ce que aujourd’hui semble être une évolution inéluctable pourra paraitre demain une drôle vision futuriste, alors que certaines applications auxquelles personne n’a encore pensé pourront changer durablement la vie de notre société… Néanmoins, l’étude accomplie nous a permis de trouver certains principes guides qui resteront, à notre avis, figés au cours des prochaines années :
-
en général, le use case doit arriver avant la techno spécifique. Cette réflexion pourrait paraitre triviale, mais c’est toujours bien de se rappeler que nous ne pourrons pas trouver une solution, si le problème n’a pas encore été correctement identifié. Ce principe général, valable bien au-delà de la Data Science, prendre une importance toute particulière dans un domaine aussi quantitative ;
-
beaucoup entre les use cases ont des points en commun entre eux : en particulier, un cas d’usage Smart City est souvent une application à un nouveau secteur d’une solution déjà expérimentée dans un autre. Emprunter les idées qui ont déjà marchés dans d’autres domaines, donc, devient d’importance centrale pour mener à terme le projet avec un budget plus limité, et de façon plus rapide et efficace ;
-
le compromis difficulté – bénéfices doit être évalué attentivement avant de prendre une décision sur les projets à suivre, ceux à abandonner et ceux à laisser de côté pour l’instant, en attendant un changement des conditions actuellement défavorables ;
La Data Science n’est pas de la science-fiction ! Surtout dans une période où les efforts publicitaires sur les améliorations promis par ces nouvelles méthodes sont très présents, garder une approche plus pragmatique est fondamental pour arriver à des résultats concrets. Cette remarque est particulièrement vraie pour les structures les plus petites, qui disposent forcément de budgets réduits pour mettre en place ce genre d’initiative.
De toute manière, nous croyons que l’enthousiasme autour du sujet Smart City est bien justifiée, car tous les cas d’usage ici présenté auraient été inimaginables il y a quelques années (et dans certains cas, il y a quelques mois !). Chez Quantmetry, donc, nous sommes prêts et motivés à vous accompagner dans vos efforts pour rendre les villes qui nous habitons plus vivables, plus intéressantes, plus « intelligents ». Et vous, êtes-vous prêts à cette aventure ?
